Die Verwaltung von Daten für eine zeitnahe Entscheidungsfindung ist eine Herausforderung. Die Datenmenge wächst kontinuierlich und wird in verschiedenen Formaten bereitgestellt. Es gibt nach wie vor viele Datensilos, deren Daten integriert werden müssen. Es gab bereits Versuche, eine zentrale Datenquelle Daten, Informationen und Wissen zu schaffen, die das Unternehmen organisationsweit gemeinsam nutzen kann. Frühe Anwendungsbeispiele finden sich in der Funktionsweise von ERP-Systemen, die mehrere Funktionsbereiche eines Unternehmens abdecken. Dies reicht jedoch aufgrund des Wachstums und der Nutzung von Daten für verschiedene Datenverbraucher nicht aus.
Was ist die Data-Hub-Architektur?
Data-Hub-Architekturen sind eine Sammlung von Daten und Informationen aus mehreren unterschiedlichen Quellen für spezifische Verbraucherentscheidungen. Die gesammelten Daten können sich überall und in jedem Format befinden. Der Hub verarbeitet die erforderlichen Daten und hilft dabei, das Datenrauschen zu beseitigen und die Leistung für Entscheidungen zu verbessern. Die Daten werden effizient, effektiv und wirtschaftlich integriert und organisiert, um funktionale Geschäftsergebnisse zu unterstützen.
Datenhubs können Daten aus verschiedenen Quellen, wie beispielsweise Data Lakes, verarbeiten. Die Gestaltung der Datenhub-Architektur hängt davon ab, dass man die Nutzer der Daten und die zu treffenden Entscheidungen sowie die Datenquellen selbst versteht und weiß, wie diese im Hinblick auf die geschäftlichen Anforderungen miteinander in Beziehung stehen – im Wesentlichen also die Unterstützung von Geschäftsentscheidungen über funktionale Einheiten hinweg.
Die Data-Hub-Architektur muss die Wertschöpfungskette zwischen allen Funktionen und den Datenübergängen zwischen diesen Funktionen berücksichtigen, einschließlich automatisierter Datenentscheidungsprozesse, Fähigkeiten künstlicher Intelligenz (KI) und Maschinelles Lernen ML) stattfinden. Der letztendliche Nutzen lässt sich anhand von vier spezifischen Bereichen für die bereitgestellten, unterstützten und genutzten Dienste und Produkte darstellen. Diese vier Bereiche beziehen sich auf Entscheidungen in den Bereichen Innovation, Wachstum, Kundenbetreuung und Wettbewerbsanforderungen des Unternehmens.
Open-Data-Hubs tragen dazu bei, die unterschiedlichen Anforderungen an den Datenzugriff zu erfüllen, die verschiedene Personen innerhalb der Organisation haben. Da jede Funktion und Rolle Daten auf unterschiedliche Weise nutzt,
und manchmal auf dieselbe Weise. Ein Open-Data-Hub unterstützt zudem den Einsatz vonCloud sowie die Zusammenarbeit und Integration zwischen verschiedenen Fachteams. Dies gilt insbesondere für die Zusammenarbeit zwischen Entwicklern, Datenwissenschaftlern und Dateningenieuren.
Datenintegrations-Hub-Architekturen helfen dabei, über den Daten-Hub multiple data zu verbinden, unabhängig davon, wo sie sich befinden, z. B. in der Cloud oder On-Premises. Dies hilft dabei, spezifische Systeme der Aufzeichnung zu erstellen, die für bestimmte Anwendungen der Daten benötigt werden.
Arten der Datendrehscheibenarchitektur
Data-Hub-Architekturen ermöglichen den Austausch von Daten, Informationen und Wissen durch die Zusammenarbeit zwischen bestimmten Datenproduzenten und bestimmten Datenkonsumenten. Dies sollte kunden- oder verbraucherorientiert erfolgen, damit die gesammelten Daten dem Kunden der Daten zugute kommen. Kundendaten-Hub-Architekturen sollten als der Ansatz betrachtet werden, der den Lebenszyklus von Kundendaten für eine intelligente Entscheidungsunterstützung im Unternehmen ermöglicht. Die Kundendatendrehscheibe sollte als Epizentrum für das Verständnis und die Reaktion auf Kundenbedürfnisse betrachtet werden.
Die Architekturen von Datendrehscheiben basieren auf den Datenmustern, die die Datenkonsumenten benötigen. Die Architektur einer Datendrehscheibe kann von Drehscheibe zu Drehscheibe unterschiedlich sein, je nach Dateninput und Datenkonsumenten. Obwohl sie einem grundlegenden Konstrukt wie Hub und Spoke folgt, kann jede Architektur sehr unterschiedlich sein, was die Art und Weise betrifft, wie die Daten für die Nutzung aufbereitet werden. Es werden nicht alle Datenquellen in den Hub kopiert, sondern nur die, die für Verbraucherentscheidungen benötigt werden.
Data Warehouse mit Nabe und Speiche vs. Bus-Architektur
Bei der Hub-and-Spoke-Datenarchitektur handelt es sich im Grunde um einen zentralisierten Ansatz zur Verbindung der Datendrehscheibe mit mehreren Eingängen oder Datenanbietern für verschiedene Datenkonsumenten. Ein Hub kann mit einer Spoke- oder einer Bus-Architektur erstellt werden. Eine Bus-Architektur wird verwendet, um ein Data Warehouse zu erstellen, das einem Hub ähnelt, aber die Daten haben keine Standardreferenz in Bezug auf die Datenkonsumenten. Spoke-Architekturen haben in der Regel den Hub als zentralen Punkt für Daten und sind daher oft der Standardbezugspunkt. In Anwendungsfällen, in denen eine strenge Kontrolle und Steuerung erforderlich ist, neigen Unternehmen dazu, Spoke- statt Bus-Architekturen zu verwenden. Der Bus kann alle Arten von Daten enthalten, aber die Anwendungen sind die Hauptquelle der Daten, die aus der großen Bus-Warehouse-Architektur zu extrahieren sind. Die Hub-and-Spoke-Architektur für den Data Hub ist explizit für die Verbraucher konzipiert. Hub und Spoke werden aufgrund der Spezifität der im Data Hub enthaltenen Daten als schneller angesehen.
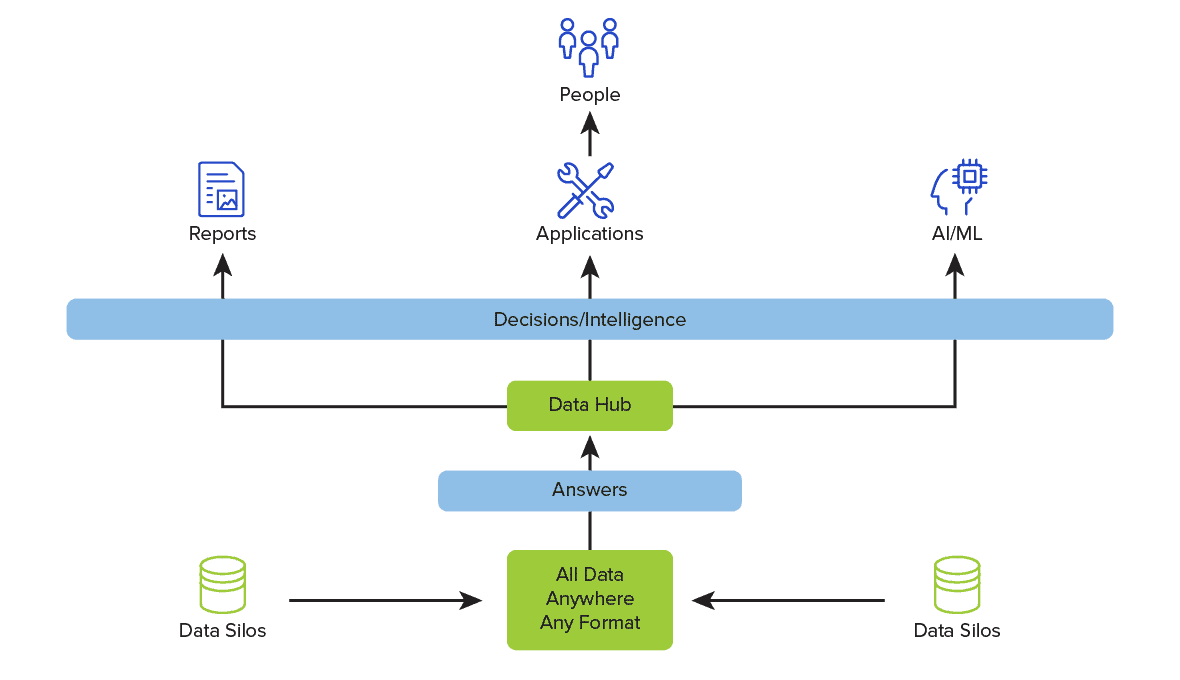
Diagramm zur Architektur der Datendrehscheibe
Das folgende Diagramm der Daten-Hub-Architektur zeigt eine einfache Hub-and-Spoke-Perspektive zwischen den Daten und den Datenverbrauchern. Die Architektur kann multiple data enthalten, die für den Zweck der Datenkonsumenten geeignet sind. Dies fördert die Leistung und das allgemeine Verständnis dafür, wie die Daten für die Entscheidungsfindung innerhalb des Unternehmens genutzt werden.
Die Eingaben für die Datendrehscheibe können aus Data Warehouses, XML, JSON, Sharepoints, anderen Datensilos und von jedem anderen Ort stammen, an dem sich Daten befinden. Entscheidend ist dabei, dass beim Aufbau einer Datendrehscheibe die Datenauswahl, die für die Entscheidungen der Verbraucher benötigt wird, genau festgelegt wird. Andernfalls würde eine zu große Datenmenge, die verwalten muss, die Leistung beeinträchtigen und die Komplexität erhöhen.
Daten liefern Antworten in Form der Daten selbst oder einer Umwandlung mit anderen Daten in Informationen und Wissen für den Verbraucher der Daten. Bei den Datenkonsumenten kann es sich um Menschen oder automatisierte Quellen handeln, wie z. B. beim Maschinelles Lernen und der künstlichen Intelligenz. In jedem Fall sollte sich das Unternehmen darüber im Klaren sein, dass die Anwendung einer Datendrehscheibe eine Initiative zur kontinuierlichen Verbesserung ist, um leistungsstarke Geschäftsergebnisse zu unterstützen.
Actian und die Data Intelligence Platform
DieActianData Intelligence Platformwurde speziell entwickelt, um Unternehmen dabei zu unterstützen, ihre Daten in hybriden Umgebungen zu vereinheitlichen, verwalten und zu verstehen. Sie vereint Metadaten , Governance, Datenherkunft, Qualitätsüberwachung und Automatisierung auf einer einzigen Plattform. So können Teams nachvollziehen, woher Daten stammen, wie sie genutzt werden und ob sie internen und externen Anforderungen entsprechen.
Über seine zentralisierte Schnittstelle ermöglicht Actian Erkenntnis Datenstrukturen und -flüsse, wodurch die Umsetzung von Richtlinien, die Behebung von Problemen und die abteilungsübergreifende Zusammenarbeit vereinfacht werden. Die Plattform hilft zudem dabei, Daten mit dem geschäftlichen Kontext zu verknüpfen, sodass Teams Daten effektiver und verantwortungsbewusster nutzen können. Die Plattform von Actian ist darauf ausgelegt, mit sich entwickelnden Datenökosystemen mitzuwachsen und eine konsistente, intelligente und sichere Datennutzung im gesamten Unternehmen zu unterstützen.Fordern Sie Ihre persönliche Demo an.
Diagramm zur Architektur der Datendrehscheibe