La observabilidad de los datos es la práctica de supervisar de forma continua el estado, la fiabilidad y la calidad de los datos a medida que estos circulan por los flujos de datos, las transformaciones y los sistemas, de modo que, cuando surge algún problema, los equipos de datos sean los primeros en enterarse, y no los últimos.
Sin observabilidad de los datos, un cambio en el esquema de un sistema fuente provoca, de forma silenciosa, que tres informes posteriores dejen de funcionar. Un retraso en la carga por lotes hace que los ejecutivos tomen decisiones basándose en las cifras de ayer sin saberlo. Un modelo de aprendizaje automático empieza a perder eficacia porque los datos con los que se alimenta se han desviado de la distribución con la que se entrenó. Ninguno de estos fallos se detecta de forma evidente. La observabilidad de los datos los hace visibles antes de que se conviertan en problemas para la empresa.
¿Qué es la observabilidad de los datos?
La observabilidad de los datos es la capacidad de comprender el estado interno de los sistemas de datos a partir de sus resultados externos, aplicando el mismo principio que utilizan los equipos de DevOps para la observabilidad de las aplicaciones a los flujos de datos, los almacenes de datos y los sistemas de los que dependen las organizaciones para el análisis de datos y la inteligencia artificial.
El término se acuñó en 2019 para describir un enfoque más completo de la fiabilidad de los datos que los controles tradicionales de calidad de los datos. Mientras que la calidad de los datos mide si estos cumplen con los estándares definidos en un momento dado, la observabilidad de los datos supervisa los datos de forma continua en cinco dimensiones —actualidad, volumen, esquema, calidad y linaje— y avisa automáticamente a los equipos cuando alguna de estas dimensiones se sale de los límites esperados.
El objetivo es reducir el tiempo de inactividad de los datos: los periodos en los que los datos son parciales, erróneos, incompletos o poco fiables por cualquier otro motivo. El tiempo de inactividad de los datos tiene un coste directo. Los analistas dedican tiempo a validar los datos en lugar de analizarlos. Los ingenieros investigan los fallos en los flujos de trabajo de forma reactiva, en lugar de prevenirlos. Los modelos de IA generan resultados poco fiables porque sus datos de entrada se han degradado sin que nadie se haya dado cuenta. La observabilidad de los datos aborda estos tres aspectos.
Los cinco pilares de la observabilidad de los datos
Todo marco de observabilidad de datos se sustenta en cinco pilares. En conjunto, proporcionan una visibilidad completa del estado de los datos a lo largo de todo el ciclo de vida del proceso.
| Pilar | Qué supervisa | Ejemplo de error que detecta |
|---|---|---|
| Frescura | Si los datos se han recibido a tiempo y cumplen con el SLA | Se ha completado un trabajo por lotes diario, pero no se han cargado los resultados: la tabla muestra datos de hace 28 horas en lugar de hace 4 horas. |
| Volumen | Si el número de filas, el tamaño de los archivos y el rendimiento se encuentran dentro de los rangos previstos | Una extracción de la API devolvió un 40 % menos de registros que la media diaria: un fallo silencioso en la fase previa. |
| Esquema | Si la estructura de los activos de datos ha cambiado de forma inesperada | Se ha cambiado el nombre de un sistema de origen customer_id a cust_id — Ahora, todas las uniones posteriores están generando valores nulos |
| Calidad | Si los valores de los campos cumplen las normas establecidas en materia de precisión, exhaustividad, validez y coherencia | El order_amount El campo presenta esta mañana una tasa de valores nulos del 12 %, frente al 0,3 % de ayer: se trata de un error de transformación. |
| Linaje | Cómo fluyen los datos desde la fuente hasta su uso y qué depende de qué | Un error de calidad en una tabla de origen afecta a 14 activos posteriores; el linaje identifica los 14 antes de que se produzcan fallos. |
Estos cinco pilares funcionan de forma conjunta. La supervisión de la actualidad detecta que una tabla no se ha actualizado. La supervisión del volumen detecta que han llegado menos registros de los esperados. La supervisión del esquema detecta que ha cambiado la definición de un campo. La supervisión de la calidad detecta que los valores de los campos se encuentran fuera de los rangos esperados. La supervisión del linaje muestra qué activos posteriores se ven afectados por cualquiera de los aspectos anteriores.
Observabilidad de los datos frente a conceptos relacionados
Observabilidad de los datos frente a calidad de los datos
| Observabilidad de datos | Calidad de los datos | |
|---|---|---|
| Qué hace | Supervisa continuamente el estado de los datos en cinco dimensiones y avisa cuando se produce algún fallo | Evalúa si los datos cumplen con los estándares definidos en un momento determinado |
| Cuando está en funcionamiento | De forma continua, en tiempo real o casi en tiempo real | Según una programación o activado por la ejecución del proceso |
| Resultado principal | Alertas, detección de anomalías, contexto de los incidentes | Puntuaciones de calidad, resultados de validación, estado de la certificación |
| Horizonte temporal | Supervisión continua: detecta desviaciones y fallos en el momento en que se producen | Evaluación puntual: te indica el estado actual de la calidad |
| Relación | La observabilidad detecta problemas de calidad. La gestión de la calidad define los estándares con respecto a los cuales se supervisa la observabilidad. |
La calidad de los datos y la observabilidad de los datos son conceptos complementarios, no alternativos. Se necesitan estándares de calidad para saber qué se considera «bueno». Se necesita observabilidad para saber cuándo lo «bueno» deja de serlo.
Observabilidad de los datos frente a supervisión de los datos
La supervisión de datos suele referirse a comprobaciones programadas que se ejecutan a intervalos definidos: una comprobación nocturna del recuento de filas, un informe semanal sobre la tasa de valores nulos. La observabilidad de los datos es más amplia y continua: combina comprobaciones programadas con la detección de anomalías, que aprende cuál es el comportamiento normal de cada activo y avisa cuando este se desvía, sin necesidad de definir manualmente cada umbral. La supervisión te indica cuándo se incumple una regla que has establecido. La observabilidad te indica cuándo está ocurriendo algo inesperado, incluso si no habías previsto ese modo de fallo concreto.
Observabilidad de los datos frente al linaje de los datos
El linaje de datos permite seguir el recorrido de los datos desde su origen hasta su consumo, pasando por todas las transformaciones. La observabilidad de datos utiliza el linaje como uno de sus cinco pilares: el contexto que permite actuar ante fallos relacionados con la calidad y la actualidad de los datos. Cuando la observabilidad detecta una anomalía, el linaje muestra qué cambio en las fases anteriores la ha provocado y qué activos en las fases posteriores se ven afectados. El linaje es el mapa; la observabilidad es el sistema de monitorización que lo lee en tiempo real.
Observabilidad de los datos frente a observabilidad de las aplicaciones
La observabilidad de las aplicaciones (métricas, registros y trazas en DevOps) supervisa el estado de los sistemas de software. La observabilidad de los datos aplica el mismo principio a los sistemas de datos: supervisa los flujos de datos, los almacenes de datos y los propios datos, en lugar del código que los procesa. Los marcos son análogos, pero las señales son diferentes. La observabilidad de las aplicaciones se pregunta: «¿Funciona el sistema?». La observabilidad de los datos se pregunta: «¿Son correctos los datos?».
Cómo funciona la observabilidad de los datos
Un sistema de observabilidad de datos funciona a través de cuatro capas técnicas.
1. Conexión y recopilación de metadatos
Las herramientas de observabilidad se conectan a todas las fuentes de datos del entorno —almacenes de datos, bases de datos, lagos de datos, plataformas de streaming, herramientas de orquestación y sistemas de BI— y recopilan metadatos de forma continua: esquemas de tablas, recuentos de filas, tasas de valores nulos, distribuciones de valores, registros de ejecución de flujos de datos e historiales de consultas. Estos metadatos constituyen la materia prima de toda la supervisión.
2. Aprendizaje básico
Antes de alertar sobre anomalías, el sistema aprende cuál es el comportamiento normal de cada activo. El número de filas de una tabla de transacciones minoristas se dispara de forma natural los fines de semana y días festivos. Una tarea ETL que procesa datos de fin de mes tarda más en la última semana del mes. Los volúmenes de datos financieros se disparan al final del trimestre. Un sistema de observabilidad de datos aprende estos patrones —normalmente en un plazo de entre 2 y 4 semanas— y establece umbrales dinámicos que tienen en cuenta la variación natural, en lugar de aplicar reglas estáticas que generan falsos positivos.
3. Detección de anomalías y alertas
Una vez establecidas las líneas de referencia, el sistema supervisa continuamente si se producen desviaciones. Cuando una métrica se sale de su rango esperado —retraso en la actualización más allá de lo establecido en el SLA, número de filas por debajo del mínimo esperado, detección de un cambio en el esquema o pico en la tasa de valores nulos—, se activa una alerta con información contextual: qué activo, qué métrica, en qué medida se ha salido de la línea de referencia y qué fuente anterior es la causa probable según el linaje.
4. Análisis de las causas fundamentales y de las repercusiones
Una observabilidad de datos eficaz va más allá de las alertas. Cuando se detecta una anomalía, el contexto de linaje muestra el cambio anterior que probablemente la haya provocado y los activos posteriores que puedan verse afectados. En lugar de una alerta que diga «la tabla de pedidos presenta una tasa de valores nulos anómala», un sistema de observabilidad maduro indica «la tasa de valores nulos de la tabla de pedidos es del 12 % en discount_code campo —probablemente debido a un cambio en el esquema del CRM de origen implementado a las 2:14 de la madrugada—; 7 informes derivados y 2 características de aprendizaje automático se ven afectados».
¿Quién utiliza la observabilidad de los datos y cómo?
Ingeniero de datos:Recibeuna alerta a las 7 de la mañana que indica que el flujo de pedidos ha registrado una caída del 40 % en el volumen en comparación con la media de los últimos 14 días. El contexto de Lineage muestra la causa probable: se ha alcanzado el límite de rate de una API de origen a las 3 de la madrugada. Soluciona el problema antes de que comience la jornada laboral. Sin observabilidad, el problema se habría detectado a las 10 de la mañana, cuando un analista preguntara por qué su panel de control no muestra ningún pedido nuevo.
Analista de datos:Abreel catálogo de datos para buscar un conjunto de datos con el que realizar un análisis de los ingresos trimestrales. El catálogo muestra el estado de observabilidad del conjunto de datos: se cumple el SLA de actualidad, la puntuación de calidad es del 98 % y no hay incidencias activas. Continúa con confianza. Sin observabilidad, la validación es un proceso manual que consiste en realizar recuentos de filas y comprobaciones aleatorias antes de dar por fiables los datos.
Responsable de datos:revisael informe semanal sobre el estado de la observabilidad correspondiente a su ámbito. Tres activos han registrado una disminución en sus puntuaciones de calidad durante la última semana: dos debido a un cambio en el sistema de origen y uno a causa de un problema de calidad de los datos en la fase anterior del proceso. Deriva cada caso al equipo de ingeniería correspondiente, aportando el contexto del sistema de observabilidad. Sin la observabilidad, estas deterioraciones se acumulan de forma silenciosa hasta que afectan a un informe de producción.
Ingeniero de aprendizaje automático:Configurala supervisión de la observabilidad en las tablas de características que alimentan un modelo de detección de fraudes. Recibe una alerta cuando la distribución de una característica clave se desvía más de dos desviaciones estándar respecto a la referencia de entrenamiento, lo que constituye una señal temprana de la deriva del modelo antes de que alcance el umbral en el que las predicciones se deterioran. Sin observabilidad, la deriva no se detectaría hasta semanas más tarde, cuando las métricas de rendimiento del modelo comenzaran a empeorar.
Director de Datos:Revisaun cuadro de mando mensual sobre la fiabilidad de los datos: tiempo medio de detección de incidencias relacionadas con los datos, tiempo medio de resolución, número de incidencias por ámbito y tasa de cumplimiento de los acuerdos de nivel de servicio (SLA) del proceso. Utiliza esta información para identificar en qué ámbitos es necesario invertir en la gestión de los datos y para informar al equipo directivo sobre el estado de la fiabilidad de los datos.
Aplicación de la observabilidad de los datos
Paso 1: Realiza una auditoría de tus procesos de mayor riesgo
Empieza por los flujos de datos que alimentan los informes críticos para el negocio, las presentaciones reglamentarias y los modelos de IA en producción. Estos son los activos en los que un fallo en los datos tiene el mayor impacto en el negocio. Establece métricas de calidad de referencia para cada uno de ellos: rangos de recuento de filas, umbrales de tasa de valores nulos, ventanas de actualidad esperadas e instantáneas del esquema.
Paso 2: Conecta tus fuentes de datos
Implementa conectores de observabilidad en todas las fuentes de datos prioritarias. La mayoría de las herramientas modernas de observabilidad se conectan a almacenes de datos en la nube (Snowflake, BigQuery, Redshift), plataformas de orquestación (Airflow, dbt) y herramientas de BI sin necesidad de modificar el código de los flujos de trabajo existentes.
Paso 3: Dejar que las líneas de referencia aprendan
Deja que el sistema funcione entre 2 y 4 semanas antes de esperar una detección de anomalías de alta calidad. Durante este periodo, el sistema aprende los patrones normales de cada activo, incluidas las variaciones estacionales y cíclicas. Las alertas que se generen durante este periodo tendrán índices de falsos positivos más elevados; tenlo en cuenta y aprovéchalo para ajustar los umbrales.
Paso 4: Configurar el enrutamiento de alertas
Define quién recibe las alertas para cada dominio y cuál es el proceso de escalado cuando una alerta no se confirma dentro de un plazo determinado. Vincula las alertas de observabilidad a los flujos de trabajo de gestión de tu catálogo de datos para que las incidencias se registren y se resuelvan con un historial de auditoría completo.
Paso 5: Integrar el linaje
La observabilidad sin linaje genera alertas sin contexto. Asegúrate de que tu sistema de observabilidad se integre con tu capa de linaje, de modo que cada alerta incluya posibles causas en las fases anteriores y el alcance del impacto en las fases posteriores. Esto es lo que transforma la observabilidad de un sistema de monitorización en un sistema de respuesta a incidentes.
Paso 6: Ampliar a los flujos de trabajo de IA
Configura la observabilidad de los datos que alimentan los modelos de IA en producción: conjuntos de datos de entrenamiento, flujos de características y entradas de inferencia. Establece una supervisión de la distribución de las características clave para detectar la deriva de los datos antes de que se vea afectado el rendimiento del modelo. Esta es la aplicación de la observabilidad de los datos en el ámbito de la gobernanza de la IA y se está convirtiendo rápidamente en un requisito de cumplimiento normativo.
Paso 7: Medir y elaborar un informe
Realiza un seguimiento de cuatro métricas: el tiempo medio de detección (MTTD) de incidentes de datos, el tiempo medio de resolución (MTTR), el número de incidentes por dominio al mes y la tasa de cumplimiento de los SLA del proceso. Presenta estos datos mensualmente a los responsables de gobernanza. Un programa de observabilidad maduro debería mostrar una disminución del MTTD y del MTTR con el paso del tiempo, a medida que mejoran los valores de referencia y maduran los flujos de trabajo de respuesta a incidentes.
Observabilidad de los datos en los sectores regulados
Servicios financieros:Las interrupciones en el suministro de datosen el sector financiero tienen consecuencias normativas directas. Un informe de riesgos retrasado, un archivo de posiciones dañado o una fuente de datos de mercado desactualizada pueden acarrear sanciones. La norma BCBS 239 exige a los bancos que demuestren la exactitud y la puntualidad de los datos para la presentación de informes de riesgos, requisitos que la observabilidad de los datos cumple como resultado de la supervisión continua. El cumplimiento de la ley SOX exige datos fiables para la presentación de informes financieros, y la observabilidad proporciona el registro de auditoría sobre el estado de los datos que necesitan los auditores.
Sanidad:Los sistemas de apoyo a la toma de decisiones clínicas, los procesos de facturación y los sistemas de historiales de pacientes requieren datos fiables. Un retraso en la recepción de los resultados de laboratorio, un cambio en el esquema de datos que inhabilite las tablas de consulta de medicamentos o un identificador de paciente dañado no son solo problemas operativos, sino que suponen riesgos para la seguridad de los pacientes. La observabilidad de los datos permite una supervisión continua de los datos que alimentan los sistemas clínicos, con los registros de auditoría que exige el cumplimiento de la HIPAA.
Comercio minorista y comercio electrónico: La calidad de los datos de inventario afecta directamente al cumplimiento de los pedidos: unos niveles de existencias obsoletos o inexactos provocan un exceso de ventas. La actualidad de los datos de los clientes afecta a la personalización: las recomendaciones basadas en los datos de navegación del día anterior no tienen en cuenta el comportamiento de la misma sesión. Los modelos de detección de fraudes requieren datos de transacciones actualizados y precisos. La observabilidad supervisa estos tres aspectos de forma continua y avisa cuando alguno de ellos se sale de los límites esperados.
Productos farmacéuticos: Los datos de ensayos clínicos y de calidad de fabricación deben demostrar su integridad conforme a la norma 21 CFR Parte 11 de la FDA y a las normativas GxP. La observabilidad permite supervisar de forma continua los datos que se utilizan en las presentaciones reglamentarias, así como los registros de auditoría que demuestran la integridad de los datos a lo largo de todo su ciclo de vida.
Observabilidad de los datos e inteligencia artificial
El auge de los sistemas de inteligencia artificial está generando una nueva demanda de capacidades de observabilidad de datos para las que las herramientas de supervisión tradicionales no estaban diseñadas.
Observabilidad de los datos de entrenamiento: La fiabilidad de los modelos de IA depende de la calidad de los datos con los que se han entrenado. La observabilidad aplicada a los conjuntos de datos de entrenamiento supervisa los índices de calidad, los índices de exhaustividad y las características de distribución en el momento del entrenamiento, y detecta cuándo estos cambian de forma que puedan afectar al comportamiento del modelo. Cuando una sesión de reentrenamiento utiliza datos procedentes de una fuente cuya calidad se ha deteriorado durante dos semanas, la observabilidad de los datos de entrenamiento lo detecta antes de que se implemente el modelo.
Observabilidad de los flujos de características:Los flujos de características basados en aprendizaje automáticotransforman los datos sin procesar en las entradas que consumen los modelos. La observabilidad de los flujos de características supervisa las distribuciones de las características comparándolas con los valores de referencia del entrenamiento y emite alertas cuando la deriva supera los umbrales definidos. La detección temprana de la deriva permite a los equipos volver a entrenar o ajustar los modelos antes de que el rendimiento se vea afectado en producción.
Observabilidad de los flujos de trabajo de los modelos de lenguaje a gran escala (LLM):Las aplicaciones de los modelos de lenguaje a gran escalaplantean nuevos requisitos de observabilidad: supervisar la calidad y la actualidad de los documentos en los almacenes de recuperación RAG, realizar un seguimiento de los patrones de interacción entre prompts y respuestas para detectar resultados inesperados, y supervisar los datos que alimentan los flujos de trabajo de ajuste fino. La observabilidad de los datos se extiende a estos nuevos tipos de flujos de trabajo a medida que maduran los requisitos de gobernanza de la IA.
Supervisión de las entradas del modelo:En el caso delos modelos desplegados, la observabilidad supervisa la distribución de las solicitudes de predicción entrantes comparándola con la distribución utilizada en el entrenamiento. Cuando los datos que recibe un modelo en producción se desvían significativamente de aquellos con los que se entrenó, el rendimiento del modelo se ve afectado. La supervisión de las entradas detecta esta desviación de forma temprana, a menudo semanas antes de que se haga visible en las métricas de rendimiento del modelo.
Preguntas frecuentes
La observabilidad de los datos es un sistema que supervisa continuamente tus flujos de datos y tus almacenes de datos, y te avisa cuando algo va mal, antes de que tus partes interesadas se den cuenta de que un panel de control no funciona o de que hay una cifra errónea en un informe.
Frescura (¿lleguen los datos según lo previsto?), volumen (¿se recibe el número correcto de registros?), esquema (¿ha cambiado la estructura de los datos de forma inesperada?), calidad (¿se encuentran los valores de los campos dentro de los rangos esperados?) y linaje (¿qué depende de estos datos y de dónde proceden?). En conjunto, ofrecen una visibilidad completa del estado de los datos.
El tiempo de inactividad de los datos es cualquier periodo en el que los datos son parciales, erróneos, están incompletos o, de cualquier otra forma, no son fiables. Es el equivalente en el ámbito de los datos al tiempo de inactividad de las aplicaciones. La observabilidad de los datos tiene como objetivo reducir el tiempo de inactividad de los datos mediante la detección temprana de problemas y la resolución más rápida de los mismos.
La calidad de los datos mide si estos cumplen con los estándares definidos en un momento dado. La observabilidad de los datos supervisa los datos de forma continua en múltiples dimensiones y avisa cuando su comportamiento se desvía de los patrones esperados, incluyendo fallos que ninguna regla de calidad predefinida detectaría. La gestión de la calidad define qué se considera «correcto». La observabilidad supervisa si ese «correcto» sigue siendo válido.
La supervisión de datos aplica comprobaciones programadas en función de umbrales predefinidos. La observabilidad de datos tiene un alcance más amplio: aprende dinámicamente cuál es el comportamiento normal de cada activo y detecta anomalías que se salen de los patrones aprendidos, no solo de las reglas predefinidas. La supervisión detecta los modos de fallo conocidos. La observabilidad detecta los desconocidos.
Se conecta a tus fuentes de datos y recopila metadatos de forma continua; aprende los patrones de referencia de cada activo; detecta anomalías mediante métodos estadísticos y aprendizaje automático; activa alertas con información contextual sobre la causa probable y el impacto en las fases posteriores; y se integra con tu catálogo de datos y tus flujos de trabajo de gestión para gestionar los incidentes hasta su resolución.
Las conexiones iniciales y la supervisión básica de la actualidad y el volumen de los flujos de datos prioritarios pueden estar operativas en una semana. La detección de anomalías requiere entre 2 y 4 semanas para el aprendizaje de la línea de base. La cobertura completa de todos los flujos de datos críticos, con integración del linaje y supervisión de los flujos mediante IA, suele llevar entre 2 y 3 meses para equipos de datos de tamaño medio.
El retorno de la inversión (ROI) proviene de tres fuentes: la reducción del tiempo que dedican los ingenieros a la investigación reactiva de incidencias (el tiempo medio de detección y resolución se reduce significativamente), el menor número de decisiones erróneas tomadas a partir de datos poco fiables y la identificación más rápida de problemas de calidad de los datos antes de que afecten a los sistemas de producción o a las presentaciones reglamentarias. La mayoría de las organizaciones recuperan su inversión en observabilidad en un plazo de entre 6 y 12 meses solo gracias al ahorro de tiempo de los ingenieros.
La observabilidad de los datos supervisa la calidad y la actualidad de los conjuntos de datos de entrenamiento, detecta desviaciones en la distribución de las características antes de que se produzca un deterioro en el rendimiento del modelo y realiza un seguimiento de los datos que alimentan los modelos implementados en producción. A medida que maduran las normativas sobre gobernanza de la IA, la supervisión continua de los datos del proceso de la IA se está convirtiendo en un requisito de cumplimiento normativo, más que en una buena práctica.
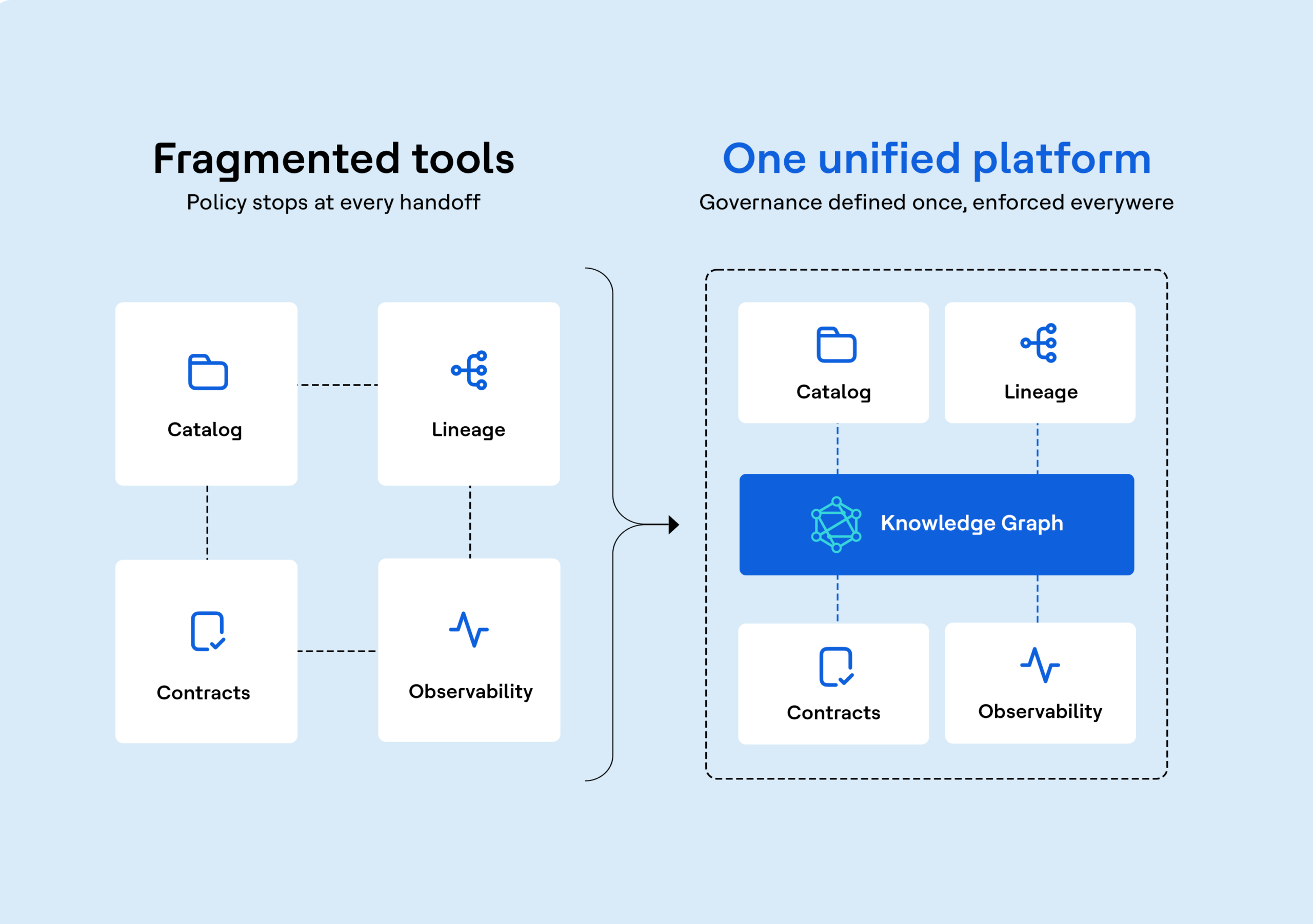
Un catálogo de datos documenta qué activos de datos existen y sus metadatos. La observabilidad de los datos supervisa de forma continua el estado de dichos activos. Ambos elementos funcionan conjuntamente: un catálogo enriquecido con datos de observabilidad muestra a los usuarios no solo qué activos existen, sino también si se encuentran actualmente en buen estado, cuándo se produjo su última incidencia y cuál es su historial de fiabilidad. En conjunto, proporcionan a los usuarios de datos tanto la posibilidad de descubrir los activos como la confianza en ellos.