Intégration de Python avec Vector ou Actian Ingres
Actian Corporation
12 janvier 2018

Introduction
Aujourd'hui, nous allons voir comment démarrer avec Actian Vector, notrein-memory de haute performance . base de données analytiqueet Python, l'un des langages les plus utilisés par les data scientists ces derniers temps. En utilisant les techniques ci-dessous, vous serez en mesure de démarrer avec Python en utilisant Vector ODBC et JDBC. (Vous pourrez également utiliser certaines de ces techniques avec Actian Ingres; voir la section Références en bas de page pour plus d'informations). Nous aborderons également quelques fonctions de base simples de CURD (Create, Update, Read, and Delete) à l'aide de Python.
Le code suivant a été testé avec Python 2.7 32-bit. Si vous ne connaissez pas Vector, cette installation devrait prendre 2 à 3 heures, et un peu moins si vous êtes familier avec Vector et Python.
Modules nécessaires pour ODBC et Vector
- Pyodbc (que vous pouvez obtenir sur https://mkleehammer.github.io/pyodbc/)
- Pilote ODBC Vector
Note: pypyodbc fonctionnerait également pour la même configuration mais le code suivant a été testé avec pyodbc.
Connexion ODBC à l'aide d'un DSN
Dans cette section, nous aborderons les bases de la création d'un DSN sous Linux et Windows qui sera utilisé par la connexion ODBC.
Linux
Pour que le DSN fonctionne sous Linux, l'environnement doit être configuré correctement. Avec d'autres paramètres Vector que vous obtenez en utilisant la source .ingVWsh (si le code d'installation est VWW), ce qui suit doit être exporté ou vous pouvez ajouter ce qui suit dans .bashrc pour faire fonctionner l'ODBC.
ODBCSYSINI=$II_SYSTEM/ingres/files export ODBCSYSINI
Note: veuillez définir II_ODBC_WCHAR_SIZE si nécessaire en fonction de votre gestionnaire de pilote ODBC.
L'utilitaire Ingres 'iiodbcadmin' peut être utilisé sous Linux pour créer un DSN, comme le montre l'exemple ci-dessous.
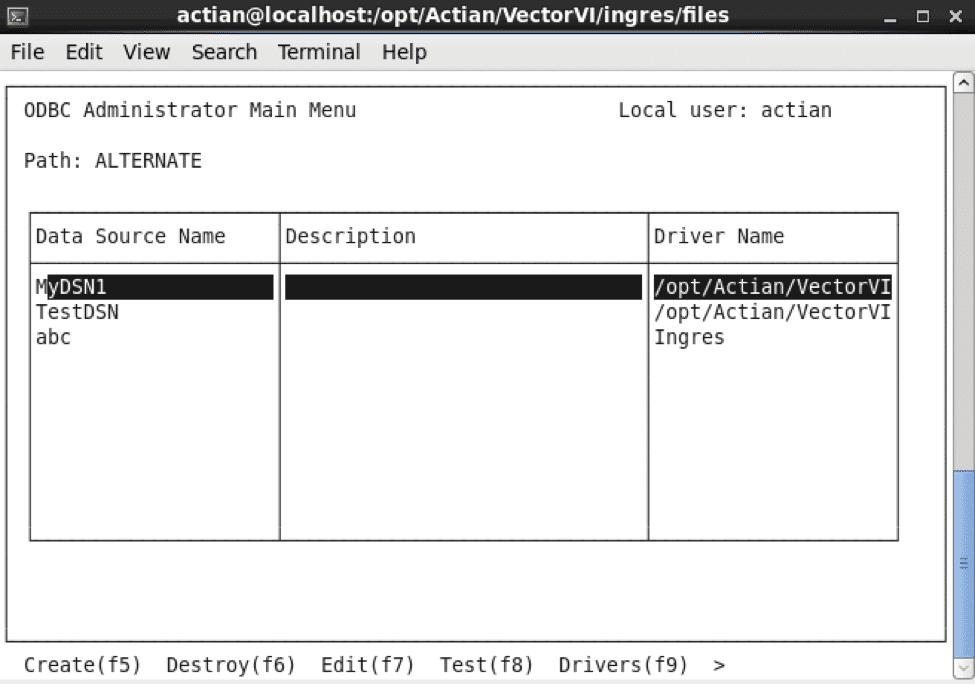
Note: Si vous êtes familier avec le pilote ODBC Ingres et ses paramètres, vous pouvez également éditer odbc.ini comme dans l'exemple ci-dessous. Les détails ajoutés seront reflétés dans l'utilitaire 'iiodbcadmin'.
Exemple :
[Sources de données ODBC] MYDSN=Ingres [MyDSN] Driver=/opt/Actian/VectorVI/ingres/lib/libiiodbcdriver.1.so Description= Vendeur=Actian Corporation DriverType=Ingres Nom d'hôte=(local) ListenAddress=VI Database=test ServerType=Ingres utilisateur password=actian
Pour plus de détails, voir Configurer une source de données (Linux)
Fenêtres
Si vous utilisez python 32 bits, vous aurez besoin d'un runtime client 32 bits pour utiliser le DSN ODBC 32 bits. De même, si vous utilisez python 64 bits, vous aurez besoin d'un moteur d'exécution client 64 bits pour utiliser le DSN ODBC 64 bits.
Pour plus de détails, voir Configurer une source de données (Windows).
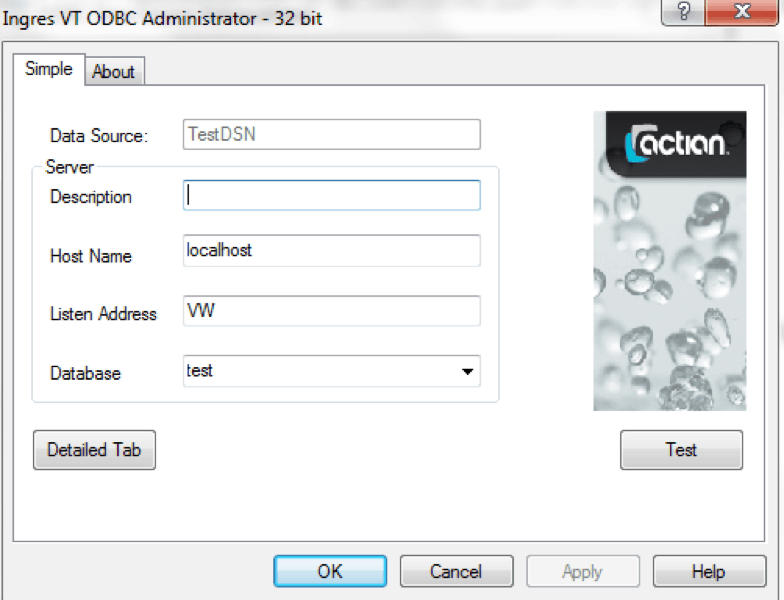
Voici une capture d'écran d'une DSN 32 bits :
Connexion ODBC en Python
Vous pouvez utiliser le DSN pour vous connecter :
import pyodbc as pdb
conn = pdb.connect("dsn= MYDSN " )
Avec ce nom d'utilisateur et ce mot de passe :
conn = pdb.connect("dsn=TestDSN;uid=username;pwd=password" )
Voici un autre exemple :
conn = pdb.connect("dsn=TestDSN;uid=actian;pwd=actian123" )
Vous pouvez également vous connecter directement sans DSN en utilisant les différents paramètres comme le montre l'exemple ci-dessous.
conn = pdb.connect("driver=Ingres;servertype=ingres;server=@localhost,tcp_ip,VW;uid=actian;pwd=actian123;database=test")
Modules nécessaires à la connexion JDBC
- jaydebeapipython
- Pilote JDBC Vector (installé à l'aide du clientruntime d'ESD)
Jaydebeapi peut être facilement installé en utilisant 'pip install JayDeBeApi'. Cependant, si pour certaines raisons vous ne pouvez pas utiliser pip, vous pouvez aussi l'installer manuellement. Vous pouvez télécharger le code source à partir de https://github.com/baztian/jaydebeapi sur votre ordinateur. Décompressez et exécutez 'python setup.py install'. Cependant, vous devrez installer les outils de développement à la racine (yum install gcc-c++ ) pour l'installer manuellement.
Connexion JDBC en Python
import jaydebeapi as jdb
conn = jdb.connect('com.ingres.jdbc.IngresDriver','jdbc:ingres://localhost:VI7/test' ,driver_args={'user': 'actian', 'password': 'actian'}, jars='iijdbc.jar')
cursor = conn.cursor()
Exemple : Création d'un tableau et insertion de valeurs (création dans CURD)
Un simple encart
curseur = conn.curseur()
#Drop table :
cursor .execute("DROP TABLE IF EXISTS customer")
#Créer une table :
cursor.execute("CREATE TABLE customer(customer_no INT NOT NULL PRIMARY KEY,last_name VARCHAR(40),first_name CHAR(40))")
conn.commit()
#Insérer des lignes dans le tableau des clients :
cursor .execute("INSERT INTO customer VALUES (1, 'Harry', 'Potter')")
cursor .execute("INSERT INTO customer VALUES (2, 'Ron', 'Weasley')")
cursor .execute("INSERT INTO client VALUES (3, 'Draco', 'Malfoy')")
Pour exécuter une seule instruction, on utilise .execute().
Insertion à l'aide de variables de liaison
Pour insérer plusieurs lignes à l'aide de variables de liaison, vous pouvez procéder comme suit :
#Insérer des lignes dans le tableau des clients :
cursor .execute("INSERT INTO customer VALUES ( ?, ?, ?)", 4, 'A', 'B')
Insertion de plusieurs lignes à l'aide de .executemany()
données =[
(1, "Harry", "Potter"),
(2, "Ron", "Weasley"),
(3, "Draco", "Malefoy")]
cursor.executemany("INSERT INTO customer VALUES ( ?,?, ?)",data)
#Dans le cas où vous devez insérer des données uniquement dans certaines colonnes,
données =[
(8, 'A', ),
(9, 'B',),
(10, 'C', )]
cursor.executemany("insert into customer(customer_no, first_name) VALUES( ?, ?)", data)
Autre exemple d'insertion de plusieurs lignes
Si les valeurs de la colonne doivent être ajoutées dans certaines plages, comme dans l'exemple suivant, les éléments de la colonne testid du tableau test seront ajoutés de 0 à 99 :
cursor .execute("DROP TABLE IF EXISTS test")
#CREATING TABLE to insert many rows using executemany()
cursor .execute("CREATE TABLE test(testid varchar(100))")
data_to_insert = [(i,) for i in range(100)]
cursor.executemany("INSERT INTO test (testid) VALUES ( ?)", data_to_insert)
conn.close() ;
Mise à jour des données (la mise à jour en cours)
Mise à jour d'une seule ligne
updatedata= ('X', 'Y', 10)
sql = 'UPDATE customer SET last_name = ? , first_name= ? where customer_no = ? '
cursor.execute(sql, updatedata)
Récupérer des données (la lecture dans cuRd)
Récupération d'une ligne
Il existe de nombreuses fonctions pour récupérer des données comme #fetchone(), fetchall(), etc :
cursor.execute("select count(*) from customer")
result=cursor.fetchone()
print(result[0])
cursor.close()
conn.close()
Récupération d'un grand nombre de lignes
cursor.execute("select First 3 * from customer")
for row in cursor :
print ("Numéro de client : ",ligne[0]," Prénom : ",ligne[2]," Nom : ",ligne[2])
cursor.close()
conn.close()
Les résultats seront affichés comme suit :
Cust_no : 1 First Name : Potter Nom de famille : Potter
Cust_no : 2 First Name : Weasley Nom : Weasley
Cust_no : 3 Prénom : Malefoy Nom de famille : Malefoy
Suppression de données (le "Delete" de curD)
Suppression d'une seule ligne
sql = 'DELETE from customer where customer_no =9' cursor.execute(sql)
Suppression de plusieurs lignes
#Supprimez plusieurs lignes en utilisant "in" :
id_list = [1,2,3] requête= "delete from customer where customer_no in (%s)" % ','.join(['?'] * len(id_list)) cursor.executerequête, id_list) Code complet pour ODBC /JDBC
Importer pyodbc en tant que pdb :
conn = pdb.connect("dsn=TestDSN;uid=vidisha;pwd=vidisha" )
#conn= pdb.connect("driver=Ingres;servertype=ingres;server=@localhost,tcp_ip,VW;uid=vidisha;pwd=vidisha;database=test")
# Python 2.7
conn.setdecoding(pdb.SQL_CHAR, encoding='utf-8')
conn.setdecoding(pdb.SQL_WCHAR, encoding='utf-8')
conn.setencoding(str, encoding='utf-8')
conn.setencoding(unicode, encoding='utf-8')
conn.autocommit= True
cursor = conn.cursor()
print("DROPPING TABLE")
cursor .execute("DROP TABLE IF EXISTS customer")
conn.commit
print("nCREATING TABLE ")
cursor .execute("CREATE TABLE customer(customer_no INT NOT NULL PRIMARY KEY,last_name VARCHAR(40),first_name CHAR(40))")
print("INSERTING ROWS TO TABLE customer")
cursor.execute("INSERT INTO client VALUES (1, 'Harry', 'Potter')")
cursor.execute("INSERT INTO client VALUES (2, 'Ron', 'Weasley')")
cursor.execute("INSERT INTO client VALUES (3, 'Draco', 'Malfoy')")
data =[
(5, 'Harry', 'Potter'),
(6, 'Ron', 'Weasley'),
(7, 'Draco', 'Malfoy')]
cursor.executemany("INSERT INTO customer VALUES ( ?,?, ?)",data)
#ou
data =[
(8, 'A', ),
(9, 'B',),
(10, 'C', )]
cursor.executemany("insert into customer(customer_no, first_name) VALUES( ?, ?)", data)
print("DROPPING TABLE")
cursor.execute("DROP TABLE IF EXISTS test")
print("CREATING TABLE to insert many rows using executemany()")
cursor.execute("CREATE TABLE test(testid varchar(100))")
data_to_insert = [(i,) for i in range(100)]
print("Insérer plusieurs données dans test")
cursor.executemany("INSERT INTO test (testid) VALUES ( ?)", data_to_insert)
print("Récupération du COUNT DE LA TABLE")
cursor.execute("select count(*) from customer")
result=cursor.fetchone()
print(result[0])
print("FETCHING MANY ROWS")
cursor.execute("select First 3 * from customer")
results=cursor.fetchall()
for row in results :
print ("Numéro de client : ",ligne[0]," Prénom : ",ligne[2]," Nom : ",ligne[2])
print("UPDATING SINGLE ROW")
updatedata= ('X', 'Y', 10)
sql = 'UPDATE customer SET last_name = ? , first_name= ? where customer_no = ? '
cursor.execute(sql, updatedata)
print("DELETING A ROW")
sql = 'DELETE from customer where customer_no =9'
cursor.execute(sql)
print("Suppression de plusieurs lignes en utilisant 'IN'")
id_list = [1,2,3]
requête= "delete from customer where customer_no in (%s)" % ','.join(['?'] * len(id_list))
cursor.executerequête, id_list)
#ferme la connexion
cursor.close()
conn.close()
Pour JDBC, le code est le même, seule la chaîne de connexion est différente :
import jaydebeapi as jdb
conn = jdb.connect('com.ingres.jdbc.IngresDriver','jdbc:ingres://localhost:VW7/test' ,driver_args={'user': 'vidisha', 'password': 'vidisha'},jars='iijdbc.jar')
cursor = conn.cursor()
print("DROPPING TABLE")
cursor .execute("DROP TABLE IF EXISTS customer")
conn.commit
print("nCREATING TABLE ")
cursor .execute("CREATE TABLE customer(customer_no INT NOT NULL PRIMARY KEY,last_name VARCHAR(40),first_name CHAR(40))")
print("INSERTING ROWS TO TABLE customer")
cursor.execute("INSERT INTO customer VALUES (1, 'Harry', 'Potter')")
cursor.execute("INSERT INTO customer VALUES (2, 'Ron','Weasley')")
cursor.execute("INSERT INTO customer VALUES (3, 'Draco', 'Malfoy')")
Références supplémentaires :
- Page produit et guides Actian Vector
- pyodbc
- JayDeBeAPI
- Un exemple plus détaillé utilisant Python, Vector et Ingres
S'abonner au blog d'Actian
Abonnez-vous au blogue d'Actian pour recevoir des renseignements sur les données directement à vous.
- Restez informé - Recevez les dernières informations sur l'analyse des données directement dans votre boîte de réception.
- Ne manquez jamais un article - Vous recevrez des mises à jour automatiques par courrier électronique pour vous avertir de la publication de nouveaux articles.
- Tout dépend de vous - Modifiez vos préférences de livraison en fonction de vos besoins.
S'abonner
(c'est-à-dire sales@..., support...).