Is Actian VectorAI DB the Best On-Premises Pinecone Alternative?





Summary
- The main decision between Pinecone and VectorAI DB is where the vector database needs to run.
- Pinecone is better for cloud-native teams that want a mature managed service with broad SDK and ecosystem support.
- VectorAI DB is built for self-hosted, air-gapped, and fully isolated environments with no outbound dependency.
- The tradeoff is managed simplicity and ecosystem depth versus deployment control and local infrastructure ownership.
- If strict residency, compliance, or zero-connectivity rules apply, the article treats VectorAI DB as the viable option.
The decision between Pinecone and Actian VectorAI DB comes down to one question: Where does your vector database need to run? Pinecone is a cloud-only service. Its Bring Your Own Cloud (BYOC) option keeps vector data inside your Virtual Private Cloud (VPC), but its control plane still runs on Pinecone infrastructure and requires outbound connectivity. This makes it unsuitable for true air-gapped or fully isolated environments. VectorAI DB takes the opposite approach, running entirely on your own hardware with zero cloud dependency.
This is not a feature-by-feature comparison in the traditional sense. If your deployment environment requires strict data residency, air-gapped operation, or zero outbound internet access, Pinecone is structurally disqualified. No configuration or pricing tier changes that constraint.
VectorAI DB exists to serve this exact category of deployments in air-gapped environments.
For teams building cloud-native applications without sovereignty or compliance restrictions, Pinecone remains the more mature and proven managed service today. It offers a broader ecosystem, established operational tooling, and a track record in production environments.
This article compares both systems across deployment model, performance, cost, and ecosystem maturity so you can decide based on your actual constraints.
Summary Table of Pinecone vs. VectorAI DB
This table compares Pinecone and VectorAI DB across key dimensions:
| Capacidad | Piña | VectorAI DB |
| Deployment model | Cloud-only with BYOC option | Fully self-hosted on your infrastructure |
| Air-gap capable | No, requires outbound connectivity to control plane | Yes, runs with zero external connectivity |
| QPS at 1M vectors | Not publicly specified. No QPS guarantee in Pinecone SLA; 100 req/s per namespace rate limit enforced from Jan 2026 | 1,040 QPS |
| p99 latency | Not publicly specified | 12.7 ms |
| Minimum monthly cost | $50 (Standard plan minimum) | Based on vector count tiers (5K, 1M, 5M, 10M) |
| Modelo de precios | Usage-based (read units + storage) | Usage-based by number of vectors |
| SDK languages | Python, Node.js, Java, Go, .NET, Rust | Python, JavaScript |
| Compliance certifications | SOC 2, HIPAA (managed service environment) | No certifications at launch; architecture supports deployment within GDPR, HIPAA, and ISO 27001-compliant environments |
Why Does Deployment Decide This Comparison?
In regulated environments, infrastructure decisions are often dictated by compliance controls around network boundaries, external dependencies, and system ownership.
Pinecone’s BYOC model reduces data exposure by keeping vector data inside your VPC, but operational control still depends on Pinecone-managed services. Core orchestration and management functions remain tied to Pinecone’s control plane, which must stay reachable from the deployment environment.
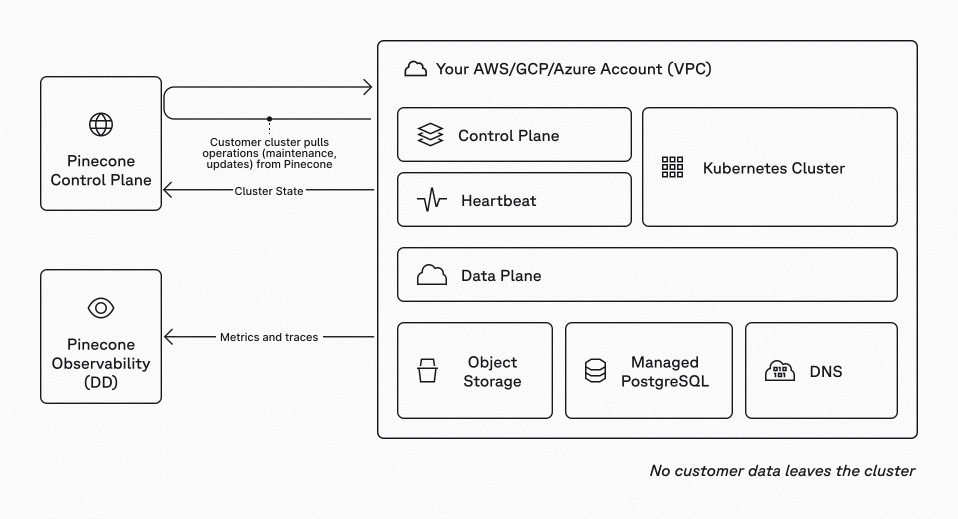
Pinecone BYOC architecture diagram
This becomes a problem in environments where external communication is prohibited or heavily restricted. This includes air-gapped systems, classified networks, and certain regulated deployments in healthcare, defense, and industrial settings. In those cases, even a minimal dependency on an externally managed control layer can become a deployment blocker during security review or compliance validation.
VectorAI DB removes this dependency entirely. It runs as a self-contained system within your infrastructure. There is no external control plane and no requirement for outbound connectivity.
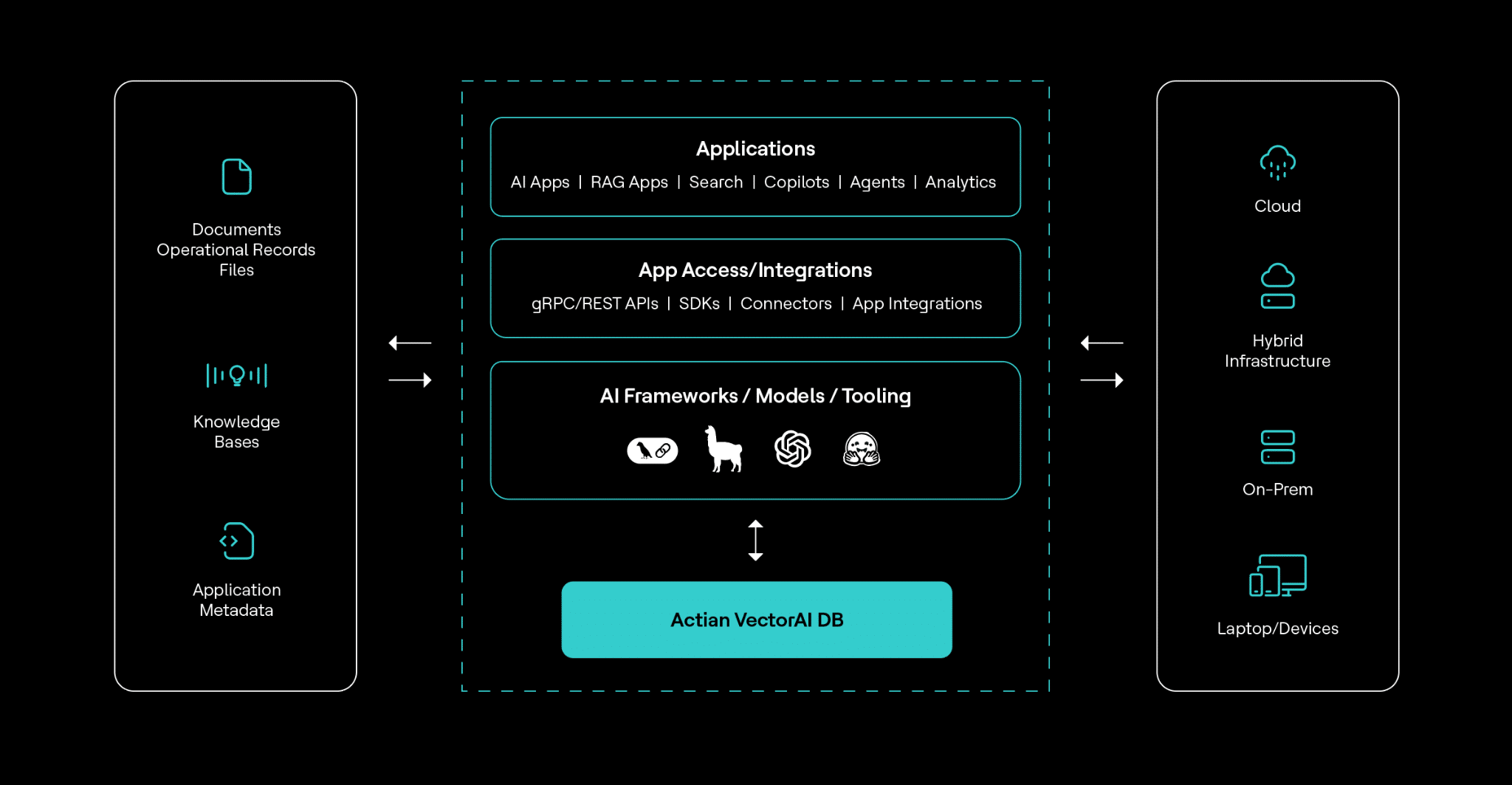
Actian VectorAI DB architecture
All vector operations, indexing, and query execution happen within your defined network boundary. This makes it suitable for environments where regulations restrict or prohibit external communication.
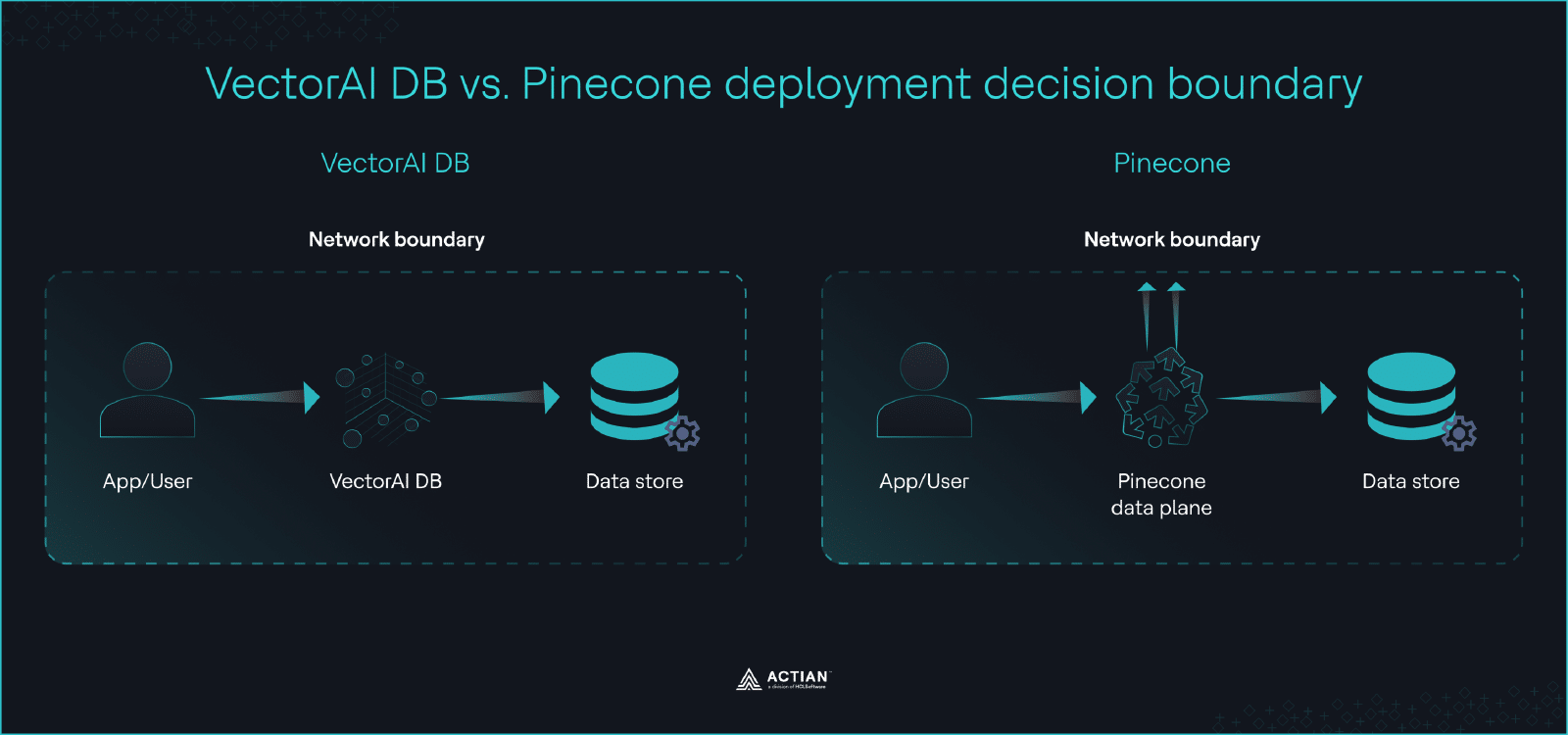
VectorAI DB vs. Pinecone deployment decision boundary
The result is a binary decision. If your deployment environment requires zero external connectivity or full infrastructure control, VectorAI DB is the only viable option between the two. If your environment allows managed services and outbound connections, then Pinecone remains in consideration and other factors like ecosystem maturity and operational overhead become relevant.
Performance at 1 Million Vectors
Performance is one of the hardest areas to compare directly between Pinecone and VectorAI DB because the two systems publish results differently. Pinecone does not publish fixed Queries Per Second or latency guarantees in its Service Level Agreement, and it does not provide standardized benchmarks at fixed dataset sizes such as one million vectors under controlled conditions. Instead, Pinecone documents performance in terms of scaling behavior, index configurations, and workload-dependent tuning.
In its own testing guidance, Pinecone emphasizes that performance depends on factors such as pod type, replicas, and query patterns rather than a single baseline number. This means there is no official Pinecone benchmark that can be directly compared to a fixed self-hosted setup without making assumptions about infrastructure size, cost, or configuration. Any direct QPS or latency comparison would be speculative.
VectorAI DB, by contrast, publishes concrete benchmark results under defined conditions. In the April, 2026 test using one million vectors at 768 dimensions, VectorAI DB achieved 1,040 queries per second with a p99 latency of 12.7 milliseconds. Load duration was 1,242 seconds, and recall reached 0.9948. The team obtained these results without vendor-specific tuning, which gives a baseline for expected performance on self-hosted hardware.
The key takeaway is not that one system is definitively faster than the other. It is that VectorAI DB provides predictable, reproducible performance characteristics tied to your hardware, while Pinecone abstracts performance behind managed infrastructure that scales based on configuration and spend.
Cost at Production Scale
Cost is where the differences between Pinecone and VectorAI DB become more visible over time. Pinecone employs a usage-based pricing model built around storage and read units. Its Standard plan starts at a minimum of $50 per month, but that entry point does not reflect real production workloads. Read units, priced per million operations, become the primary cost driver as query volume increases. This creates a direct relationship between traffic and spend, which can be difficult to predict under variable workloads.
Community benchmarks highlight how quickly these costs can scale. Engineering analysis from PE Collective reports Pinecone deployments ranging from $50 to $200 per month at around 1-10 million vectors, with some teams exceeding $500 per month for relatively modest datasets. The variability comes from query patterns, index configuration, and replication strategy. As usage grows, cost scales with both data size and query frequency, making long-term budgeting dependent on workload stability.
VectorAI DB takes a different approach. Its pricing model is based on vector count tiers, such as 5K, 1M, 5M, and 10M vectors, rather than per-query usage. You can use the pricing calculator to get an accurate estimate of your workloads. This structure makes cost more predictable because it is tied to dataset size rather than query volume. Once deployed on your infrastructure, query throughput does not directly increase licensing cost. For workloads with high query frequency, vector-tier pricing can keep costs more predictable than usage-based models.
The trade-off is operational. With VectorAI DB, you are responsible for the underlying infrastructure, including compute, storage, and scaling. Pinecone bundles this into a managed service, which simplifies operations but shifts cost into ongoing usage fees. For teams already operating on-premises or managing their own infrastructure, VectorAI DB aligns cost with existing resource planning. For teams that prefer fully managed services and are comfortable with variable spend tied to usage, Pinecone remains a viable option.
Ecosystem and Integration Maturity
Pinecone has spent years building out a broad set of SDKs, integrations, and documentation that support production use across multiple programming languages and AI workflows. It offers official SDKs for Python, Node.js, Java, Go, .NET, and Rust, along with both REST and gRPC APIs. This makes it easy to integrate into existing tech stacks, whether you are building retrieval-augmented generation pipelines, recommendation systems, or semantic search applications.
VectorAI DB enters this space with a narrower ecosystem at launch. It supports Python and JavaScript SDKs, along with REST and gRPC APIs for direct integration.
Pinecone offers a wider range of officially supported languages and has more production-hardened integrations today. VectorAI DB covers the essential integrations required to get started. For teams operating in constrained environments, this trade-off is often acceptable. For teams prioritizing rapid development and minimal integration effort, Pinecone remains the more mature option.
Code walkthrough
This code connects to a Pinecone vector database, selects an index, and performs a similarity search using a 768-dimension vector. The query() method returns the top five closest matches based on vector similarity. Semantic search, recommendation systems, and Retrieval-Augmented Generation (RAG) applications all rely on this pattern.
# Pinecone: initialize client and run a query
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
index = pc.Index("example-index")
query_vector = [0.1] * 768
response = index.query(
vector=query_vector,
top_k=5
)
print(response)Code snippet for Pinecone
This example below demonstrates how to use VectorAI DB to create a vector collection, insert vector data with metadata, and perform a similarity search. VectorAI DB compares vectors using cosine similarity, and the search returns the closest matching points along with their scores and payload information. This workflow is useful for AI-powered search, embeddings storage, and nearest-neighbor retrieval tasks.
from actian_vectorai import VectorAIClient, VectorParams, Distance, PointStruct
with VectorAIClient("localhost:50051") as client:
# Health check
info = client.health_check()
print(f"Connected to {info['title']} v{info['version']}")
# Create collection
client.collections.create(
"demo_collection",
vectors_config=VectorParams(size=128, distance=Distance.Cosine),
)
# Insert points
client.points.upsert("demo_collection", [
PointStruct(id=1, vector=[0.1] * 128, payload={"name": "Widget"}),
PointStruct(id=2, vector=[0.2] * 128, payload={"name": "Gadget"}),
PointStruct(id=3, vector=[0.3] * 128, payload={"name": "Gizmo"}),
])
# Search
results = client.points.search("demo_collection", vector=[0.15] * 128, limit=5)
for r in results:
print(f" id={r.id} score={r.score:.4f} payload={r.payload}")Code snippet for VectorAI DB
When to Choose Pinecone
There is a clear scenario where Pinecone is the better choice. If your deployment environment has no restrictions on outbound connectivity, and you prefer a fully managed service, Pinecone is the more mature and operationally simple choice. You do not need to manage infrastructure, handle scaling, or tune performance at the hardware level. This reduces operational overhead and allows teams to focus on building AI applications rather than maintaining database systems.
Pinecone is also the stronger option when ecosystem depth and production maturity matter more than deployment control. Its broader SDK support across Python, Node.js, Java, Go, .NET, and Rust makes it easier to integrate into diverse tech stacks. Pinecone’s established tooling, documentation, and community support shorten development time for teams building semantic search, recommendation systems, or retrieval-augmented generation pipelines in cloud-native environments.
Cost and performance trade-offs also play a role. For smaller workloads or early-stage projects, Pinecone’s managed model can be more efficient because it avoids upfront infrastructure investment. You can scale usage incrementally and pay based on demand. This is particularly useful for teams that expect variable traffic patterns or do not yet have stable query workloads.
Choose Pinecone when:
- You want a fully managed vector database and prefer not to operate infrastructure yourself.
- You are building cloud-native applications where outbound connectivity and managed control planes are acceptable.
- You prioritize ecosystem maturity, including broad SDK coverage and well-established integrations with AI frameworks.
- You rely on production-tested documentation, community patterns, and stable operational behavior at scale.
Not every use case requires a dedicated vector database. For teams that do need a dedicated vector database and have no deployment constraints, Pinecone remains the more proven and mature choice today.
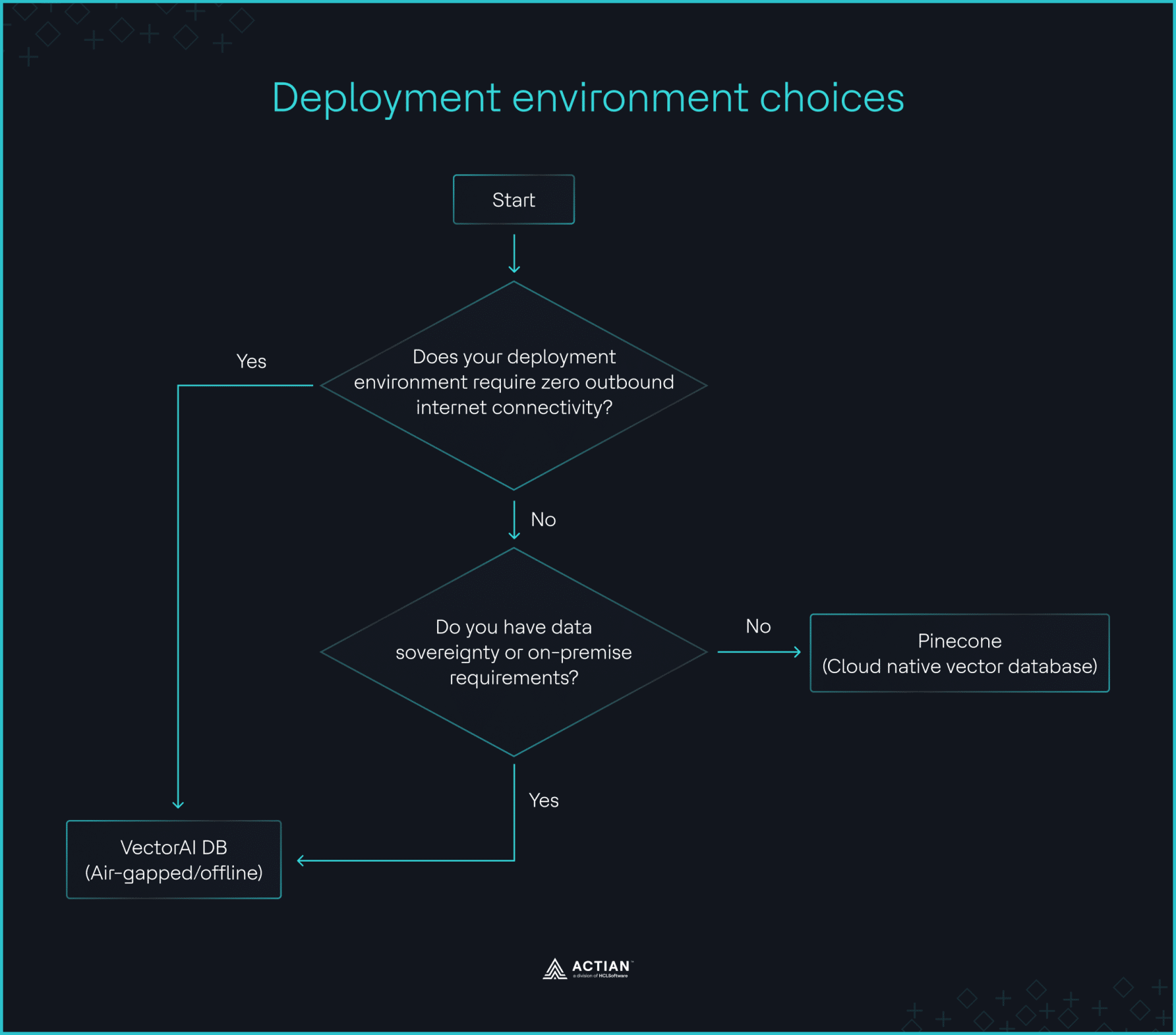
Decision flowchart for choosing between Pinecone and VectorAI DB
How Other Pinecone Alternatives Compare
Open-source vector databases such as Milvus and Qdrant offer full self-hosting with no cloud dependencies. They support high-dimensional vector search, approximate-nearest-neighbor indexing, and integrations with common AI frameworks. These systems are well-suited for teams that want control over their infrastructure without committing to a proprietary platform. The trade-off is operational overhead. You are responsible for deployment, scaling, performance tuning, and cluster management, which can become complex at production scale.
Weaviate takes a hybrid approach. It offers both a managed cloud service and a self-hosted option. This makes it attractive for teams that want flexibility between environments. It also includes built-in modules for hybrid search and machine-learning model integrations. However, even in self-hosted mode, teams must manage infrastructure and ensure operational stability, which introduces similar challenges to other open-source vector databases.
Another category includes general-purpose databases that have added vector search capabilities. PostgreSQL with the pgvector extension is the most common example. It allows teams to store vector embeddings alongside relational data and run similarity search queries within the same system. For workloads under roughly 50 million vectors, this can be a practical and cost-efficient option. It reduces infrastructure sprawl and simplifies integration with existing applications. The limitation is performance at scale, where specialized vector databases outperform general-purpose systems.
VectorAI DB positions itself differently from these alternatives. It focuses on operational simplicity in self-hosted environments. Instead of assembling and tuning multiple components, it runs as a single system with predictable performance characteristics. This makes it appealing for air-gapped, on-premises, and edge deployments where both control and simplicity matter. Compared with open-source solutions, it reduces operational overhead. Compared to Pinecone, it removes the cloud dependency entirely.
| Capacidad | Piña | VectorAI DB | Weaviate | Milvus | Cuadrante | pgvector |
| Deployment model | Cloud-only with BYOC (data plane in VPC, control plane managed externally) | Fully self-hosted | Cloud and self-hosted | Self-hosted | Self-hosted | Self-hosted |
| Air-gap capable | No | Sí | Yes (self-hosted) | Sí | Sí | Sí |
| Performance model | Managed scaling based on pods and replicas | Fixed, hardware-bound performance | Depends on deployment mode | Depends on cluster configuration | Depends on configuration | Constrained by relational engine |
| Modelo de precios | Usage-based (read units + storage) | Vector count tiers | Open source + managed pricing | Código abierto | Código abierto | Código abierto |
| SDK languages | Python, Node.js, Java, Go, .NET, Rust | Python, JavaScript | Python, JavaScript, Go, Java | Python, Go, Java | Python, JavaScript, Rust, Go | Any PostgreSQL client |
| APIs | REST, gRPC | REST, gRPC | REST, GraphQL | REST, gRPC | REST, gRPC | SQL |
| Ecosystem maturity | Alta | Early stage | Mature | Mature | Mature | Very mature |
| Operational overhead | Low (managed service) | Medium (self-managed infrastructure) | Medium to high | Alta | Medio | Low to medium |
| Best fit | Cloud-native AI workloads | Air-gapped, on-premises, edge deployments | Flexible hybrid deployments | Large-scale self-hosted systems | Lightweight self-hosted setups | Small to mid-scale workloads under ~50M vectors |
Conclusión
The decision between Pinecone and VectorAI DB is about constraints. If your environment requires zero outbound connectivity, strict data residency, or full infrastructure control, Pinecone is not an option. VectorAI DB exists for this exact scenario and provides a self-hosted path with predictable performance and cost.
If those constraints do not apply, Pinecone remains the more mature and operationally simple choice today. It offers a broader ecosystem, managed scaling, and faster time to production for cloud-native workloads.
If your team falls into the first category, sign up for the Actian VectorAI DB Community Edition and start building today. You can find implementation details in the VectorAI DB documentation, and connect with the community on Discord to learn more and get support.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)