Marquez : La solution de découverte des métadonnées chez WeWork
Actian Corporation
10 décembre 2020

Créée en 2010, WeWork est une société mondiale de location de bureaux et d'espaces de travail. Son objectif est de fournir des espaces de collaboration à des équipes de toute taille, qu'il s'agisse de startups, de PME ou de grandes entreprises. Pour ce faire, les services proposés par WeWork se répartissent en trois catégories différentes :
- Espace: Pour garantir aux entreprises un espace optimal, WeWork doit fournir l'infrastructure appropriée, qui consiste à réserver des salles pour les entretiens/les entretiens individuels ou même des bâtiments entiers pour les grandes entreprises. Ils doivent également s'assurer qu'ils sont équipés des installations appropriées telles que des cuisines pour le déjeuner et les pauses café, des salles de bains, etc.
- Communauté: Via l'application interne de WeWork, l'entreprise permet aux membres de WeWork de se connecter les uns aux autres, que ce soit au niveau local dans leur propre espace WeWork, ou au niveau mondial. Par exemple, si une entreprise a besoin d'un retour d'information pour un projet de la part de certains postes (comme un développeur ou un concepteur UX), elle peut directement demander un retour d'information et des suggestions via l'application à n'importe quel membre, quel que soit son emplacement.
- Services: WeWork fournit également à ses membres des services informatiques complets en cas de problème, ainsi que d'autres services tels que les services de paie, les services publics, etc.
En 2020, WeWork représente :
- Plus de 600 000 adhésions.
- Des sites dans 127 villes de 33 pays différents.
- 850 bureaux dans le monde.
- a généré des recettes de 1,82 milliard de dollars.
Il est clair que WeWork travaille avec toutes sortes de données provenant de son personnel et de ses clients, qu'il s'agisse d'individus ou d'entreprises. La grande entreprise avait donc besoin d'une plateforme où ses experts en données pourraient voir, collecter, agréger et visualiser les métadonnées de leur écosystème de données. Ce besoin a été résolu par la création de Marquez.
Cet article se concentrera sur la mise en œuvre de Marquez par WeWork, principalement par le biais de la documentation gratuite et accessible fournie sur divers sites Web, afin d'illustrer l'importance de disposer d'une plateforme de métadonnées à l'échelle de l'entreprise afin de devenir véritablement axé sur les données.
Pourquoi gérer et utiliser des métadonnées?
Dans sa conférence "A métadonnées Service for Data Abstraction, Data Lineage & Event-Based Triggers" au Data Council en 2018, Willy Lulciuc, ingénieur logiciel pour le projet Marquez chez WeWork, a expliqué que les métadonnées sont cruciales pour trois raisons :
- Assurer la qualité des données: Lorsque les données n'ont pas de contexte, il est difficile pour les citoyens de faire confiance à leurs données : y a-t-il des champs manquants ? La documentation est-elle à jour ? Qui est le propriétaire des données et l'est-il toujours ? L'utilisation de métadonnées permet de répondre à ces questions.
- Comprendre l'historique des données: Connaître les origines et les transformations de vos données est essentiel pour être en mesure de savoir par quelles étapes vos données sont passées au fil du temps.
- Démocratisation des jeux de données: Selon Willy Lulciuc, la démocratisation des données dans l'entreprise est essentielle ! Disposer d'un portail central ou d'une interface utilisateur permettant aux utilisateurs de rechercher et d'explorer leurs jeux de données est l'un des moyens les plus importants dont disposent les entreprises pour créer une véritable culture de données en libre-service .
En résumé, il s'agit de créer un écosystème de données sain. Willy explique que la capacité à gérer et à utiliser les métadonnées crée une culture de données durable où les individus n'ont plus besoin de demander de l'aide pour trouver et travailler avec les données dont ils ont besoin. Dans sa diapositive, il passe en revue trois catégories différentes qui constituent un écosystème de données sain :
- Être un écosystème en libre-service, où les utilisateurs de données et les entreprises ont la possibilité de découvrir les données et les métadonnées dont ils ont besoin, et d'explorer les ressources de données de l'entreprise lorsqu'ils ne savent pas exactement ce qu'ils recherchent. Fournir des données en contexte permet à tous les utilisateurs et citoyens des données de travailler efficacement sur leurs cas d'utilisation des données.
- Être autonome en donnant aux utilisateurs de données la liberté d'expérimenter avec leurs jeux de données ainsi que la flexibilité de travailler sur chaque aspect de leurs jeux de données , qu'il s'agisse de jeux de données données d'entrée ou de jeux de données sortie, par exemple.
- Enfin, au lieu de s'appuyer sur certaines personnes ou certains groupes, un écosystème de données sain permet à tous les employés d'être responsables de leurs propres données. Chaque utilisateur a la responsabilité de connaître ses données, ses coûts (ces données produisent-elles suffisamment de valeur ?) et de suivre la documentation de ses données afin d'instaurer la confiance autour de ses jeux de données.
Pipeline de réservation de chambres Avant
Comme mentionné ci-dessus, l'utilisation des métadonnées est cruciale pour que les utilisateurs de données puissent trouver les données dont ils ont besoin. Dans sa présentation, Willy a partagé une situation réelle qui prouve que métadonnées sont essentielles : Le pipeline de données de WeWork pour la réservation d'une chambre.
Pour un "WeWorker", les étapes sont les suivantes :
- Trouver un lieu (l'exemple était un complexe immobilier à San Francisco).
- Choisir la taille de la salle appropriée (généralement en fonction du nombre de participants - dans ce cas, ils ont choisi une salle pouvant accueillir de 1 à 4 personnes).
- Choisissez la date à laquelle la réservation aura lieu.
- Décidez du créneau horaire pour lequel la salle est réservée ainsi que de la durée de la réunion.
- Confirmer la réservation.
Maintenant que nous avons un exemple du fonctionnement de leur pipeline de réservation, Willy nous montre comment une équipe de données typique travaillerait pour extraire des données sur les réservations de WeWork. Dans ce cas, l'exercice consistait à trouver le bâtiment qui contenait le plus de réservations de chambres, et à extraire ces données pour les envoyer à la direction. Les étapes qu'il a décrites sont les suivantes :
- Lire les réservations de chambres à partir d'une source de données (généralement inconnue).
- Récapitulez toutes les réservations de chambres et indiquez les lieux les plus importants.
- Une fois l'emplacement du sommet calculé, l'étape suivante consiste à l'écrire dans une source de données de sortie.
- Exécutez la tâche une fois par heure.
- Traiter les données à l'aide de fichiers .csv et les stocker quelque part.
Cependant, Willy a déclaré que même si ces étapes semblent suffisantes, des problèmes surviennent généralement. Il passe en revue trois types de problèmes au cours du processus d'embauche :
- Où puis-je trouver le jeu de données de l'agence pour l'emploi ?
- Le jeu de données a-t-il un propriétaire ? De qui s'agit-il ?
- À quelle fréquence le jeu de données est-il mis à jour ?
Il est difficile de répondre à la plupart de ces questions et les emplois finissent par échouer. Si l'on n'est pas sûr de ces informations et si l'on ne s'y fie pas, il peut être difficile de présenter des chiffres à la direction. Ce sont ces problèmes et ces questions qui ont poussé WeWork à développer Marquez.
Qu'est-ce que Marquez ?
Willy définit la plateforme comme une "solution ouverte pour l'agrégation, la collecte et la visualisation des métadonnées de l'écosystème de données [de WeWork]". En effet, Marquez est un système modulaire et a été conçu comme une solution agnostique de plateforme hautement évolutif et hautement extensible pour la gestion desmétadonnées . Il se compose des éléments suivants :
- métadonnées dépôt: Stocke tous les travaux et jeu de données métadonnées, y compris un historique complet des exécutions de travaux et des statistiques au niveau des travaux (c'est-à-dire le nombre total d'exécutions, les durées moyennes d'exécution, les réussites/échecs, etc.)
- métadonnées API: API RESTful permettant à un ensemble diversifié de clients de commencer à collecter des métadonnées autour de la production et de la consommation de jeu de données .
- métadonnées UI: Utilisée pour ladécouverte de jeu de données , la connexion de plusieurs jeux de données et l'exploration de leur graphe de dépendance.
Marquez's Design
Marquez fournit des clients spécifiques à chaque langue qui implémentent l'API des métadonnées . Cela permet à un ensemble varié d'applications de traitement de données de créer une collection de métadonnées . Dans leur version initiale, ils ont fourni un support pour Java et Python.
L'API métadonnées extrait des informations sur la production et la consommation de jeux de données. Il s'agit d'une couche sans état responsable de la spécification de la persistance et de l'agrégation des métadonnées . L'API permet aux clients de collecter et/ou d'obtenir des informations sur les jeu de données vers/depuis ledépôt métadonnées .
métadonnées doit être collectée, organisée et stockée de manière à permettre des requêtes exploratoires riches via l'interface utilisateur de métadonnées . Ledépôt métadonnées sert de catalogue d'informations de jeu de données encapsulées et proprement abstraites par l'API de métadonnées .
Les jeux de données dans Marquez sont indexés et classés grâce à l'utilisation d'un moteur de recherche basé sur un mot clé ou une phrase, ainsi que sur la documentation d'un jeu de données: plus un jeu de données est contextualisé, plus il a de chances d'apparaître en premier dans les résultats de la recherche. La documentation d'un jeu de donnéescomprend par exemple sa description, son propriétaire, son schéma, sa balise, etc.
Vous pouvez voir plus de détails sur le modèle de données de Marquez dans la présentation elle-même ici : https://www.youtube.com/watch?v=dRaRKob-lRQ&ab_channel=DataCouncil
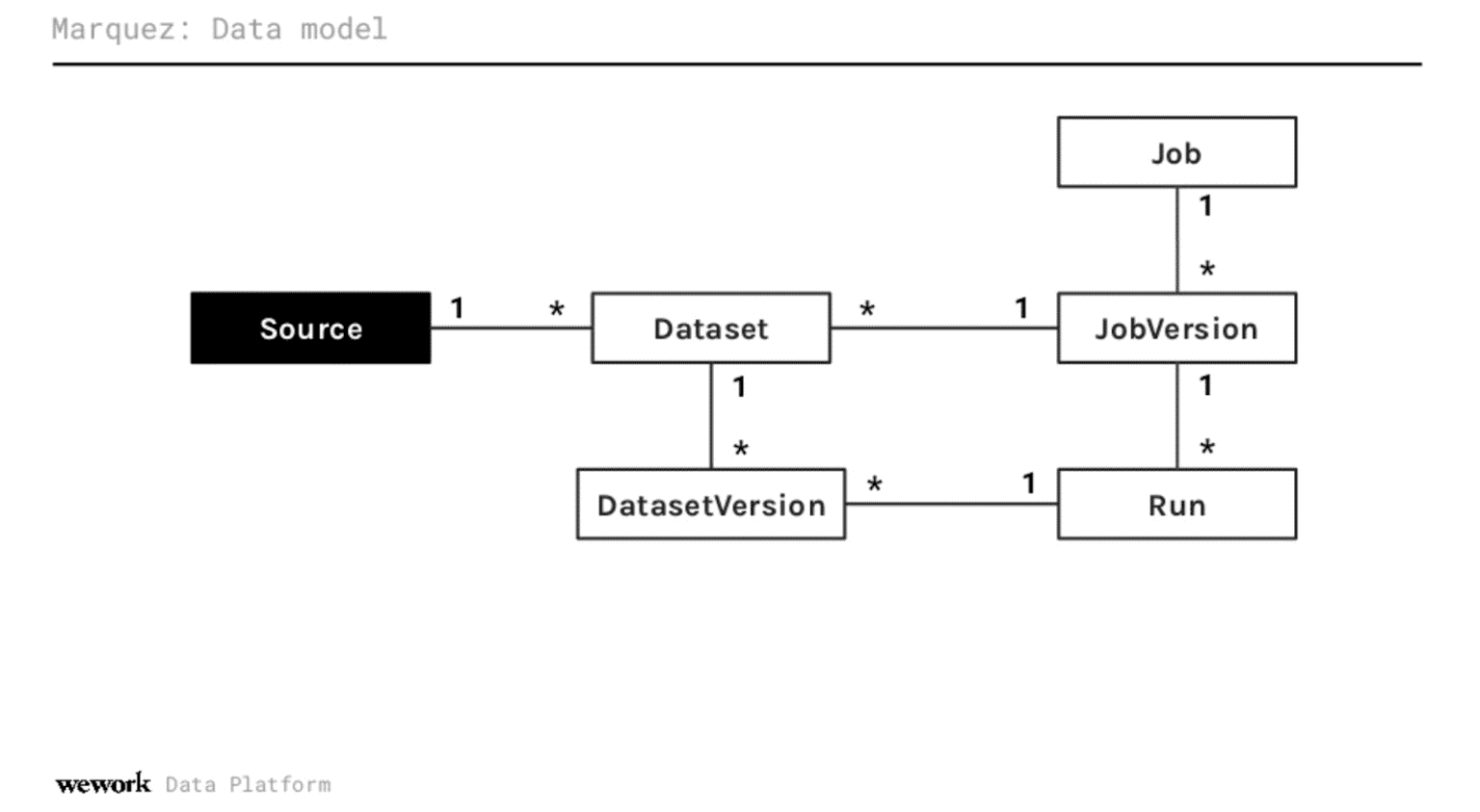
L'avenir de la gestion des données chez WeWork
Deux ans après le lancement du projet, Marquez s'est avéré être d'une grande aide pour le géant du leasing. Sa feuille de route à long terme est de se concentrer uniquement sur l'interface utilisateur de sa solution, en incluant davantage de visualisations et de représentations graphiques afin d'offrir aux utilisateurs des moyens plus simples et plus amusants d'interagir avec leurs données.
Ils proposent également diverses communautés en ligne via leur page Github, ainsi que des groupes sur LinkedIn pour ceux qui sont intéressés par Marquez, afin de poser des questions, d'obtenir des conseils ou même de signaler des problèmes sur la version actuelle de Marquez.
Sources d'information
A métadonnées Service for Data Abstraction, Data Lineage & Event-Based Triggers, WeWork. Youtube : https://www.youtube.com/watch?v=dRaRKob-lRQ&ab_channel=DataCouncil
29 Stunning WeWork Statistics - The New Era Of Coworking, TechJury.com : https://techjury.net/blog/wework-statistics/
Marquez : Collecter, agréger et visualiser les métadonnées d'un écosystème de données, https://marquezproject.github.io/marquez/
S'abonner au blog d'Actian
Abonnez-vous au blogue d'Actian pour recevoir des renseignements sur les données directement à vous.
- Restez informé - Recevez les dernières informations sur l'analyse des données directement dans votre boîte de réception.
- Ne manquez jamais un article - Vous recevrez des mises à jour automatiques par courrier électronique pour vous avertir de la publication de nouveaux articles.
- Tout dépend de vous - Modifiez vos préférences de livraison en fonction de vos besoins.
S'abonner
(c'est-à-dire sales@..., support...).