Actian Vector ingestion de données





Summary
- Actian Vector utilizes a highly optimized execution engine that allows organizations to ingest massive, high-velocity datasets with minimal latency.
- The platform handles real-time data streaming and continuous bulk loading without locking tables or degrading active analytical query performance.
- Vector memory management structures stream updates directly into disk-based storage blocks to maximize transactional throughput and reliability.
- Integrating parallel loading streams into the database architecture enables teams to ingest and analyze multi-gigabyte data files simultaneously.
Action Vector 7.0 pasa a llamarse Actian Analytics Engine a partir de la versión 8.0
La utilidad de una base de datos analítica está estrechamente ligada a su capacidad para recopilar, almacenar y procesar grandes cantidades de datos. Por lo general, los datos se recopilan de múltiples fuentes, como bases de datos operativas, archivos CSV y flujos de datos continuos. En la mayoría de los casos, las cargas diarias de datos se miden en decenas o cientos de millones de filas, por lo que el mecanismo tradicional INSERT de SQL no resulta adecuado para estos volúmenes de datos.
In this blog post, we’ll look at Actian Vector, our columnar database ideally suited for analytic applications, and evaluate a variety of CSV data ingestion options that operate at the required data rates. In future posts, we’ll examine Actian VectorH executing in a Hadoop environment and ingestion from streaming data sources.
El objetivo de este ejercicio no es comparar el rendimiento de la ingesta de datos, sino evaluar la velocidad relativa de diversos métodos en el mismo entorno de hardware. Evaluaremos la instrucción SQL INSERT como referencia, la instrucción SQL COPY TABLE, la herramienta de línea de comandos vwload y las herramientas de ETL/flujo de trabajo Pentaho Data Integration (también conocida como Kettle), Talend Open Studio for Data Integration y Apache NiFi. Talend y Pentaho son herramientas ETL tradicionales que han evolucionado para incluir una variedad de cargadores masivos y otras herramientas y tecnologías denominadas de big data; ambas se basan en la interfaz de usuario de Eclipse. NiFi fue cedido como código abierto a la Fundación Apache por la Agencia de Seguridad Nacional de EE. UU. (NSA) y es una herramienta de uso general para automatizar el flujo de datos entre sistemas de software; utiliza una interfaz de usuario basada en web.
Los tres implementan algún tipo de grafo dirigido en el que los datos fluyen de un operador al siguiente, y los operadores se ejecutan en paralelo. Pentaho y Talend cuentan con ediciones comunitarias y de suscripción, mientras que NiFi es un proyecto de código abierto de Apache.
El servidor Vector cuenta con un procesador AMD Opteron 6234 de seis núcleos de clase de escritorio, 64 GB de memoria y discos duros SATA (coste del hardware: unos 2500 dólares) y ejecuta la versión 5.0 de Vector en un único nodo.
A modo de referencia, vamos a introducir aproximadamente 24 millones de registros en la tabla de elementos de línea del benchmark TPCH. La estructura de esta tabla es la siguiente:
l_orderkey bigint NOT NULL, l_partkey INT NOT NULL, l_suppkey INT NOT NULL, l_linenumber INT NOT NULL, l_quantity NUMERIC(19,2) NOT NULL, l_extendedprice NUMERIC(19,2) NOT NULL, l_discount NUMERIC(19,2) NOT NULL, l_tax NUMERIC(19,2) NOT NULL, l_returnflag CHAR(1) NOT NULL, l_linestatus CHAR(1) NOT NULL, l_shipdate DATE NOT NULL, l_commitdate DATE NOT NULL, l_receiptdate DATE NOT NULL, l_shipinstruct CHAR(25) NOT NULL, l_shipmode CHAR(10) NOT NULL, l_comment VARCHAR(44) NOT NULL
SQL INSERT
Dado que Vector es compatible con ANSI SQL, quizá el mecanismo de inserción más obvio sea la instrucción INSERT estándar de SQL. Por lo general, esta es la opción menos eficiente, ya que da lugar a operaciones de inserción individuales. Las inserciones pueden optimizarse en cierta medida utilizando la parametrización e insertando registros por lotes, pero es posible que ni siquiera eso proporcione el nivel de rendimiento requerido.
Para la prueba SQL INSERT, crearemos un flujo de trabajo sencillo en Pentaho con dos pasos: uno para leer el archivo de datos CSV y otro para insertar esas filas en una base de datos Vector. También ejecutaremos el flujo de trabajo tanto en el mismo nodo que la instancia de Vector como en un nodo remoto, con el fin de evaluar el efecto de la sobrecarga de red.

En esta situación, la carga desde un nodo remoto ofrece un rendimiento ligeramente superior al de la carga desde el nodo local, y el rendimiento suele mejorar a medida que aumenta el tamaño del lote hasta alcanzar aproximadamente 100 000 registros, tras lo cual se estabiliza. Esto no quiere decir que 100 000 sea siempre el tamaño óptimo del lote; lo más probable es que varíe en función del tamaño de las filas.
Vector COPIAR TABLA
La instrucción COPY TABLE de Vector se utiliza para cargar datos de forma masiva desde un archivo CSV a la base de datos. Si se ejecuta desde un nodo remoto, este método requiere la instalación del Vector Client Runtime, es decir, Ingres Net y el monitor de terminal de Ingres SQL. El Client Runtime es de libre acceso y no tiene requisitos de licencia. Tanto Pentaho como Talend incorporan compatibilidad con esta instrucción, aunque la implementación es ligeramente diferente. Pentaho utiliza tuberías con nombre para enviar datos al operador, mientras que Talend crea un archivo de disco intermedio y luego llama al operador.
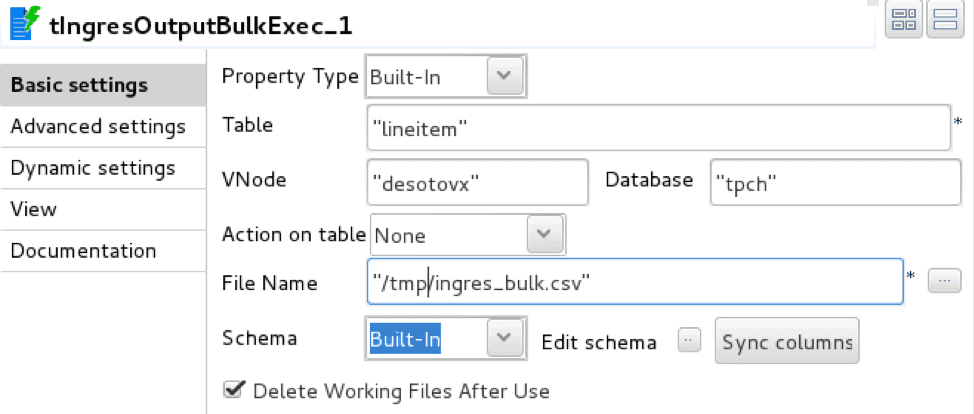
La implementación de Talend utiliza dos operadores: tFileInputDelimited, un lector de archivos delimitados, y tIngresOutputBulkExec, un cargador COPY TABLE de Ingres/Vector

El cargador está configurado con los datos de conexión a la base de datos, la tabla de destino y el archivo de almacenamiento temporal.
La implementación de Pentaho utiliza dos operadores equivalentes: la entrada de archivos CSV (lector de archivos delimitados) y el cargador masivo de Ingres VectorWise (cargador de tablas de bases de datos).

El cargador está configurado con una conexión Vector y una tabla de destino. A diferencia de Talend, el cargador de Pentaho no utiliza un archivo intermedio de almacenamiento temporal.

El rendimiento de ambas herramientas es prácticamente el mismo, pero unas seis veces más rápido que la instrucción INSERT de SQL. Apache NiFi no ofrece compatibilidad nativa con la instrucción COPY TABLE de Vector, y simular este enfoque iniciando el monitor de terminal por separado y conectándose mediante tuberías con nombre resulta relativamente engorroso.
Vector vwload
La utilidad vwload suministrada por Vector es un cargador masivo de alto rendimiento tanto para Actian Vector como para VectorH. Se trata de una utilidad de línea de comandos diseñada para cargar uno o varios archivos en una tabla de Vector o VectorH desde el sistema de archivos local o desde HDFS. Analizaremos la variante de HDFS en una próxima publicación.
Vwload puede ejecutarse de forma independiente o como mecanismo de carga de datos para los flujos de trabajo generados por Pentaho, Talend o NiFi. Pentaho incluye compatibilidad integrada con vwload, mientras que Talend y NiFi ofrecen un mecanismo para dirigir los flujos de datos de los flujos de trabajo a vwload sin necesidad de guardarlos primero en el disco.
La implementación de Talend utiliza el componente tFileInputDelimited para leer el archivo CSV de origen y el componente tFileOutputDelimited para escribir las filas del archivo de origen en una tubería con nombre. Para cargar el flujo de datos en Vector, debemos ejecutar vwload con la misma tubería con nombre que el archivo de origen.
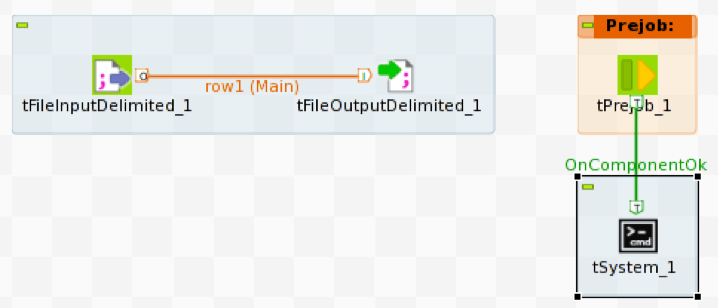
Para iniciar vwload, utilizamos el operador Prejob para activar el operador tSystem; tSystem es el mecanismo que permite ejecutar comandos a nivel del sistema operativo o scripts de shell. El operador Prejob se activa automáticamente al inicio del trabajo, antes que cualquier otro operador del flujo de trabajo, y está configurado para activar el operador tSystem.
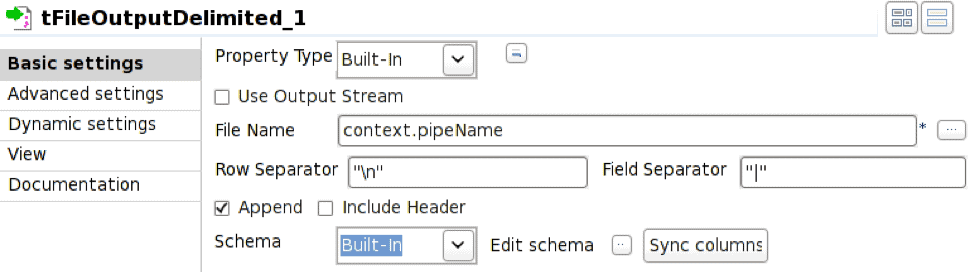
El operador tFileOutputDelimited está configurado para escribir en la canalización con nombre definida por la variable de entorno context.pipeName. La canalización con nombre debe existir en el momento de la ejecución del trabajo y la opción «Añadir» debe estar marcada.
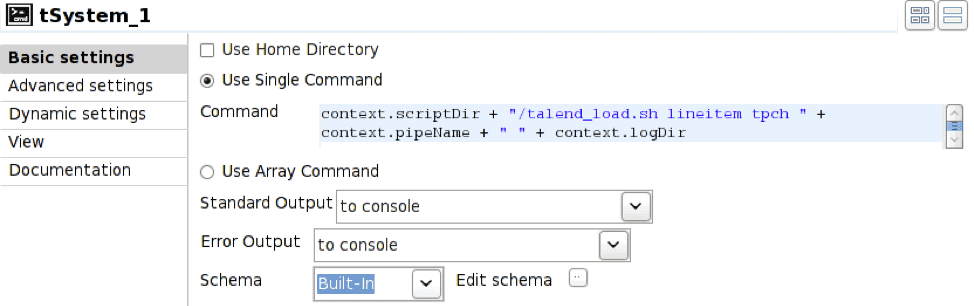
En este caso, el operador tSystem ejecuta el script de shell talend_load.sh pasando los parámetros correspondientes al nombre de la tabla, el nombre de la base de datos, el nombre de la tubería y el directorio del archivo de registro resultante. La notación «context.» es el mecanismo que permite hacer referencia a las variables de entorno asociadas al trabajo; esto permite parametrizar los trabajos. El script de shell es:
#!/bin/bash nohup vwload -m -t $1 $2 $3 > $4/log_`date +%Y%m%d_%H%M%S`.log 2>&1 &
La secuencia de ejecución resultante es:
- Ejecutar el operador de pre-trabajo
- Los desencadenantes previos al trabajo del operador tSystem
- El operador del sistema ejecuta un script de shell
- El script de Shell ejecuta vwload en segundo plano y vuelve; vwload está leyendo ahora desde la tubería con nombre, a la espera de que lleguen las filas
- Inicie tFileInputDelimited para leer las filas del archivo de origen
- Inicia tFileOutputDelimited para recibir las filas entrantes y escribirlas en una canalización con nombre
La implementación de Pentaho utiliza los operadores de entrada de archivos CSV y de carga de Ingres VectorWise, al igual que en el caso de COPY TABLE, pero el cargador masivo está configurado para utilizar vwload en su lugar.
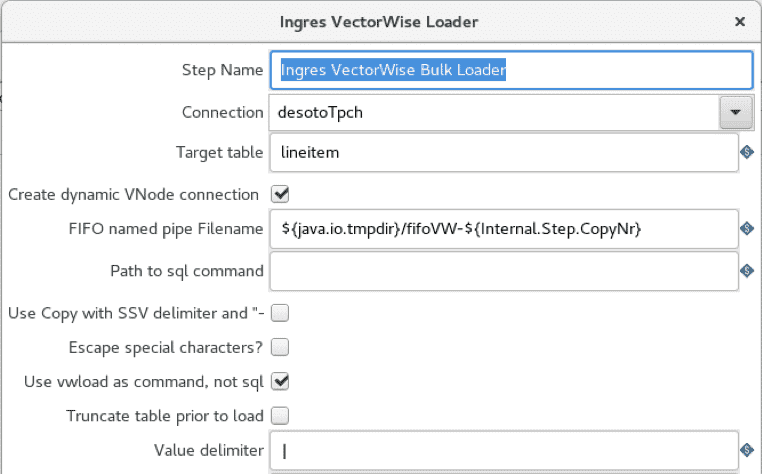
La opción «use vwload» está seleccionada y el campo «Path to sql command» está en blanco. Así es como se ejecuta la utilidad vwload.
La implementación de Apache NiFi utiliza tres operadores: GetFile, que es un detector de directorios; FetchFile, que lee el archivo propiamente dicho; y ExecuteStreamCommand, que envía los datos del flujo del archivo al proceso vwload en segundo plano.
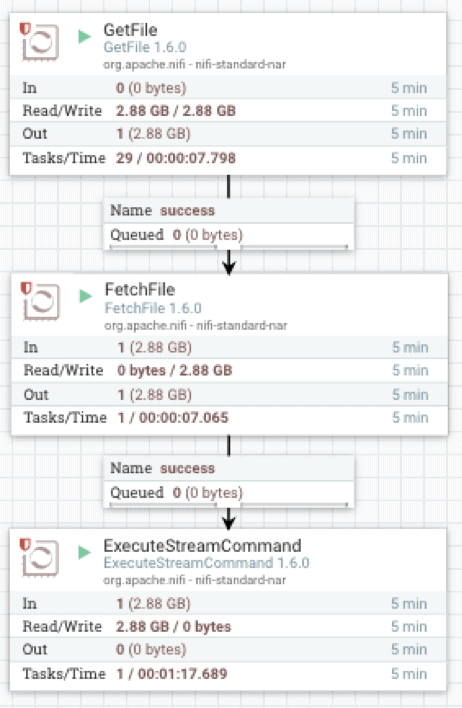
FetchFile envía el flujo de datos de origen a ExecuteStreamCommand, que está configurado para ejecutar un script de shell.
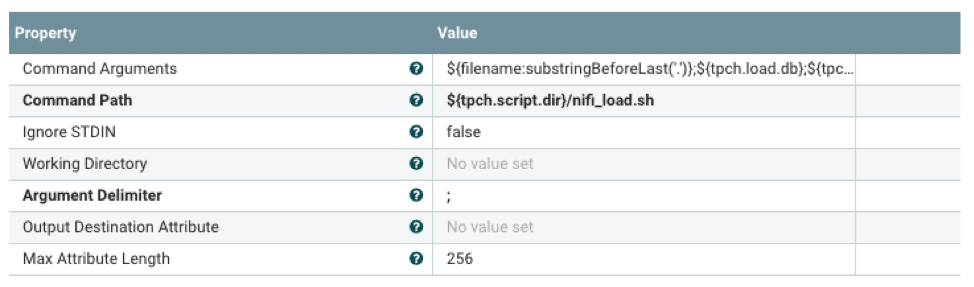
El script de shell ejecutará vwload en segundo plano y dirigirá el flujo de datos a vwload a través de una tubería con nombre. La notación ${} es el mecanismo que permite hacer referencia a las propiedades configuradas en un archivo de propiedades externo. Esto permite configurar el procesador de flujo en tiempo de ejecución.
#!/bin/bash tableName=$1 dbName=$2 loadPipe=$3 logDir=$4 echo "`date +%Y-%m-%d\ %H:%M:%S` vwload -m -t $tableName db $dbName $loadPipe " >> $logDir/load.log vwload -uactian -m -t $tableName $dbName $loadPipe >> $logDir/load.log 2>&1 & cat /dev/stdin >>$loadPipe
El comando vwload se utiliza como mecanismo de carga en los flujos de trabajo anteriores de Pentaho, Talend y NiFi. A modo de comparación, también cargamos el mismo conjunto de datos utilizando vwload de forma independiente en el equipo Vector local, así como desde el cliente remoto mediante Ingres Net.

Los tiempos transcurridos y las velocidades de lectura variarán considerablemente en función del hardware y del tamaño de las filas.
En resumen, las opciones de ingesta de datos, por orden de rendimiento creciente, son SQL INSERT, SQL COPY TABLE y vwload. Para volúmenes de datos considerables, vwload, utilizado junto con la herramienta ETL adecuada, suele ser la opción más acertada. La elección de la herramienta ETL suele depender del rendimiento y la funcionalidad. Como mínimo, debe existir un mecanismo que permita interactuar con el método de ingesta elegido. Los requisitos de funcionalidad dependen principalmente de la cantidad y el tipo de transformación que deba realizarse en el flujo de datos entrante. Incluso si los datos entrantes se van a cargar tal cual, una herramienta ETL puede seguir siendo útil para la detección de archivos entrantes, la programación de tareas y la notificación de errores.
Los flujos de trabajo anteriores constituyen el caso más sencillo de ingesta de archivos CSV, que normalmente consiste simplemente en leer un archivo de datos de origen y cargarlo en Vector. Como tales, también representan el mejor rendimiento posible para cada uno de los métodos de ingesta. La mayoría de los casos de uso reales implicarán algún grado de lógica de transformación en el flujo de trabajo, y las velocidades de flujo de datos disminuirán en función de la complejidad de la transformación. Medir las velocidades de datos del flujo de trabajo nos permite seleccionar el método de ingesta que satisfaga esos requisitos.
Más información Acerca de Actian
Para obtener más Acerca de Actian , consulta los siguientes recursos:
Para obtener más información sobre nuestras ediciones comunitarias de Actian Vector, visite:
Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)