
Data platform architecture is the foundational structure that supports the collection, storage, processing, and management of data within an organization. What makes a data platform scalable is its ability to grow in response to increasing data demands without negatively affecting performance or reliability. Scalable data architectures are designed to handle massive amounts of data efficiently, ensuring smooth operations as data volume, complexity, and the need for wider democratization rise.
Building a scalable data platform is crucial for supporting the long-term growth of any business. As organizations expand, so does the volume of data they must handle, analyze, and store. Without a scalable data platform architecture, businesses face bottlenecks, inefficiencies, and increased costs. In fact, many of the largest companies today — including Netflix, Amazon, and LinkedIn — have built their success on highly scalable, resilient, and efficient data platforms.
This article will break down the critical components that make up a successful, scalable data platform architecture. From choosing the right scaling strategy to optimizing data flows, it will provide actionable steps to ensure an organization’s data platform supports current needs and future growth.
The Importance of Scalable Data Architectures
The digital landscape is evolving rapidly, and businesses across all industries generate vast amounts of data daily. Whether it’s customer data in retail, patient records in healthcare, or financial transactions in banking, the volume of information that needs to be processed and stored is continuously expanding. A scalable data platform ensures that companies can meet both the current demands and the challenges of tomorrow without system limitations.
Scalability is crucial as businesses adopt new technologies like artificial intelligence (AI), machine learning (ML), and advanced analytics — all of which require vast amounts of data to operate effectively. The ability to efficiently handle increasing data volumes allows organizations to remain agile and competitive in a data-driven world.
Engaging Stakeholders in the Design Process
Building an effective data platform architecture requires collaboration across various departments. Involving key stakeholders from the outset ensures that the architecture aligns with business goals and addresses the unique needs of different teams.
- IT Teams: Ensure that the data platform is technically sound and meets the scalability requirements.
- Business Analysts: Provide insights on how the data will be used for decision-making, ensuring the architecture supports data analytics.
- Security Teams: Establish protocols to protect sensitive information and ensure compliance with data protection regulations.
Early engagement with these stakeholders helps identify potential challenges and ensures the platform meets technical and business requirements.
Building Efficient Data Pipelines for Scalability
At the heart of any scalable data platform is the data pipeline — the system that manages data flow from ingestion to transformation and storage. An efficient pipeline ensures data moves seamlessly through the system, regardless of volume.
To build an effective pipeline:
- Automate Data Ingestion: Set up automatic data ingestion from multiple sources, including databases, APIs, and real-time streaming data.
- Data Transformation and Cleansing: Clean and standardize incoming data to ensure consistency and usability. Automating these processes reduces manual intervention and improves scalability.
- Data Storage Optimization: Store data in formats optimized for use cases, whether in a cloud data architecture or on-premises scalable data storage solutions.
A well-designed data pipeline ensures that a scalable data platform can handle increasing workloads while maintaining performance and reliability.
Horizontal vs. Vertical Scaling
When designing a scalable database architecture, it’s essential to understand two fundamental scaling methods: horizontal scaling and vertical scaling. These strategies offer different approaches to expanding system capacity and performance.
Horizontal Scaling
This involves adding more servers (or nodes) to a system, which distributes the workload across multiple machines. As data grows, new servers can be added seamlessly to handle the increased demand. This method is popularly used in cloud-based architectures, as it allows for almost unlimited scaling.
Benefits:
- Easy to implement in cloud environments.
- Allows for near-infinite scalability.
- Reduces the risk of single points of failure.
Vertical Scaling
Vertical scaling enhances the power of existing infrastructure by upgrading hardware components, like adding more CPU, RAM, or storage to a single server. While effective for specific workloads, vertical scaling has limits, as there is only so much that can be upgraded before reaching a cap.
Benefits:
- Simple to implement for smaller systems.
- No need to modify applications significantly.
- Ideal for workloads that require substantial processing power on individual nodes.
Choosing between horizontal and vertical scaling depends on an organization’s needs. However, for most enterprise-level data platforms, horizontal scaling is favored for its flexibility and long-term scalability.
Optimizing With Data Partitioning, Sharding, and Redundancy
Once an organization selects a scaling approach, data partitioning, sharding, and redundancy become essential to optimize performance.
- Data Partitioning: Partitioning breaks large datasets into smaller, manageable chunks, typically based on logical groupings such as date ranges or regions. This improves query performance and allows for faster data retrieval by limiting the scope of searches.
- Sharding: Sharding goes a step further by distributing data across multiple servers. Each shard is an independent database that holds a subset of the data, which allows for improved scalable data processing and storage. This technique is critical for high-traffic applications, as it helps balance loads across multiple servers.
- Data Redundancy and Replication: To ensure data availability and fault tolerance, data redundancy replicates information across multiple servers or locations. If a server fails, redundant systems ensure data remains accessible, preventing service disruptions.
By leveraging partitioning, sharding, and redundancy, organizations can create scalable data architectures that maintain high performance even as data volume increases.
Leveraging Cloud Services and Hybrid Solutions
As businesses move towards greater digital transformation, cloud data architecture has become an essential tool for scalability. Cloud services offer on-demand resources that can automatically adjust to meet a platform’s needs as data grows.
- Cloud-Based Hyperscalers: Cloud platforms such as AWS, Microsoft Azure, Actian DataConnect, and Google Cloud provide auto-scaling features that adjust computing power and scalable data storage based on traffic and data volumes. This eliminates the need for manual scaling efforts and ensures the platform can handle fluctuations in demand.
- Hybrid Solutions: Hybrid data architectures allow for seamless integration for businesses that need a combination of on-premises and cloud infrastructure. Data can be stored locally for compliance or security reasons while leveraging the cloud’s scalability for processing power.
Cloud solutions provide an efficient way to build and maintain a scalable data platform without significant upfront investment in infrastructure.
Ensuring Performance and Availability With Load Balancing
To maintain optimal performance, load balancing is crucial. Load balancers distribute incoming network traffic across multiple servers to ensure no single server becomes overwhelmed, preventing bottlenecks and improving the availability of the data platform.
- Dynamic Load Balancing: Modern load balancers use algorithms to assess the current server load and direct traffic accordingly. This prevents straining the system and ensures consistent performance.
- Failover Protection: In the event of a server failure, load balancers can automatically reroute traffic to functioning servers, minimizing disruption.
Incorporating load balancing into your scalable database architecture ensures that performance remains steady as demand increases.
Scalable Data Platform Architecture Examples
Understanding how successful organizations design their scalable data platform architectures can provide valuable insights. Below are real-world examples of architectures used by companies like Netflix and Amazon, showcasing how they leverage scalability to handle massive data volumes.
1. Netflix’s Scalable Microservices Architecture
Netflix is known for its microservices-based architecture, which breaks down large applications into smaller, independent processes. This allows Netflix to scale different parts of its platform as needed, such as user authentication, video streaming, or content recommendation engines. Each microservice can be deployed independently and scaled horizontally.
Here’s a simplified model of Netflix’s architecture:

This architecture enables Netflix to scale specific services based on demand, ensuring uninterrupted service even during peak usage.
2. Amazon’s E-Commerce Architecture
Amazon’s scalable database architecture supports its vast e-commerce platform, which handles millions of transactions daily. Amazon uses a combination of horizontal scaling, data partitioning, and sharding to manage its inventory, customer orders, and logistics efficiently.
Here’s a representation of Amazon’s architecture:

This architecture allows Amazon to handle the large and dynamic workloads of its e-commerce platform by distributing tasks across many smaller databases.
3. LinkedIn’s Real-Time Data Processing Architecture
LinkedIn’s architecture is designed to handle large-scale data ingestion and processing in real time, ensuring that members receive updates (such as news feed posts and job recommendations) instantly. LinkedIn uses Apache Kafka for real-time data streaming and Hadoop for distributed data storage.
Here’s how LinkedIn structures its data platform architecture:
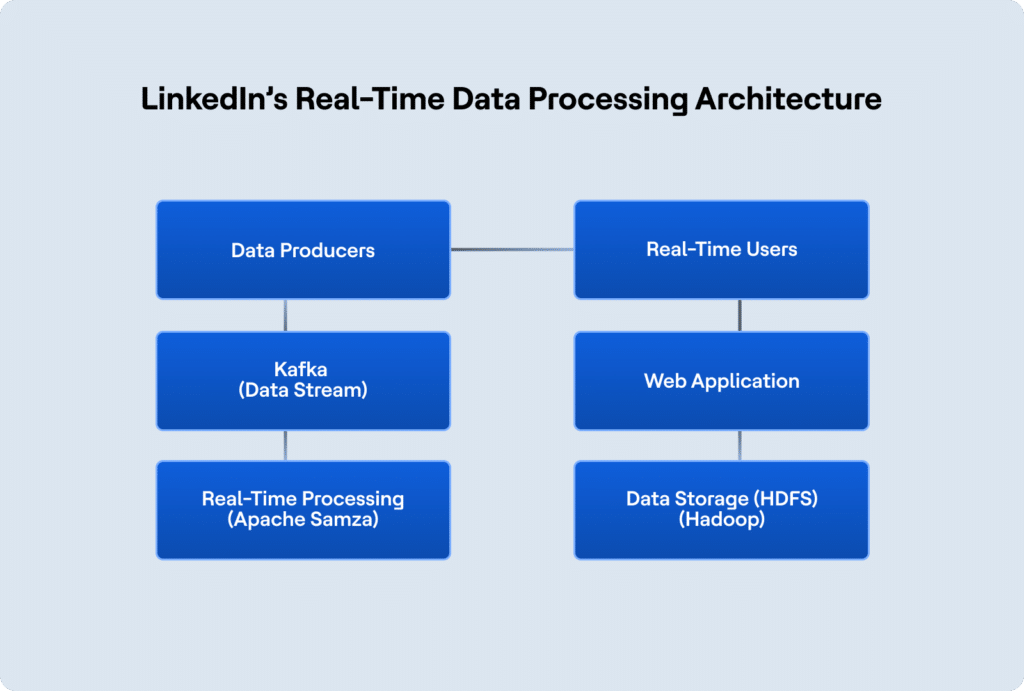
This architecture allows LinkedIn to handle real-time data processing while ensuring the platform can scale with the growing number of users and features.
Actian and the Data Intelligence Platform
Actian Data Intelligence Platform is purpose-built to help organizations unify, manage, and understand their data across hybrid environments. It brings together metadata management, governance, lineage, quality monitoring, and automation in a single platform. This enables teams to see where data comes from, how it’s used, and whether it meets internal and external requirements.
Through its centralized interface, Actian supports real-time insight into data structures and flows, making it easier to apply policies, resolve issues, and collaborate across departments. The platform also helps connect data to business context, enabling teams to use data more effectively and responsibly. Actian’s platform is designed to scale with evolving data ecosystems, supporting consistent, intelligent, and secure data use across the enterprise. Request your personalized demo.
FAQ
A scalable data platform architecture is a foundational structure that supports the collection, storage, processing, and management of data with the ability to grow in response to increasing data demands without negatively affecting performance or reliability.
Scalability ensures that companies can meet current demands and future challenges without system limitations, allowing organizations to remain agile and competitive as they adopt technologies like AI, machine learning, and advanced analytics that require vast amounts of data.
Horizontal scaling adds more servers to distribute workloads across multiple machines and allows for near-infinite scalability, while vertical scaling upgrades existing hardware components like CPU or RAM on a single server but has physical limits.
Sharding distributes data across multiple servers where each shard is an independent database holding a subset of the data, which improves scalable data processing and storage by balancing loads across multiple servers, making it critical for high-traffic applications.
IT teams ensure technical soundness and scalability requirements, business analysts provide insights on data usage for decision-making, and security teams establish protocols for data protection and compliance, with early engagement helping identify challenges and align the architecture with both technical and business requirements.
Efficient data pipelines manage data flow from ingestion to transformation and storage by automating data ingestion from multiple sources, cleaning and standardizing incoming data, and optimizing storage formats to handle increasing workloads while maintaining performance and reliability.
Load balancing distributes incoming network traffic across multiple servers to prevent any single server from becoming overwhelmed, ensuring consistent performance and providing failover protection by automatically rerouting traffic to functioning servers during failures.
Cloud platforms like AWS, Microsoft Azure, and Google Cloud provide auto-scaling features that automatically adjust computing power and storage based on traffic and data volumes, eliminating manual scaling efforts and allowing platforms to handle fluctuations in demand without significant upfront infrastructure investment.


