Accélérer Spark avec Actian Vector dans Hadoop





Spark est l'un des projets les plus en vogue au sein de la communauté Apache Hadoop, et Actian a le plaisir d'annoncer un connecteur Spark-Vector pour la plateforme Actian Vector in Hadoop (VectorH) qui relie les deux. VectorH fournit la solution SQL la plus rapide et la plus complète dans Hadoop, et la connexion à Spark ouvre des interfaces vers de nouveaux formats de données et de nouvelles fonctionnalités comme le streaming et l'apprentissage automatique.
Pourquoi utiliser VectorH avec Spark ?
VectorH est un système de gestion de base de données SQL analytique de de haute performance, conforme à ACID, qui exploite le système de fichiers distribués Hadoop (HDFS) ou MapR-FS pour le stockage et Hadoop YARN pour la gestion des ressources. Si vous souhaitez écrire en SQL et effectuer des tâches SQL complexes, vous avez besoin de VectorH. SparkSQL n'est qu'un sous-ensemble de SQL et doit être invoqué à partir d'un programme écrit en Scala, R, Python ou Java.
VectorH est un SGBDR mature, de niveau entreprise, avec un optimiseur de requête avancé, un support pour les mises à jour incrémentales, et une certification avec les outils bi les plus populaires. Il comprend également des fonctions de sécurité avancées et une gestion des charge de travail . Le format de données en colonnes de VectorH et la compression optimisée permettent des performances de requête plus rapides et une utilisation plus efficace du stockage que les autres formats Hadoop courants.
Pourquoi utiliser Spark avec VectorH ?
Spark offre un moteur de calcul distribué qui étend ses fonctionnalités à de nouveaux services tels que le traitement structuré, la streaming, l'apprentissage automatique et l'analyse graphique. Spark, en tant que plateforme pour le scientifique des données, permet à quiconque de travailler avec Scala, R, Python ou Java.
Ce connecteur Spark-Vector élargit considérablement l'accès de VectorH à la connectivité et aux fonctionnalités de Spark. Un cas d'usage très puissant est la capacité de transférer des données de Spark vers VectorH de manière hautement parallèle. Cette capacité ETL est l'un des cas d'utilisation les plus courants d'Apache Spark.
Si vous n'êtes pas encore un programmeur Spark, le connecteur fournit un simple chargeur de ligne de commande qui exploite Spark en interne et vous permet de charger des fichiers CSV, Parquet et ORC sans avoir à écrire une seule ligne de code Spark. Spark est un composant standard supporté par toutes les distributions Hadoop majeures, vous devriez donc être en mesure d'utiliser le connecteur en suivant les informations sur le site du connecteur.
Comment ça fonctionne
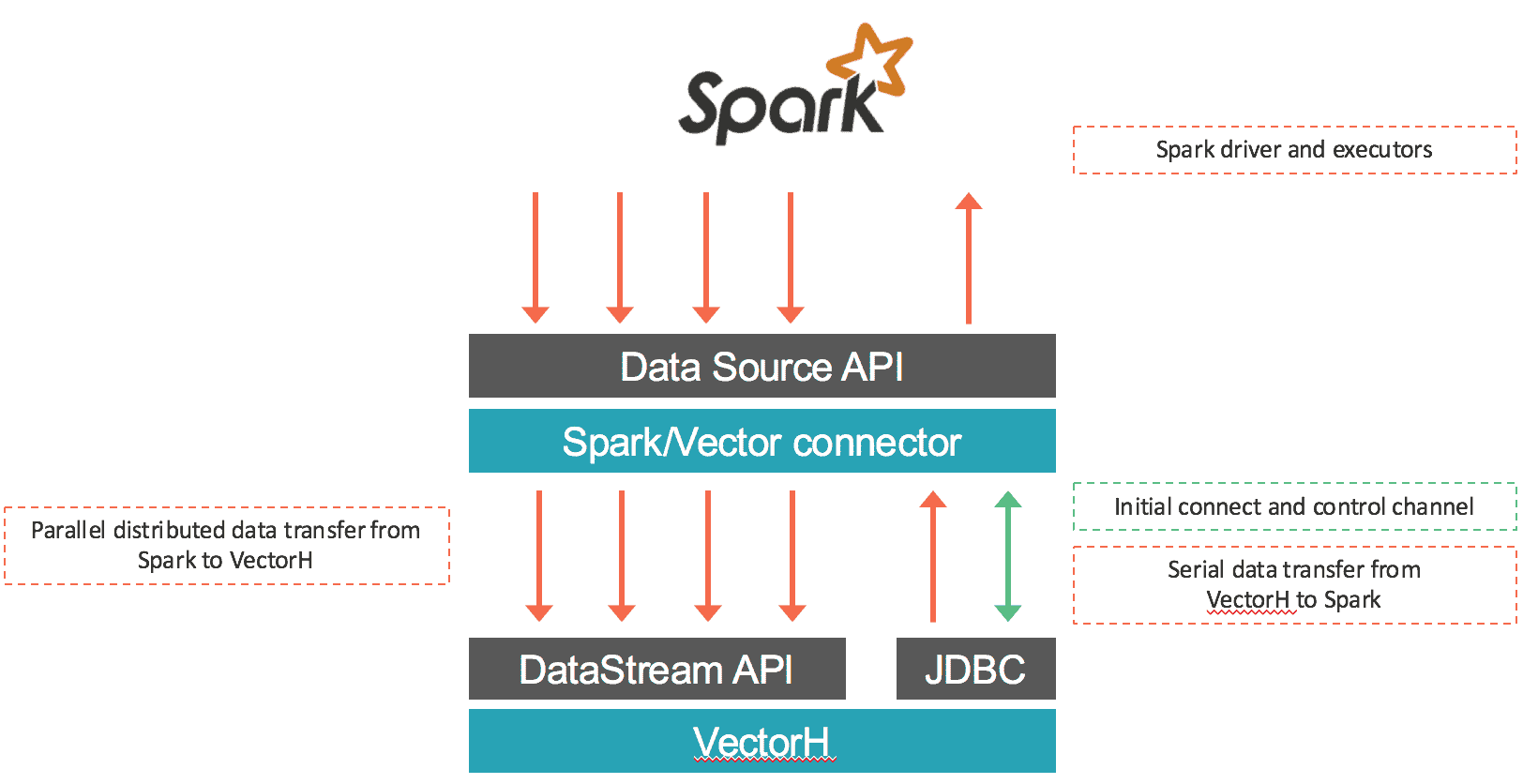
Le connecteur charge les données de Spark dans Vector et récupère les données via SQL depuis VectorH. La première partie est réalisée en parallèle : les données provenant de chaque RDD sont sérialisées à l'aide du protocole binaire de Vector et transférées via des connexions socket vers les points finaux de Vector à l'aide de l'API DataStream de Vector. La plupart du temps, ce connecteur n'attribue que des partitions RDD locales à chaque point d'extrémité de Vector afin de préserver la localité des données et d'éviter les retards dus aux communications réseau. Dans le cas de la récupération des données de Vector vers Spark, les données sont exportées de Vector et ingérées dans Spark en utilisant une connexion JDBC au nœud leader de Vector. Le connecteur fonctionne à la fois avec Vector SMP et VectorH MPP, et avec Spark 1.5.x. Une vue d'ensemble du mouvement des données est présentée ci-dessous :
Qu'y a-t-il d'autre ?
Cette dernière version de VectorH (4.2.3) comprend également les nouvelles fonctionnalités suivantes :
- support YARN sur MapR, en plus des distributions Cloudera et Hortonworks déjà certifiées. Grâce à la support native de YARN, vous pouvez exécuter plusieurs charges de travail dans le même Cluster Hadoop afin de partager l'ensemble des ressources.
- Les fichiers de profil de requête peuvent être écrits dans un répertoire spécifié, y compris un répertoire HDFS. Cette fonctionnalité offre plus de flexibilité et de contrôle pour gérer et partager les profils de requête entre différents utilisateurs.
- Nouvelles options pour afficher l'état des services du cluster, y compris l'état de base des nœuds, l'accès Kerberos s'il est activé, l'accès MPI, HDFS Safemode, et HDFS fsck.
- Une nouvelle option pour créer des index MinMax sur un sous-ensemble de colonnes ainsi qu'une gestion améliorée de la mémoire de MinMax, résultant en une réduction du processeur et de la surcharge de mémoire.
Pour en savoir plus, consultez le site https://www.actian.com/products/ ou contactez sales@actian.com pour parler à un représentant.
Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)