Reinforcement Learning From Human Feedback

Reinforcement learning from human feedback (RLHF) is used in machine learning (ML) to improve the accuracy and language of agent or model responses using human feedback. The feedback can be captured passively, based on edits to outputs, or more actively through numeric scoring of responses or natural language assessments.
Why is Reinforcement Learning From Human Feedback Important?
RLHF is very useful when feedback is sparse or “noisy.” When the ML function provides natural language or text summarization, humans can easily judge the quality, which is challenging to do accurately using an algorithmic approach. The RLHF model can fine-tune its performance using positive and negative feedback by having humans rank outputs from good to bad.
Learning Methods
Humans can provide explicit feedback to a learning algorithm by editing output, which can be reviewed by the algorithm as guidance. Tuning usually begins with the use of training datasets. These include the prompt dataset containing unlabeled prompts and a human preference dataset that contains pairs of candidate responses, including labels indicating the preferred prompt response. A more hands-off approach is used during the reinforcement phase by biasing the learning toward the conversations that provide the best ratings of the agent’s output. Human trainers can provide feedback about what was done well and less well for more sophisticated or nuanced subjects.
Applications of RLHF
There are many current and emerging applications for RLHF. Here are some examples:
Conversational Chatbots
Conversational chatbots usually start with a partially pre-trained model, and then human trainers tune the base model. When deployed into production, the chatbots solicit user input to score their understanding and responses. The higher-scoring conversations are used to set positive reinforcement benchmarks for continuous improvement.
GPT Dialogs
Chats involving a GPT-driven conversation can use positive feedback from humans to guide their learning. Pre-trained plug-ins that include knowledge of various domains can be developed.
Text Summarization and Translation
Human reviewers read summaries and either make or suggest edits that the machine learning model uses as input for successive attempts. The same approach works well for translation and transcription services where the model has to adapt to subtle local differences.
Challenges With RLHF
Artificial intelligence (AI)-driven conversations still have a way to go to be as natural as real human conversations, but they are maturing fast. The reliance on human subjectivity can be problematic because different people’s views vary. Conversations rarely use poor grammar but can have flaws based on the trainer’s use of language. For example, if the trainer is biased or overuses colloquialisms, the algorithm will pick up those traits. A different trainer must flag these traits negatively to train them out of use. Imagine training your chatbot using too many press releases and marketing content. The result will be that overusing hyperbole impacts the chat agent’s credibility. A model that has been undertrained often resorts to repetition, which can tire or irritate the consumer.
Benefits of RLHF
Below are many of the benefits of adopting RLHF:
- Provides a way to continuously improve the accuracy and performance of chat-based conversations.
- Enables the finer tuning of domain-specific dialogs using human input.
- Allows chat agents to mimic language more naturally, improving customer service.
- Provides an end user to deliver feedback that improves future interactions.
- It enables humans to train AI to be better aligned with their interaction style, including having a more informal and less robotic persona.
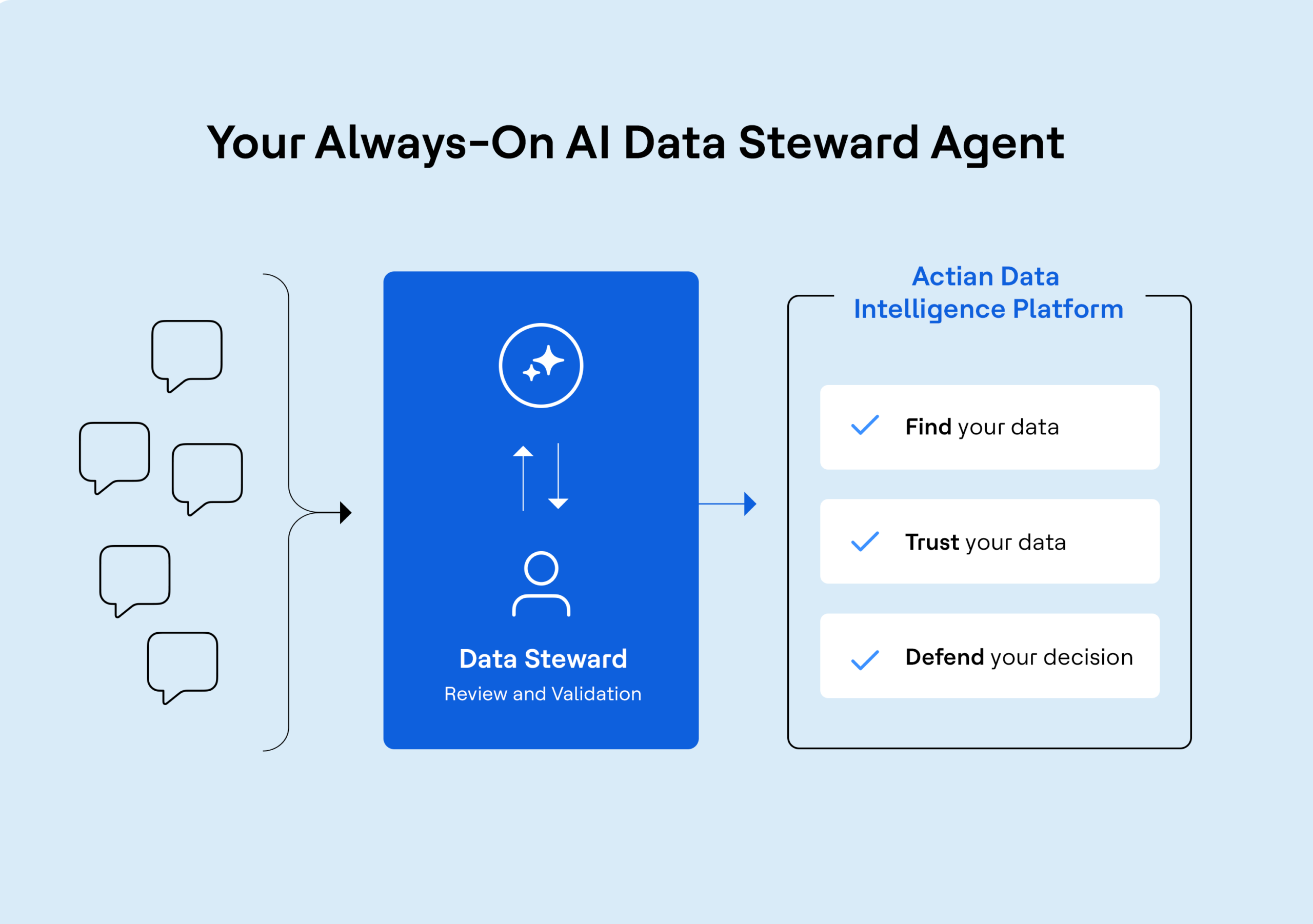
Actian and the Data Intelligence Platform
Actian Data Intelligence Platform is purpose-built to help organizations unify, manage, and understand their data across hybrid environments. It brings together metadata management, governance, lineage, quality monitoring, and automation in a single platform. This enables teams to see where data comes from, how it’s used, and whether it meets internal and external requirements.
Through its centralized interface, Actian supports real-time insight into data structures and flows, making it easier to apply policies, resolve issues, and collaborate across departments. The platform also helps connect data to business context, enabling teams to use data more effectively and responsibly. Actian’s platform is designed to scale with evolving data ecosystems, supporting consistent, intelligent, and secure data use across the enterprise. Request your personalized demo.
FAQ
Reinforcement learning from human feedback (RLHF) is a training approach where machine learning models—especially large language models—are improved using human evaluations. Human feedback guides the model toward producing safer, higher-quality, and more aligned responses.
RLHF typically involves three steps:
- Fine-tuning a base model with supervised examples.
- Training a reward model based on human preference rankings.
- Using reinforcement learning algorithms (such as PPO) to optimize model behavior according to the reward model.
RLHF helps align model outputs with human expectations, reduces harmful or incorrect responses, improves coherence, and allows models to follow instructions more reliably compared to training on raw data alone.
Human feedback can include ranked responses, binary preferences, corrections, annotations, or domain-specific evaluations. This feedback trains the reward model that ultimately influences how the system behaves.
Challenges include the scalability of human labeling, inconsistent or biased feedback, reward hacking, over-optimization toward narrow goals, and high computational cost for reinforcement learning training cycles.
Enterprises use RLHF to improve chatbot accuracy, align AI assistants with domain-specific knowledge, refine model behavior for compliance and safety, and optimize decision-making models based on expert human judgment.