Buscar en vídeos de formación sin tener que verlos





Summary
- Turn training videos into searchable knowledge by transcribing audio, chunking transcripts, and indexing them as vectors.
- The system retrieves the right video moment by meaning, not exact keywords, and links directly to the timestamp.
- It uses Whisper for transcription, local embeddings, VectorAI DB for search, and a local LLM for grounded answers.
- This makes long video libraries usable for onboarding, compliance, and procedure lookups without manual scrubbing.
- The main value is fast, semantic, on-prem video search with cited answers and exact jump-to moments.
We have a folder of training videos. Onboarding walkthroughs, compliance briefings, clinical procedure demos, recorded Q&A sessions. Useful content that nobody watches because nobody has time to scrub through a 45-minute recording looking for the two minutes they actually need.
The fix is search. But video files are opaque to a database; you can’t index pixels or audio waveforms the way you index text. What you can index is what was said. Transcribe the audio, chunk it into segments with timestamps, embed each chunk, store it in Actian VectorAI DB. Now the video library is searchable by meaning, not by filename.
The screenshot below shows it working against a real collection of 678 transcript chunks. A nurse asks about hand hygiene protocol. The system finds the exact 35-second segment in the right training video and links directly to it.
The System in Action
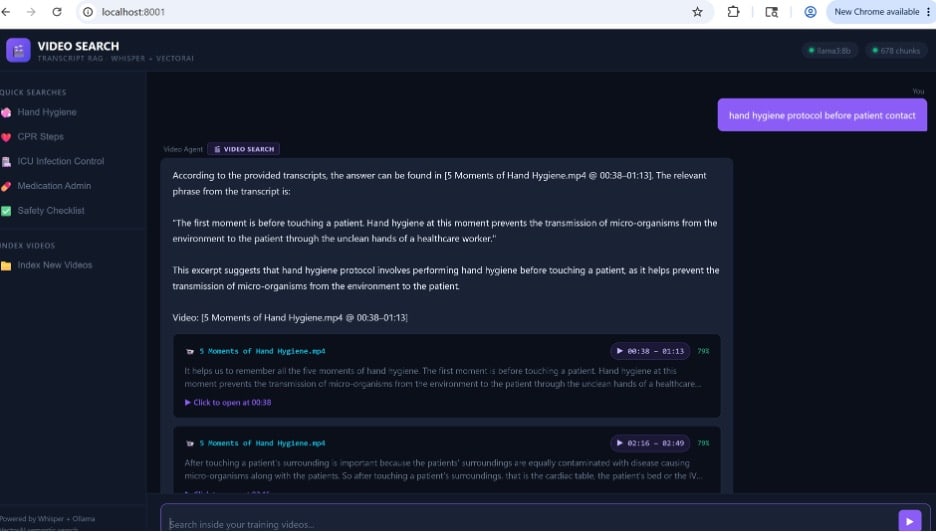
Video Search UI — query: “hand hygiene protocol before patient contact” — 678 chunks, 2 results shown
The Full Pipeline
The architecture splits into two lanes. The left lane runs offline — videos are transcribed by Whisper, chunked into 30-second segments, embedded with mxbai-embed-large, and stored in VectorAI DB once. The right lane runs at query time; the user’s question is embedded with the same model, matched against stored chunks by cosine similarity using the HNSW index, and the top results are passed to llama3:8b for a grounded, timestamped answer.
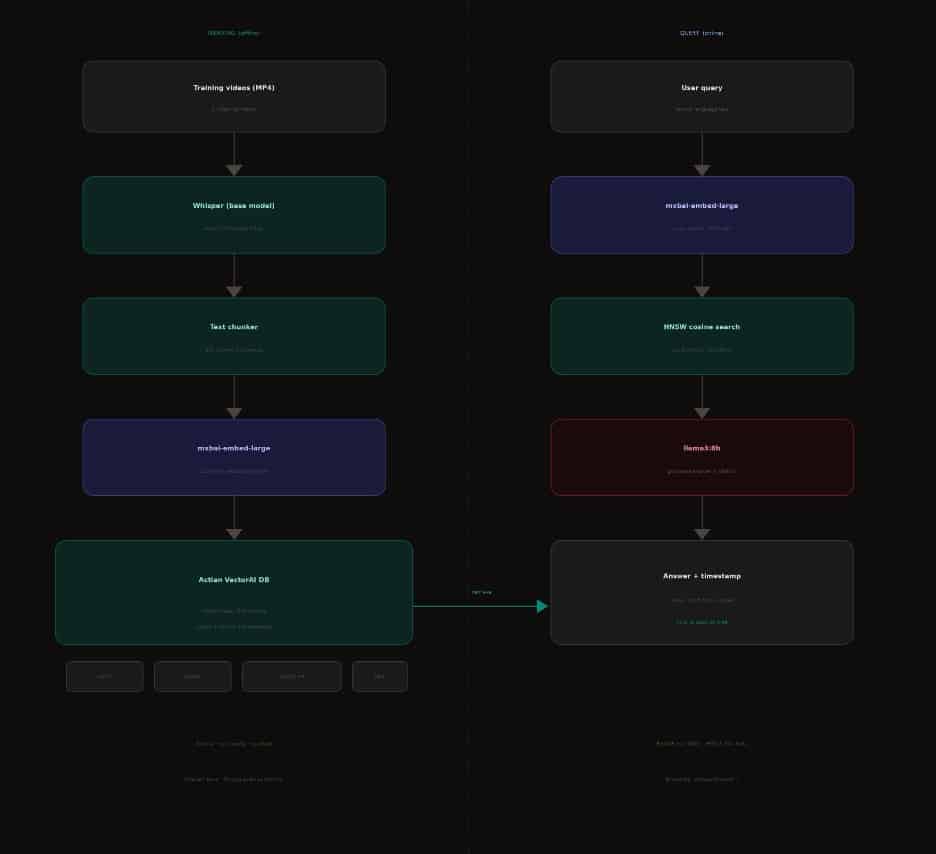
Video search architecture — indexing pipeline (left) and query pipeline (right)
What You’re Looking At
Every element in this screenshot is the direct output of the semantic search pipeline. Here’s what each part means:
| UI Element | Label | What it means |
| Top bar | 678 chunks | Total transcript segments indexed across all training videos. Each chunk is one PointStruct in VectorAI DB. |
| Top bar | llama3:8b | The LLM that synthesises the answer from the retrieved chunks. Runs locally via Ollama. |
| Sidebar | Quick Searches | Pre-set queries stored in the UI config. Clicking one runs a vector search instantly. |
| Query bubble | hand hygiene protocol before patient contact | The raw user query. This exact text is embedded by mxbai-embed-large into a 1024-dim vector. |
| Result header | VIDEO SEARCH badge | Confirms this response came from the transcript retrieval path, not a fallback. |
| Answer text | Grounded answer | The LLM’s response, generated from the retrieved transcript text — not from its training weights. |
| Citation | 5 Moments of Hand Hygiene.mp4 @ 00:38–01:13 | Exact filename and timestamp range pulled from the payload stored alongside the vector. |
| Result card | 00:38 – 01:13 | 79% | Timestamp range (start_time / end_time from payload) and cosine similarity score (0.79). |
| Transcript snippet | It helps us to remember… | The raw chunk text stored in the payload, shown as a preview so users can confirm relevance before clicking. |
| Click to open | Click to open at 00:38 | Direct link using the HTML5 #t=38 URL fragment. Opens the video at the exact second. |
| Second card | 02:16 – 02:49 | 79% | A second relevant chunk from the same video — a different moment covering a related part of the topic. |
How This Result Was Retrieved
The answer shown in the screenshot didn’t come from a keyword index or a FAQ list. It was retrieved through four distinct steps.
Step 1 — The query becomes a vector
When the user types “hand hygiene protocol before patient contact,” that text is passed to mxbai-embed-large running locally via Ollama. The model outputs a list of 1,024 floating-point numbers, a vector that encodes the semantic meaning of the query:
query = "hand hygiene protocol before patient contact"
r = requests.post('http://localhost:11434/api/embeddings',
json={"model": "mxbai-embed-large", "prompt": query})
query_vector = r.json()["embedding"] # 1024 floats
# e.g. [0.142, -0.831, 0.623, ..., -0.044]The model doesn’t know what hand hygiene is. It knows that the phrase lives near other clinical safety phrases in the high-dimensional space it was trained on. That neighborhood relationship is what the search uses.
Step 2 — VectorAI DB finds the closest chunks
The query vector is sent to Actian VectorAI DB via the Python client. The HNSW index compares it against all 678 stored transcript chunk vectors using cosine similarity and returns the top matches:
results = client.points.search(
collection_name="video_transcripts",
query_vector=query_vector,
limit=5,
with_payload=True # return text, filename, timestamps
)
# Result #1:
# id=87 score=0.79
# payload: {
# "source": "5 Moments of Hand Hygiene.mp4"
# "start_time": 38.2, "end_time": 73.6
# "start_fmt": "0:38"
# "text": "It helps us to remember all the five moments..."
# }The 79% score shown in the result card is this cosine similarity value. It means the query vector and the chunk vector point in nearly the same direction in the 1024-dimensional space, they are semantically close. No keyword matching happened. The chunk text doesn’t contain the phrase “hand hygiene protocol” — it talks about “the five moments” and “before touching a patient.” The model understood both mean the same thing.
Step 3 — The LLM synthesizes an answer
The retrieved chunk text is passed to llama3:8b as context. The LLM is instructed to answer only from the provided transcript, cite the source, and not hallucinate beyond what was said:
prompt = f"""
You are a helpful assistant. Answer using ONLY the transcript below.
Cite the video and timestamp in your answer.
Transcript:
[5 Moments of Hand Hygiene.mp4 @ 00:38-01:13]
{results[0].payload['text']}
Question: {query}
"""
response = ollama.chat(model="llama3:8b", messages=[{"role": "user", "content": prompt}])The answer shown in the screenshot — “The first moment is before touching a patient. Hand hygiene at this moment prevents the transmission of micro-organisms from the environment to the patient through the unclean hands of a healthcare worker,” is a direct quote from the transcript chunk. The LLM selected and formatted it; it didn’t invent it.
Step 4 — The UI builds the clickable timestamp link
The filename and timestamps are included in the payload stored with each vector. The UI uses the start_time value to build an HTML deep-link using the #t=seconds fragment:
p = results[0].payload
url = f"http://localhost:8001/videos/{p['source']}#t={int(p['start_time'])}"
# http://localhost:8001/videos/5 Moments of Hand Hygiene.mp4#t=38
# Browser opens the video and jumps directly to 0:38
# No scrubbing. No searching the timeline.That’s the “Click to open at 00:38” link in the result card. One click, correct moment.
The query said “hand hygiene protocol before patient contact.” The matching chunk said “the five moments of hand hygiene” and “before touching a patient.” No keywords matched. The model understood both meant the same thing.
What the Index Actually Contains
Each of the 678 chunks in the collection corresponds to a 30-second segment of a training video. The payload stored alongside every vector carries exactly what the UI needs:
| Payload field | Example value | Propósito |
| source | 5 Moments of Hand Hygiene.mp4 | Identify which video file to open |
| text | It helps us to remember all five moments… | Shown as the transcript snippet in the result card |
| start_time | 38.2 | Used to build the #t= URL fragment for deep linking |
| end_time | 73.6 | Defines the end of the result card timestamp badge |
| start_fmt | 0:38 | Human readable timestamp shown in the result card header |
Why Keyword Search Would Have Failed Here
The query was “hand hygiene protocol before patient contact.” The matching transcript chunk contains none of those exact words in combination. A keyword index, even a good one with stemming and stopword removal, would have found no match or returned a poor one.
| Keyword search | Semantic search |
| Looks for exact words or stems | Looks for similar meaning |
| “protocol” not in the chunk → no match | “five moments” ≈ “protocol” in meaning → matched |
| Returns nothing for “before touching patient” | Returns the exact segment that explains it |
| Requires manual synonym lists | Synonyms learned from training data automatically |
| Fails on paraphrase and clinical shorthand | Handles paraphrase, shorthand, and context |
User types a query. mxbai-embed-large converts it to a 1024-dim vector. VectorAI DB’s HNSW index finds the 5 closest transcript chunks by cosine similarity. The payload of each chunk carries the video filename and timestamp. The LLM reads the chunk text and generates a grounded answer citing the source. The UI builds a #t=seconds deep-link so the user can jump directly to the right moment. 678 chunks, sub-50ms retrieval, runs entirely on-premises.
All results shown are real output from the video transcript collection (678 chunks). mxbai-embed-large via Ollama 0.24.0, Whisper base model, llama3:8b, Actian VectorAI DB.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)