Datenkriege: Der Aufstieg von HCL Informix®
Lawrence Fernandes
11. Februar 2025

"Niemand ist jemals wirklich weg." - Luke Skywalker
In einer nicht allzu fernen Galaxie, in der Scalability und Leistung an erster Stelle stehen, taucht ein Name immer wieder auf - HCL Informix®. HCL Informix wird oft als Vertreter der traditionellen relationalen Datenbanken gepriesen, hat sich aber ständig weiterentwickelt, um den Anforderungen moderner Datenherausforderungen gerecht zu werden. Mit der Veröffentlichung von HCL Informix v15, die in der letzten Data Wars-Folge [1] kurz vorgestellt wurde, beginnt ein neues Kapitel, das das Unternehmen als Very Large Database (VLDB) positioniert, indem es sein reichhaltiges RDBMS mit anderen bereits vorhandenen innovativen Funktionen verbindet, die dem NewSQL-Paradigma Rechnung tragen. Aber kann HCL Informix wirklich einen Platz am NewSQL-Tisch beanspruchen? Lassen Sie es uns herausfinden!
Eine NewSQL-Hoffnung
Bevor wir uns mit HCL Informix beschäftigen, sollten wir über NewSQL sprechen. Warum ist es wichtig? Oder sollte ich sagen: "Ist es noch wichtig"?
Zunächst einmal wurde der Begriff NewSQL erstmals von Matthew Aslett, einem Analysten der 451Group, in einem Forschungspapier aus dem Jahr 2011 [2] verwendet, in dem er den Aufstieg einer neuen Generation von Datenbankmanagementsystemen erörterte, die die Scalability von NoSQL mit den ACID-Garantien traditioneller RDBMS kombinieren sollten. Im Jahr 2020 schrieb ich einen Artikel [3] über das Aufkommen von NewSQL-Datenbanken als Lösung für die Einschränkungen sowohl traditioneller RDBMS als auch von NoSQL-Systemen und sagte abschließend ein erhebliches Wachstum in diesem Branchensegment voraus.
Was meine Vorhersage angeht, würde ich sagen, dass ich teilweise Recht hatte, wenn wir die finanzielle Leistung von zwei der größten NewSQL-Anbieter als Referenz nehmen, nämlich CockroachDB und SingleStore. Laut Sacra ist der Umsatz von Cockroach Labs von 2020 bis 2021 mit einer CAGR von 140 % gewachsen [4], während die ARR von SingleStore von 2022 bis 2023 um 29 % gestiegen ist, mit einer Bewertung von 1,30 Mrd. $ im Jahr 2023 [5]. Laut Verified Market Reports wurde der NewSQL-Datenbankmarkt im Jahr 2023 mit 22,81 Milliarden US-Dollar bewertet und soll bis 2030 111,14 Milliarden US-Dollar erreichen, mit einer CAGR von 21,78 % [6]. Das sind alles gute Zahlen, aber nichts Außergewöhnliches und weit entfernt von der absoluten Dominanz, die viele noch im Jahr 2020 erwartet hatten.
Was ist nun mit meiner ersten Behauptung? Nun, obwohl ein allgemeiner Konsens darüber besteht, dass NewSQL-Systeme beeindruckend sind, da sie horizontale Skalierung und Hochverfügbarkeit bieten (die wichtigsten Ziele der NoSQL-Bewegung) und gleichzeitig ACID-Transaktionen und SQL unterstützen (einige der besten Vorteile von RDBMS), zeigt die Realität, dass nicht alles Gold ist, was glänzt [7]. NewSQL-Anbieter sehen sich mit vielen Herausforderungen konfrontiert, wie z. B. Marktaufklärung, Integration in bestehende Datenökosysteme, Kompatibilität mit Legacy-Anwendungen, Probleme beim Nachweis der Kosteneffizienz in großen Implementierungen, Versagen bei der Gewährleistung der Beständigkeit [8] und mangelnde Standardisierung [9][10].

RDBMS (SQL) vs NoSQL vs NewSQL Vergleich von Dr. Rabi Prasad Padhy [9]
Obwohl die NewSQL-Bewegung inzwischen ausgereift ist (sie besteht seit über 10 Jahren [11]) und die Akzeptanz auf dem Markt zugenommen hat, haben selbst die führenden Anbieter nur ein mäßiges Wachstum und einen begrenzten Marktanteil zu verzeichnen. Die meisten der ursprünglichen NewSQL-Anbieter haben ihr Geschäft aufgegeben, wurden verkauft (und konnten keine großen Gewinne verbuchen) oder haben sich neu orientiert [12][13]. Darüber hinaus macht die zunehmende Konkurrenz durch RDBMS und die Tatsache, dass NoSQL-Anbieter im Vergleich besser abschneiden, die Zukunft von NewSQL ungewiss, wobei viele Experten bereits 2021 den Tod von NewSQL verkünden [7][11][12][13].
Der Wettbewerb schlägt zurück
Zurück ins Jahr 2025: Das Leben ist alles andere als einfach für die verbleibenden NewSQL-Anbieter auf dem Markt. Der Verkauf von Datenbanken ist unbestreitbar eine Herausforderung - eine Realität, die ich aus eigener Erfahrung bestätigen kann. Das Kernproblem liegt in der "Klebrigkeit" von Datenbanken; Unternehmen sind verständlicherweise vorsichtig, wenn es darum geht, von ihren etablierten RDBMS oder NoSQL-Systemen zu migrieren. Darüber hinaus haben sich viele dieser Systeme zu Multi-Modell-Datenbanken entwickelt, eine Kategorie, die Gartner in seinem Hype Cycle für Datenmanagement 2023 auf dem Plateau der Produktivität ansiedelt.
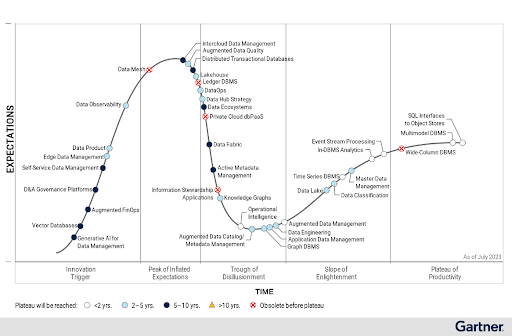
Gartner Hype Cycle für Datenmanagement, 2023
Dies bringt uns zu HCL Informix: ein etabliertes RDBMS mit einer langen Geschichte und einem langen Stammbaum, das sich zu einer Multi-Modell-Datenbank entwickelt hat. Das 1980 gegründete und 1986 an die Börse gebrachte Unternehmen HCL Informix (damals nur "Informix" genannt) erlangte in den 1990er Jahren große Bekanntheit und wurde zur zweitgrößten Datenbank nach Oracle. Laut Art Kagel konkurrierten Informix und Oracle während der heftigen Datenbankkriege der 90er Jahre intensiv um den Titel der "besten" OLTP-Leistung, wobei Informix nie einen vergleichenden Benchmark gegen Oracle, Sybase, SQL Server oder andere Wettbewerber verlor [14]. Apropos Leistungsbenchmarks: Ein alter TPC-D-Benchmark ergab, dass Informix 70 % schneller war als Oracle und dabei auf 25 % weniger Hardware lief [15].
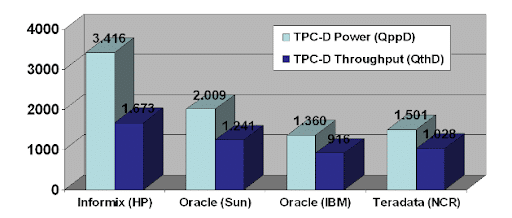
TPC-D Benchmark aus den 90er Jahren
Von 1996 bis 2000 war die Datenbanklegende Michael Stonebraker nach der Übernahme von Illustra [16] der CTO von Informix. Trotz seiner technologischen Fortschritte wurde der Erfolg von Informix durch einige technische Rückschläge [17][18] und Finanzskandale[19] getrübt, die zum Niedergang des Unternehmens führten. Die Bemühungen, sich durch Umstrukturierungen und Übernahmen zu erholen, scheiterten letztendlich und gipfelten in der Übernahme von Informix durch IBM im Jahr 2005.
Wie Art Kagel feststellte, "hat IBM mehr Verbesserungen, Erweiterungen und neue Funktionen für das Produkt vorgenommen als die Informix Corp. in den 18 Jahren ihres Bestehens" [20]. Zu diesen Verbesserungen gehören unter anderem der Informix Warehouse Accelerator (IWA), die Unterstützung für die MongoDB-API und Konnektivitätsprotokolle.
andere. Aus vielen Gründen (von denen einige im gleichen Quora-Thread [20] erörtert werden) schlägt die Konkurrenz jedoch zurück, was zu einem Verlust von Marktanteilen und Bekanntheit führt.
Der Aufstieg von HCL Informix
2017 unterzeichnete IBM eine langfristige Partnerschaftsvereinbarung mit HCLTech, einem der weltweit größten Beratungsunternehmen (neben anderen verwandten Unternehmen), um gemeinsam die Informix-Produktfamilie zu entwickeln [21][22], womit wir bei HCL Informix wären: dieselbe Informix-Datenbank, die Kunden lieben gelernt haben, aber lizenziert von Actian, einer Abteilung von HCLSoftware [23].
HCL Informix ist produktgleich mit der IBM® Informix® Advanced Enterprise Edition, einschließlich der Unterstützung für IWA, und verfügt nun über ein eigenes HCL Informix 4GL- und ISQL-Angebot sowie über aufregende neue Funktionen , die in Version 15 veröffentlicht wurden. Mit einem vereinfachten Lizenzierungsmodell pro Kern, wettbewerbsfähigen Preisen, erfahrenem Kundensupport und ohneLieferanten-Lock-in gibt es mehr, um sich in HCL Informix zu verlieben [24].
Aber Sie werden vielleicht fragen: "Ok, aber ist HCL Informix ein NewSQL-System?". Die kurze Antwort ist nein. HCL Informix hat sich jedoch im Laufe der Jahrzehnte weiterentwickelt und beinhaltet Funktionen (Unterstützung von relationalen, Dokumenten-, Zeitreihen- und räumlichen Daten), wodurch es sowohl mit NewSQL- als auch mit NoSQL-Systemen konkurrieren kann. Die einzigartige Kombination traditioneller relationaler Datenbankfunktionen mit modernen Funktionen wie Hochverfügbarkeit, Scalability und hybrider Datenverarbeitung macht sie zu einem ernstzunehmenden Konkurrenten in beiden Kategorien und macht sie zu einer vielseitigen Wahl für Unternehmen, die die Kluft zwischen strukturiertem und unstrukturiertem Datenmanagement überbrücken wollen.
Die MongoDB-API von HCL Informix ermöglicht es Entwicklern, MongoDB-ähnliche Funktionen zur Dokumentenspeicherung und -abfrage nativ zu nutzen. Außerdem werden die MongoDB-Shell und alle standardmäßigen MongoDB-Befehlsdienstprogramme und -Tools unterstützt sowie eine REST-API, MQTT-Konnektivität und JSON-Datensharing bereitgestellt [25]. Durch die Bereitstellung einer einheitlichen Plattform sowohl für SQL- als auch für NoSQL-Workloads macht HCL Informix separate DBMS überflüssig und reduziert die betriebliche Komplexität. Dieser hybride Ansatz ist besonders wertvoll für Unternehmen, die gemischte transaktionale Arbeitslasten verwalten, die auch die Speicherung von JSON-Dokumenten erfordern.
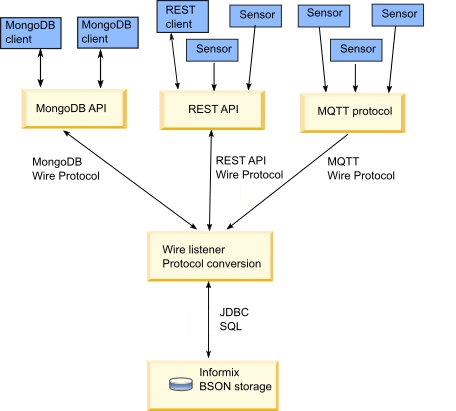
Die Wire-Listener-Architektur von HCL Informix
Die Datenreplikationsfunktionen von HCL Informix ermöglichen eine nahtlose Replikation von Daten über Knoten hinweg und gewährleisten Beständigkeit und Fehlertoleranz [26]. HCL Informix bietet eine umfassende Suite von Datenreplikationsfunktionen - Enterprise Replication (ER), High-Availability Data Replication (HDR), Remote Standalone Secondary (RSS) und Shared Disk Secondary (SDS) -, die mit den Funktionen von NoSQL- und NewSQL-Systemen konkurrieren.
Enterprise Replication ermöglicht asynchrone Multi-Master-Replikation in geografisch verteilten Umgebungen und ist damit vergleichbar mit NoSQL-Lösungen wie
MongoDBs Replikatsätzen [27]. HDR hingegen bietet synchrone Replikation für ein Primary-Secondary-Setup, das eine starke Beständigkeit gewährleistet, ähnlich wie NewSQL-Datenbanken wie SingleStore, die CABeständigkeit und Verfügbarkeit) im CAP-Theorem [28] priorisieren.
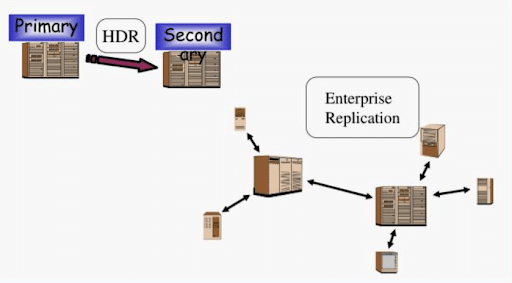
Enterprise Replikation von HCL Informix im Vergleich zu HDR
RSS sorgt für zusätzliche Flexibilität, indem es Nur-Lese-Replikate an entfernten Standorten ermöglicht und so die Wiederherstellung im Katastrophenfall und die globale Scalability optimiert, ähnlich wie die Lesepräferenzeinstellungen von MongoDB oder die regionalen Replikate von Spanner [29]. Schließlich erweitert SDS die Scalability und Fehlertoleranz, indem es eine Shared-Disk-Architektur mit minimaler Latenz ermöglicht, was es ideal für High-Performance macht [30].

HCL Informix's HADR vs. ER Merkmale
Die Funktionen von HCL Informix stärken die Position von HCL Informix gegenüber NoSQL- und NewSQL-Systemen im Umgang mit großen Datenmengen. SmartBLOBs ermöglicht die Verwaltung großer Mengen unstrukturierter Daten durch die Bereitstellung effizienter Speicher-, Abruf- und Funktionen für Multimedia-Inhalte, Dokumente und andere BLOB/CLOB-Datentypen, die nahtlos in transaktionale Workflows integriert sind - eine Funktionalität, die mit der Veröffentlichung von External SmartBLOBs in HCL Informix 15 [31] weiter verbessert wurde.
Darüber hinaus verfügt HCL Informix 15 über größere Zeilen- und Seitenadressen: Die Tabellengröße hat sich im Vergleich zu HCL Informix 14.10 um das 134-Millionenfache, die Chunkgröße um das 2,25-Millionenfache und die Speicherkapazität um das 4,2-Millionenfache erhöht. Durch diese Änderung steigt die maximale Speicherkapazität einer einzelnen HCL Informix 15-Instanz auf ein halbes Yottabyte oder das Vierfache der geschätzten Größe des Internets!

HCL Informix 15 mit neuer Architektur für eine massive Verbesserung der Speicherkapazität
Zusammen bieten diese Funktionen Unternehmen ein vielseitiges Replikations-Toolkit und die Möglichkeit, große Datenmengen zu verarbeiten und die Lücke zwischen der Zuverlässigkeit traditioneller RDBMS und der horizontalen Skalierung moderner NoSQL- und NewSQL-Plattformen zu schließen. Einen detaillierten Vergleich von HCL Informix mit einigen wichtigen NewSQL-Anbietern finden Sie in den unten stehenden Tabellen:
| Merkmal/Metrik | Informix | NewSQL-Anbieter |
| Kategorie | Traditionelle RDBMS mit Multi-Modell Funktionen | Hybride Datenbanken, die RDBMS mit Scalability kombinieren |
| Architektur | Traditionelle RDBMS mit optionalem Clustering und erweitertenFunktionen | Verteilte, Cloud-native Architekturen, die für horizontale Scalability ausgelegt sind |
| Unterstützte Datenmodelle | Relational, Dokument (JSON), Zeitreihen, räumlich | KakerlakenDB: Relationale
EinzelSpeicher: Relational, Schlüssel/Wert, Dokument (JSON), objektorientiert, mehrwertig, Vektor Spanner: Relational, Schlüssel/Wert, Vektor YugabyteDB: Relational, Schlüssel/Wert |
| Transaktionen pro Sekunde (TPS) | 2 Millionen TPS | KakerlakenDB: 1,684,437 TPS
SingleStore: 10M TPS Google Cloud Spanner: 1B TPS YugabyteDB: 100K |
| Maximale Speicherkapazität | Ein halbes Yottabyte | KakerlakenDB: ~890TB (10TiB pro Knoten, empfohlen max. 81 Knoten)
Einzelne Filiale: Unbegrenzt (theoretisch unbegrenzt auf Spanner: ~850TB (10TB pro Knoten, maximal 85 Knoten - aber Benutzer können eine Erhöhung beantragen) YugabyteDB: ~1000TB (10TB pro Knoten, max. 100 Knoten getestet - kann aber mehr, aber es kann zu Leistungsengpässen kommen) |
| Tabellen pro Datenbank | 477.102.080 (maximale Anzahl von Tabellen pro System, Unterstützung von bis zu 21 Mio. Datenbanken pro System) | KakerlakenDB: Praktisch unbegrenzt
SingleStore: Praktisch unbegrenzt Schraubenschlüssel: 5000 YugabyteDB: Praktisch unbegrenzt |
| Spalten pro Tabelle | 32K | KakerlakenDB: 1600
SingleStore: 4096 Schraubenschlüssel: 1024 YugabyteDB: 1600 (Limit auf PSQL, nicht auf YugabyteDB selbst) |
| Skalierbarkeit | Konzipiert für vertikale Skalierung (Scale-up) durch Nutzung stärkerer Hardware; horizontale Skalierung (Scale-out) wird unterstützt, erfordert jedoch eine spezielle Konfiguration
Zu den horizontalen Skalierungsfunktionen gehören Fragmentierung, Sharding (sowohl lokale als auch Remote-Shards und JSON-Daten-Shards), Replikation und verteilte Abfragen. |
KakerlakenDB: Entwickelt für horizontale Skalierung; automatische Aufteilung der Daten auf die Knoten, mit mühelosem Hinzufügen/Entfernen von Knoten
SingleStore: Unterstützt sowohl vertikale als auch horizontale Skalierung, optimiert für schnelle Abfragen und gemischte OLTP/OLAP-Workloads Spannen: Außergewöhnliche horizontale Scalability; skaliert über Regionen und Zonen hinweg und behält dabei die globale Beständigkeit bei YugabyteDB: Hochgradig skalierbar, horizontal skalierbar durch Hinzufügen von Knoten, konzipiert für globale Verteilung |
| ACID-Konformität | Vollständige ACID-Konformität, die stabile Transaktionen in Einzelknoten- und verteilten Konfigurationen gewährleistet | KakerlakenDB: Vollständig ACID-konform, auch bei verteilten Transaktionen
SingleStore: Bietet ACID-Konformität, aber die Transaktionsfähigkeit kann je nach den spezifischen Tabellentypen variieren Spanner: Vollständig ACID-konform mit TrueTime-basierter starker Beständigkeit YugabyteDB: Vollständig ACID-konform, entwickelt für verteilte Transaktionsarbeitslasten |
| CAP-Theorem | Hält sich primär an CABeständigkeit & Verfügbarkeit), geeignet für OLTP-Workloads in stabilen Netzwerken | KakerlakenDB: Schwerpunkte sind CP Beständigkeit & Partitionstoleranz), auf Kosten der Verfügbarkeit in bestimmten Partitionsszenarien
SingleStore: Zielt auf CA ab, optimiert für Leistung bei strenger Partitionstoleranz Spanner: Gleicht CP aus, mit global konsistenten Transaktionen unter Verwendung von TrueTime YugabyteDB: Priorisiert CP und bietet eine hohe Beständigkeit in verteilten Umgebungen |
| Benutzerfreundlichkeit | Ausgereiftes, unternehmenstaugliches Ökosystem mit einer breiten Palette von Tools und Integrationen sowie einer umfassenden Dokumentation |
KakerlakenDB: Einfache Einrichtung mit SQL-Kenntnissen und intuitives Tooling; nahtlose horizontale Skalierung erfordert möglicherweise etwas FachwissenSingleStore: Benutzerfreundlichkeit durch integrationsorientierte Funktionen (z. B. Pipelines), aber die Verwaltung von Tabellentypen (Rowstore vs. Columnstore) erhöht die Komplexität Schraubenschlüssel: Einfach für grundlegende Operationen, aber fortgeschrittene Funktionen erfordern Kenntnisse über TrueTime und globale Verteilung YugabyteDB: Vertraute SQL-Syntax und gute Entwicklerdokumentation; verteiltes Deployment kann für Anfänger eine Herausforderung sein |
| Zielgebrauchsfälle | Ideal für OLTP, IoT , Zeitserien-Workloads und traditionelle Geschäftsanwendungen, die eine stabile Leistung erfordern
Unterstützung für OLAP-Workloads durch IWA oder Echtzeit-Integration mit Actian Data Platform for Big Data Analytics Unterstützung für hybride Architekturen: HCL Informix ist sowohl vor Ort als auch in den Cloud (AWS, Azure, |
KakerlakenDB: Gut geeignet für globales verteiltes OLTP Workloads, Multi-Region-Setups und moderne SaaS-Anwendungen sowie hybride Architekturen (On-Premises, AWS, Azure, GCP, DigitalOcean)SingleStore: Optimiert für gemischte OLTP- und OLAP-Anwendungsfälle, Echtzeitanalysen und schnelle Ingest-Workloads wie IoT. Verwalteter Service (SaaS) beschränkt auf AWS Spanner: Globale Anwendungen im Unternehmensmaßstab mit strengen Anforderungen an Beständigkeit und Hochverfügbarkeit. Managed Service (SaaS) beschränkt auf GCP YugabyteDB: Cloud, verteilte transaktionale Arbeitslasten und Cloud (vor Ort, AWS, Azure, GCP) |
Vielen Dank für die Lektüre, und wenn Sie sich für HCL Informix interessieren, ist Actian, die Data & Analytics-Abteilung von HCLSoftware, bereit, Sie bei Ihrer Migration zu unterstützen. Bis zur nächsten Data Wars Folge, möge die Macht (der Daten) mit Ihnen sein! Wenn Ihnen dieser Blog gefallen hat, sollten Sie sich für meinen Data Wars-Newsletter auf LinkedIn anmelden.
Ehrung eines herausragenden Erbes in der Informix-Gemeinschaft
Ich widme diesen Artikel dem Gedenken an Harry Carlton Doe III, einer Säule der Informix-Gemeinschaft, dessen Engagement und Fachwissen unzählige Fachleute inspirierte. Obwohl wir uns nie begegnet sind, haben Carlton Does Beiträge - unter anderem als Gründungsmitglied der International Informix Nutzer Group (IIUG) und seine vielen Informix-Bücher (von denen ich einige besitze) - einen unauslöschlichen Eindruck hinterlassen, und sein Vermächtnis dient der gesamten Informix-Gemeinschaft weiterhin als Leitfaden und Unterstützung.
OBS: Informix ist in mindestens einer Rechtsordnung eine Marke der IBM Corporation und wird unter Lizenz verwendet.
Referenzen:
[1] Lawrence Fernandes. Data Wars: 2024 Nachbereitung.
[2] Aslett, Matthew (April 6, 2011). "Worüber wir sprechen, wenn wir über NewSQL sprechen". 451 Group.
[3] Lawrence Fernandes. Datenkriege: Eine NewSQL-Hoffnung.
[4] https://sacra.com/c/cockroach-labs/.
[5] https://sacra.com/c/singlestore/
[6] https://www.verifiedmarketreports.com/product/newsql-database-market/
[7] https://dev.to/arctype/too-good-to-be-true-why-newsql-failed-l7p
[8] NewSQL-Datenbanksysteme sind nicht in der Lage, Beständigkeit zu garantieren, und ich gebe Spanner die Schuld. Daniel Abadi. DBMS Amusings. September 21, 2018.
[9] NewSQL-Datenbanken. Mandeep Kumar. July, 2022.
[10] Google Spanner: Eine Migration oder der Anfang vom Ende der NoSQL-Ära. Dr. Rabi Prasad Padhy. October, 2018.
[11] Ten years of NewSQL: Zurück in die Zukunft der verteilten relationalen Datenbanken. Matt Aslett. June, 2021.
[12] Andrew Pavlo. Die offizielle Zehn-Jahres-Retrospektive von NewSQL-Datenbanken: Video
[13] Andrew Pavlo. Der offizielle Zehn-Jahres-Rückblick auf NewSQL-Datenbanken: PDF
[14] Art Kagle. Quora. Welche Vorteile hat die Verwendung einer Informix-Datenbank gegenüber einer Oracle-Datenbank?
[15] Informix IDS vs. Oracle: Ein Vergleich der Wettbewerber. https://slideplayer.com/slide/6229837/
[16] https://en.wikipedia.org/wiki/Michael_Stonebraker
[17] Informix gibt zu, dass fehlerhafter Code Universal Server zum Absturz bringen wird. TechMonitor, CBR Staff Writer, Oktober 1996. https://www.techmonitor.ai/technology/informix_admits_faulty_code_will_crash_universal_server
[18] New Era ist nicht verschwunden, nur nicht mehr relevant. TechMonitor, CBR Staff Writer, Juli 1997. https://www.techmonitor.ai/technology/informixs_new_era_is_not_gone_just_no_longer_relevant_1/
[19] Steve W. Martin. 2005. Die wahre Geschichte von Informix Software und Phil White: Lektionen in Business und Leadership für das Executive Team. Sand Hill Publishing.
[20] Art Kagle. Quora. Was sind die Vor- und Nachteile der Verwendung von Informix als Datenbank? https://qr.ae/pYsl2Z
[21] Art Kagle. Quora. Was ist die Zukunft von Informix? https://qr.ae/pYsdFQ
[22] https://virtual-dba.com/blog/explaining-the-ibm-hcl-partnership/
[23] https://www.hcl-software.com/actian/informix
[24] https://www.actian.com/databases/hcl-informix/
[25] https://help.hcl-software.com/hclinformix/15.0.0/json/json.html
[26]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication
[27]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication/ER.xml
[28eingebettet
[29]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication/ER.xml
[30]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication/RSS.xml
[31] https://help.hcl-software.com/hclinformix/15.0.0/1infocenter/new_features_ce.html#concept_v15.0.0.0__ext_sbspace_15.0.0.0
Haftungsausschluss:
Ich stehe in keiner Verbindung zu den zitierten Autoren oder der Walt Disney Company und werde von ihnen auch nicht unterstützt. Verweise auf Star Wars sind lediglich eine von Fans gemachte Hommage.

Abonnieren Sie den Actian Blog
Abonnieren Sie den Blog von Actian, um direkt Dateneinblicke zu erhalten.
- Bleiben Sie auf dem Laufenden: Holen Sie sich die neuesten Informationen zu Data Analytics direkt in Ihren Posteingang.
- Verpassen Sie keinen Beitrag: Sie erhalten automatische E-Mail-Updates, die Sie informieren, wenn neue Beiträge veröffentlicht werden.
- Ganz wie sie wollen: Ändern Sie Ihre Lieferpräferenzen nach Ihren Bedürfnissen.
Abonnieren
(d.h. sales@..., support@...)