Data preparation is a multistep process to refine raw data from source systems and prepare it for data analysis.
Why is Data Preparation Important?
Data preparation is essential for providing high-quality data to support decision-making. Most businesses have abundant data available to them but often lack the resources to get sufficient value from that data. Preparing data provides a way to efficiently convert raw data into a form that is easy to analyze.
When Hadoop first emerged, the IT world suddenly had a low-cost, highly scalable file system to create a repository of potentially useful data and “Big Data” movement. Cloud-based storage soon became more cost-effective than on-premises data, so businesses created data lakes in public clouds. The problem with this approach was that data assets were hard to find and needed preparation to make them useful. Data preparation software and processes or data integration solutions finally automated the delivery of high-quality data to data warehouses, data lakes and data lake houses, data meshes and data fabrics. Finally, analysts and data scientists have the data they need in a form that can be used to gain insights through data analytics and machine learning.
Data Preparation Steps
Data preparation consists of multiple steps that can include the following:
Accessing Data
Data ingestion is the very first step in data preparation. It involves collecting data from different sources, such as databases, log files, existing data lakes, and social media, and loading them into a central repository or data processing environment. Data integration technology such as DataConnect can help connect to all these sources and load them into your target destination. It has pre-built connectors to most data sources and the ability to quickly create your own connector to homemade data formats.
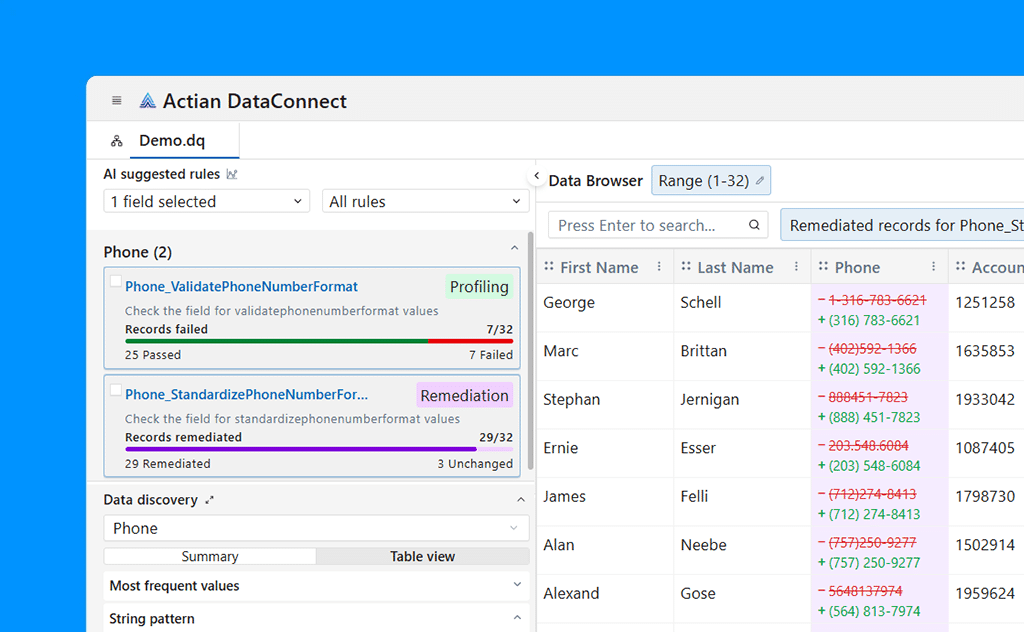
Profiling Data
Data profiling uses rules to assess source data accuracy, completeness, consistency, timeliness, validity, uniqueness, etc. This helps to quickly determine the quality levels of the source data, identify the types of problems, and reduce issues resulting from propagating bad data to downstream systems and applications.
Filtering Data
By this stage, an organization has decided what questions the data is going to be used to help answer. Irrelevant or unnecessary records and fields can be filtered out to make the resulting data set more compact and faster to analyze. Any outlying values can be filtered out to prevent data skew.
Filling Gaps
Missing values can be replaced by using defaults where appropriate or through extrapolation or interpolation if the source data is correctly ordered.
Merging Data
Data sets often need to be combined to get the whole picture. Merging multiple data sets must be done with care to avoid creating duplicate records. Reconciliation rules are used to deal with cases where two records with the same key need to be combined. Rules are used to help fill gaps or give precedence to the more recent data. Inspecting data from multiple sources can also validate data values to increase data quality scores.
Transforming Data
Data transformation is a critical step in the process, where raw data is converted, manipulated, or reshaped to make it suitable for analysis, modeling, or visualization.
Loading Data
The next phase is loading the data. The best way to analyze data is to load it into an analytics-oriented database such as Actian Analytics Engine. High-speed loaders can bypass the SQL API and use parallel loading for large datasets. To prevent the input file from becoming an I/O bottleneck, the data can be segmented into multiple files on different physical devices to maximize throughput.
Validating Data
Data validation involves checking that data meets data quality standards and that transformation and loading processing have not introduced errors.
Documenting Data
Documentation helps ensure transparency and reproducibility in your preparation processes.
Automating Data Preparation
Most data analysis is done regularly, so it makes sense to make the whole process repeatable to refresh or update data on a schedule. Data Integration tools such as DataConnect provide the tools to build a data preparation pipeline and centrally monitor scheduled tasks with built-in exception handling for any surprises.
The Benefits of Data Preparation
The following list contains some of the more commonly cited benefits of data preparation:
- Data is available for analysis at short notice so the business can adapt to market changes faster.
- Data preparation makes more of a company’s data assets productive.
- Data prep scripts can be reused or used in automated data pipelines.
- With data integration technology, the data preparation process can be managed centrally.
- Data preparation promotes data governance and data cataloging.
- Using automated data preparation provides an audit trail for data provenance.
- Data quality is improved.
- More decisions are data-driven as analytics are easier to run with trusted data.
Data Preparation and Analysis With Actian
Actian provides a unified location to build and maintain all analytics projects. Built-in data integration schedules data preparation steps. The Analytics Engine analytics database uses a vectorized columnar database that outperforms alternatives by 7.9x.
Actian and the Data Intelligence Platform
Actian Data Intelligence Platform is purpose-built to help organizations unify, manage, and understand their data across hybrid environments. It brings together metadata management, governance, lineage, quality monitoring, and automation in a single platform. This enables teams to see where data comes from, how it’s used, and whether it meets internal and external requirements.
Through its centralized interface, Actian supports real-time insight into data structures and flows, making it easier to apply policies, resolve issues, and collaborate across departments. The platform also helps connect data to business context, enabling teams to use data more effectively and responsibly. Actian’s platform is designed to scale with evolving data ecosystems, supporting consistent, intelligent, and secure data use across the enterprise. Request your personalized demo.
FAQ
Data preparation is a multistep process to refine raw data from source systems and prepare it for data analysis, converting it into a form that is easy to analyze and use for decision-making.
Data preparation is essential for providing high-quality data to support decision-making, efficiently converting raw data into a usable form and making more of a company’s data assets productive for analytics and machine learning.
The main steps include accessing data from various sources, profiling data quality, filtering irrelevant records, filling gaps in missing values, merging data sets, transforming data formats, loading data into analytics databases, validating data quality, and documenting the process.
Data profiling uses rules to assess source data accuracy, completeness, consistency, timeliness, validity, and uniqueness to quickly determine quality levels, identify problems, and reduce issues from propagating bad data to downstream systems.
Data transformation is a critical step where raw data is converted, manipulated, or reshaped to make it suitable for analysis, modeling, or visualization.
Yes, data integration tools like DataConnect provide the ability to build repeatable data preparation pipelines with scheduled tasks, centralized monitoring, and built-in exception handling for regular data analysis updates.
Benefits include faster business adaptation to market changes, improved data quality, reusable preparation scripts, centralized management, better data governance, audit trails for data provenance, and easier data-driven decision making with trusted data.