Datenbankgeschichte im Entstehen: Ingres trifft auf X100





Doug Inkster ist ein Actian Fellow mit einer langen Geschichte auf dem Datenbankmarkt, die in den 1970er Jahren mit IDMS begann und in den 1990er Jahren zu Ingres führte. Wir haben ihn gebeten, sich an die aufregendsten Zeiten seiner langen Karriere zu erinnern. Hier sind einige seiner Gedanken:
In den mehr als 40 Jahren, in denen ich mit Datenbankverwaltungssoftware arbeite und sie entwickle, war einer der schönsten Tage, Peter Boncz und Marcin Żukowski zum ersten Mal zu treffen. Ich war in Redwood City und leitete die abfragen Training für das Performance-Engineering-Team der Ingres Corp. (jetzt Actian), und Peter und Marcin waren in der Bay Area, um einen Vortrag an der Stanford University zu halten.
Dan Koren, Leiter der Abteilung Performance Engineering, lud sie ein, über die MonetDB/X100-Technologie zu sprechen, die Gegenstand von Marcins Doktorarbeit unter Peters Leitung war. Dan war ein großer Fan der MonetDB-Forschung, die hauptsächlich von Peter am CWI (dem von der niederländischen Regierung finanzierten Zentrum für Forschung in Mathematik und Informatik) in Amsterdam durchgeführt wurde, und X100 war eine Weiterentwicklung von MonetDB.
Der Tag begann mit uns vier in einem Konferenzraum in der Ingres-Zentrale, und Marcin begann mit einem kurzen Überblick über die Stanford-Präsentation. Peter und Marcin führten ein Experiment durch, bei dem sie eine Reihe von Zeilenspeicher-DBMS, die die erste abfragen des TPC H-Benchmarks ausführen, mit einem handgeschriebenen C-Programm verglichen, das der gleichen abfragen entspricht. Das handgeschriebene Programm war weitaus schneller als das schnellste DBMS und führte zu dem X100-Forschungsprojekt (so benannt wegen ihres "bescheidenen" Ziels, die aktuelle Datenbankleistung um den Faktor 100 zu übertreffen).
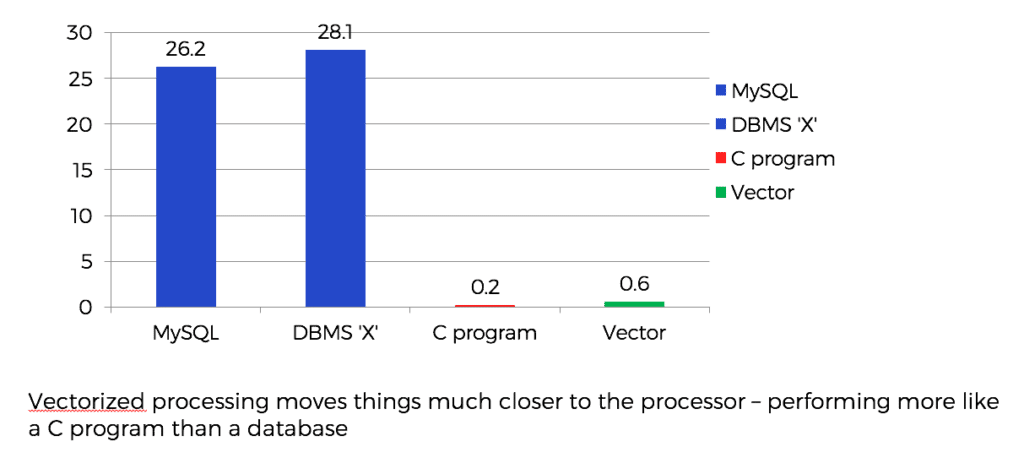
Bei ihren Untersuchungen kamen sie schnell zu dem Schluss, dass die Komplexität von Zeilenspeichern nicht nur auf ihre Darstellung auf der Festplatte beschränkt ist. Die Verarbeitung von Zeilenspeicherdaten im Speicher eines Datenbankservers ist nach wie vor sehr komplex. Die Komplexität des Codes widersetzt sich den Versuchen des Cache, die Vorteile der Lokalität und der Ausführung von Befehlen in Reihenfolge zu nutzen. Einige Spaltenspeicher leiden unter denselben Verarbeitungsproblemen, da das Format des Spaltenspeichers in Zeilen umgewandelt wird, sobald sich die Daten im Speicher des Servers befinden. Die Adressierung der fraglichen Spalten und die anschließende zellenweise Ausführung der Operationen verbraucht viele Maschinenzyklen.
Mit MonetDB hatte man bereits einige der Probleme in Angriff genommen, aber die Komplexität der abfragen und die Scalability waren immer noch ein Problem. X100 führte die Idee ein, "Vektoren" von Spaltendaten auf einmal zu verarbeiten und sie von Operator zu Operator Streaming . Anstatt Ausdrücke auf den Spalten einer Zeile zu berechnen oder Spaltenwerte aus einzelnen Zeilen zu vergleichen, verarbeitet die X100-Ausführungsmaschine Operatoren auf Vektoren von Spaltenwerten mit einem einzigen Aufruf von Routinen zur Ausdrucksverarbeitung. Die Routinen nehmen die Vektoren als Parameter entgegen und bestehen aus einfachen Schleifen, um alle Werte in den gelieferten Vektoren zu verarbeiten. Diese Art von Code lässt sich sehr gut mit modernen Computerarchitekturen kompilieren, da er das Pipelining von Schleifen nutzt, von der Lokalität der Referenz profitiert und in einigen Fällen SIMD single instruction, multiple data) einführt, die auf alle Werte des Eingangsvektors gleichzeitig wirken können.
Das Ergebnis war die gleichzeitige Verringerung der Anweisungen pro Tupel und der Zyklen pro Anweisung, was zu einer massiven Verbesserung der Leistung führte. Ich erinnerte mich an die alten wissenschaftlichen Computer der 1970er Jahre (CDC, Cray usw.), die ebenfalls in der Lage waren, bestimmte Anweisungen auf Datenvektoren gleichzeitig auszuführen. Damals waren diese Techniken jedoch hochspezialisierten wissenschaftlichen Verarbeitungen vorbehalten - Wettervorhersage und so weiter. Auch die moderne Wiedereinführung solcher Hardwarefunktionen war eher auf Multimedia-Anwendungen und Computerspiele ausgerichtet. Die Tatsache, dass Peter und Marcin sie genutzt haben, um alte Datenbankverarbeitungsprobleme zu lösen, war genial!
Natürlich ging es bei ihren Forschungen um mehr als nur das. Ein wichtiger Bestandteil von X100 war die Idee, die Speicherhierarchie - von der Festplatte über den Hauptspeicher bis zum Cache - so effektiv wie möglich zu nutzen. Die Daten werden auf der Festplatte (leicht) komprimiert und erst dekomprimiert, wenn die Wertevektoren zur Verarbeitung anstehen. Die Größe der Vektoren wird so optimiert, dass ein Gleichgewicht zwischen dem E/A-Durchsatz und der Cache-Kapazität hergestellt wird. Aber für mich war es spannend (und amüsant zugleich) zu sehen, dass Hardware, die für das Streaming Filmen und das Spielen von Minecraft entwickelt wurde, so effektiv für eine so grundlegende Geschäftsanwendung wie die Datenbankverwaltung eingesetzt werden kann.
Die anschließende Übernahme der X100-Technologie durch Ingres führte schnell zu einer Aufzeichnung TPC H-Leistung und einigen der schönsten Jahre meiner beruflichen Laufbahn.
Hinweis: Ingres ist nach wie vor ein beliebtes zeilenorientiertes RDBMS , das geschäftskritische Anwendungen unterstützt, während X100 sowohl in der Actian Vector Analytics Database als auch in der Actian X Hybrid Database, einer Kombination aus Ingres- und X100-Technologien, die sowohl zeilen- als auch spaltenbasierte Tabellen verarbeiten kann, eine branchenführende abfragen bietet.

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)