According to Gartner, poor data quality costs organizations an average of $12.9 million annually, while IBM research from 2025 shows that organizations take an average of 258 days to identify and contain a data breach. These statistics reveal a fundamental truth: governance can no longer be an afterthought or a manual process; it must be automated, centralized, and embedded into data operations.
A data catalog is a centralized metadata system that helps organizations discover, understand, and govern their data. Within a data intelligence platform, the data catalog provides the discovery and contextual foundation that connects metadata, lineage, governance, and observability across the enterprise. It provides automated discovery, lineage, classification, and policy enforcement, so teams can quickly find trusted data and use it responsibly.
A modern data catalog, with automated discovery, centralized metadata, and policy enforcement, turns fragmented, risky data governance into proactive, trusted self-service access that improves compliance, quality, and decision-making. It represents the change from reactive firefighting to strategic data stewardship, enabling organizations to govern at scale while accelerating analytics and innovation.
Enterprise data catalogs require more than basic search and inventory. Essential capabilities include automated metadata discovery, integrated business glossary alignment, end-to-end lineage, role-based access controls, policy enforcement, data marketplace. and data quality and observability signals. When delivered as part of a data intelligence platform, these capabilities ensure that trusted, governed data is available where analytics and AI are actually used.
What is a Data Catalog?
A data catalog is a centralized system that inventories, organizes, and enriches metadata so users can discover, understand, trust, and govern data across an organization. Modern data catalogs automate metadata collection, track lineage, apply governance policies, and surface quality and trust indicators to support analytics, compliance, and AI initiatives.
Key Benefits of a Data Catalog
Modern data catalogs deliver transformative benefits across governance, compliance, and operational efficiency.
- Centralizes metadata from all sources into a single searchable repository, eliminating data silos.
- Improves data quality and trust through continuous monitoring, validation, and quality scoring.
- Automates classification and policy enforcement, ensuring consistent treatment of sensitive data.
- Speeds analytics and self-service access, by making trusted data discoverable in minutes, not weeks.
- Strengthens compliance with GDPR, HIPAA, and industry regulations.
- Provides lineage to understand data origin, transformations, and usage across the entire ecosystem.
- Reduces operational risk and manual governance work, freeing teams to focus on strategic initiatives.
- Enables data democratization while maintaining security and control through role-based access.
- Accelerates AI and ML initiatives by providing trusted, well-documented training data.
- Improves collaboration between technical and business teams through shared understanding.
Understanding Key Data Governance Challenges
Data governance is the set of policies, roles, and processes that ensure data is available, usable, accurate, and secure across the enterprise. As organizations ingest more data from diverse sources, governance grows harder and more important.
Key challenges include fragmented metadata across disconnected systems, creating inconsistent views and making enterprise-wide governance impossible. Data silos persist because departmental systems don’t communicate, duplicating data and creating version-control nightmares. Inconsistent business terminology means the same concept can have different names across teams, such as “customer” or “client”, while different concepts share the same name, causing confusion and errors.
Manual compliance processes remain slow and error-prone. Spreadsheet-based data inventories go out of date immediately. Access reviews happen quarterly or annually, leaving inappropriate permissions in place for months. Classification relies on manual tagging that misses sensitive data or applies labels inconsistently. Audit preparation consumes weeks of manual evidence gathering.
Poor visibility plagues organizations: teams can’t find datasets that already exist, leading to duplicate work and wasted resources. They can’t assess quality without tribal knowledge or a time-consuming investigation. They can’t trace lineage to understand where data comes from or what depends on it, making impact analysis impossible and root cause investigation painfully slow.
Without clear ownership and stewardship, data quality decays as no one takes responsibility for accuracy, completeness, or timeliness. Trust erodes when users encounter quality issues repeatedly, and they stop using official data sources in favor of uncontrolled alternatives.
The consequences go beyond inefficiency: regulatory fines, security incidents, and stalled analytics or AI initiatives. Organizations attempting to scale AI find that model development grinds to a halt without reliable, well-documented training data. To scale trusted self-service and become data-driven, organizations need governance that is automated, centralized, and integrated into everyday workflows.
Automate Data Discovery and Metadata Collection
Automated discovery continuously scans databases, files, cloud storage, and applications to identify data assets, eliminating manual inventories and ensuring comprehensive coverage. Modern discovery tools detect source locations, schema, relationships, and usage patterns, improving accuracy over time with machine learning.
Automated metadata harvesting extracts far richer information than manual documentation ever could. Technical metadata includes schema details, data types, nullability, uniqueness, cardinality, and statistical profiles showing value distributions and quality indicators. Business metadata captures purpose, ownership, quality scores, and usage guidelines. Operational metadata tracks access patterns, query performance, data refresh schedules, and lineage showing transformations.
These automated processes keep the catalog synchronized with reality. When developers deploy schema changes through CI/CD pipelines, discovery detects them within hours. When new data sources come online, they appear in the catalog automatically. When datasets are decommissioned, the catalog reflects their removal. This synchronization prevents the catalog from becoming yet another out-of-date documentation system that teams ignore.
Automation dramatically shortens onboarding times for new sources—from weeks or months to hours or days—so analytics projects start faster. At the same time, governance policies and access controls apply from ingestion onward.
Build a Centralized, Comprehensive Data Catalog
A centralized data catalog indexes and organizes all enterprise data assets into a single searchable interface, breaking down silos and creating a single source of truth. This consolidation delivers immediate practical benefits. Users spend minutes finding datasets instead of days asking around. Duplicate work decreases dramatically when teams can see what already exists. Governance policies apply uniformly because there’s one place to define and enforce them. Audit preparation accelerates because all evidence resides in one system with comprehensive logging.
Search and Discovery Capabilities: Modern catalogs offer multiple search paradigms to match different user needs. Keyword search allows quick lookups by name or description. Semantic search understands business concepts, finding “revenue” datasets when users search for “sales.” Faceted search enables filtering by source system, data domain, owner, classification, quality score, or recency. Users can browse taxonomies and hierarchies, or follow recommendations based on their role and past usage patterns.
Data Quality and Trust Indicators: Each dataset displays quality metrics computed from profiling and validation rules: completeness percentages, accuracy scores, timeliness indicators, and consistency measures. User ratings and comments provide qualitative feedback. Usage statistics show popularity—datasets heavily used by senior analysts often signal higher trust than rarely touched assets. Certification badges indicate formal review and approval by stewards.
Usage Analytics: The catalog tracks who accesses datasets, when, and for what purposes. This visibility reveals popular data products worthy of additional investment, identifies underutilized assets that might be candidates for archival, and helps stewards understand their data’s impact. Analytics also detect unusual access patterns that might indicate security concerns or policy violations.
Collaborative Features: Users can comment on datasets, asking questions or sharing insights. They can rate data quality based on experience. Stewards can attach usage examples showing common queries or analysis patterns. Discussion threads around data assets create institutional knowledge that would otherwise live in Slack channels or email threads, making them difficult to find later.
Business Context and Standardization: Centralization enforces consistent business language through standardized definitions, classifications, and glossaries. When “customer” has an authoritative definition linked to every dataset containing customer data, cross-departmental confusion disappears. Teams align on terminology, reducing misunderstandings that lead to incorrect analysis or duplicated work.
Modern catalogs store technical and business metadata, usage examples, and quality assessments so users understand what data means, how it’s produced, how reliable it is, and the appropriate use cases and limitations.
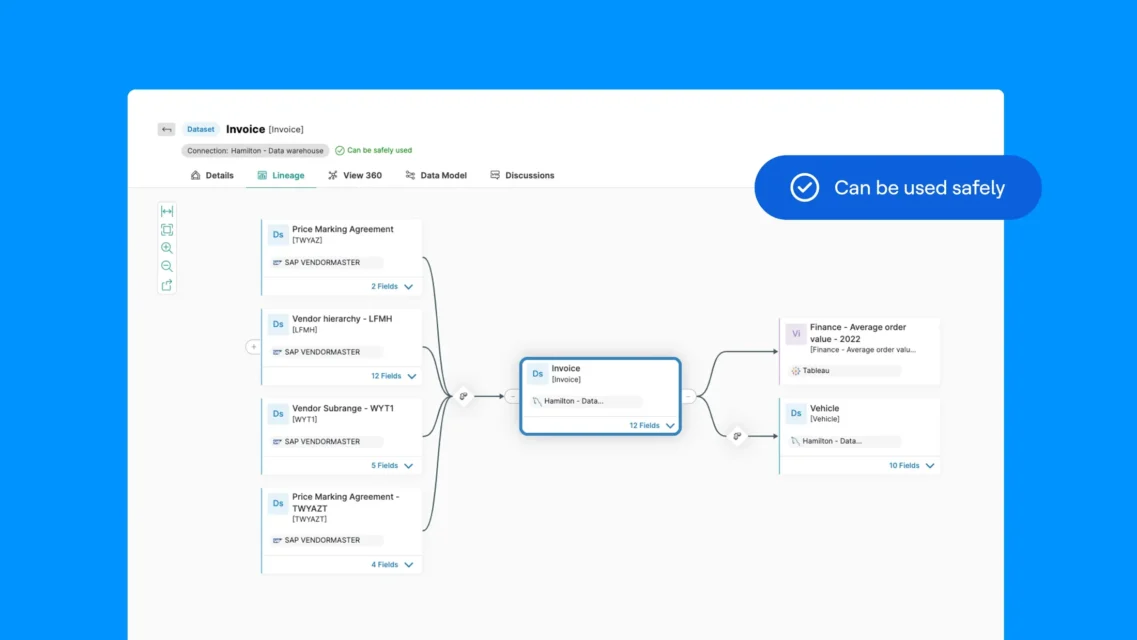
Data Lineage and Impact Analysis
Data lineage visualization represents one of the most powerful governance capabilities, showing how data flows from source systems through transformations, integrations, and analytics to final consumption points. Complete lineage answers critical questions that manual documentation struggles to address: Where did this value come from? What transformations were applied? Which reports and models depend on this dataset? If I change this table, what breaks downstream?
End-to-End Flow Visualization: Modern catalogs construct comprehensive lineage graphs spanning the entire data estate. This visibility spans technologies and platforms, showing lineage even when data crosses system boundaries.
Column-Level Lineage: For regulatory compliance and deep impact analysis, table-level lineage often isn’t sufficient. Column-level lineage tracks individual fields through transformations, showing that “annual_revenue” in a report ultimately derives from “total_sales” in the source system after currency conversion and aggregation. This granularity proves essential for privacy regulations requiring documentation of how personal data flows through systems, and for quality investigations requiring precise root cause identification.
Root Cause Analysis for Quality Issues: When data quality problems occur, lineage enables rapid investigation. If a dashboard shows incorrect values, teams trace lineage upstream through transformations to identify where errors were introduced. Was it bad source data? A logic error in the transformation code? An unexpected null value that broke calculations? Lineage cuts investigation time from days to hours by providing a roadmap directly to the problem.
ML Model Governance: As organizations deploy more machine learning models, lineage becomes essential for model governance and explainability. It documents which training data was used, how features were engineered, what preprocessing occurred, and whether any of those components have changed since model deployment. When model performance degrades, lineage helps diagnose whether the cause is data drift, concept drift, or changes in upstream data sources.
Data Product Development: Organizations building internal data products—curated datasets published for reuse across teams—rely on lineage to understand dependencies and ensure reliability. Product owners can see all upstream sources their product depends on and all downstream consumers who depend on them, enabling proper change management and SLA commitments.
Enforce Role-Based Access Controls and Security Policies
Role-based access control (RBAC) assigns permissions by role, ensuring only authorized users access sensitive data while enabling legitimate business use. In a catalog, RBAC maps job functions to specific viewing, editing, and usage rights, ensuring consistent and auditable access.
Integrating RBAC with enterprise security policies centralizes enforcement and simplifies compliance audits. Automating access decisions based on predefined rules reduces the IT burden and removes ad-hoc permission practices that create gaps. When new analysts join, they automatically receive standard analyst permissions based on their department and seniority. When employees transfer, their permissions adjust automatically. When employees leave, their access is revoked immediately across all governed systems. This automation eliminates the manual ticket-based access request process that creates delays and inconsistencies.
Advanced RBAC can be context-aware—adapting permissions by time, location, device, or purpose—balancing strict protection of sensitive information with operational flexibility for legitimate workflows.
This sophisticated approach balances strict protection of sensitive information with operational flexibility for legitimate workflows. A data scientist might access complete customer records for model training on a corporate laptop during business hours, but only see aggregated statistics on a personal device from home. A contractor might access project-specific datasets during their contract period but automatically lose access when the engagement ends.
Implement Automated Classification and Policy Enforcement
Automated classification applies algorithms and ML to label data by type, sensitivity, and regulatory requirements, enabling consistent handling across the data estate. This replaces error-prone manual tagging and ensures sensitive records (PII, financials, IP) are reliably identified.
Classifications span multiple dimensions: Data type identifies whether data is PII, PHI, financial information, intellectual property, or public information. Sensitivity level ranks data as public, internal, confidential, or restricted. Regulatory scope tags data subject to GDPR, HIPAA, PCI DSS, CCPA, or industry-specific regulations. Retention requirements specify how long data must be kept and when it should be deleted. Geographic restrictions indicate where data can be stored and who can access it based on data residency laws.
Policy enforcement uses those classifications to apply controls automatically—access restrictions, masking, retention rules, and monitoring—while continuously scanning for policy violations. The platform can flag unusual access, generate alerts, and trigger remediation workflows to reduce human error and enforcement lag.
Automated compliance reporting produces audit trails and reports (who accessed what, when, and under which controls) required for GDPR, HIPAA, and other regulations, reducing the effort and risk of manual reporting.
Maintain Audit Trails and Enable Proactive Compliance Monitoring
Audit trails record chronological actions on data assets—accesses, edits, metadata changes, and lineage updates—providing essential evidence for accountability, incident investigations, and regulatory audits. Logs capture direct and indirect usage (reports, analytics, pipelines) to support forensic analysis and risk assessment.
Proactive compliance monitoring continuously analyzes access patterns, policy adherence, and usage anomalies to detect issues before they escalate. When anomalies arise, the system can alert stakeholders, launch remediation workflows, or enforce automatic corrections depending on severity.
Advanced monitoring can offer predictive insights from historical patterns, helping teams anticipate and prevent compliance risks rather than react to them after the fact.
Facilitate Collaboration With Template-Driven Documentation
Template-driven documentation standardizes how metadata, business context, steward assignments, and policies are collected and presented, reducing variability and manual effort. Drag-and-drop and guided forms let non-technical contributors add context, business rules, and usage guidance without specialized skills.
Platforms commonly provide modules tailored to roles: studio modules for stewards to manage workflows and policies, and explorer modules for business users to discover assets and contribute domain knowledge. Templates support asset registers, glossaries, stewardship assignments, policy declarations, and usage guidelines, all with approval workflows and version control to ensure accuracy.
This structured, collaborative approach distributes documentation work, maintains quality, and ensures published information is reviewed and governed.
Best Practices for Successful Data Catalog Implementation
Implementing a catalog successfully requires addressing both technology and people. Key practices include:
- Assign Clear Stewardship: Designate owners and stewards for all major data domains with defined responsibilities for documentation, quality, and access governance.
- Develop and Maintain a Standardized Business Glossary: Align terminology across teams through authoritative definitions of business terms, metrics, and concepts. The glossary becomes the semantic foundation, ensuring everyone speaks the same language.
- Automate Metadata Synchronization: Integrate catalog updates with CI/CD and data pipeline deployments so metadata stays current automatically.
- Provide Role-Based Training: Tailor training to stewards, data engineers, analysts, and business users with practical scenarios showing catalog value for each role.
- Integrate the Catalog Into Workflows: Embed catalog capabilities where users already work so governance is embedded, not an extra step.
Organizations that apply these practices report better data visibility, faster time-to-insight, stronger auditability, and higher confidence in analytics outcomes. The catalog transforms from a compliance requirement into a strategic capability, enabling safe, rapid innovation.
How Modern Data Catalogs Differ From Traditional Catalog Tools
Traditional data catalog tools focus primarily on inventory and search. While useful, these tools often lack real-time metadata synchronization, a unified business glossary, deep lineage, embedded governance, and quality signals required for enterprise-scale analytics and AI.
Modern data catalogs operate as part of a broader data intelligence platform. They continuously collect technical, business, and operational metadata, connect lineage, observability, and business glossary definitions, and embed governance policies directly into how data is accessed and used. This shift transforms the catalog from a passive reference system into an active control and trust layer for enterprise data.
Data Catalog vs. Traditional and Point Solutions
Many organizations adopt point solutions for data cataloging, business glossaries, lineage, or data quality. While these tools address individual needs, they often create fragmented experiences that are difficult to scale.
A modern data catalog within a data intelligence platform unifies discovery, business glossary definitions, lineage, governance, and observability in a single system. This eliminates disconnected tools, reduces manual integration work, and ensures governance policies and trust signals are applied consistently across analytics and AI workflows.
Unlike standalone catalog tools, an integrated approach enables organizations to move beyond inventory toward active governance, trusted self-service, and AI-ready data at enterprise scale.
FAQ
A data catalog is a centralized metadata system that helps teams discover, understand, and govern enterprise data. It works by automatically scanning data sources, harvesting metadata, classifying sensitive information, mapping lineage, and enforcing governance policies so users can quickly find trusted data for analytics and AI.
A data catalog supports data intelligence by acting as the primary discovery and context layer that connects metadata, lineage, governance, and data quality across the enterprise.
Within a data intelligence platform, the catalog continuously collects technical, business, and operational metadata, making data assets searchable, understandable, and governed at scale. It provides visibility into ownership, usage, lineage, and trust indicators so analytics teams, AI systems, and business users can confidently select the right data for their needs.
Without a data catalog, data intelligence lacks a practical interface for discovery and adoption. The catalog ensures intelligence is not just documented, but actively used across analytics, AI, and operational workflows.
A data catalog provides the visibility and control that governance teams need. It centralizes metadata, standardizes definitions, enforces access policies, and automates compliance monitoring. This reduces risk, improves data quality, and ensures consistent governance across the entire data estate.
A data catalog solves the core challenges that prevent organizations from trusting and scaling data use. It eliminates fragmented metadata, reduces duplicate analytics work, and makes governed, high-quality data easy to find and understand.
Modern data catalogs address common issues such as inconsistent business definitions, limited lineage visibility, manual compliance processes, and low trust in analytics outputs. By centralizing metadata, lineage, governance context, and quality indicators, a data catalog enables faster decision-making, stronger compliance, and reliable AI and analytics initiatives.
Enterprise data catalogs require more than basic search and inventory. Essential features include automated metadata discovery, end-to-end lineage, role-based access controls, policy enforcement, data quality and observability signals, and support for hybrid and multi-cloud environments.
In practice, these capabilities only scale when the catalog operates as part of a broader data intelligence platform, where governance workflows, trust indicators, and business context are applied directly to how data is accessed and used across analytics and AI systems. Without this foundation, catalogs struggle to move beyond small teams or compliance-only use cases.
AI improves a data catalog by automating discovery, classification, and metadata enrichment. Machine learning identifies data patterns, detects anomalies, recommends related assets, flags quality issues, and predicts potential compliance risks. These capabilities help organizations scale governance with less manual work.
Yes. A modern data catalog plays a critical role in AI and machine learning by providing the metadata, lineage, and quality context models depend on.
AI initiatives require trusted training data, explainable feature pipelines, and visibility into how data changes over time. A data catalog enables this by documenting data origins, transformations, quality signals, and usage constraints—reducing risk, bias, and model drift while improving transparency and governance.
Open-source catalogs offer flexibility for teams that want to customize their own tooling but may require more engineering resources. Enterprise data catalogs provide built-in automation, governance workflows, security controls, scalability, support, and integration with broader data platforms—making them better suited for regulated or large-scale environments.


