Cómo le ayuda Actian Vector a eliminar los cubos OLAP




Actian Vector was renamed to Actian Analytics Engine in 2026.
Los cubos OLAP (OnLine Analytical Processing) se utilizan ampliamente en la actualidad porque muchas plataformas de bases de datos no pueden analizar grandes volúmenes de datos con rapidez. Esto se debe a que la mayoría de los programas de bases de datos no aprovechan al máximo la potencia de cálculo y la memoria para ofrecer un rendimiento óptimo. Algunos de los síntomas de esto son:
- Las consultas de gran tamaño acaban acaparando los recursos del servidor.
- La respuesta se vuelve más lenta a medida que aumentan el volumen de datos y el número de usuarios.
- La gestión de consultas simultáneas resulta difícil o imposible.
- Las tablas agregadas o materializadas adicionales, los índices y, en ocasiones, incluso los data marts individuales no logran ofrecer el rendimiento y la concurrencia necesarios.
Los cubos OLAP se crearon para satisfacer la necesidad de los usuarios de BI de agregar, segmentar y analizar rápidamente grandes cantidades de datos con el fin de responder a una serie de preguntas predeterminadas. A continuación, veremos cómo podemos utilizar Actian Vector, nuestra base de datos analítica columnar de alta velocidad, para prescindir del uso de cubos OLAP.
¿Cuáles son las desventajas de utilizar almacenes de cubos OLAP?
- Inversiones adicionales en hardware y software, así como gastos de mantenimiento continuos.
- Para consultar los cubos OLAP se requieren conocimientos totalmente nuevos sobre el lenguaje MDX (Multi-Dimensional Expressions).
- Impone un esquema estricto (en estrella o en copo de nieve), mientras que algunos de los almacenes de cubos de última generación admiten tablas en 3NF (o modelos ROLAP). Sin embargo, el mejor rendimiento siempre se obtiene con un esquema en estrella.
- Limitan la flexibilidad de las consultas ad hoc. El diseño del cubo OLAP requiere una gran reflexión. Una vez creado, solo se podrán consultar las filas y columnas que se hayan incluido. A menudo, se necesita un nuevo cubo para cada nueva consulta.
- Esto aumenta considerablemente el tiempo de procesamiento y genera nuevos cuellos de botella en el ciclo de vida de la inteligencia empresarial. El usuario de BI tendría que pagar un alto precio en forma de pérdida de tiempo si el cubo OLAP se creara de forma incorrecta. La actualidad de los datos se ve comprometida, ya que estos deben trasladarse desde los sistemas operativos al almacén de datos, al cubo OLAP y, posteriormente, a las herramientas de BI.
Echando un vistazo bajo el capó
Veamos a qué renuncias con un cubo OLAP. He aquí un ejemplo sencillo en el que los datos sin procesar de la base de datos relacional subyacente tienen el siguiente aspecto:
| Fecha de venta | Año | mes | década | ciudad _id | nombre de la ciudad | estado | Región _id | Nombre de la región | ID del producto | Nombre del producto | Importe de las ventas |
| 1990 | 1990 | Enero | 1990-2000 | 1 | Palo Alto | CA | 1 | Oeste de EE. UU. | 1 | Tornillos | 20 |
| 1990 | 1990 | Enero | 1990-2000 | 1 | Palo Alto | CA | 1 | Oeste de EE. UU. | 1 | Tornillos | 23 |
| 1990 | 1990 | Enero | 1990-2000 | 1 | Palo Alto | CA | 1 | Oeste de EE. UU. | 1 | Tornillos | 15 |
| 1993 | 1993 | Enero | 1990-2000 | 1 | Palo Alto | CA | 1 | Oeste de EE. UU. | 2 | martillo | 14 |
| 1993 | 1994 | mayo | 1990-2000 | 2 | La Jolla | CA | 2 | Oeste de EE. UU. | 3 | tornillos | 60 |
| 2003 | 2003 | Enero | 2000-2010 | 3 | Dallas | TX | 1 | Sur de EE. UU. | 1 | Tornillos | 12 |
| 1993 | 1993 | mayo | 2000-2010 | 4 | Atlanta | GA | 2 | Sur de EE. UU. | 3 | Tornillos | 34 |
| 2004 | 2004 | octubre | 2000-2010 | 5 | Nueva York | Nueva York | 1 | Este de EE. UU. | 1 | Tornillos | 35 |
| 2004 | 2004 | noviembre | 2000-2010 | 6 | Boston | Máster | 1 | Este de EE. UU. | 1 | Tornillos | 37 |
| 2004 | 2004 | diciembre | 2000-2010 | 1 | Palo Alto | CA | 1 | Oeste de EE. UU. | 1 | Tornillos | 39 |
| 2004 | 2004 | Enero | 2000-2010 | 1 | Palo Alto | CA | 1 | Oeste de EE. UU. | 1 | Tornillos | 42 |
| 2004 | 2004 | febrero | 2000-2010 | 7 | Madison | WI | 1 | Centro de EE. UU. | 1 | Tornillos | 44 |
| 2004 | 2004 | marzo | 2000-2010 | 8 | Chicago | IL | 1 | Centro de EE. UU. | 2 | martillo | 46 |
| 2011 | 2011 | abril | 2010-2020 | 9 | Salt Lake City | UT | 2 | Oeste de EE. UU. | 3 | tornillos | 49 |
| 2012 | 2012 | mayo | 2010-2020 | 1 | Palo Alto | CA | 2 | Oeste de EE. UU. | 1 | Tornillos | 51 |
| 2013 | 2013 | junio | 2010-2020 | 2 | La Jolla | CA | 2 | Oeste de EE. UU. | 3 | Tornillos | 53 |
| 2014 | 2014 | julio | 2010-2020 | 10 | Jersey City | Nueva Jersey | 2 | Este de EE. UU. | 1 | Tornillos | 56 |
Si un usuario está interesado en crear un cubo OLAP sencillo sobre las ventas a partir de los datos anteriores y las métricas de interés son los importes de ventas agregados por década, año, producto y región, el cubo OLAP contendría los siguientes datos:
| Década | Año | Nombre de la región | Nombre del producto | Importe de ventas | Precio medio |
| 1990-2000 | 1994 | Oeste de EE. UU. | Tornillos | $60.00 | $19.33 |
| 1990-2000 | 1993 | Sur de EE. UU. | Tornillos | $34.00 | $14.00 |
| 1990-2000 | 2003 | Sur de EE. UU. | Tornillos | $12.00 | $60.00 |
| 2000-2010 | 2004 | Centro de EE. UU. | Tornillos | $44.00 | $34.00 |
| 2000-2010 | 2004 | Centro de EE. UU. | Martillo | $46.00 | $12.00 |
| 2000-2010 | 2004 | Este de EE. UU. | Tornillos | $72.00 | $44.00 |
| 2000-2010 | 2004 | Oeste de EE. UU. | Tornillos | $81.00 | $46.00 |
| 2000-2010 | 2011 | Oeste de EE. UU. | Tornillos | $49.00 | $36.00 |
| 2010-2020 | 2012 | Oeste de EE. UU. | Tornillos | $51.00 | $40.50 |
| 2010-2020 | 2013 | Oeste de EE. UU. | tornillos | $53.00 | $49.00 |
| 2010-2020 | 2014 | Este de EE. UU. | Tornillos | $56.00 | $51.00 |
| 2010-2020 | 1994 | Oeste de EE. UU. | Tornillos | $60.00 | $53.00 |
Los datos se agrupan por década, año, nombre de la región y nombre del producto. Se pierde el detalle a nivel de transacción. Por este motivo, algunos de los cubos OLAP más avanzados ofrecen una función de desglose que permite al usuario consultar los datos detallados. Sin embargo, el rendimiento podría verse afectado si el volumen de datos subyacente a la agregación es elevado.
Una consulta MDX típica para obtener estos datos del cubo tendría este aspecto, en función de lo que el usuario desee ver en las filas, las columnas y los puntos de datos.
WITH
MEMBER[measures].[avg price] AS
'[measures].[sales_amt] / [measures].[sales_num]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} EN COLUMNAS,
{[product].members, [year].members} EN FILAS
FROM SALES_CUBE
El «Avg_price» es una medida calculada. Tenga en cuenta que las medidas calculadas pueden especificarse en la definición del cubo OLAP o definirse en la consulta MDX. Una de las ventajas de las medidas calculadas definidas en los cubos OLAP es que, si se modifica la consulta para incluir un filtro o se añade una dimensión adicional, la medida calculada se recalculará automáticamente con los nuevos parámetros.
Así pues, el cubo OLAP acaba siendo una solución parcial a un problema: las bases de datos relacionales orientadas a filas simplemente no son lo suficientemente rápidas para las consultas analíticas. ¿Qué pedirían tus usuarios de OLAP si pudieran tener todo lo que quisieran? Lo que nos transmiten los usuarios son estos requisitos:
- Velocidad similar a la de OLAP o superior, con compatibilidad total con consultas ad hoc
- La posibilidad de utilizar cualquier modelo de datos que deseen
- Todas sus herramientas de BI favoritas
- Los datos más recientes disponibles
- Acceso a datos detallados completos en la misma consulta, sin sacrificar el rendimiento
¿Parece imposible? No lo es. Actian Vector puede ofrecerte todo esto y mucho más. ¿Cómo es posible? ¡Sigue leyendo!
Sustitución de cubos OLAP por Vector
Actian Vector se encuentra en una posición única para sustituir a los cubos OLAP. Lo hemos desarrollado desde cero con una serie de optimizaciones destinadas a aumentar considerablemente el rendimiento de las consultas analíticas. A continuación, ofrecemos un breve resumen de lo que hemos creado:
- Procesamiento vectorial: La vectorización lleva la paralelización a un nivel superior al enviar una única instrucción a múltiples puntos de datos, lo que permite obtener una respuesta casi en tiempo real.
- Almacenamiento en columnas: El almacenamiento en columnas reduce considerablemente las operaciones de E/S, ya que solo carga en memoria las columnas necesarias para una consulta, en lugar de cargar todas las columnas y seleccionar después las necesarias para satisfacer la consulta.
- Optimizado en memoria: el uso avanzado de la caché del procesador y la memoria principal, así como la compresión y descompresión en memoria, aceleran el proceso.
- Flexibility: Vector works with any data-model – star, snowflake, 3NF and de-normalized eliminating the need to create any type of materialization of data. Since the BI user is working off of the source of data, query freedom is not lost.
- Riqueza funcional: Las funciones avanzadas de OLAP y Windows permiten al usuario formular una amplia variedad de consultas complejas.
Pasar de Cubes a Actian Vector
Para migrar informes de BI desde cubos OLAP, es importante conocer las características de los cubos que deben migrarse. Entre ellas se incluyen:
- Modelo de cubo OLAP: comprender el modelo de datos del propio cubo y establecer una correspondencia con el modelo de datos del RDBMS.
- Consultas MDX, medidas calculadas y filtros que se están utilizando.
- KPI: indicadores clave de rendimiento.
- Análisis de hipótesis para diferentes escenarios.
Modelo de cubo OLAP
Analiza el cubo OLAP e identifica en qué tipo de modelo de datos se basa: ROLAP, HOLAP o MOLAP. Los modelos ROLAP se basan en modelos de datos en tercera forma normal (3NF), en los que los datos están altamente normalizados. Por lo general, el uso de modelos ROLAP en los cubos conlleva una pérdida de rendimiento.
HOLAP es un modelo híbrido en el que se utiliza una combinación de modelos en estrella o en copo de nieve, datos desnormalizados y la tercera forma normal (3NF). Esto también conlleva una pérdida de rendimiento.
MOLAP es el modelo subyacente más adecuado cuando se utiliza un modelo de datos en estrella o en copo de nieve, ya que ofrece el mejor rendimiento. Por lo general, en el ciclo de vida de la inteligencia empresarial, los datos de origen se encuentran en la tercera forma normal (3NF) y deben someterse a un largo proceso de transformación para convertirse en un modelo de esquema en estrella. Este esfuerzo inicial permite obtener un mejor rendimiento posteriormente.
Si se utiliza una consulta en la fuente de datos, es necesario tener en cuenta los siguientes factores:
- Dimensiones: ¿Cómo se calculan en el cubo? Especialmente para los modelos ROLAP y HOLAP.
- Medidas: tanto medidas calculadas como medidas normales.
- Datos: ¿Se trata de una sola tabla o de una combinación de tablas?
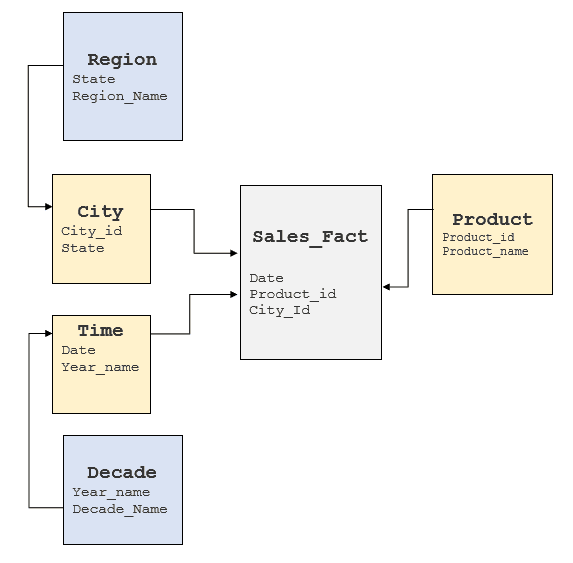
Es importante analizar los factores mencionados anteriormente para comprender el modelo de SGBDR subyacente y determinar dónde se pueden obtener estos elementos. Por lo general, los almacenes de datos implementan modelos en estrella o en copo de nieve, aunque algunos tienden a presentar un modelo altamente normalizado. En el caso del cubo anterior, un modelo típico en copo de nieve tendría el siguiente aspecto:
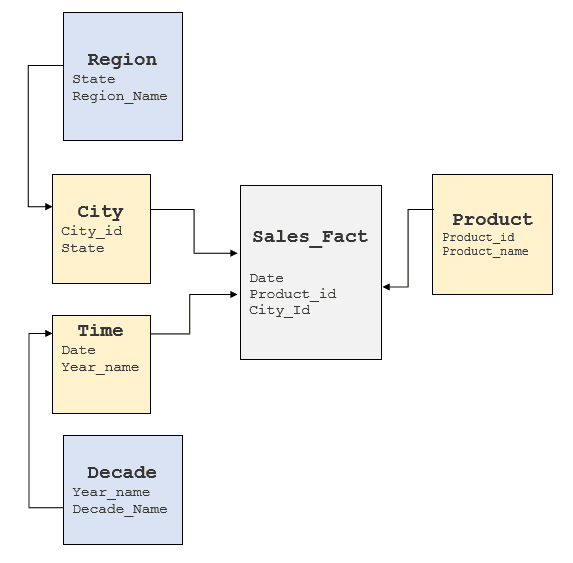
Conversión de consultas MDX a SQL
Analiza la consulta MDX e identifica los siguientes elementos del cubo OLAP y de la consulta MDX. Consulta un tutorial básicode MDXsi lo necesitas. Esto es lo que debes saber:
- Dimensiones
- Medidas
- Medidas calculadas
- Segmentos de datos o filtros (Ejemplo: si el usuario quisiera conocer las ventas solo de «tornillos» o solo del mes de enero).
Tomando como ejemplo la consulta MDX de la sección anterior:
WITH
MEMBER[measures].[avg price] AS
'[measures].[sales_amt] / [measures].[sales_num]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} EN COLUMNAS,
{[product].members, [year].members} EN FILAS
FROM SALES_CUBE
Dónde:
- El precio medio es una medida calculada
- Sales_amt es una medida definida en el cubo
- [product].members es la dimensión del producto
- [Year].members es la dimensión «Año»
Ahora quieres convertir las consultas MDX en consultas SQL basándote en el modelo anterior. La consulta MDX se puede reescribir en SQL de la siguiente manera:
Seleccionar year_name, product_name, sum(sales_amt) como sales, avg(sales_amt) como avg_sales de Sales FT unir Time_Dimension TD en FT.date = TD.date unir Month_Dimension MD en month(TD.date) = MD.month unir Year_Dimension YD en year(date) = YD.year unir City_Dimension RD en FT.city_id = RD.city_id unir State_Dimension SD en FT.state_id= RD.state_id unir Product PD en FT.product_id = PD.Product_id agrupar por year_name, product_name
o bien, simplifica aún más la consulta eliminando las tablas de dimensiones si estas se introdujeron únicamente para crear el cubo:
Seleccionar date_part(year, sale_date) como year_name, product_name, sum(sales_amt) como sales, avg(sales_amt) como avg_sales de Sales FT unido a Product PD donde FT.product_id = PD.Product_id agrupado por década, year_name, region_name, product_name
Nota: Esto no significa que las uniones con otras tablas puedan eliminarse por completo. Solo pueden eliminarse aquellas tablas que se introdujeron únicamente para cumplir con el estricto esquema en estrella o en copo de nieve.
Si la herramienta de BI no ofrece funciones analíticas de ventana, consulte lasfunciones analíticas yde ventana que ofrece Vector para que puedan ejecutarse directamente en la base de datos.
Si el usuario desea profundizar en un conjunto específico de filas, puede eliminar la agregación y ejecutar la consulta directamente en la base de datos. Por ejemplo, si el usuario desea profundizar en las cifras de ventas de enero de 1993 del producto «Tornillos», podría utilizar la siguiente consulta SQL:
Seleccionar Date_part(year, sale_date) como year_name, product_name, sales_amt como sales de Sales FT unido a Product PD donde FT.product_id = PD.Product_id donde Product_name = «Bolts» y Date_part(year, sale_date) = «1993» y Date_part(month, sale_date) = «January»
Indicadores clave de rendimiento
En la jerga empresarial, un indicador clave de rendimiento (KPI) es una medida cuantificable que permite evaluar el éxito de una empresa.
Un objeto KPI sencillo se compone de: información básica, el objetivo, el valor real alcanzado, un valor de estado, un valor de tendencia y una carpeta en la que se visualiza el KPI. La información básica incluye el nombre y la descripción del KPI. En un cubo de Microsoft SQL Server Analysis Services, el objetivo es una expresión MDX que se evalúa como un número. El valor real es una expresión MDX que se evalúa como un número. Los valores de estado y tendencia son expresiones MDX que se evalúan como un número. La carpeta es una ubicación sugerida para que el KPI se presente al cliente.
Aunque algunos almacenes de cubos OLAP ofrecen interfaces elegantes y fáciles de usar para almacenar e implementar indicadores clave de rendimiento (KPI) y acciones, estas funciones se pueden implementar fácilmente mediante una combinación de funciones de bases de datos más habituales y código de aplicación.
Análisis de hipótesis para diferentes escenarios
Algunas bases de datos de cubos ofrecen funciones de análisis de escenarios hipotéticos con interfaces fáciles de usar. Esto también se puede implementar utilizando las funciones de la base de datos y el código de la aplicación, aunque requiere cierto esfuerzo.
Este tipo de análisis requiere almacenar diversos escenarios y analizar el impacto de la situación actual de la empresa en relación con dichos escenarios. Se utiliza habitualmente en el sector de los servicios financieros y en las empresas de negociación para evaluar constantemente el riesgo y el impacto de las operaciones.
Sería necesario realizar un análisis detallado de los requisitos, lo cual excede un poco el alcance de esta entrada del blog.
Summary
Para los usuarios de OLAP que desean simplificar el ciclo de vida de la inteligencia empresarial, la base de datos analítica Actian Vector ofrece una alternativa viable a los cubos OLAP gracias a su tecnología innovadora, su rendimiento superior y sus capacidades analíticas integradas en la propia base de datos. Las ventajas de la migración son la reducción de costes y una mejor experiencia de usuario en materia de inteligencia empresarial, gracias a la libertad de consulta.
No te limites a creerme. Pruébalo por ti mismo. Hemos preparado una guía y una versión de prueba de Vector, junto con todo el material de apoyo que necesitarás para probar Vector en aproximadamente una hora. Puedes plantear tus preguntas a nuestra activa comunidad de Vector aquí.
Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)