Integration von Actian Zen und Apache Kafka mithilfe von Kafka Connect (JDBC)




Zusammenfassung
- Erstellen Sie eine Datenpipeline in Echtzeit, Datenpipeline Streaming Zen-Daten mithilfe von JDBC-Source- und Sink-Konnektoren an Apache Kafka Streaming .
- Quelltabellen, die nur angehängt werden können, und idempotente Upserts ermöglichen Streaming Handelsereignissen niedrige Latenz, das wiederholbar und für Audits geeignet ist.
- Avro mit Schema Registry gewährleistet eine strenge Schema-Governance und eine sichere Weiterentwicklung für Workloads im Finanzbereich.
- Diese Architektur modernisiert Batch-Systeme zu StreamingLösungen, ohne die operativen Datenbanken zu ersetzen.
Moderne Finanzsysteme basieren nicht mehr auf nächtlichen Batch-Verarbeitungen oder periodischen ETL-Jobs. Preisberechnungsmodule, Handelserfassungssysteme, Risiko-Dashboards und Compliance-Plattformen sind alle auf kontinuierliche Ereignisströme angewiesen, die mit geringer Latenz, hoher Zuverlässigkeit und vollständiger Beobachtbarkeit verarbeitet werden müssen.
Gleichzeitig setzen viele Unternehmen bereits auf bewährte operative Datenbanken, um Transaktionsdaten zu speichern und geschäftskritische Anwendungen zu betreiben. Ein Austausch dieser Systeme kommt selten in Frage.
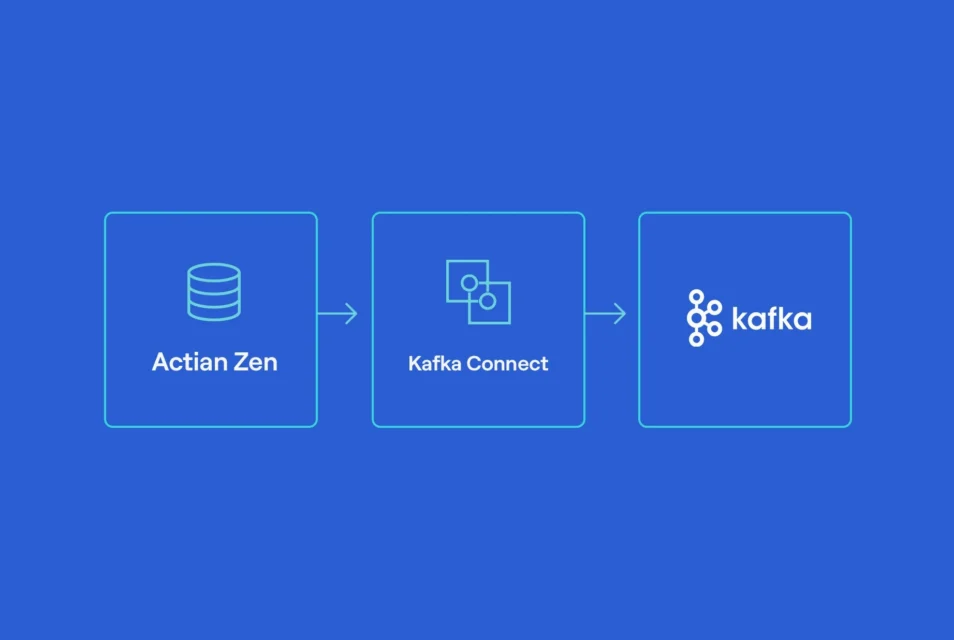
Diese technische Anleitung zeigt, wie Actian Zen und Apache Kafka zusammenarbeiten können, um eine robuste Datenpipelinezu bilden – ohne Anwendungen neu zu schreiben oder komplexen benutzerdefinierten Code einzuführen. Mithilfe der Kafka Connect JDBC-Source- und Sink-Konnektoren streamen wir finanzhandelsähnliche Daten von Zen nach Kafka und zurück nach Zen und schaffen so ein wiederverwendbares Architekturmuster, das für reale Finanz-Workloads geeignet ist.
Warum Streaming in der Finanzbranche Streaming
Finanzdaten weisen eine Reihe einzigartiger Merkmale auf:
- Zeitkritikalität: Veraltete Daten können Entscheidungen ungültig machen.
- Burstiness: Marktöffnung/-schluss und Volatilität verursachen Spitzenwerte.
- Strenge Korrektheit: Duplikate oder fehlende Ereignisse sind nicht zulässig.
- Nachprüfbarkeit: Teams müssen vergangene Entscheidungen nachvollziehen und erläutern können.
Herkömmliche Batch-Architekturen haben mit diesen Anforderungen zu kämpfen. Im Gegensatz dazu behandeln Streaming jede Aufzeichnung unveränderliches Ereignis und ermöglichen es nachgelagerten Systemen, nahezu in Echtzeit zu reagieren.
Kafka hat sich zum Rückgrat ereigniszentriert entwickelt, doch Kafka allein löst das Problem der Datenbankintegration nicht. Kafka Connect schließt diese Lücke, indem es Daten zwischen Datenbanken und Kafka mithilfe von Konfigurationen statt mit benutzerdefiniertem Code überträgt.
Was wir entwickeln
Diese Pipeline veranschaulicht, wie finanzhandelsähnliche Daten aus einer operativen Zen-Datenbank in Kafka gestreamt und anschließend mithilfe von JDBC-Source- und Sink-Konnektoren wieder in eine nachgelagerte Zen-Tabelle geschrieben werden können:
Der Ablauf ist wie folgt:
- Ein Python generiert synthetische Handelsdaten.
- Jeder Datensatz wird in eine Zen-Quelltabelle (FinanceSource) eingefügt.
- Ein Kafka Connect JDBC Konnektor neue Zeilen schrittweise Konnektor .
- Die Datensätze werden als Avro-Nachrichten an Kafka gesendet (die Schema Registry verwaltet die Schemata).
- Ein Kafka Connect JDBC-Sink Konnektor das Thema.
- Die Datensätze werden in eine Zen-Sink-Tabelle (Finanzen) eingefügt oder aktualisiert.
Dieses Muster lässt sich direkt auf Dateneingang, die Handelsreplikation, Streaming und das operative Berichtswesen übertragen.
Ein Blick auf die Architektur
Auf einer übergeordneten Ebene besteht die Architektur aus drei Schichten:
- Datengenerierung und operative Speicherung: Actian Zen speichert eingehende Handelsdaten.
- Streaming : Kafka bietet ein dauerhaftes, wiedergabefähiges Ereignisprotokoll.
- Integration und Bereitstellung: Kafka Connect liest aus Zen und schreibt zurück nach Zen.
Ein zentrales Entwurfsprinzip ist die Entkopplung: Produzenten sind nicht von Konsumenten abhängig, und die Datenbank bleibt das Aufzeichnung.
Datenmodellierung in der Praxis
Das Schema-Design ist von grundlegender Bedeutung. In dieser Demonstration werden zwei Zen-Tabellen mit klar definierten Rollen verwendet:
Quelltabelle: FinanceSource (nur zum Anfügen)
CREATE TABLE FinanceSource ( id IDENTITY PRIMARY KEY, symbol VARCHAR(16) NOT NULL, trade_date DATE NOT NULL, trade_time TIME NOT NULL, price DECIMAL(18,6) NOT NULL, volume INTEGER NOT NULL, bid DECIMAL(18,6), ask DECIMAL(18,6), exchange VARCHAR(16), currency VARCHAR(8) DEFAULT 'USD', recorded_at TIMESTAMP NOT NULL );
Zwei Spalten sind für Streaming besonders wichtig:
- id bietet einen stabilen, inkrementierenden Cursor.
- recorded_at liefert den Zeitpunkt des Ereignisses und ermöglicht sicheres inkrementelles Lesen.
Sink-Tabelle: Finanzen (aktualisierter Stand)
CREATE TABLE Finance ( id INTEGER PRIMARY KEY, symbol VARCHAR(16), trade_date DATE, trade_time TIME, price DECIMAL(18,6), Volumen INTEGER, Geldkurs DECIMAL(18,6), Briefkurs DECIMAL(18,6), Börse VARCHAR(16), Währung VARCHAR(8), Erfasst_am TIMESTAMP );
Das Waschbecken verwendet „id“ als Primärschlüssel, was idempotente Upserts während der Wiedergabe oder des Neustarts ermöglicht.
Handels-Ticks mit Python generieren
Der Generator simuliert einen Live-Marktfeed, indem er Aufzeichnung zwei Sekunden eine neue Aufzeichnung einfügt. Jedes Ereignis enthält Symbol, Kurs, Geld-/Briefkurs, Volumen, Börse, Währung und Zeitstempel.
Die Generatorfunktion erzeugt realistische Marktdaten:
def gen_tick(): symbol = random.choice(SYMBOLS) price = round(random.uniform(10, 1500), 6) spread = round(random.uniform(0.01, 0.50), 6) bid = round(price - spread/2, 6) ask = round(price + spread/2, 6) vol = random.randint(1, 5000) now = datetime.now() return { "symbol": symbol, "trade_date": date.today(), "trade_time": now.time().replace(microsecond=0), "price": price, "volume": vol, "bid": bid, "ask": ask, "exchange": random.choice(EXCHANGES), "currency": CURRENCY, "recorded_at": now, }
INSERT-Anweisung:
sql = """ INSERT INTO FinanceSource ( symbol, trade_date, trade_time, price, volume, bid, ask, exchange, currency, recorded_at ) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) """
Dieser „Append-only“-Ansatz passt gut zu Kafka: Jede Zeile ist ein unveränderliches Ereignis, das gestreamt, wiedergegeben und von mehreren nachgelagerten Diensten verarbeitet werden kann.
Streaming → Kafka mit dem JDBC-Source Konnektor
Konnektor JDBC-Source Konnektor von Kafka Connect Konnektor FinanceSource Konnektor und veröffentlicht Nachrichten in Kafka.
Themenabbildung:
- Konnektor : Demo
- Themen-Präfix: Finanzen.
- Thema: Finanzen.FinanceSource
Inkrementalmodus:
"mode": "timestamp+incrementing", "timestamp.column.name": "recorded_at", "incrementing.column.name": "id", "poll.interval.ms": "2000"
Dieser Modus liest nur neue Zeilen, vermeidet vollständige Durchläufe und unterstützt sichere Neustarts. Durch die Abfrage alle zwei Sekunden bleibt die Latenz gering, ohne unnötige Last zu verursachen. Bei Demo moderaten Workloads sorgt die Abfrage alle zwei Sekunden zudem für ein ausgewogenes Verhältnis zwischen Latenz und Last; in der Produktion sollte dies entsprechend der Häufigkeit von Zeileneinfügungen und der Datenbankkapazität angepasst werden.
Vollständige Konnektor von Source Konnektor :
"Konnektor.class": "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url": "jdbc:pervasive://host.docker.internal:1583/DEMODATA", "dialect.name": "ZenDatabaseDialect", "mode": "timestamp+incrementing", "timestamp.column.name": "recorded_at", "incrementing.column.name": "id", "table.whitelist": "FinanceSource", "topic.prefix": "finance.", "poll.interval.ms": "2000", "value.converter": "io.confluent.connect.avro.AvroConverter"
Avro und Schema-Registry für die Schema-Governance
Finanzschemata entwickeln sich weiter: Neue Kennzahlen, neue Identifikatoren oder angepasste Genauigkeitswerte kommen zum Einsatz. Avro mit Schema Registry bietet starke Typisierung, zentralisierte Versionierung und Kompatibilitätsprüfungen.
Konnektor :
"value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "http://schema-registry:8081"
Bei dieser Konfiguration werden Schemata automatisch registriert, und die Verbraucher können im Laufe der Zeit sicher weiterentwickelt werden. Die Schema Registry ist nur bei der Verwendung von Avro (oder Protobuf/JSON Schema) erforderlich; für schlankere Demos können JSON-Konverter verwendet werden, wobei jedoch Abstriche bei der Schema-Governance gemacht werden müssen.
Kafka → Zen mit dem JDBC-Sink Konnektor Upsert)
Der Sink Konnektor das Kafka-Topic Konnektor und schreibt die Daten in die Tabelle „Finance“.
Upsert-Konfiguration:
"topics": "finance.FinanceSource", "table.name.format": "Finance", "insert.mode": "upsert", "pk.mode": "Aufzeichnung", "pk.fields": "id", "auto.create": "false", "auto.evolve": "true"
Upsert ist eine gute Standardwahl, da Neustarts und Wiederholungen idempotent bleiben und nachträglich eintreffende Korrekturen bestehende Schlüssel aktualisieren können.
Deployment Orchestrierung
Alle Kafka-Komponenten laufen in Docker: Kafka-Broker, Schema Registry, Kafka Connect und Kafka-UI (Kafbat / AKHQ-kompatibel). Actian Zen läuft auf dem Host.
Ein einziges Orchestrierung startet den Stack, initialisiert Tabellen, erstellt Konnektoren und startet den Generator. Dieses Modell DemoEin-Befehl Demoeignet sich gut für Training, Proofs of Concept und wiederholbare Tests.
Endpunkte, die üblicherweise bei der Validierung verwendet werden:
- Kafbat-Benutzeroberfläche: http://localhost:8080
- Kafka Connect REST: http://localhost:8083
- Schema-Register: http://localhost:8081
Betriebsvalidierung
So überprüfen Sie den gesamten Ablauf:
- Vergewissern Sie sich, dass der Generator alle zwei Sekunden neue Ticks ausgibt.
- Überprüfen Sie Konnektor über Kafka Connect REST.
- Nachrichten im Bereich Thema „finance.FinanceSource“ Thema.
- Die Zen-Sink-Tabelle abfragen Finanzen.
Statusabfragen:
curlDemo curlDemo
Wenn etwas schiefgeht, liefern die Kafka-Connect-Protokolle in der Regel am schnellsten Aufschluss: fehlende JDBC-JAR-Dateien, Dialektprobleme oder Authentifizierungsprobleme.
Überlegungen zur Produktion
Diese Demo bewusst einfach gehalten, aber die Architektur lässt sich gut skalieren. Beachten Sie in der Produktion Folgendes:
- TLS und Authentifizierung für Kafka und Connect.
- Themenaufteilung zur Parallelisierung (z. B. nach Symbolen).
- Dead-Letter-Warteschlangen für problematische Datensätze.
- Durchsetzung der Schemakompatibilität in der Schema-Registry.
- Multi-Worker-Connect-Cluster für hohen Durchsatz und Ausfallsicherheit.
- Überwachung (Prometheus/Grafana).
Das Kernmuster – ausschließliches Hinzufügen an der Quelle + inkrementelle Abfrage + Avro + idempotente Upserts am Ziel – bleibt eine solide Grundlage.
Machen Sie einen visuellen Rundgang
Die folgenden Screenshots veranschaulichen den Ablauf der Pipeline, von der Datengenerierung über Kafka bis hin zur endgültigen Sink-Tabelle:
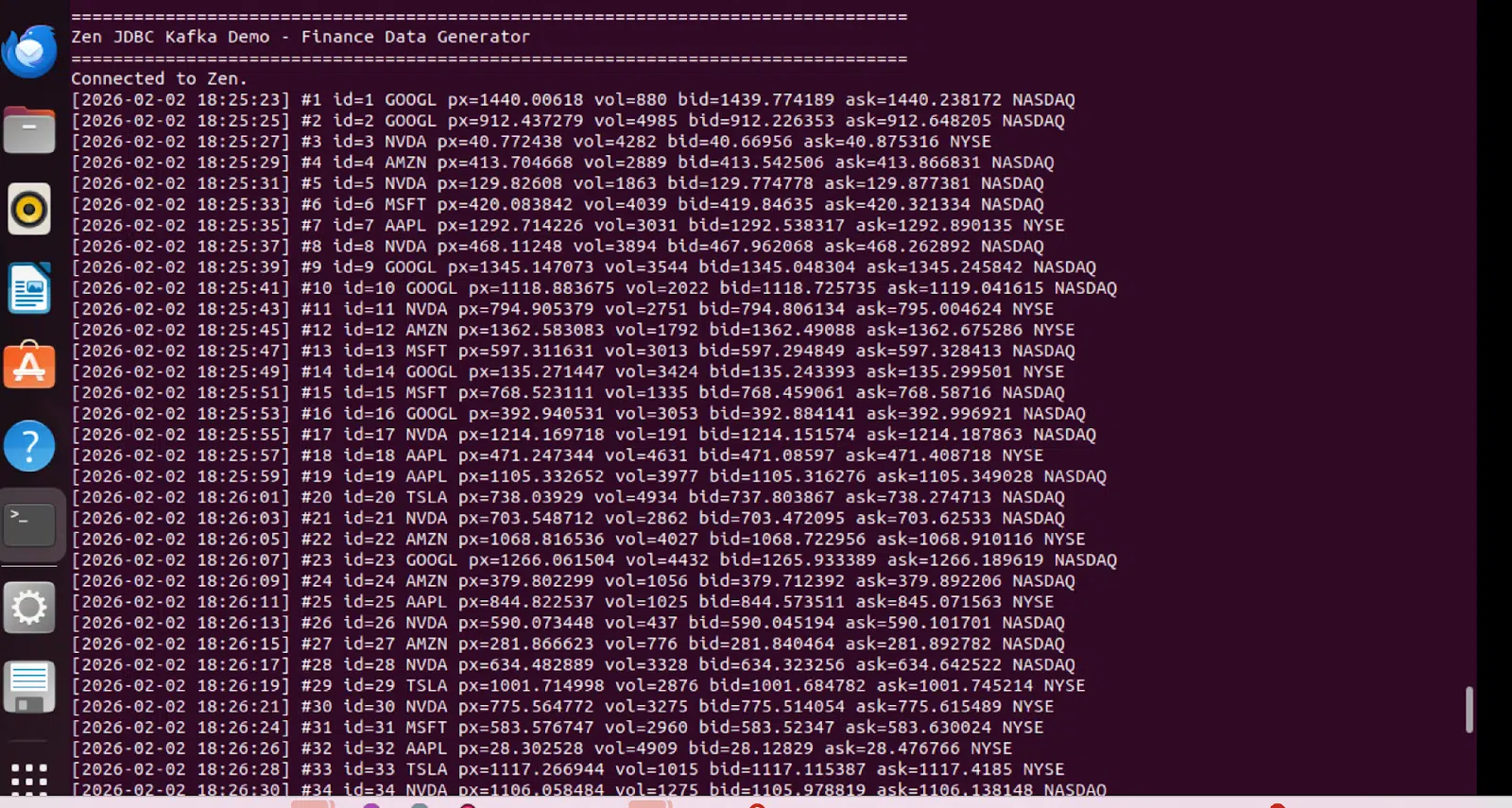
Ausgabe des Datengenerators
Der Python erzeugt alle zwei Sekunden kontinuierlich synthetische Handelsdaten und simuliert so Live-Marktdaten:
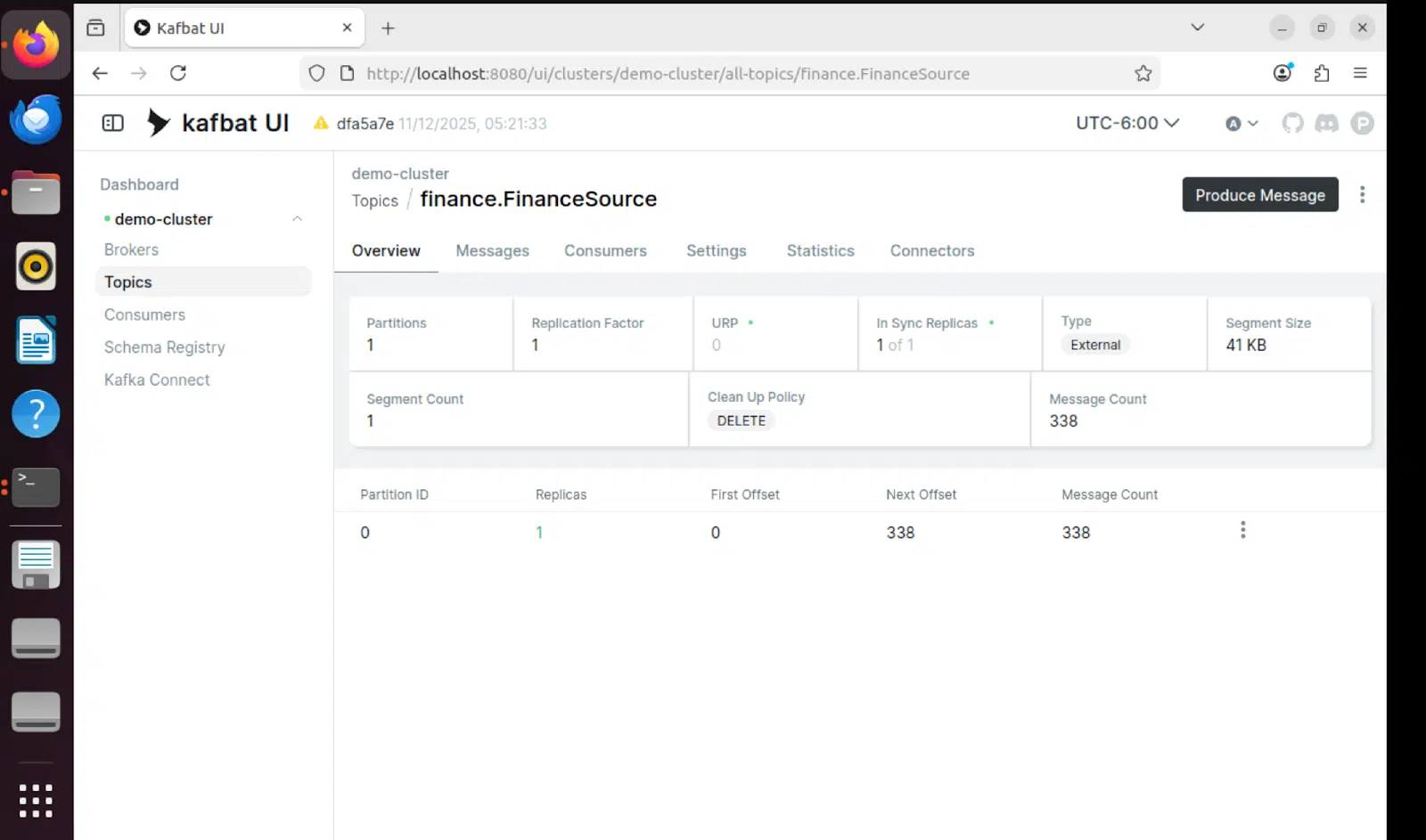
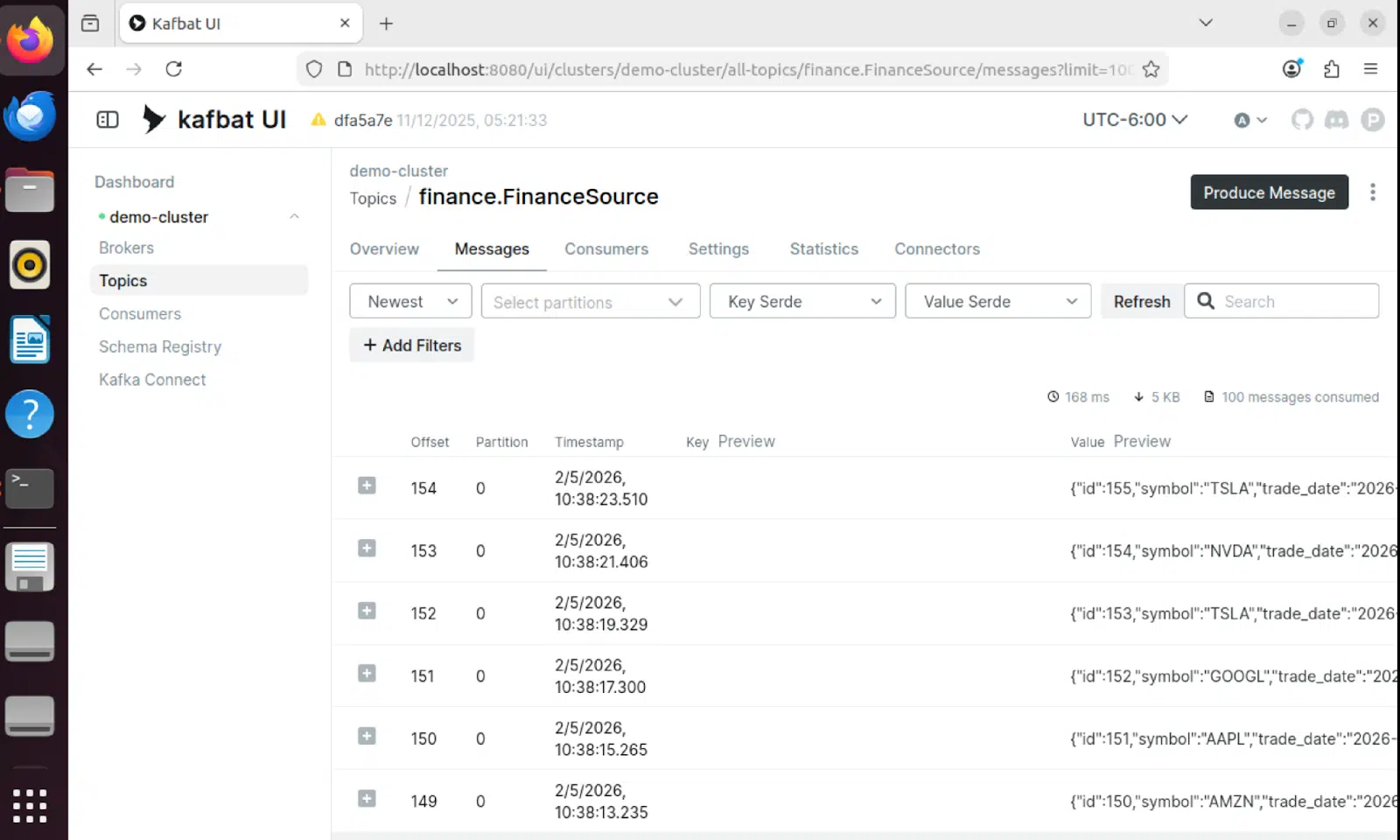
Kafbat UI – Themenansicht
Die Kafbat-Benutzeroberfläche bietet einen Echtzeit-Überblick über Kafka-Themen und zeigt die durch die Pipeline fließenden Nachrichten an:
Konnektor
Sowohl der Quell- als auch der Senken-Konnektor zeigen den Status „RUNNING“ an, was bestätigt, dass die Pipeline betriebsbereit ist:
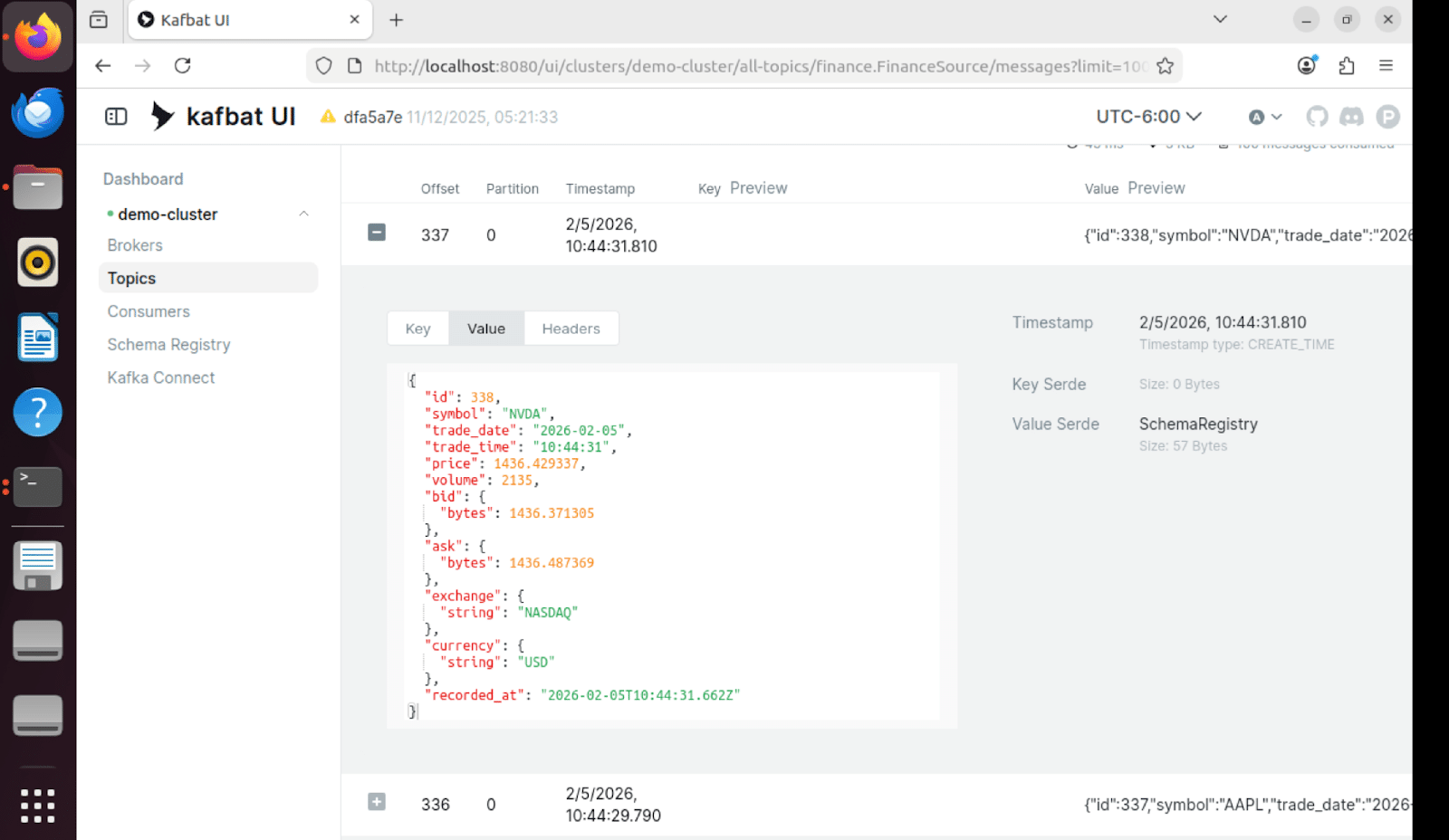
Inhalt der Nachricht
Einzelne Nachrichten in Kafka enthalten die vollständigen Handelsdaten im Avro-Format mit Schema-Versionierung:
Ergebnisse der Sink-Tabelle
Die „Finance Sink“-Tabelle in Zen empfängt die gestreamten Daten und zeigt damit einen erfolgreichen End-to-End-Datenfluss an.
Erste Schritte
Die Demo ein umfassendes Orchestrierung , das den gesamten Einrichtungsprozess automatisiert. Um die Demo auszuführen, Demo lediglich ein einziges Python ausgeführt Demo .
Demo mit einem Befehl
Der Orchestrator führt fünf wichtige Schritte automatisch aus:
- Docker-Compose-Stack starten (Kafka, Schema Registry, Connect, UI).
- Warten Sie, bis alle Dienste wieder ordnungsgemäß funktionieren (45 bis 60 Sekunden).
- Initialisiere die Tabellen „FinanceSource“ und „Finance“ in Zen.
- JDBC-Quell- und -Zielkonnektoren erstellen und konfigurieren.
- Starten Sie den Datengenerator im Hintergrund.
Orchestrierung :
def run(self): # Schritt 1: Docker Compose starten self.start_docker_compose() # Schritt 2: Auf Dienste warten self.wait_for_services() # Schritt 3: Datenbanken initialisieren self.initialize_databases() # Schritt 4: Konnektoren einrichten self.setup_connectors() # Schritt 5: Datengenerator starten self.start_data_generator() # Status anzeigen und weiterlaufen lassen self.show_status()
Das Skript liefert bei jedem Schritt klare Statusmeldungen und führt bei einer Unterbrechung (Strg+C) eine Bereinigung durch.
Initialisierung der Tabelle
Das Initialisierungsskript erstellt beide Tabellen mit den entsprechenden Schemata und löscht vorhandene Tabellen, um einen sauberen Zustand zu gewährleisten:
def create_finance_source(conn): exec_sql(conn, "DROP TABLE IF EXISTS FinanceSource") create_sql = """ CREATE TABLE FinanceSource ( id IDENTITY PRIMARY KEY, symbol VARCHAR(16) NOT NULL, trade_date DATE NOT NULL, trade_time TIME NOT NULL, price DECIMAL(18,6) NOT NULL, volume INTEGER NOT NULL, bid DECIMAL(18,6), ask DECIMAL(18,6), exchange VARCHAR(16), currency VARCHAR(8) DEFAULT 'USD', recorded_at TIMESTAMP NOT NULL ) """ exec_sql(conn, create_sql)
Aufbau und Nutzen einer Finanz-Pipeline in Echtzeit
Diese Lösung zeigt einen praktischen Ansatz zum Aufbau einer Echtzeit-Finanzdatenpipeline mit Actian Zen und Kafka Connect:
- Zen speichert Betriebsdaten und dient weiterhin als Aufzeichnung.
- Kafka bietet einen dauerhaften, wiederholbaren Datenstrom.
- Kafka Connect überträgt Daten zuverlässig anhand von Konfigurationen.
- Avro und das Schema-Register sorgen für Schemasicherheit.
- Die Sink-Tabelle stellt einen abfragbaren materialisierten Zustand bereit.
Für Unternehmen, die ihre Finanzdatenflüsse modernisieren, bietet diese Architektur einen klaren Weg von der Stapelverarbeitung hin zu Streaming, ohne dass bestehende Investitionen in Datenbanken aufgegeben werden müssen.
Lesen Sie mehr in unserem Blog Reihe , die sich darauf konzentriert, Entwicklern eingebettet den Einstieg in Actian Zen zu erleichtern.

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)