Traitement des données en temps réel avec les connecteurs Actian Zen et Kafka





Bienvenue dans le monde d'Actian Zen, une solution de gestion des données polyvalente et puissante, conçue pour vous aider à créer des applicationsEmbarqué faible latence . En partie 1 nous avons exploré comment tirer parti de BtrievePython pour exécuter des applications Python Btrieve2, en utilisant le moteur de base de données Zen 16.0 Enterprise/Server.
Voici la deuxième partie de la série de blogues de démarrage rapide qui vise à aider les développeurs d'applications Embarqué à démarrer avec Actian Zen. Dans cet article de blog, nous allons passer en revue la mise en place d'une démo Kafka à l'aide d'Actian Zen, en démontrant comment gérer et traiter des transactions financières en temps réel de manière transparente. Cela comprend la configuration des variables d'environnement, l'utilisation d'un script d'orchestration, la génération de données de transaction fictives, l'exploitation de Docker pour un déploiement rationalisé et l'utilisation de Docker Compose pour l'orchestration.
Introduction aux connecteurs Actian Zen Kafka
Dans le monde dynamique de la finance, il est indispensable de traiter et de gérer efficacement les transactions en temps réel. Les connecteurs Kafka d'Actian Zen offrent une solution robuste pour la streaming données transactionnelles entre les systèmes financiers et les sujets Kafka. Les connecteurs Kafka d'Actian Zen facilitent l'intégration transparente entre les bases de données Actian Zen et Apache Kafka. Ces connecteurs support opérations de source et de puits, ce qui vous permet de diffuser des données d'une base de données Zen Btrieve vers des sujets Kafka ou vice versa.
Source Connecteur
Le connecteur Zen Source diffuse des données JSON depuis une base de données Zen Btrieve dans un sujet Kafka. Il utilise le change capture polling pour récupérer les nouvelles données à des intervalles utilisateur, garantissant que vos sujets Kafka sont toujours mis à jour avec les dernières informations de vos bases de données Zen.
Connecteur d'évier
Le connecteur Zen Sink diffuse des données JSON depuis un sujet Kafka vers une base de données Zen Btrieve. Vous pouvez choisir de streamer les données dans une base de données existante ou d'en créer une nouvelle lorsque vous démarrez le connecteur.
Configuration des variables d'environnement
Avant de se lancer dans la configuration, il est essentiel de définir les variables d'environnement nécessaires. Ces variables permettent de s'assurer que les chemins d'accès au système et aux bibliothèques sont correctement configurés, et que vous acceptez le Contrat de Licence utilisateur Final (CLUF) de Zen.
Voici un exemple des variables d'environnement que vous devez définir :
export PATH="/usr/local/actianzen/bin:/usr/local/actianzen/lib64:$PATH"
export LD_LIBRARY_PATH="/usr/local/actianzen/lib64:/usr/lib64:/usr/lib"
export CLASSPATH="/usr/local/actianzen/lib64"
export CONNECT_PLUGIN_PATH='/usr/share/java'
export ZEN_ACCEPT_EULA="YES"
Configuration des connecteurs Kafka
Les paramètres de configuration des connecteurs Kafka sont fournis sous forme de paires clé-valeur. Ces configurations peuvent être définies via un fichier de propriétés, l'API REST Kafka ou de manière programmatique. Voici un exemple de configuration JSON pour un connecteur source :
{ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.Kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.Kafka.connect.storage.StringConverter", "value.converter": "org.apache.Kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }
Vous pouvez également définir des requêtes utilisateur pour un filtrage plus granulaire des données à l'aide du langage de requête JSON décrit dans la documentation de l'API Btrieve2. Par exemple, pour filtrer les transactions supérieures ou égales à 1000 $ :
"\"Transaction\":{\"Amount\":{\"$gte\":1000}}"
Script d'orchestration : kafkasetup.py
Le fichier kafkasetup.py automatise le processus de démarrage et d'arrêt des connecteurs Kafka. Voici un extrait montrant comment le script configure les connecteurs :
import requests import json def main(): requestMap = {} requestMap["Financial Transactions"] = ({ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }, "8083") for name, requestTuple in requestMap.items(): input("Press Enter to continue...") (request, port) = requestTuple print("Now starting " + name + " connector") try: r = requests.post("https://localhost:"+port+"/connectors", json=request) print("Response:", r.json) except Exception as e: print("ERROR: ", e) print("Finished setup!...") input("\n\nPress Enter to begin shutdown") for name, requestTuple in requestMap.items(): (request, port) = requestTuple try: r = requests.delete("https://localhost:"+port+"/connectors/"+request["name"]) except Exception as e: print("ERROR: ", e) if __name__ == "__main__": main()
Lorsque vous exécutez le script, il vous invite à démarrer chaque connecteur un par un, en veillant à ce que tout soit correctement configuré.
Générer des données de transaction avec data_generator.py
Le fichier data_generator.py simule des données de transactions financières, en créant des enregistrements de transactions à des intervalles spécifiés. Voici un aperçu de la fonction principale :
import sys import os import signal import json import random from time import sleep from datetime import datetime sys.path.append("/usr/local/actianzen/lib64") import btrievePython as BP
classe GracefulKiller :
kill_now = False def __init__(self): signal.signal(signal.SIGINT, self.exit_gracefully) signal.signal(signal.SIGTERM, self.exit_gracefully) def exit_gracefully(self, *args): self.kill_now = True def generate_transactions(): client = BP.BtrieveClient() assert(client != None) collection = BP.BtrieveCollection() assert(collection != None) collectionName = os.getenv("GENERATOR_DB_URI") rc = client.CollectionCreate(collectionName) rc = client.CollectionOpen(collection, collectionName) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) interval = int(os.getenv("GENERATOR_INTERVAL")) kill_condition = GracefulKiller() while not kill_condition.kill_now: transaction = { "Transaction": { "ID": random.randint(1000, 9999), "Amount": round(random.uniform(10.0, 5000.0), 2), "Currency": "USD", "Timestamp": str(datetime.now()) } } print(f"Generated transaction: {transaction}") documentId = collection.DocumentCreate(json.dumps(transaction)) if documentId < 0: print("DOCUMENT CREATE ERROR: " + BP.Btrieve.StatusCodeToString(collection.GetLastStatusCode())) sleep(interval) rc = client.CollectionClose(collection) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) if __name__ == "__main__": generate_transactions()
Ce script exécute une boucle infinie, générant et insérant continuellement des données de transaction dans une collection Btrieve.
Utiliser Docker pour le déploiement
Pour faciliter cette configuration, nous utilisons un conteneur Docker. Voici le fichier Docker qui configure l'environnement pour exécuter notre script de génération de données :
FROM actian/zen-client:16.00 utilisateur root RUN apt update && apt install python3 -y COPY --chown=zen-svc:zen-data data_generator.py /usr/local/actianzen/bin ADD _btrievePython.so /usr/local/actianzen/lib64 ADD btrievePython.py /usr/local/actianzen/lib64 utilisateur zen-svc CMD ["python3", "/usr/local/actianzen/bin/data_generator.py"]
Ce fichier Docker s'étend à partir de l'image du client Actian Zen, installe Python et inclut le script de génération de données. En construisant et en exécutant ce conteneur Docker, nous pouvons générer et diffuser des données de transaction dans des sujets Kafka comme configuré.
Docker Compose pour l'orchestration
Pour gérer et orchestrer plusieurs conteneurs, y compris Kafka, Zookeeper et notre générateur de données, nous utilisons Docker Compose. Voici le fichier docker-compose.yml qui rassemble tout :
version : '3.8' services : zookeeper : image : wurstmeister/zookeeper:3.4.6 ports : - "2181:2181" kafka : image : wurstmeister/kafka:2.13-2.7.0 ports : - "9092:9092" environnement : KAFKA_ZOOKEEPER_CONNECT : zookeeper:2181 KAFKA_ADVERTISED_LISTENERS : PLAINTEXT://kafka:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP : PLAINTEXT:PLAINTEXT KAFKA_LOG_RETENTION_HOURS : 1 KAFKA_MESSAGE_MAX_BYTES : 10485760 KAFKA_BROKER_ID : 1 volumes : - var.sock:var.sock actianzen : build : . environment : GENERATOR_DB_URI : "transactions.mkd" GENERATOR_LOCALE : "Austin" GENERATOR_INTERVAL : "5" volumes : - ./data:/usr/local/actianzen/data
Ceci docker-compose.yml met en place Zookeeper, Kafka et notre générateur de données Actian Zen dans une configuration unique. En exécutant docker-compose upnous pouvons mettre en route l'ensemble de la pile et commencer à streaming temps réel les données des transactions financières dans les sujets Kafka.
Visualisation du flux Kafka
Pour mieux comprendre le flux de données dans cette configuration, voici un diagramme illustrant le flux Kafka :

Dans ce diagramme, les données des transactions financières circulent de la base de données Actian Zen vers les sujets Kafka en passant par le connecteur source Kafka. Les données peuvent ensuite être consommées et traitées par diverses applications en aval.
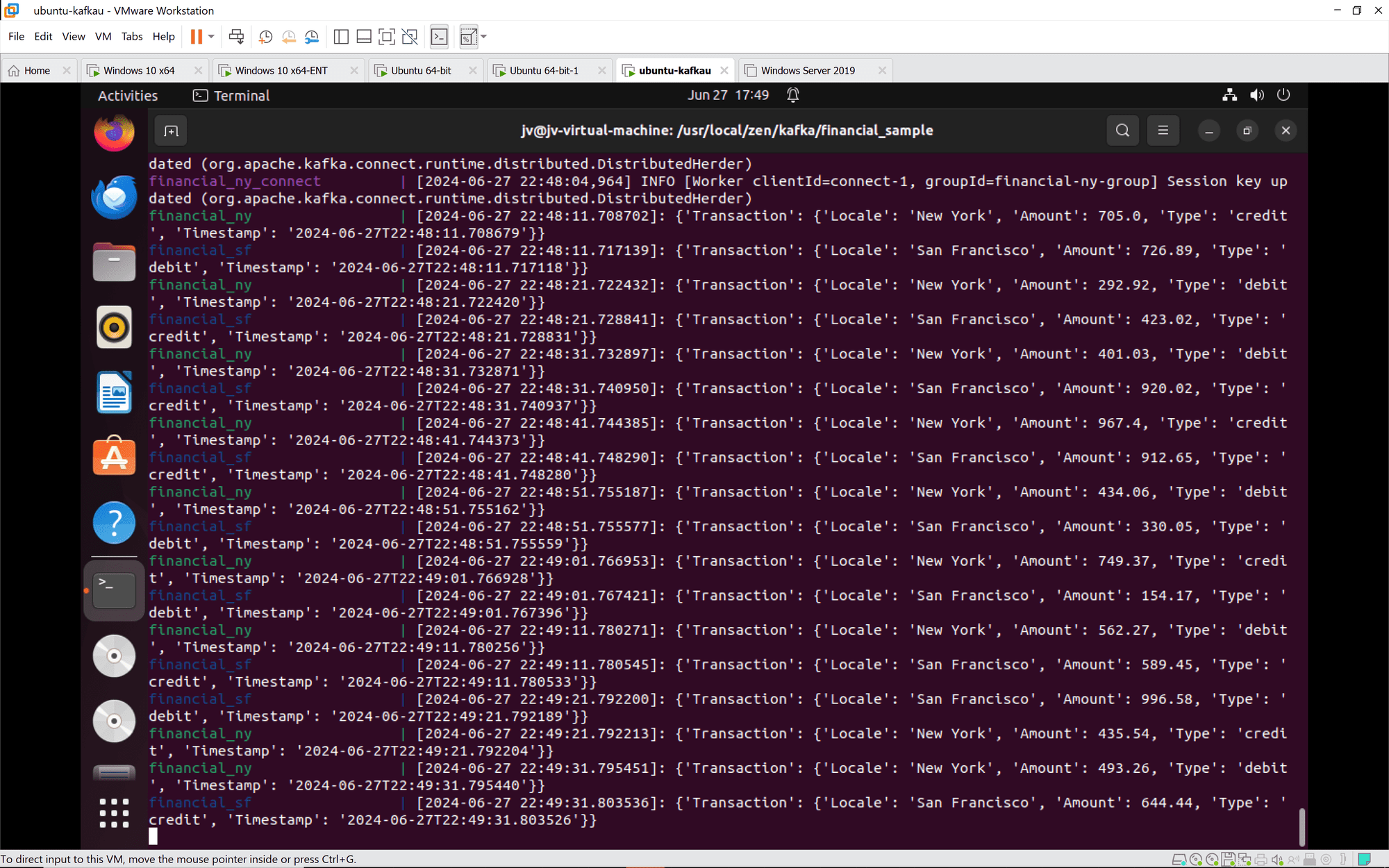
Connexion Kafka: Les instances de Kafka Connect rejoignent correctement les groupes et se synchronisent. Les tâches et les connecteurs sont configurés et démarrés comme prévu.
Transactions financières: Les transactions provenant de New York et de San Francisco sont traitées et enregistrées correctement. Les transactions comprennent une variété d'actions de crédit et de débit avec des montants et des horodatages variables.
Conclusion
L'intégration d'Actian Zen avec les connecteurs Kafka offre une solution puissante pour la streaming et le traitement de données en temps réel. En suivant ce guide, vous pouvez mettre en place un système robuste pour gérer les transactions financières, en veillant à ce que les données soient diffusées, traitées et stockées de manière efficace. Cette configuration démontre non seulement les Fonctionnalités d'Actian Zen et de Kafka, mais aussi la facilité de déploiement à l'aide de Docker et de Docker Compose. Que vous traitiez des transactions financières ou d'autres applications à forte intensité de données, cette solution offre une approche évolutif et fiable de la gestion des données en temps réel.
Pour plus de détails et de guides visuels, consultez le site de l Académie Actian et la documentation complète documentation. Bon codage !

Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)