¿Debería usar RAG o ajustar su modelo extenso de lenguaje (LLM)?




Summary
- El RAG domina el ámbito de la IA empresarial gracias a su flexibilidad, pero el ajuste fino destaca por su capacidad a gran escala, su baja latencia y sus resultados estructurados.
- RAG añade costes recurrentes derivados del contexto y la recuperación, mientras que el ajuste fino adelanta los costes gracias a una tarifa estable por consulta.
- Los enfoques híbridos combinan la recuperación con el ajuste fino para lograr una mayor precisión y un mejor razonamiento.
- La elección del enfoque adecuado depende de la volatilidad de los datos, el volumen de consultas y las capacidades del equipo.
El debate entre la generación aumentada por recuperación (RAG) y el ajuste fino parece sencillo a primera vista. La RAG incorpora datos externos en el momento de la inferencia. El ajuste fino modifica los pesos del modelo durante el entrenamiento. En los sistemas de producción, esa distinción no basta.
Según el informe de Menlo Ventures de 2024 , el 51 % de las implementaciones de IA en las empresas utilizan RAG en producción. Solo el 9 % se basa principalmente en el ajuste fino. Sin embargo, estudios como el estudio de RAFT de la Universidad de California en Berkeley, muestran que los sistemas híbridos que combinan la recuperación y el ajuste fino superan a cualquiera de los dos enfoques por separado en las pruebas comparativas.
Si los sistemas híbridos pueden ofrecer mejores resultados, ¿por qué la industria se decanta únicamente por el RAG? En este artículo, compararemos el RAG, el ajuste fino y una arquitectura híbrida para comprender las ventajas y desventajas de cada enfoque, así como en qué aspectos destaca cada uno.
TL;DR
- RAG: Ideal para conocimientos que cambian con frecuencia y un volumen de tráfico moderado; fácil de actualizar sin necesidad de volver a formar al personal.
- Ajuste fino: Ideal para dominios estables y tareas de gran volumen o baja latencia; mejora la precisión y el formato específicos de la tarea.
- Híbrido/RAFT: Combina la recuperación actualizada con un comportamiento optimizado del modelo para obtener la máxima precisión.
- Comprobación clave: La elección depende del volumen de consultas, de la frecuencia con la que cambia el conocimiento y de la experiencia del equipo.
Por qué falla la comparación entre el método RAG estándar y el ajuste fino
RAG es un método en el que el modelo incorpora dinámicamente datos externos en el momento de la inferencia. Cada consulta recupera documentos o fragmentos de conocimiento relevantes, que el sistema añade a la solicitud, lo que permite al modelo generar respuestas basadas en información actualizada.
El ajuste fino es el proceso de modificar los pesos de un modelo durante el entrenamiento utilizando datos etiquetados. En lugar de depender de la recuperación de información externa, el modelo interioriza los patrones directamente, generando resultados coherentes sin consultar fuentes externas.
Aunque estas definiciones son técnicamente correctas, la mayoría de las comparaciones estándar pasan por alto los factores que realmente influyen en las decisiones en la producción. En los sistemas reales, la elección entre RAG y el ajuste fino depende de variables como la escala, el volumen de consultas y la frecuencia con la que cambian los datos.
Variable ausente 1: Expansión del contexto a gran escala
En muchos sistemas RAG de producción, cada solicitud añade cientos de tokens. Ese contexto adicional modifica la forma en que el modelo distribuye su atención y prioriza los pesos.
Los contextos de recuperación extensos compiten por la atención con la solicitud y las instrucciones, lo que puede reducir la calidad de la señal. Los pequeños errores de recuperación o los fragmentos de relevancia dudosa pueden provocar desviaciones en el formato o alterar el razonamiento de forma sutil. El resultado del sistema queda estrechamente vinculado a la calidad de la recuperación.
El ajuste fino funciona de manera diferente. En lugar de introducir grandes volúmenes de texto en el momento de la inferencia, incorpora patrones y restricciones directamente en el modelo durante el entrenamiento. Esta diferencia influye en el comportamiento del sistema ante cargas de trabajo reales.
Variable 2 ausente: Frecuencia de reentrenamiento
El consejo habitual es: «utiliza RAG si los conocimientos cambian con frecuencia» y «utiliza el ajuste fino si el comportamiento es estable». Pero, ¿qué significa «con frecuencia»?
Si tu base de conocimientos cambia a diario, los procesos de reciclaje profesional pueden generar fricciones operativas. Los ciclos de evaluación, el control de versiones de los conjuntos de datos y la validación de la implementación suponen retrasos.
La preparación de los datos también es importante. Si tu organización carece de conjuntos de datos estructurados, versionados y limpios, el coste oculto de preparar los datos de entrenamiento puede superar los costes de computación.
Comparación de costes entre RAG y el ajuste fino
Las comparaciones superficiales entre RAG y el ajuste fino suelen pasar por alto las curvas de costes que determinan la viabilidad a largo plazo. En los sistemas de producción, las estimaciones financieras son fundamentales a la hora de tomar decisiones arquitectónicas. Para evaluar de forma realista el RAG frente al ajuste fino, debemos examinar tres niveles de costes:
- Coste de las fichas y expansión del contexto.
- Coste de la infraestructura de recuperación.
- Coste de las infraestructuras de formación.
La estructura de costes de RAG
Los sistemas RAG suponen un coste operativo recurrente, ya que cada consulta recupera información externa y la incorpora a la indicación del modelo. Ese contexto adicional se factura en cada solicitud.
Ampliación del contexto
Los sistemas RAG de producción añaden unos 500 tokens de contexto recuperado a cada consulta. El proveedor factura esos tokens en cada solicitud.
Con un precio similar al GPT-5.2 a 1,750 dólares por millón de tokens de entrada, el coste mensual incremental es:
Coste por consulta
500 tokens × 1,75 $/1 000 000 = 0,000875 $ por consulta
A pequeña escala, este coste parece insignificante. Sin embargo, dado que se aplica a cada consulta, la sobrecarga total aumenta linealmente con el tráfico.
En diferentes niveles de tráfico:
| Consultas mensuales | Coste contextual |
| 10 millones | $8,750 |
| 50 millones | $43,750 |
| 100 millones | $87,500 |
Esto corresponde únicamente a la sobrecarga de contexto. No incluye los tokens de salida ni los tokens del prompt base. A largo plazo, lo que parece flexible y económico se convierte en un gasto recurrente considerable.
Base de datos vectorial y coste de recuperación
El coste de los tokens es solo uno de los componentes de los costes de RAG. RAG también se basa en una base de datos vectorial para la búsqueda semántica. El sistema debe almacenar, indexar y consultar las representaciones de manera eficiente.
Precios públicos de las listas de Pinecone:
- Almacenamiento a aproximadamente 0,33 dólares por gigabyte al mes.
- Las unidades se cotizan a unos 16 dólares por millón.
- Calcular las unidades a unos cuatro dólares por millón.
Por ejemplo, imaginemos un sistema que gestiona 50 millones de consultas al mes, en el que cada consulta realiza una única búsqueda vectorial (suponiendo un vector de 1.024 dimensiones). Esto supondría 50 millones de operaciones de lectura al mes. Si el sistema también escribe aproximadamente seis millones de registros al mes, la actividad combinada de lectura y escritura elevaría el coste mensual total estimado a unos 1.532 dólares.
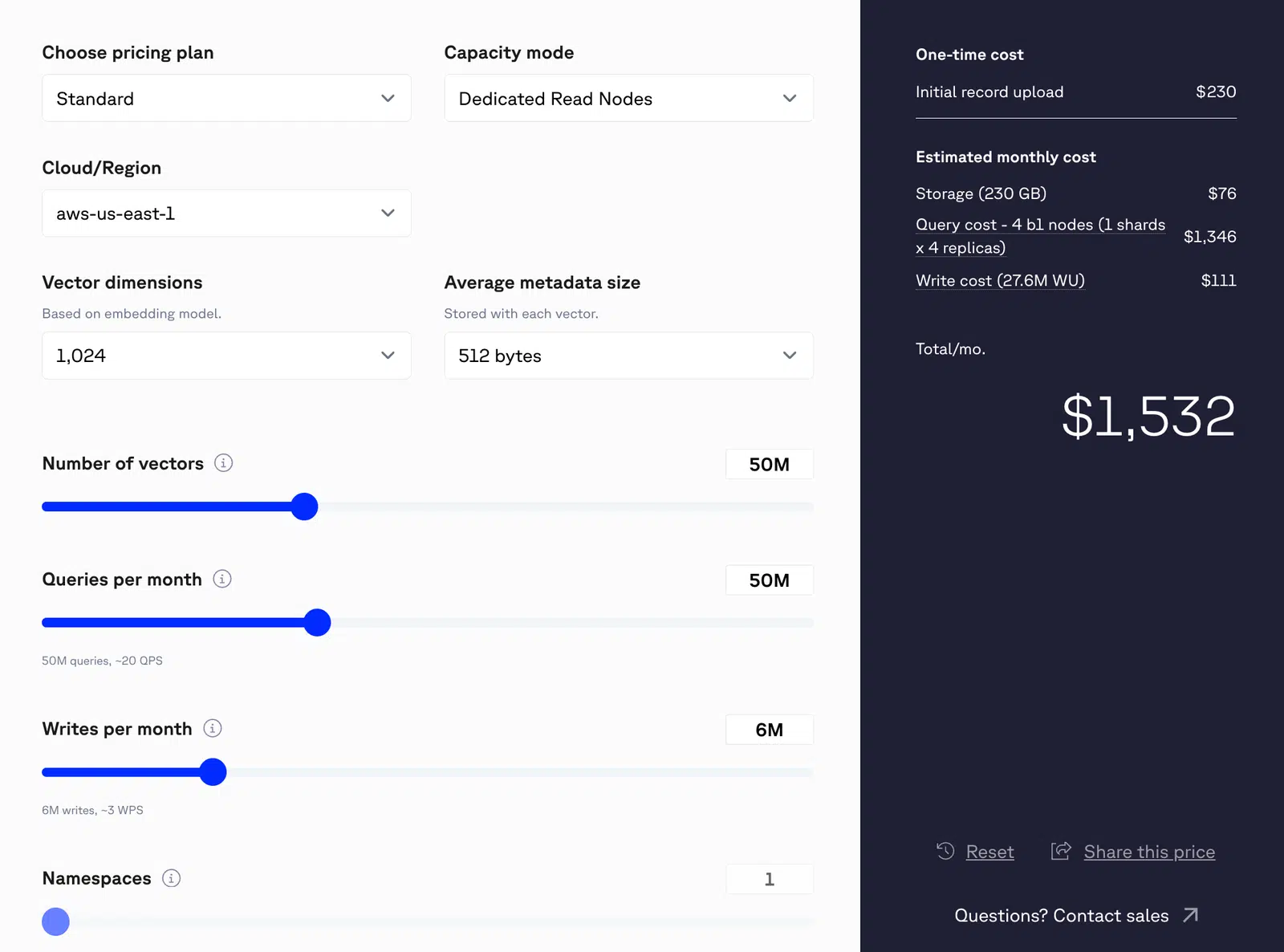
Figura 1: Precios de Pinecone para 50 millones de vectores
Con 200 millones de consultas al mes, los gastos totales ascienden a 9 000 dólares al mes.
Por lo tanto, dos sistemas RAG que atienden el mismo tráfico pueden tener estructuras de costes sustancialmente diferentes dependiendo de cómo se diseñe y optimizada.
Coste de las infraestructuras
Los sistemas RAG requieren una infraestructura de almacenamiento y computación para generar representaciones, almacenar e indexar vectores, ejecutar consultas de recuperación y realizar inferencias. Cada una de estas etapas consume recursos de computación, que suelen aprovisionarse a través de servidores en la nube que deben adaptarse al volumen de tráfico.
Para aplicaciones en tiempo real o de alto rendimiento, se requiere una capacidad adicional para mantener una baja latencia y la fiabilidad del sistema. Los mecanismos de replicación, autoescalado, supervisión y conmutación por error aumentan la complejidad operativa. Estas capas de infraestructura son esenciales para un RAG de nivel de producción, pero elevan el coste total más allá del mero uso de tokens.
La estructura de costes del ajuste fino
El ajuste fino introduce un modelo económico diferente al de los sistemas RAG. En lugar de pagar costes incrementales por cada solicitud de contexto externo, se realiza una inversión inicial para modificar el comportamiento interno del modelo.
Esa inversión inicial se puede dividir en cuatro categorías principales de costes: datos, recursos informáticos para la formación, experimentación y mantenimiento operativo.
Costes de preparación de datos
Los datos etiquetados de alta calidad son la base de un ajuste fino eficaz. Esto implica recopilar ejemplos específicos del ámbito, eliminar las inconsistencias, dar el formato adecuado a las entradas y salidas, y validar la calidad de las anotaciones.
En muchas organizaciones, la preparación de datos consume entre el 20 y el 40 por ciento del presupuesto total destinado al ajuste fino. Unos datos mal gestionados reducen directamente el rendimiento del modelo, lo que conlleva ciclos de reentrenamiento adicionales y un desperdicio de recursos informáticos.
Costes de computación para el entrenamiento
OpenAI calcula que el ajuste fino de GPT-4.1 cuesta aproximadamente 25 dólares por cada millón de tokens de entrenamiento. Una ejecución con 20 millones de tokens costaría unos 500 dólares en tarifas directas de entrenamiento, y este importe aumentaría si se utilizaran conjuntos de datos más grandes o se realizaran varias ejecuciones.
En el caso del entrenamiento autohospedado, los costes dependen del tamaño del modelo y del hardware. Las GPU de alto rendimiento, como los clústeres A100, pueden costar miles de dólares por época de entrenamiento. Dado que el ajuste fino rara vez es un proceso de una sola pasada, es habitual realizar múltiples épocas, evaluaciones y ciclos de reentrenamiento, lo que aumenta aún más el coste total.
Costes de experimentación y validación
El ajuste fino es un proceso iterativo que requiere experimentar con hiperparámetros, realizar evaluaciones comparativas con modelos de referencia y llevar a cabo pruebas en casos extremos. Estos flujos de trabajo requieren tiempo de ingeniería, infraestructura y marcos de evaluación estructurados. A diferencia de la ingeniería de prompts, el ajuste fino implica un ciclo de vida completo del aprendizaje automático, lo que añade una carga operativa continua.
Esto da lugar a una curva de costes no lineal. El ajuste fino concentra los costes al principio, mientras que el coste marginal por solicitud se mantiene relativamente estable a medida que aumenta el tráfico.
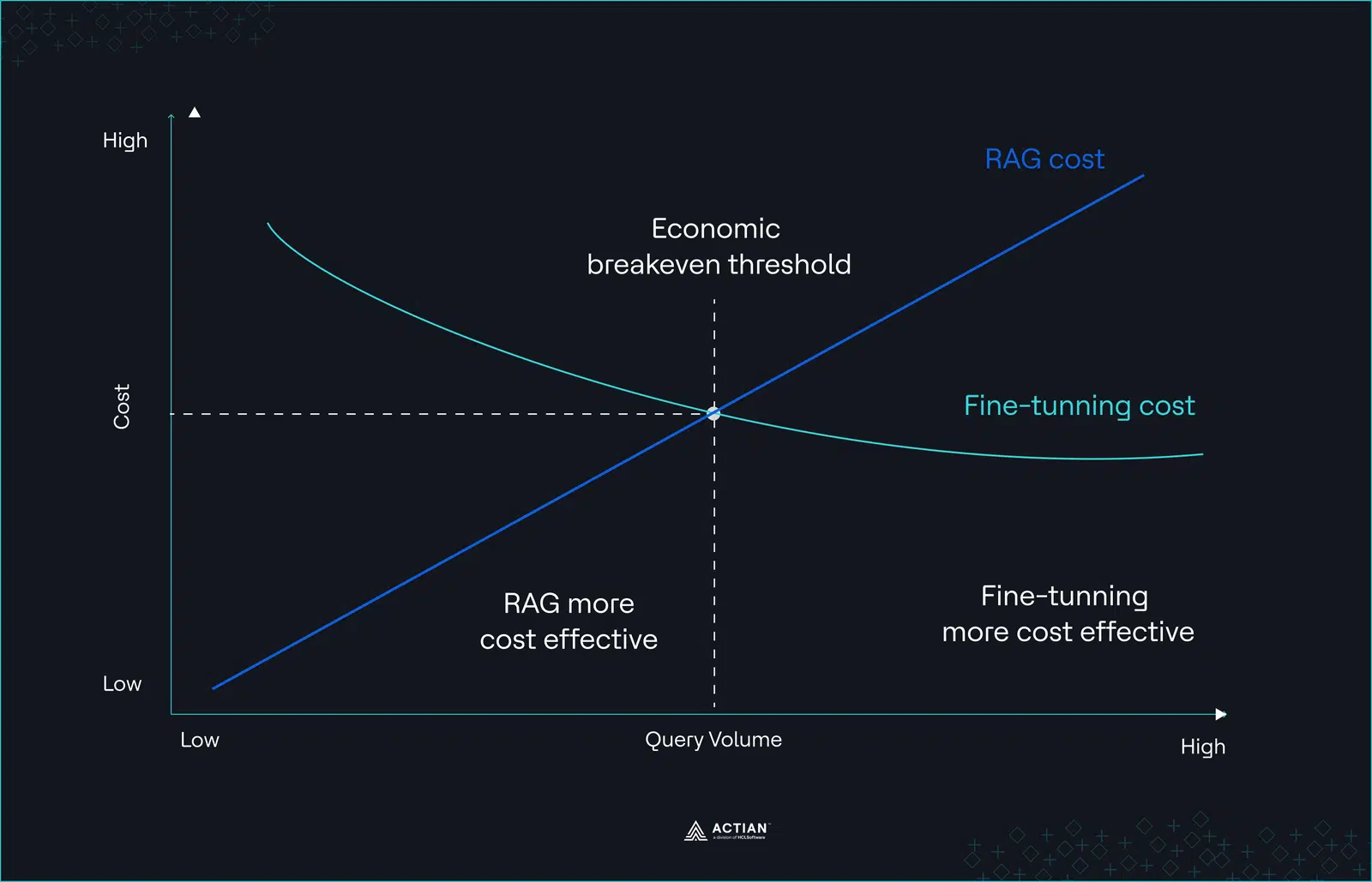
Figura 2: Curva de costes no lineal
Que esa compensación resulte ventajosa depende de tres variables: el volumen de consultas, la estabilidad del conocimiento y la frecuencia de reentrenamiento. Sin modelarlas explícitamente, las comparaciones de costes entre RAG y el ajuste fino siguen siendo incompletas.
Cuando gana el RAG
A pesar de sus limitaciones en cuanto a la escalabilidad, RAG sigue siendo la opción predominante en producción por una razón. En determinadas condiciones de funcionamiento, es estructuralmente más flexible, permite iteraciones más rápidas y resulta más seguro desde el punto de vista operativo que el ajuste fino. RAG es adecuado en los siguientes casos:
- Cuando el conocimiento cambia con frecuencia
Si tus conocimientos sobre el dominio cambian cada semana o cada día, el ajuste fino se vuelve costoso desde el punto de vista operativo. Las actualizaciones de los conjuntos de datos, el reentrenamiento, la evaluación y la implementación provocan retrasos que pueden prolongarse desde horas hasta semanas, dependiendo de los requisitos de gobernanza.
Los equipos suelen subestimar la carga operativa que supone mantener sincronizado un modelo optimizado con una base de conocimientos en rápida evolución. En estos entornos, el RAG traslada el problema del reentrenamiento del modelo a la indexación de datos.
- Cuando se dispone de una gran cantidad de datos no estructurados, pero de datos etiquetados limitados
Muchas organizaciones disponen de terabytes de documentos internos, pero carecen de conjuntos de datos supervisados de alta calidad. La creación de corpus de entrenamiento etiquetados requiere flujos de trabajo de anotación, expertos en la materia y procesos de validación de la calidad. En la práctica, esto suele convertirse en la parte más costosa de los proyectos de ajuste fino.
RAG elude esta limitación al permitir que los modelos operen directamente sobre corpus de documentos existentes sin necesidad de crear grandes conjuntos de datos etiquetados.
- Cuando los requisitos de gobernanza y residencia de datos son estrictos
Una vez que la información confidencial se integra en los pesos del modelo, resulta difícil eliminarla y realizar auditorías. Eliminar un registro concreto de un modelo ajustado suele requerir un nuevo entrenamiento o el mantenimiento de un complejo historial de los conjuntos de datos.
Las arquitecturas RAG evitan este problema al almacenar la información confidencial en sistemas de almacenamiento externos en los que ya existen controles de gobernanza estándar.
- Cuando el volumen de consultas es moderado
Como se muestra en el análisis de costes anterior, los gastos generales de expansión del contexto aumentan con el volumen de consultas, hasta alcanzar aproximadamente 43 750 dólares al mes con 50 millones de consultas. Con un tráfico moderado, los costes por solicitud de RAG suelen ser inferiores a los gastos amortizados del ajuste fino, incluyendo el entrenamiento y el mantenimiento continuo. Esto convierte a RAG en una opción atractiva para las organizaciones que desean resultados de alta calidad sin tener que realizar inversiones iniciales en infraestructura y recursos informáticos.
Casos prácticos
Los ejemplos a gran escala demuestran la eficacia de RAG a este nivel. El asistente de preguntas y respuestas de Notion es , en la práctica, un sistema RAG a gran escala sobre datos del espacio de trabajo. El difícil problema de ingeniería no era la recuperación en sí, sino la aplicación de controles de identidad y acceso durante la recuperación. Cuando un usuario consulta al asistente, el sistema debe garantizar que el modelo solo recupere los documentos que el usuario tiene permiso para ver.
LinkedIn utilizó RAG y grafos de conocimiento para conservar la estructura de sus casos de asistencia técnica. Este sistema recuperó subgrafos relevantes en lugar de fragmentos de texto aislados, lo que mejoró la precisión de la recuperación en un 77,6 % y reduciendo el tiempo medio de resolución de incidencias en un 28,6 %.
En sistemas de esta envergadura, RAG combina la rentabilidad con la flexibilidad, lo que permite a los equipos actualizar rápidamente las fuentes de conocimiento sin necesidad de volver a entrenar los modelos, al tiempo que sigue ofreciendo resultados de alta calidad.
Cuando el ajuste fino marca la diferencia
El ajuste fino resulta ventajoso desde el punto de vista estructural en determinadas condiciones. Estas condiciones suelen estar relacionadas con la escala, la estabilidad y la precisión del comportamiento.
- Cuando el volumen de consultas supera los 100 millones al mes
Cuando el tráfico es muy elevado (más de 100 millones de consultas al mes), la sobrecarga de contexto por solicitud de RAG se vuelve significativa. Cada consulta añade cientos de tokens recuperados que el modelo debe procesar, lo que hace que los costes aumenten de forma lineal con el tráfico. Las ventanas de contexto de gran tamaño también pueden aumentar la latencia, reducir el rendimiento y complicar la fiabilidad de la infraestructura.
Si el conocimiento del dominio es relativamente estable, el ajuste fino puede resultar más eficiente. Al integrar el conocimiento directamente en el modelo, las organizaciones evitan los costes repetidos de recuperación y de tokens, lo que se traduce en gastos por consulta más predecibles, una mayor coherencia y operaciones más sencillas a gran escala.
- Cuando la estructura de salida es fundamental
Los modelos ajustados suelen destacar en tareas que requieren un estricto cumplimiento de la estructura o de las restricciones formales. Por ejemplo, Cosine, un asistente de ingeniería de software de IA capaz de resolver errores y desarrollar funciones de forma autónoma, logró una puntuación SOTA del 43,8 % en el banco de pruebas verificado SWE-bench.
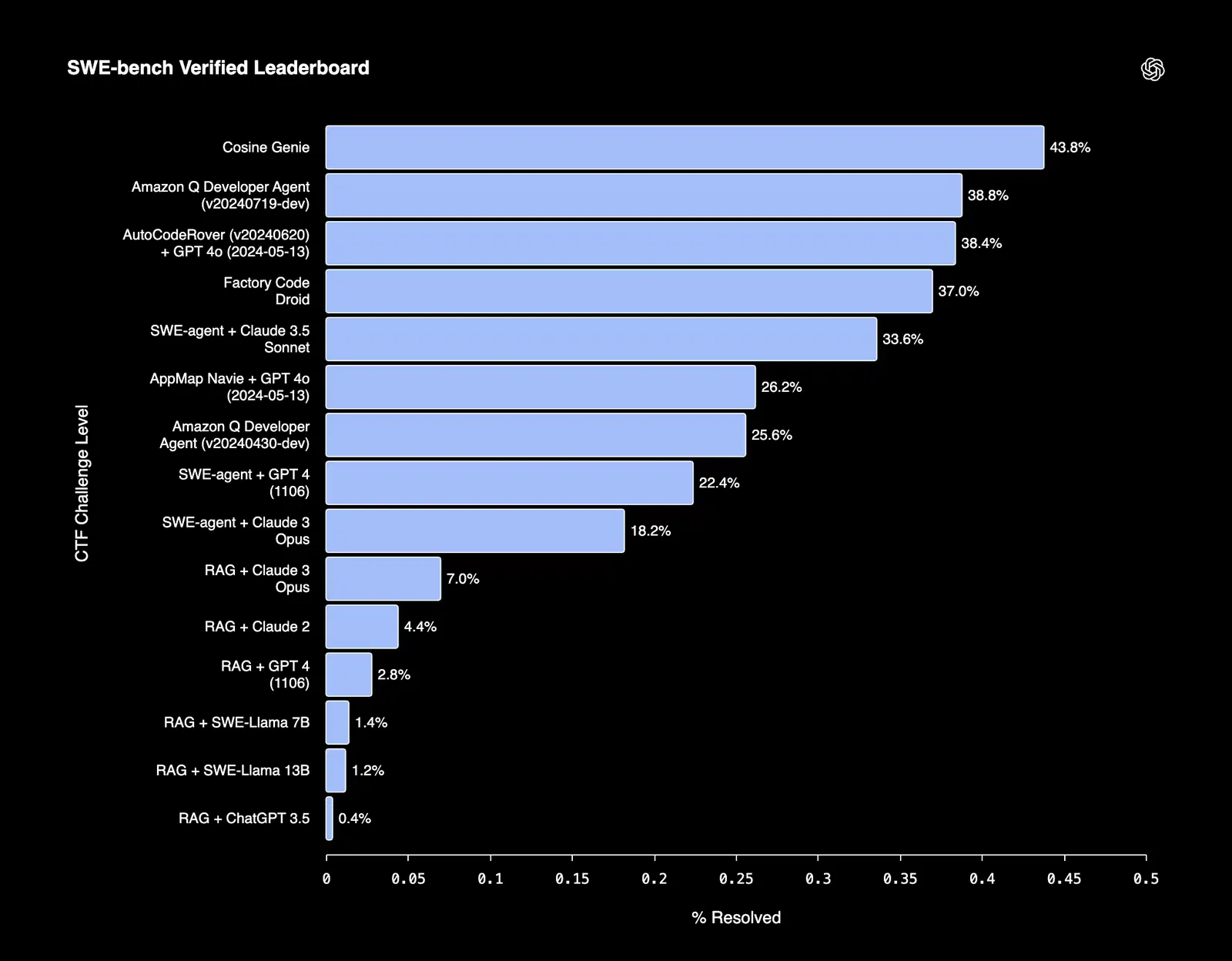
Figura 3: Clasificación de SWE-bench
Del mismo modo, Distyl se hizo con el primer puesto en la prueba de rendimiento BIRD-SQL, considerada por muchos como la principal evaluación del rendimiento de la conversión de texto a SQL. Su modelo GPT-4o, optimizado al detalle, alcanzó una precisión de ejecución del 71,83 % en la clasificación.
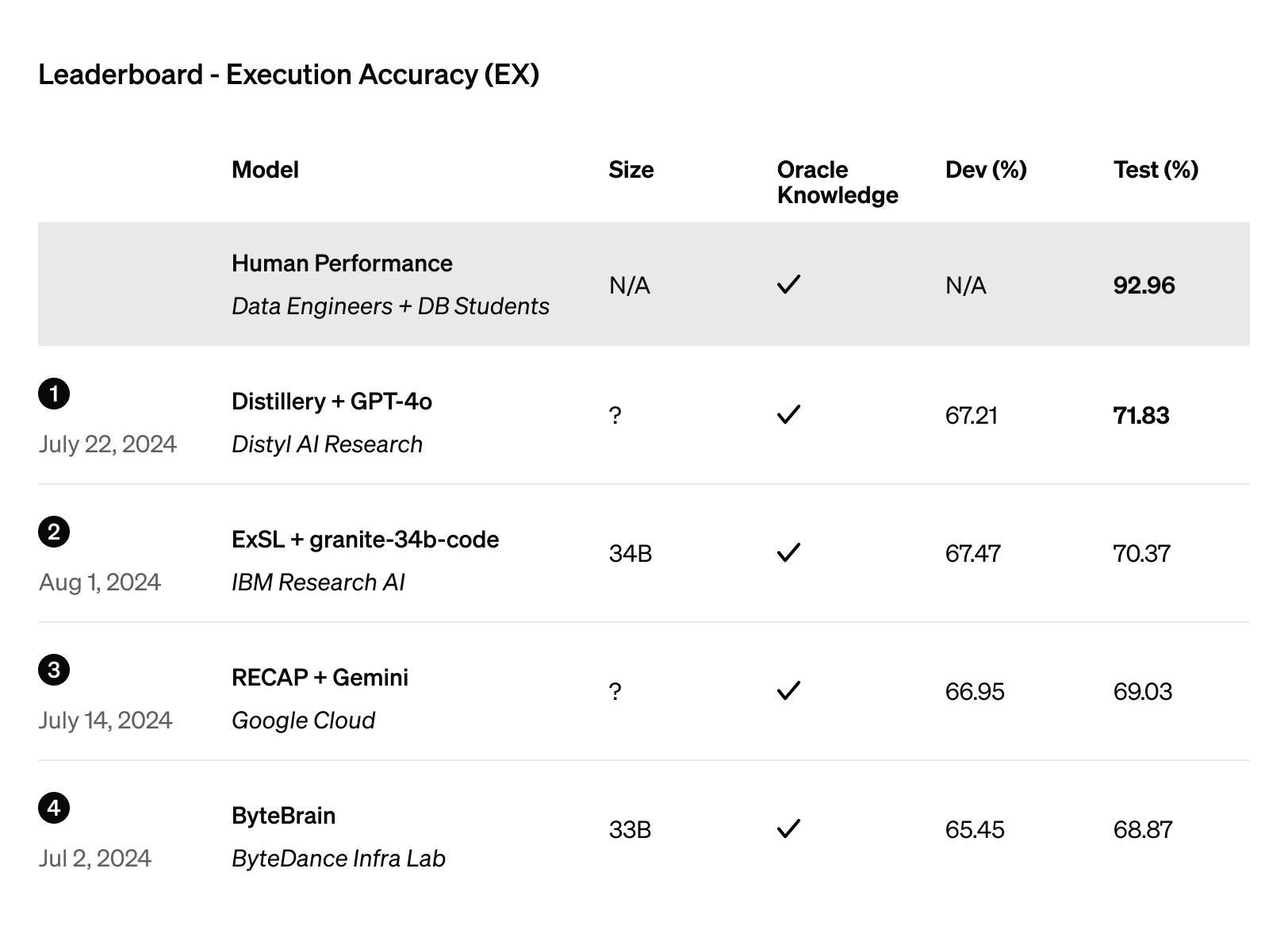
Figura 4: Clasificación de precisión en la ejecución
En aplicaciones en las que los errores se propagan a etapas posteriores —ya sea en cálculos financieros, API automatizadas o documentos de cumplimiento—, la coherencia en el comportamiento es imprescindible. En estos contextos, el ajuste fino proporciona la fiabilidad necesaria para minimizar el riesgo y mantener la confianza en los resultados automatizados.
- Cuando los requisitos de latencia son estrictos
RAG añade varios pasos al proceso de inferencia que aumentan el tiempo de respuesta. Cada consulta debe pasar por la generación de representaciones, la búsqueda vectorial y la inyección de contexto antes de llegar al modelo.
Los modelos optimizados prescinden por completo de la recuperación de datos. Todo el conocimiento y los patrones de razonamiento necesarios están integrados, lo que permite al modelo generar resultados de forma inmediata. En aplicaciones en las que se requieren respuestas en menos de 100 ms, como los motores de recomendación en tiempo real o los sistemas de negociación de alta frecuencia, la eliminación del proceso de recuperación de datos suprime un importante cuello de botella.
- Cuando el razonamiento especializado es más importante que la actualidad
Un estudio comparativo específico del sector agrícola reveló que el ajuste fino mejoró la precisión del modelo del 75 % al 81 %, mientras que los sistemas híbridos (ajuste fino + recuperación) alcanzaron el 86 %. Dado que el conjunto de datos se centraba en conocimientos agrícolas especializados y tareas de razonamiento, la mejora refleja principalmente un razonamiento más sólido en el ámbito, y no simplemente un mejor acceso a información externa.
En ámbitos como el análisis jurídico o el apoyo a la toma de decisiones médicas, los patrones de razonamiento pueden ser complejos. El ajuste fino permite a los modelos asimilar los conocimientos especializados del ámbito en cuestión, en lugar de basarse únicamente en el contexto recuperado.
El enfoque híbrido
Aunque tanto el RAG como el ajuste fino tienen ventajas claras, las investigaciones demuestran que combinarlos de forma eficaz puede dar lugar a resultados superiores, pero solo si se hace correctamente. El enfoque RAFT (Retrieval Augmented Fine-Tuning), desarrollado por la Universidad de California en Berkeley, Microsoft y Meta Research, demuestra cómo hacerlo en la práctica.
RAFT entrena un modelo para que funcione en un entorno de «libro abierto». Aprende a procesar el contexto recuperado, identificar pasajes relevantes, ignorar elementos que distraen y citar las pruebas con precisión. Sin este entrenamiento explícito, el simple hecho de superponer RAG a un modelo ajustado a menudo fracasa. Por ejemplo, un modelo ajustado para el razonamiento médico puede recuperar artículos de revistas irrelevantes si no ha aprendido a filtrar y priorizar el contexto, lo que da lugar a alucinaciones o recomendaciones incorrectas.
RAFT aborda esto con una división estructurada del entrenamiento en una proporción 80/20. El 80 % de los ejemplos de entrenamiento incluyen documentos de Oracle que el modelo debe utilizar, mientras que el 20 % restante no los incluye, lo que obliga al modelo a aprender cuándo confiar en los datos recuperados y cuándo basarse en el conocimiento internalizado. Este detalle operativo es crucial para que los ingenieros evalúen si su equipo puede implementar con éxito un enfoque híbrido. No basta con combinar RAG y el ajuste fino. El modelo debe entrenarse para razonar sobre el contexto recuperado.
Un patrón habitual y práctico es «ajuste fino para el formato, RAG para el conocimiento». El ajuste fino configura el comportamiento interno del modelo, imponiendo un razonamiento específico del ámbito, la estructura de los resultados y el estilo. RAG proporciona acceso dinámico a información externa que cambia con frecuencia o que es demasiado voluminosa para almacenarla en los pesos del modelo. En el ámbito sanitario, por ejemplo, el ajuste fino garantiza que el modelo comprenda la terminología médica, siga un razonamiento diagnóstico adecuado y formatee los resultados de acuerdo con los estándares de documentación clínica. RAG complementa esto recuperando las últimas investigaciones, las guías de tratamiento recién publicadas o los registros específicos de cada paciente, lo que mantiene las recomendaciones actualizadas sin necesidad de volver a entrenar todo el modelo.
Del mismo modo, Harvey AI se ha ajustado con 10 000 millones de tokens de jurisprudencia, pero sigue utilizando RAG para gestionar los casos actuales y las actualizaciones. Este patrón también se utiliza ampliamente en otros ámbitos. Los sistemas jurídicos se ajustan para el razonamiento legal y el estilo de citación, y luego incorporan RAG para recuperar la jurisprudencia más actual; los modelos financieros se ajustan para las reglas de análisis de carteras, y luego incorporan RAG para las actualizaciones del mercado y los cambios normativos. Es una forma de equilibrar la estabilidad del comportamiento aprendido con la adaptabilidad de la recuperación de información.
Un marco de decisión cuantificado para comparar RAG con el ajuste fino
La pregunta ya no es «¿qué enfoque es mejor?», sino «¿en qué condiciones tiene sentido, desde el punto de vista económico y operativo, cada enfoque?».
En lugar de basarse únicamente en preferencias arquitectónicas, evalúe tres variables cuantificables:
- Frecuencia de actualización de los conocimientos.
- Volumen mensual de consultas.
- Limitaciones en materia de capacidad de infraestructura y gobernanza.
Cuando se cuantifican esas variables, la decisión resulta mucho más clara.
Paso 1: Medir la volatilidad del conocimiento
La frecuencia con la que cambia el conocimiento suele ser la forma más rápida de descartar una opción. Si el conocimiento de tu ámbito cambia semanal o diariamente, el enfoque RAG resulta estructuralmente más adecuado. Actualizar un índice es mucho más sencillo que volver a entrenar un modelo ajustado. La separación entre los pesos del modelo y los datos externos permite la recuperación de datos en tiempo real sin necesidad de ciclos de reimplementación.
Si el conocimiento se mantiene estable durante meses, el ajuste fino resulta económicamente viable. La frecuencia de reentrenamiento disminuye y el coste de la formación puede amortizarse en intervalos más largos. En estos entornos, la incorporación de conocimientos específicos del dominio directamente en los parámetros del modelo puede reducir la sobrecarga de la inferencia a largo plazo.
A modo de referencia práctica:
- El conocimiento cambia con una frecuencia superior a la mensual → dar prioridad a RAG.
- Los datos se han mantenido estables durante varios meses → evaluar un ajuste fino.
Paso 2: Calcular el coste de la expansión del contexto
La siguiente variable es el volumen de consultas. Los sistemas RAG a gran escala añaden cientos de tokens a cada consulta, y esta sobrecarga de contexto aumenta de forma lineal con el tráfico.
Desencadenantes cuantitativos
| Consultas mensuales | Orientación |
| <10M | El RAG es más barato |
| 10–50 m | Comparar el ajuste fino con el método RAG |
| 50-100 millones | Ajuste fino o híbrido |
| >100M | Ajuste fino o híbrido |
Paso 3: Evaluar el grado de madurez de la infraestructura
Aunque los aspectos económicos apunten a una opción, la capacidad de las infraestructuras puede determinar la viabilidad.
RAG requiere:
- Sólida ingeniería de datos.
- Canales de datos fiables.
- Arquitectura eficiente de bases de datos vectoriales.
- Observabilidad y supervisión.
El ajuste fino requiere:
- Datos etiquetados de alta calidad.
- Experiencia en aprendizaje automático.
- Asignación de recursos informáticos.
- Disciplina de evaluación.
Cuando los equipos ignoran sus capacidades reales, las decisiones de arquitectura se vienen abajo al aumentar la escala. Muchos fallos en producción que se achacan a la «calidad del modelo» no son más que consecuencias de una infraestructura inmadura.
Matriz de decisión
La siguiente matriz traduce el análisis en orientaciones prácticas.
| Escenario | Consultas mensuales | Frecuencia de actualización de los conocimientos | Recomendación | Justificación |
| El contenido se actualiza semanalmente; tráfico moderado | 10–50 m | Semanal/Diario | RAG | Indexación inmediata y bajos costes recurrentes |
| Tráfico a gran escala, base de datos estable | 50–100 millones o más | <1 update/month | Ajuste fino | Evita la inyección de contexto recurrente y reduce la latencia |
| Se requiere salida estructurada o generación de código | Cualquiera | Cualquiera | Ajuste fino | Incorpora internamente reglas y formatos específicos del dominio |
| Razonamiento especializado + actualizaciones frecuentes | 10–50 m | Semanal/Diario | Híbrido | Combina el razonamiento interiorizado con el conocimiento dinámico |
| Sistemas multidominio con ciclos de actualización del conocimiento diversos | 10–100 millones | Misto | Híbrido | El ajuste fino estabiliza los dominios principales, mientras que RAG gestiona fuentes que cambian rápidamente |
Con esta matriz, resulta más fácil decidir si utilizar RAG, ajustar los modelos de lenguaje grande (LLM) o recurrir al enfoque híbrido.
Reflexiones finales
El debate entre RAG y el ajuste fino suele plantearse como una elección binaria, pero la pregunta más pertinente es: «Si está demostrado que los sistemas híbridos superan en rendimiento a cualquiera de los dos enfoques por separado, ¿por qué la industria sigue apostando de forma abrumadora por el RAG?».
El enfoque híbrido requiere contar simultáneamente con capacidades de aprendizaje automático y de ingeniería de datos, una combinación de la que disponen pocas organizaciones. El modelo RAG sigue siendo la opción práctica por defecto, ya que ofrece agilidad y transparencia con una menor complejidad inicial.
La conclusión principal es que debes elegir la arquitectura que mejor se adapte a la volatilidad de tus datos, al volumen de consultas y a las capacidades de tu equipo. Para los equipos que estén explorando sistemas de recuperación a escala empresarial, plataformas como Actian VectorAI DB ofrecen capacidades de bases de datos vectoriales diseñadas específicamente para garantizar el rendimiento y la escalabilidad.
Únete a la comunidad de Discord y descubre cómo Actian encaja en tu estrategia de IA.

Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)