La gestión de metadatos consiste en recopilar, organizar, controlar y mantener los metadatos —la información que describe los activos de datos — para que todos los equipos de la organización puedan encontrar, comprender, confiar en los datos y utilizarlos sin tener que depender de conocimientos implícitos.
Cuando la gestión de metadatos funciona correctamente, un analista que busca un conjunto de datos sobre ingresos lo encuentra en cuestión de segundos, sabe quién es el responsable de los mismos, comprende el significado de cada campo y puede comprobar si ha sido certificado para su inclusión en los informes. Cuando no funciona, ese mismo analista se pasa dos días enviando mensajes por Slack y, aun así, no está seguro de si la cifra es correcta.
Esta guía explica qué es la gestión de metadatos, cómo funciona, los tipos de metadatos que intervienen, la diferencia entre metadatos activos y pasivos, cómo crear un programa y qué aspectos hay que tener en cuenta a la hora de evaluar herramientas.
¿Qué es la gestión de metadatos?
La gestión de metadatos es la disciplina integral que abarca la recopilación, organización, mantenimiento y control de los metadatos en todo el conjunto de datos de una organización, con el fin de que los activos de datos sean localizables, fiables y se utilicen de forma coherente.
Los metadatos son datos que describen otros datos. Una tabla llamada customer_transactions contiene metadatos: quién lo creó, cuándo se actualizó por última vez, qué significa cada columna, de dónde procede, qué puntuación de calidad tiene, quién puede acceder a él y de qué informes posteriores depende. La gestión de metadatos garantiza que este contexto exista, se mantenga actualizado y sea accesible para cualquiera que lo necesite.
Sin una gestión de metadatos, las organizaciones acumulan datos a un ritmo más rápido del que nadie puede documentar. Los activos pasan a ser imposibles de localizar. Las definiciones se van desviando. Un mismo campo puede tener significados distintos en distintos sistemas. Los equipos vuelven a crear conjuntos de datos que ya existen porque no pueden encontrar los originales. Las auditorías de cumplimiento normativo requieren semanas de reconstrucción manual.
Tipos de metadatos
Un programa completo de gestión de metadatos recoge y controla cinco categorías de metadatos.
| Tipo | Qué describe | Ejemplos |
|---|---|---|
| Metadatos empresariales | El significado, las definiciones y las clasificaciones de los activos de datos en términos empresariales | Términos del glosario empresarial, definiciones de datos, clasificaciones de dominios, titularidad |
| Metadatos técnicos | La estructura física y las características de almacenamiento de los activos de datos | Esquema, nombres de tablas, definiciones de columnas, tipos de datos, índices de valores nulos, número de filas |
| Metadatos operativos | Cómo se utilizan, consultan y tratan los datos a lo largo del tiempo | Frecuencia de consultas, registros de acceso, historial de ejecuciones del proceso de tratamiento de datos, programaciones de actualización |
| Metadatos de linaje | Cómo se mueven y se transforman los datos desde su origen hasta su consumo | Sistemas de origen, lógica de transformación, dependencias del proceso de tratamiento, consumidores posteriores |
| Metadatos de gobernanza | Las políticas, los controles y las estructuras de rendición de cuentas aplicadas a los activos de datos | Permisos de acceso, clasificaciones de confidencialidad (PII, PHI), asignaciones de gestión, contratos de datos, registros de auditoría |
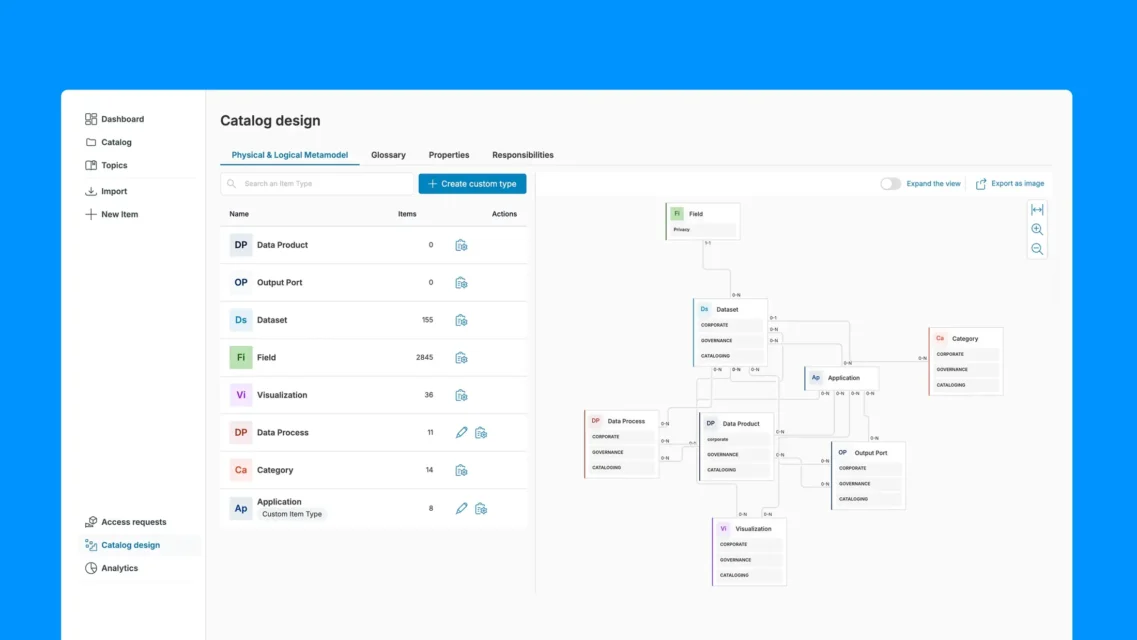
Una gestión eficaz de los metadatos recoge los cinco tipos e integra todos ellos en una única interfaz, de modo que un usuario que consulte cualquier activo de datos pueda ver su significado, estructura, historial de uso, linaje y estado de gobernanza sin necesidad de consultar varios sistemas.
Metadatos activos frente a metadatos pasivos
Esta distinción determina si un programa de gestión de metadatos se mantiene actualizado o si, con el paso del tiempo, va perdiendo precisión.
Los metadatos pasivos se recopilan en un momento determinado y se actualizan según una periodicidad establecida —actualizaciones por lotes diarias, semanales o mensuales—. La mayoría de los enfoques tradicionales de gestión de metadatos son pasivos. El catálogo refleja el estado del conjunto de datos a fecha de la última actualización. Entre una actualización y otra, se acumulan los cambios y el catálogo se va desviando de la realidad.
Los metadatos activos se actualizan continuamente a medida que cambian los datos. Cuando se ejecuta un proceso, se actualizan los registros de linaje. Cuando llegan nuevos datos, se recalculan las puntuaciones de calidad. Cuando cambia un esquema, el catálogo lo detecta y señala los activos afectados en las fases posteriores. El catálogo refleja el estado actual del conjunto de datos, no una instantánea programada.
| Metadatos pasivos | Metadatos activos | |
|---|---|---|
| Frecuencia de actualización | Lote programado (diario, semanal) | Continuo, basado en eventos |
| Precisión | Desviaciones entre ciclos de actualización | Refleja la situación actual |
| Control de calidad | Instantáneas de un momento concreto | Detección de anomalías en tiempo real |
| Linaje | Actualizado según lo previsto | Actualizaciones cuando se ejecutan los procesos automatizados |
| Scale | Los procesos manuales limitan la capacidad de expansión | Los procesos automatizados se adaptan al volumen de datos |
| Gobernanza | Políticas aplicadas manualmente | Políticas que se aplican automáticamente en el momento del acceso |
La mayoría de las empresas comienzan con metadatos pasivos y van pasando a los metadatos activos a medida que sus programas maduran. Este cambio es posible gracias a las herramientas: los metadatos activos requieren una plataforma capaz de supervisar las fuentes de forma continua, procesar eventos en tiempo real y actualizar los registros del catálogo sin intervención humana.
Cómo funciona la gestión de metadatos
Un programa de gestión de metadatos sigue un ciclo continuo que abarca seis etapas:
1. Detección e ingesta:Elsistema de gestión de metadatos se conecta a todas las fuentes de datos de la organización —bases de datos, almacenes en la nube, lagos de datos, aplicaciones SaaS, plataformas de streaming, herramientas de BI, almacenes de características de aprendizaje automático— y analiza automáticamente los metadatos técnicos: nombres de tablas, definiciones de columnas, tipos de datos, recuentos de filas, índices de valores nulos y relaciones. Las nuevas fuentes se detectan y se añaden al inventario sin necesidad de registrarlas manualmente.
2. Clasificación y enriquecimiento: Los activos escaneados se clasifican automáticamente por tipo, sensibilidad y ámbito. Los modelos de aprendizaje automático identifican la información de identificación personal (PII), la información sanitaria protegida (PHI), los datos financieros y otros contenidos regulados, y les aplican etiquetas de clasificación con puntuaciones de confianza. Los metadatos empresariales —definiciones, enlaces a términos del glosario, asignaciones de ámbitos, titularidad— se añaden mediante sugerencias automatizadas y la revisión de los responsables.
3. Mapeo de linaje: El sistema rastrea cada activo desde su origen hasta sus consumidores finales, pasando por cada transformación, unión, agregación y paso del proceso. Los registros de linaje se actualizan automáticamente cuando se ejecutan los procesos. El linaje a nivel de columna realiza un seguimiento de las transformaciones de campos individuales, no solo de los flujos a nivel de tabla.
4. Gobernanza y aplicación de políticas: Las políticas de acceso, las normas de conservación y los controles de cumplimiento se aplican a los activos en función de su clasificación y titularidad. Las solicitudes de acceso se tramitan a través de flujos de trabajo de aprobación definidos. La aplicación de las políticas se lleva a cabo en el momento de la solicitud, de forma automática, en lugar de mediante auditorías manuales periódicas.
5. Búsqueda y descubrimiento: Todos los metadatos se indexan en una interfaz de catálogo con función de búsqueda. Los usuarios realizan búsquedas utilizando lenguaje empresarial, filtran por ámbito, propietario, nivel de confidencialidad, puntuación de calidad y estado de certificación, y recuperan activos de todo el conjunto de datos. La búsqueda semántica reconoce sinónimos y terminología específica de cada ámbito sin necesidad de que los nombres de los campos coincidan exactamente.
6. Supervisión y mantenimiento: Se realizan controles de calidad de forma continua en las fuentes conectadas. Las anomalías —descensos inesperados en el recuento de filas, cambios en el esquema, picos en la tasa de valores nulos, cambios en la distribución— activan alertas y flujos de trabajo de gestión. Las métricas de estado de los metadatos informan sobre la cobertura, la actualidad y la integridad de todo el catálogo.
¿Quién utiliza la gestión de metadatos y cómo?
Analista de datos: Busca un conjunto de datos en el catálogo utilizando términos empresariales. Localiza el activo, revisa su definición, su puntuación de calidad y su estado de certificación, confirma su linaje hasta un sistema fuente de confianza y lo consulta con seguridad. No necesita preguntar a un ingeniero si se trata de la tabla correcta.
Responsable de datos: Supervisa el estado de los metadatos en su ámbito de competencia. Revisa las sugerencias de clasificación generadas automáticamente, resuelve los incidentes de calidad señalados por el sistema de supervisión, actualiza los términos del glosario empresarial cuando cambian las definiciones y certifica los activos que cumplen los umbrales de calidad definidos. Todas las acciones se registran con fines de auditoría.
Ingeniero de datos: Realiza un análisis de impacto antes de un cambio en el esquema mediante la revisión del linaje para identificar todos los activos posteriores que se verían afectados. Tras un cambio en el proceso de integración de datos, el linaje actualizado se refleja automáticamente en el catálogo sin necesidad de documentación manual.
Responsable de cumplimiento normativo: Genera informes listos para auditoría que muestran dónde se encuentra la información de carácter personal (PII) en todo el entorno, cómo se ha clasificado, quién ha accedido a ella y qué controles se aplican. Responde a las solicitudes reglamentarias a partir de los registros mantenidos como parte de la gestión rutinaria de metadatos, en lugar de hacerlo mediante un ejercicio de auditoría independiente.
Científico de datos: Encuentra conjuntos de datos de entrenamiento certificados y con puntuación de calidad, acompañados de documentación completa sobre su linaje. Es capaz de reproducir cualquier sesión de entrenamiento de un modelo y demostrar a los auditores exactamente qué datos se utilizaron para alimentar qué versión del modelo, cuándo y bajo qué condiciones de gobernanza.
Director de Datos:Supervisala cobertura de los metadatos, el estado de la calidad y la situación de la gobernanza en toda la organización a través de una única interfaz. Identifica los ámbitos con baja cobertura de metadatos o con un elevado número de incidencias pendientes y asigna los recursos de gestión en consecuencia.
Gestión de metadatos y el catálogo de datos
Un catálogo de datos es la interfaz principal a través de la cual se lleva a la práctica la gestión de metadatos. Ambos conceptos son distintos, pero inseparables.
La gestión de metadatos es tanto la práctica como el programa: los procesos, las normas, las funciones y la gobernanza que determinan cómo se recogen, mantienen y utilizan los metadatos.
Un catálogo de datos es la herramienta que permite acceder a esos metadatos: la interfaz regulada y con función de búsqueda en la que los usuarios encuentran los activos, los responsables mantienen las definiciones y los equipos de cumplimiento normativo acceden a los registros de auditoría.
Sin un catálogo de datos, la gestión de metadatos genera documentación que queda relegada a hojas de cálculo y wikis internas: técnicamente existe, pero nadie es capaz de encontrarla. Sin gestión de metadatos, un catálogo de datos se llena de entradas obsoletas, incompletas o incoherentes en las que los usuarios aprenden a no confiar.
La relación entre ambos determina si un programa de metadatos aporta valor o si simplemente genera trabajo.
Gestión de metadatos y gobernanza de datos
La gestión de metadatos es la columna vertebral operativa de la gobernanza de datos. La gobernanza define las políticas: qué datos deben clasificarse, quién puede acceder a ellos, qué estándares de calidad deben cumplir y durante cuánto tiempo deben conservarse. La gestión de metadatos aplica esas políticas mediante el registro de las clasificaciones, los registros de acceso, las puntuaciones de calidad y el linaje, lo que hace que la gobernanza sea visible y auditable.
| La gobernanza de datos ofrece | Se lleva a cabo la gestión de metadatos |
|---|---|
| Normas de clasificación de datos | Se ha aplicado el etiquetado de sensibilidad a todos los activos |
| Políticas de control de acceso | Registros de acceso, flujos de trabajo de aprobación, registros de permisos |
| Normas de calidad de los datos | Puntuaciones de calidad, normas de validación, estado de la certificación |
| Requisitos de linaje | Registros automatizados de linajes que se actualizan continuamente |
| Políticas de conservación | Metadatos del ciclo de vida, registros de archivo y de eliminación |
| Requisitos de cumplimiento | Registros de auditoría, informes reglamentarios, pruebas de cumplimiento de las políticas |
Los marcos de gobernanza como DAMA-DMBOK, DCAM e ISO 8000 identifican la gestión de metadatos como un componente fundamental de la gobernanza de los datos empresariales. Un programa de gobernanza que no invierta en la gestión de metadatos no puede demostrar el cumplimiento normativo, mantener la calidad de los datos ni ampliar la rendición de cuentas en un entorno de datos en constante crecimiento.
Creación de un programa de gestión de metadatos
Paso 1: Realizar una auditoría de la situación actual
Antes de implementar herramientas o definir procesos, es importante conocer qué metadatos existen actualmente, dónde se encuentran y qué grado de coherencia presentan. Identifica los ámbitos de datos que presentan un mayor riesgo empresarial o exposición normativa —datos de información financiera, registros de clientes, información médica protegida (PHI)— y priorízalos para el alcance inicial del programa.
Paso 2: Definir las normas de metadatos
Establece las normas que se aplicarán en toda la organización: convenciones de nomenclatura, campos de metadatos obligatorios para cada tipo de activo, taxonomía de clasificación de sensibilidad, umbrales de calidad y proceso de gestión de los términos del glosario. Las normas definidas desde el principio evitan la falta de coherencia que hace que los metadatos no sean fiables.
Paso 3: Conectar las fuentes y automatizar la importación
Implementa una plataforma de gestión de metadatos con conectores nativos para todas las fuentes de datos prioritarias. Configura el análisis y la clasificación automáticos. Revisa los resultados iniciales de la clasificación automática y corrige los errores para mejorar la precisión del modelo de cara a futuros análisis.
Paso 4: Elaborar el glosario empresarial de forma colaborativa
Colabora con los responsables de los distintos ámbitos —finanzas, marketing, producto y operaciones— para validar las sugerencias de términos del glosario generadas automáticamente y subsanar las lagunas. Los términos que las partes interesadas de la empresa han ayudado a definir son los que estas mismas partes utilizan. Asigna un responsable a cada término, de modo que haya una persona designada encargada de mantenerlo actualizado.
Paso 5: Asignar la gestión por ámbito
Identifica a los responsables de cada ámbito de datos prioritario. Define sus responsabilidades: de qué activos son responsables, qué umbrales de calidad deben garantizar, cómo tramitan las solicitudes de acceso y con qué frecuencia revisan el estado de los metadatos. Una gestión sin responsabilidades bien definidas da lugar a una cobertura inconsistente.
Paso 6: Establecer normas de calidad y criterios de certificación
Definir qué hace que un activo sea certificable: índice mínimo de integridad, índice de valores nulos aceptable, actualidad requerida, documentación obligatoria sobre el historial. Los responsables aplican estos criterios de forma coherente. Los usuarios confían en los activos certificados sin necesidad de una validación independiente.
Paso 7: Evaluar el estado del programa
Realiza un seguimiento de la tasa de cobertura de los metadatos (porcentaje de activos con metadatos completos), las tendencias en la puntuación de calidad por ámbito, el tiempo medio de resolución de los problemas relacionados con los metadatos, la tasa de cobertura del glosario y el volumen de trabajo pendiente en materia de gestión de datos. Informa periódicamente de estos datos a los responsables de gobernanza. Los programas que no pueden evaluarse a sí mismos no pueden mejorar.
Gestión de metadatos en sectores regulados
Servicios financieros: La norma BCBS 239 exige a los bancos que demuestren el origen de los datos y cumplan los estándares de calidad en la presentación de informes de riesgos. Un programa de gestión de metadatos genera esta documentación como resultado de las operaciones diarias. El cumplimiento de la ley SOX exige el mantenimiento de registros de auditoría para los datos financieros. La gestión de metadatos mantiene dichos registros de forma automática.
Sanidad: La HIPAA exige una rendición de cuentas documentada de la información médica protegida (PHI): clasificación, controles de acceso y registros de auditoría para cada acceso. Un programa de gestión de metadatos clasifica automáticamente la PHI, aplica controles de acceso en el momento de la solicitud y registra cada acceso sin necesidad de preparar manualmente los registros de auditoría.
Productos farmacéuticos: La norma 21 CFR Parte 11 de la FDA y las normativas GxP exigen la documentación de la integridad de los datos clínicos y de fabricación. La gestión de metadatos mantiene el historial y los registros de auditoría que demuestran la integridad de los datos en entornos de investigación complejos que abarcan múltiples sistemas.
Tecnología financiera y pagos: La norma PCI DSS exige controles estrictos sobre los datos de los titulares de tarjetas. La gestión de metadatos clasifica automáticamente los activos que contienen datos de tarjetas, aplica restricciones de acceso y genera las pruebas de cumplimiento que exigen las auditorías PCI.
Qué hay que tener en cuenta a la hora de elegir una plataforma de gestión de metadatos
Amplitud de la conectividad:¿Seconecta de forma nativa con todas las fuentes de tu entorno: almacenes en la nube, bases de datos locales, sistemas de streaming, herramientas de BI, aplicaciones SaaS y almacenes de características de aprendizaje automático? Las lagunas en la conectividad provocan lagunas en la cobertura de los metadatos.
Nivel de automatización: ¿Qué parte de la captura de metadatos, la clasificación, el mapeo de linaje y el control de calidad se realiza de forma automática y qué parte requiere intervención manual? A escala empresarial, los programas que dependen de la introducción manual de metadatos no pueden seguir el ritmo del volumen de datos.
Nivel de detalle del historial: ¿La plataforma realiza el seguimiento del linaje a nivel de columna o solo a nivel de tabla? El linaje a nivel de columna es necesario para el análisis de impacto y la trazabilidad normativa en los sectores regulados.
Compatibilidad con metadatos activos: ¿Actualiza la plataforma los metadatos de forma continua a medida que cambian los datos, o se basa en actualizaciones por lotes programadas? Los metadatos activos marcan la diferencia entre un catálogo que refleja la realidad y uno que refleja la situación de la semana pasada.
Integración de la gobernanza: ¿Se integra la gestión de metadatos directamente con los flujos de trabajo de control de acceso, calidad de los datos y gestión de datos, o funciona como un sistema de documentación independiente? La integración es lo que hace que los metadatos sean útiles en la práctica, en lugar de limitarse a ser meramente informativos.
Calidad de la búsqueda: ¿Pueden los usuarios empresariales encontrar recursos utilizando lenguaje natural y términos empresariales, o la búsqueda requiere nombres exactos de campos técnicos? Un catálogo por el que solo los ingenieros pueden navegar no aporta valor a toda la organización.
Escalabilidad: ¿Cómo se comporta la plataforma a medida que el número de activos pasa de miles a cientos de miles? Pide a los proveedores que te faciliten clientes de referencia con una escala similar a la tuya y del mismo sector.
Preguntas frecuentes
La gestión de metadatos es la práctica: los procesos, las normas, las funciones y la gobernanza que determinan cómo se recogen, mantienen y utilizan los metadatos. Un catálogo de datos es la herramienta que permite acceder a esos metadatos a través de una interfaz regulada y en la que se pueden realizar búsquedas. Se necesita la práctica para garantizar la precisión de la herramienta, y la herramienta para que la práctica sea escalable.
La gobernanza de datos define las políticas: normas de clasificación, reglas de acceso, umbrales de calidad y requisitos de conservación. La gestión de metadatos aplica esas políticas mediante el registro y el mantenimiento de las clasificaciones, los registros de acceso, las puntuaciones de calidad y el linaje, lo que hace que la gobernanza sea visible y auditable. Ambos aspectos son interdependientes: la gobernanza sin gestión de metadatos da lugar a políticas que no pueden aplicarse; la gestión de metadatos sin gobernanza da lugar a datos sin normas coherentes.
Metadatos de negocio (definiciones y clasificaciones), metadatos técnicos (esquema y estructura), metadatos operativos (historial de uso y procesamiento), metadatos de linaje (flujo de datos y transformaciones) y metadatos de gobernanza (políticas, controles de acceso y asignaciones de gestión). Los programas eficaces recogen e integran estos cinco tipos de metadatos.
Los metadatos pasivos se recopilan en un momento determinado y se actualizan periódicamente. Entre un ciclo de actualización y otro, se van desviando de la realidad. Los metadatos activos se actualizan continuamente a medida que cambian los datos: el linaje se actualiza cuando se ejecutan los flujos de trabajo, las puntuaciones de calidad se actualizan cuando llegan nuevos datos y las clasificaciones se ajustan cuando cambia el contenido. Los metadatos activos mantienen la precisión del catálogo sin necesidad de mantenimiento manual.
Las conexiones iniciales con las fuentes y la ingesta automatizada de metadatos para los ámbitos prioritarios pueden estar operativas en cuestión de días. La creación de un glosario empresarial, la asignación de responsabilidades, la definición de estándares de calidad y el establecimiento de flujos de trabajo de gobernanza suelen llevar entre 8 y 16 semanas en el caso de las organizaciones de tamaño medio. La implantación completa en toda la empresa, en todos los ámbitos, lleva más tiempo, dependiendo de la complejidad del entorno y del número de fuentes implicadas.
Sí. Las plataformas de gestión de metadatos empresariales se conectan a entornos híbridos mediante conectores nativos, sin necesidad de trasladar los datos a una ubicación central. Los metadatos se recopilan de cada fuente y se unifican en el catálogo; los datos subyacentes permanecen donde están.
Los modelos de IA requieren datos de entrada limpios, trazables y regulados. Un programa de gestión de metadatos realiza un seguimiento del linaje y la calidad de los conjuntos de datos de entrenamiento, clasifica los datos sensibles para evitar que entren en los flujos de trabajo de IA sin haber sido revisados y mantiene los registros de auditoría que demuestran la reproducibilidad de los modelos y el cumplimiento normativo. A medida que las organizaciones crean flujos de trabajo RAG y modelos de lenguaje grande (LLM) ajustados, la gestión de metadatos extiende esas mismas disciplinas a los datos de entrada y salida de la IA.
Los responsables de datos son los encargados operativos de los metadatos en su ámbito asignado. Revisan las clasificaciones generadas automáticamente, mantienen los términos del glosario empresarial, supervisan los índices de calidad, resuelven problemas relacionados con los metadatos, certifican los activos fiables y tramitan las solicitudes de acceso. Las herramientas de gestión de metadatos automatizan todo lo posible; los responsables aportan el criterio humano y los conocimientos especializados del ámbito que la automatización no puede sustituir.
El RGPD exige a las organizaciones saber dónde se encuentran los datos personales, cómo se utilizan, quién puede acceder a ellos y cómo localizarlos y eliminarlos cuando se solicite. Un programa de gestión de metadatos clasifica automáticamente los activos de datos personales, aplica controles de acceso, mantiene registros de auditoría de cada evento de acceso y utiliza el linaje para rastrear los datos personales a lo largo de todos los sistemas por los que pasan, lo que convierte el cumplimiento del RGPD en un resultado operativo natural, en lugar de un ejercicio de auditoría periódico.


