Echtzeit-Datenverarbeitung mit Actian Zen und Kafka Connectors





Willkommen zurück in der Welt von Actian Zen, einer vielseitigen und leistungsstarken Datenmanagement , mit der Sie niedrige Latenz eingebettet Anwendungen erstellen können. Unter Teil 1 haben wir uns mit der Nutzung von BtrievePython beschäftigt, um Btrieve2 Python unter Verwendung der Zen 16.0 Enterprise/Server Database Engine auszuführen.
Dies ist Teil 2 der Schnellstart-Blogserie, die sich darauf konzentriert, eingebettet App-Entwicklern den Einstieg in Actian Zen zu erleichtern. In diesem Blogbeitrag gehen wir durch die Einrichtung einer Demo mit Actian Zen und zeigen, wie man Finanztransaktionen in Echtzeit nahtlos verwalten und verarbeiten kann. Dazu gehören die Konfiguration von Umgebungsvariablen, die Verwendung einer Orchestrierung Skript, die Generierung von Mock-Transaktionsdaten, die Nutzung von Docker für ein optimiertes Deployment und die Verwendung von Docker Compose für die Orchestrierung.
Einführung in Actian Zen Kafka Connectors
In der dynamischen Welt des Finanzwesens ist die effiziente Verarbeitung und Verwaltung von Echtzeit-Transaktionen ein Muss. Die Kafka Connectors von Actian Zen bieten eine robuste Lösung für das Streaming von Transaktionsdaten zwischen Finanzsystemen und Kafka-Themen. Die Actian Zen Kafka Connectors ermöglichen eine nahtlose Integration zwischen Actian Zen Datenbanken und Apache Kafka. Diese Konnektoren unterstützen sowohl Source- als auch Sink-Operationen, so dass Sie Daten aus einer Zen Btrieve-Datenbank in Kafka-Themen streamen können und umgekehrt.
Quelle Konnektor
Der Zen Source Konnektor streamt JSON-Daten aus einer Zen Btrieve-Datenbank in ein Kafka-Topic. Er verwendet Change Capture Polling, um neue Daten in Nutzer Intervallen zu erfassen. So wird sichergestellt, dass Ihre Kafka-Themen immer mit den neuesten Informationen aus Ihren Zen-Datenbanken aktualisiert werden.
Spüle Konnektor
Der Zen Sink Konnektor streamt JSON-Daten aus einem Kafka-Thema in eine Zen Btrieve-Datenbank. Sie können beim Starten des Konnektor wählen, ob Sie die Daten in eine bestehende Datenbank streamen oder eine neue Datenbank erstellen möchten.
Einrichten von Umgebungsvariablen
Bevor Sie mit der Konfiguration beginnen, müssen Sie die erforderlichen Umgebungsvariablen einrichten. Diese Variablen stellen sicher, dass Ihre Systempfade und Bibliothekspfade korrekt konfiguriert sind und dass Sie die Nutzer (EULA) akzeptieren.
Hier ist ein Beispiel für die Umgebungsvariablen, die Sie setzen müssen:
export PATH="/usr/local/actianzen/bin:/usr/local/actianzen/lib64:$PATH"
export LD_LIBRARY_PATH="/usr/local/actianzen/lib64:/usr/lib64:/usr/lib"
export CLASSPATH="/usr/local/actianzen/lib64"
export CONNECT_PLUGIN_PATH='java'
export ZEN_ACCEPT_EULA="YES"
Konfigurieren der Kafka-Konnektoren
Die Konfigurationsparameter für die Kafka-Konnektoren werden als Schlüssel-Wert-Paare bereitgestellt. Diese Konfigurationen können über eine Eigenschaftsdatei, die Kafka REST API oder programmatisch festgelegt werden. Hier ist ein Beispiel für eine JSON-Konfiguration für eine Quelle Konnektor:
{ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.Kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.Kafka.connect.storage.StringConverter", "value.converter": "org.apache.Kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }
Sie können auch Nutzer für eine detailliertere Datenfilterung definieren, indem Sie die abfragen verwenden, die in der Btrieve2-API-Dokumentation beschrieben wird. Zum Beispiel, um nach Transaktionen zu filtern, die größer oder gleich $1000 sind:
"\"Transaction\":{\"Amount\":{\"$gte\":1000}}"
Orchestrierung Skript: kafkasetup.py
Die kafkasetup.py Skript automatisiert den Prozess des Startens und Stoppens der Kafka-Konnektoren. Hier ist ein Ausschnitt, der zeigt, wie das Skript die Konnektoren einrichtet:
import requests import json def main(): requestMap = {} requestMap["Financial Transactions"] = ({ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }, "8083") for name, requestTuple in requestMap.items(): input("Press Enter to continue...") (request, port) = requestTuple print("Now starting " + name + " connector") try: r = requests.post("https://localhost:"+port+"/connectors", json=request) print("Response:", r.json) except Exception as e: print("ERROR: ", e) print("Finished setup!...") input("\n\nPress Enter to begin shutdown") for name, requestTuple in requestMap.items(): (request, port) = requestTuple try: r = requests.delete("https://localhost:"+port+"/connectors/"+request["name"]) except Exception as e: print("ERROR: ", e) if __name__ == "__main__": main()
Wenn Sie das Skript ausführen, werden Sie aufgefordert, jeden Konnektor einzeln zu starten, um sicherzustellen, dass alles korrekt eingerichtet ist.
Erzeugen von Transaktionsdaten mit data_generator.py
Die Datei data_generator.py Skript simuliert Finanztransaktionsdaten und erstellt in bestimmten Abständen Transaktionsdatensätze. Hier ist ein Blick auf die Kernfunktion:
sys importieren importieren os importieren signal importieren json importiere random from time importieren schlafen from datetime importieren datetime sys.path.append("/usr/local/actianzen/lib64") btrievePython als BP importieren
Klasse GracefulKiller:
kill_now = False def __init__(self): signal.signal(signal.SIGINT, self.exit_gracefully) signal.signal(signal.SIGTERM, self.exit_gracefully) def exit_gracefully(self, *args): self.kill_now = True def generate_transactions(): client = BP.BtrieveClient() assert(client != None) collection = BP.BtrieveCollection() assert(collection != None) collectionName = os.getenv("GENERATOR_DB_URI") rc = client.CollectionCreate(collectionName) rc = client.CollectionOpen(collection, collectionName) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) interval = int(os.getenv("GENERATOR_INTERVAL")) kill_condition = GracefulKiller() while not kill_condition.kill_now: transaction = { "Transaction": { "ID": random.randint(1000, 9999), "Amount": round(random.uniform(10.0, 5000.0), 2), "Currency": "USD", "Timestamp": str(datetime.now()) } } print(f"Generated transaction: {transaction}") documentId = collection.DocumentCreate(json.dumps(transaction)) if documentId < 0: print("DOCUMENT CREATE ERROR: " + BP.Btrieve.StatusCodeToString(collection.GetLastStatusCode())) sleep(interval) rc = client.CollectionClose(collection) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) if __name__ == "__main__": generate_transactions()
Dieses Skript führt eine Endlosschleife aus, in der kontinuierlich Transaktionsdaten erzeugt und in eine Btrieve-Sammlung eingefügt werden.
Docker für die Deployment verwenden
Um diese Einrichtung zu erleichtern, verwenden wir einen Docker-Container. Hier ist die Dockerdatei, die die Umgebung für die Ausführung unseres Datengeneratorskripts einrichtet:
FROM actian/zen-client:16.00 Nutzer root RUN apt update && apt install python3 -y COPY --chown=zen-svc:zen-data data_generator.py /usr/local/actianzen/bin ADD _btrievePython.so /usr/local/actianzen/lib64 ADD btrievePython.py /usr/local/actianzen/lib64 Nutzer zen-svc CMD ["python3", "/usr/local/actianzen/bin/data_generator.py"]
Dieses Dockerfile basiert auf dem Actian Zen-Client-Image, installiert Python und enthält das Skript zur Datenerzeugung. Durch Erstellen und Ausführen dieses Docker-Containers können wir Transaktionsdaten generieren und wie konfiguriert in Kafka-Themen streamen.
Docker Compose für Orchestrierung
Zur verwalten und Orchestrierung mehrerer Container, einschließlich Kafka, Zookeeper und unseres Datengenerators, verwenden wir Docker Compose. Hier ist die docker-compose.yml Datei, die alles zusammenführt:
Version: '3.8' Dienste: zookeeper: image: wurstmeister/zookeeper:3.4.6 ports: - "2181:2181" kafka: image: wurstmeister/kafka:2.13-2.7.0 ports: - "9092:9092" Umgebung: KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT KAFKA_LOG_RETENTION_HOURS: 1 KAFKA_NACHRICHT_MAX_BYTES: 10485760 KAFKA_BROKER_ID: 1 Volumes: - var.sock:var.sock actianzen: build: . Umgebung: GENERATOR_DB_URI: "transactions.mkd" GENERATOR_LOCALE: "Austin" GENERATOR_INTERVAL: "5" Volumes: - ./data:/usr/local/actianzen/data
Diese docker-compose.yml Datei richtet Zookeeper, Kafka und unseren Actian Zen-Datengenerator in einer einzigen Konfiguration ein. Durch Ausführen von docker-compose aufkönnen wir den gesamten Stack hochfahren und mit dem Streaming von Finanztransaktionsdaten in Kafka-Themen in Echtzeit beginnen.
Visualisierung des Kafka-Streams
Zum besseren Verständnis des Datenflusses in diesem Setup finden Sie hier ein Diagramm, das den Kafka-Stream veranschaulicht:

In diesem Diagramm fließen die Finanztransaktionsdaten von der Actian Zen Datenbank durch die Kafka-Quelle Konnektor in die Kafka-Themen. Die Daten können dann von verschiedenen nachgeschalteten Anwendungen konsumiert und verarbeitet werden.
Kafka Verbinden: Kafka Connect-Instanzen werden ordnungsgemäß in Gruppen aufgenommen und synchronisiert. Tasks und Konnektoren werden wie erwartet konfiguriert und gestartet.
Finanztransaktionen: Transaktionen sowohl aus New York als auch aus San Francisco werden korrekt verarbeitet und protokolliert. Die Transaktionen umfassen eine Vielzahl von Kredit- und Debitaktionen mit unterschiedlichen Beträgen und Zeitstempeln.
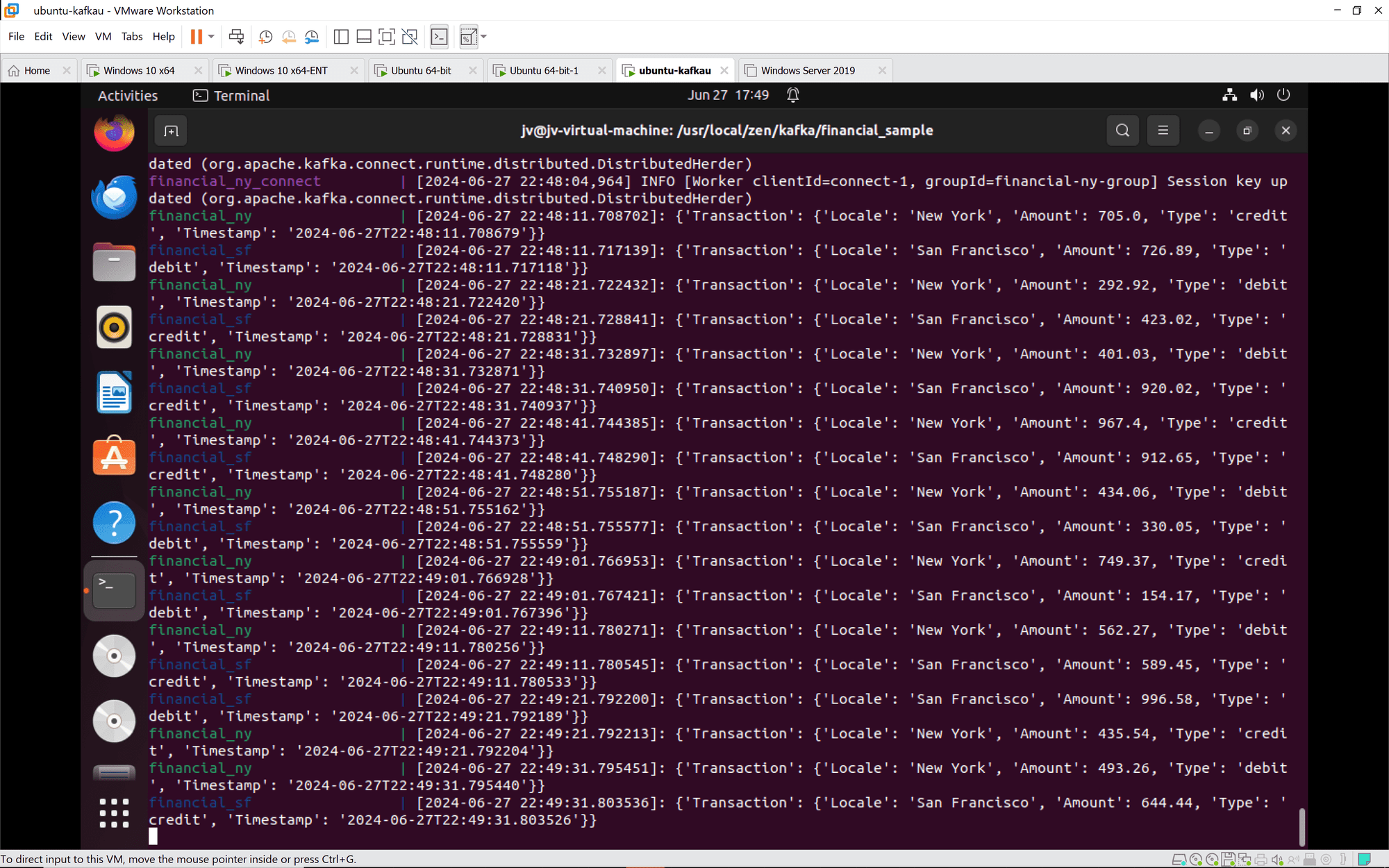
Schlussfolgerung
Die Integration von Actian Zen mit Kafka Connectors bietet eine leistungsstarke Lösung für Streaming und -Verarbeitung. Anhand dieses Leitfadens können Sie ein robustes System zur Abwicklung von Finanztransaktionen einrichten und sicherstellen, dass die Daten effizient gestreamt, verarbeitet und gespeichert werden. Dieses Setup demonstriert nicht nur die Fähigkeiten von Actian Zen und Kafka, sondern unterstreicht auch die Einfachheit des Deployment mit Docker und Docker Compose. Ob Sie nun mit Finanztransaktionen oder anderen datenintensiven Anwendungen zu tun haben, diese Lösung bietet einen skalierbar und zuverlässigen Ansatz für Datenmanagement.
Weitere Einzelheiten und visuelle Anleitungen finden Sie in der Actian Akademie und die umfassende Dokumentation. Viel Spaß beim Kodieren!

Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)