Qu'est-ce qu'un pipeline de données?
Un pipeline de données est un ensemble d'étapes de traitement qui déplacent des données d'un système source à un système de destination. Les étapes du pipeline de données sont séquentielles car la sortie d'une étape est l'entrée des étapes suivantes. Le traitement des données au sein de chaque étape peut être effectué en parallèle afin de réduire le temps de traitement. La première étape du pipeline de données est généralement l'ingestion. L'étape finale est une insertion ou un chargement dans une base de données analytique.
Les pipelines de données contrôlent le flux de données en tant que processus bien défini qui soutient la gouvernance données. Ils créent également des opportunités de réutilisation lors de la construction de futurs pipelines. Les composants réutilisables peuvent être affinés au fil du temps, ce qui permet d'accélérer le déploiement et d'améliorer la fiabilité. Les pipelines de données permettent d'instrumenter l'ensemble du flux de données et de le contrôler de manière centralisée afin de réduire les frais généraux de gestion. L'automatisation du flux de données réduit également la charge de travail.
pipeline de données Exemple
Les étapes du pipeline de données varieront en fonction du type de données et des outils utilisés. Une séquence représentative des étapes d'identification des sources appropriées et des étapes du processus du pipeline de données est énumérée ci-dessous :
- Identification des données - Les catalogues de données permettent d'identifier les sources de données potentielles pour l'analyse requise. En général, le pipeline est utilisé pour alimenter un entrepôt de données spécifique, tel qu'une plateforme de données client pour laquelle les sources de données sont bien connues. Les catalogues de données contiennent également des métadonnées sur la qualité et la fiabilité des données, qui peuvent être utilisées comme critères de sélection.
- Profilage - Le profilage permet de comprendre les formats de données et de générer des scripts appropriés pour l'ingestion de données. Les données brutes doivent parfois être exportées dans un format délimité par des virgules, car l'accès direct est difficile.
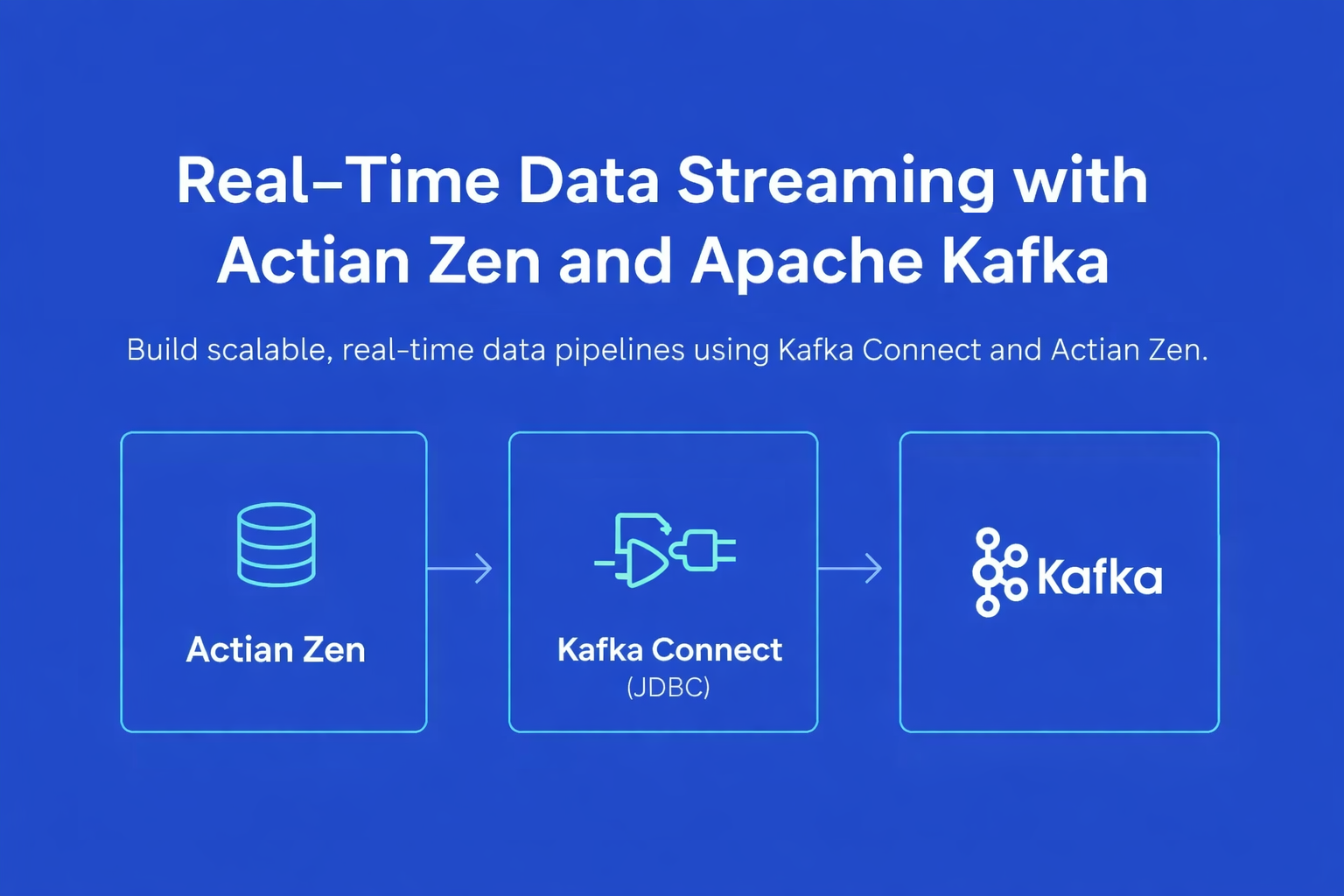
- ingestion de données - Les sources de données peuvent inclure des systèmes opérationnels, des clics sur le web, des messages sur les réseaux sociaux et des fichiers journaux. La technologie d'intégration des données peut fournir des connecteurs prédéfinis, des API par lots et streaming . Les fichiers semi-structurés peuvent nécessiter des formats d'enregistrement JSON ou XML spéciaux. L'ingestion peut se faire par lots ou par micro-lots, les enregistrements étant créés en flux.
- Normalisation - Les doublons peuvent être filtrés et les lacunes comblées par des valeurs par défaut ou calculées. Les données peuvent être triées dans l'ordre de la clé primaire, qui devient ensuite la clé naturelle d'une table de base de données à colonnes. Les valeurs aberrantes et les valeurs nulles peuvent être traitées au cours de cette étape.
- Formatage - Les données doivent être rendues cohérentes à l'aide d'un format uniforme. Les problèmes de format comprennent la façon dont les États américains sont écrits, épelés ou sous la forme d'une paire de lettres.
- Fusion - Plusieurs fichiers peuvent être nécessaires pour construire un seul enregistrement. Tout conflit doit être géré au cours de l'étape de fusion et de rapprochement des données.
- Chargement - Le dépôt analytique ou la base de données est la cible habituelle de cette dernière étape du pipeline de données . Des chargeurs parallèles peuvent être utilisés pour charger les données sous forme de flux multiples. Le fichier d'entrée doit être divisé avant un chargement parallèle afin d'éviter que le fichier unique ne devienne un goulot d'étranglement pour les performances. Un nombre suffisant de cœurs de processeur doit être alloué au chargement afin de maximiser le débit et de réduire le temps total écoulé pour l'opération de chargement.
Les éléments essentiels d'un pipeline de données robuste
Voici quelques caractéristiques souhaitables de la plate-forme technologique utilisée par le pipeline de données :
-
- déploiement hybride-cloud sur site et dans le nuage.
- Travaille avec les outils du CDC pour se synchroniser avec les sources de données.
- supportplusieurs fournisseurs de services en nuage.
- Support des formats de fichiers big data existants tels que Hadoop.
- La technologie d'intégration des données comprend des connecteurs vers les sources de données les plus courantes.
- Outils de surveillance permettant de visualiser et d'exécuter les étapes du pipeline de données .
- Traitement parallèle à chaque étape du pipeline.
- Technologie de profilage des données pour construire plus rapidement des workflows de big data.
- ETL et ELT Fonctionnalités pour que les données puissent être manipulées à l'intérieur et à l'extérieur de l'entrepôt de données cible.
- Fonctions de transformation des données.
- Génération de la valeur par défaut.
- Gestion des exceptions en cas d'échec d'un processus.
- Vérification de l'intégrité des données pour valider l'exhaustivité à la fin de chaque étape.
- Outils graphiques pour construire des pipelines.
- Facilité d'entretien.
- Chiffrement des données au repos et en vol.
- Masquage des données pour la conformité.
Avantages de l'utilisation de pipelines de données
L'utilisation d'un pipeline de données présente notamment les avantages suivants :
- Les pipelines favorisent la réutilisation des composants et le raffinement progressif.
- Permet d'instrumenter, de surveiller et de gérer le processus de bout en bout. Les étapes qui échouent peuvent alors faire l'objet d'alertes, de mesures d'atténuation et de nouvelles tentatives.
- La réutilisation accélère le développement des pipelines et la durée des tests.
- L'utilisation des sources de données peut être contrôlée de manière à ce que les données inutilisées puissent être retirées.
- L'utilisation des données peut être cataloguée, de même que les consommateurs.
- Les futurs projets d'intégration de données peuvent évaluer les pipelines existants en vue d'établir des connexions par bus ou par hub.
- Les pipelines de données favorisent la qualité et la gouvernance données.
- Des pipelines de données robustes pour des décisionsdécisions éclairées.
Pipelines de données dans Actian
Actian Data Intelligence Platform est conçue pour aider les entreprises à unifier, gérer et comprendre leurs données dans des environnements hybrides. Elle rassemble la gestion des métadonnées , la gouvernance, le lignage, le contrôle de la qualité et l'automatisation en une seule plateforme. Les équipes peuvent ainsi savoir d'où viennent les données, comment elles sont utilisées et si elles répondent aux exigences internes et externes.
Grâce à son interface centralisée, Actian offre une insight en temps réel des structures et des flux de données, ce qui facilite l'application des politiques, la résolution des problèmes et la collaboration entre les services. La plateforme aide également à relier les données au contexte commercial, ce qui permet aux équipes d'utiliser les données de manière plus efficace et plus responsable. La plateforme d'Actian est conçue pour s'adapter à l'évolution des écosystèmes de données, favorisant une utilisation cohérente, intelligente et sécurisée des données dans l'ensemble de l'entreprise. Demandez votre démo personnalisée.
Principaux enseignements

FAQ
Un pipeline de données est une série structurée de processus qui déplacent les données des systèmes sources vers des destinations telles que les bases de données, les entrepôts de données, les lacs de données ou les plateformesanalyse. Il gère l'extraction, la transformation, la validation et la livraison.
La plupart des pipelines de données comprennent l'ingestion de données, les connecteurs, la transformation (ETL/ELT), l'orchestration des workflow , les contrôles de qualité des données, les couches de stockage et la livraison des résultats aux systèmes analytiques ou opérationnels.
"L'ETL est un processus qui implique l'extraction, la transformation et le chargement d'informations. Plutôt que d'être différent des pipelines de données, le processus ETL est simplement un moyen pour un pipeline de données d'acheminer les données de la source à la destination finale.
Les principales étapes d'un pipeline de données sont la recherche, le traitement et le chargement. Il s'agit essentiellement de trouver la source d'information, de traiter cette information pour l'aligner sur la manière dont vous stockez vos données, et de transférer cette information vers sa destination.
Les innovations peuvent orienter les pipelines de données dans diverses directions. Actuellement, l'avenir anticipé comprendra une plus grande intégration de l'intelligence artificielle (IA), la décentralisation du stockage des données pour faciliter l'accessibilité et l'évolutivité, et l'introduction de modèles informatiques sans serveur.
données pour faciliter l'accessibilité et l'évolutivité rapide, et l'introduction de modèles informatiques sans serveur.