5 patrones de arquitectura de IA en el borde para entornos desconectados




Resumen
- Los entornos desconectados requieren arquitecturas de IA en el borde que funcionen totalmente sin conexión y sin depender de la nube.
- Hay cinco modelos de implementación que permiten una IA periférica resiliente: drones, fábricas, aprendizaje federado, almacenamiento y reenvío, y redes en malla.
- Los diseños nativos para el borde permiten la inferencia en tiempo real, una baja latencia y un funcionamiento fiable en redes remotas o con conexiones intermitentes.
- La elección de la arquitectura adecuada depende de la estabilidad de la conexión, los requisitos de latencia y las limitaciones de hardware.
Un camión de transporte que opera a más de 320 kilómetros de la torre de telefonía móvil más cercana no se detiene cuando se interrumpe la conexión. Un aerogenerador marino no suspende la detección de fallos porque el enlace por satélite falle durante una tormenta. En estos entornos, los sistemas de inferencia, los bucles de control y los sistemas de seguridad deben seguir funcionando independientemente del estado de la red. Sin embargo, la arquitectura dominante de IA en el borde sigue girando en torno a la conectividad y la IA en la nube.
Los entornos desconectados exigen arquitecturas nativas del borde y que den prioridad al modo sin conexión, diseñadas para garantizar la autonomía operativa. Las señales del mercado confirman esta realidad.
ABI Research prevé que el gasto en servidores periféricos alcance los 19 000 millones de dólares en 2027, de los cuales las implementaciones locales representarán cerca de 10 500 millones. En 2025, las organizaciones habrán implementado aproximadamente 815 millones de dispositivos IoT con capacidad periférica en todo el mundo.
La mayoría de los entornos operativos son intrínsecamente distribuidos, por lo que generan datos lejos de los sistemas centralizados en la nube. Las estrategias de implementación en el borde que dependen del envío de esos datos de un lado a otro para su procesamiento hacen que los sistemas de IoT pierdan información crucial, aumenten la latencia y provoquen pérdidas de datos. Sin embargo, las arquitecturas de borde propuestas siguen considerando la capacidad de funcionamiento sin conexión como un complemento, en lugar de como la opción predeterminada.
Presentamos cinco modelos de implementación de IA en el borde que funcionan sin necesidad de conectividad, analizando sus tácticas de implementación, casos prácticos, ventajas e inconvenientes, así como un marco de decisión para seleccionar el modelo más adecuado a tus prioridades operativas.
TL;DR
Resumen de los casos de uso adecuados para cada patrón de implementación documentado.
| Patrón | Ideal para |
| El dron (IA periférica autónoma de un solo nodo) | Sistemas móviles autónomos con restricciones energéticas estrictas y sin conexión a la nube |
| La fábrica (IA periférica multinodo con opción de nube) | Instalaciones con infraestructura local en entornos intermitentes |
| Aprendizaje federado jerárquico (cliente-periferia-nube) | Operaciones distribuidas en las que la privacidad es fundamental y los riesgos de fuga de datos son inaceptables |
| Inferencia desconectada de almacenamiento y reenvío | Operaciones con franjas horarias de conectividad programadas |
| La red (estructura distribuida de extremo a extremo) | Coordinación distribuida sin dependencia de la nube |
Por qué los entornos desconectados suponen un problema para la IA periférica
Existe un punto ciego estructural en lo que respecta a los entornos desconectados, motivado por la suposición de que las industrias que utilizan modelos de IA en el borde están centradas en la nube y operan con una conectividad permanente. Precisamente donde las aplicaciones de IA en el borde son más importantes, no existe un acceso constante a la red.
Qué significa realmente «desconectado»
Los entornos desconectados son entornos con una conectividad poco fiable o inexistente, que van desde situaciones de aislamiento físico total de la red hasta configuraciones intermitentes con frecuentes caídas de la conexión.
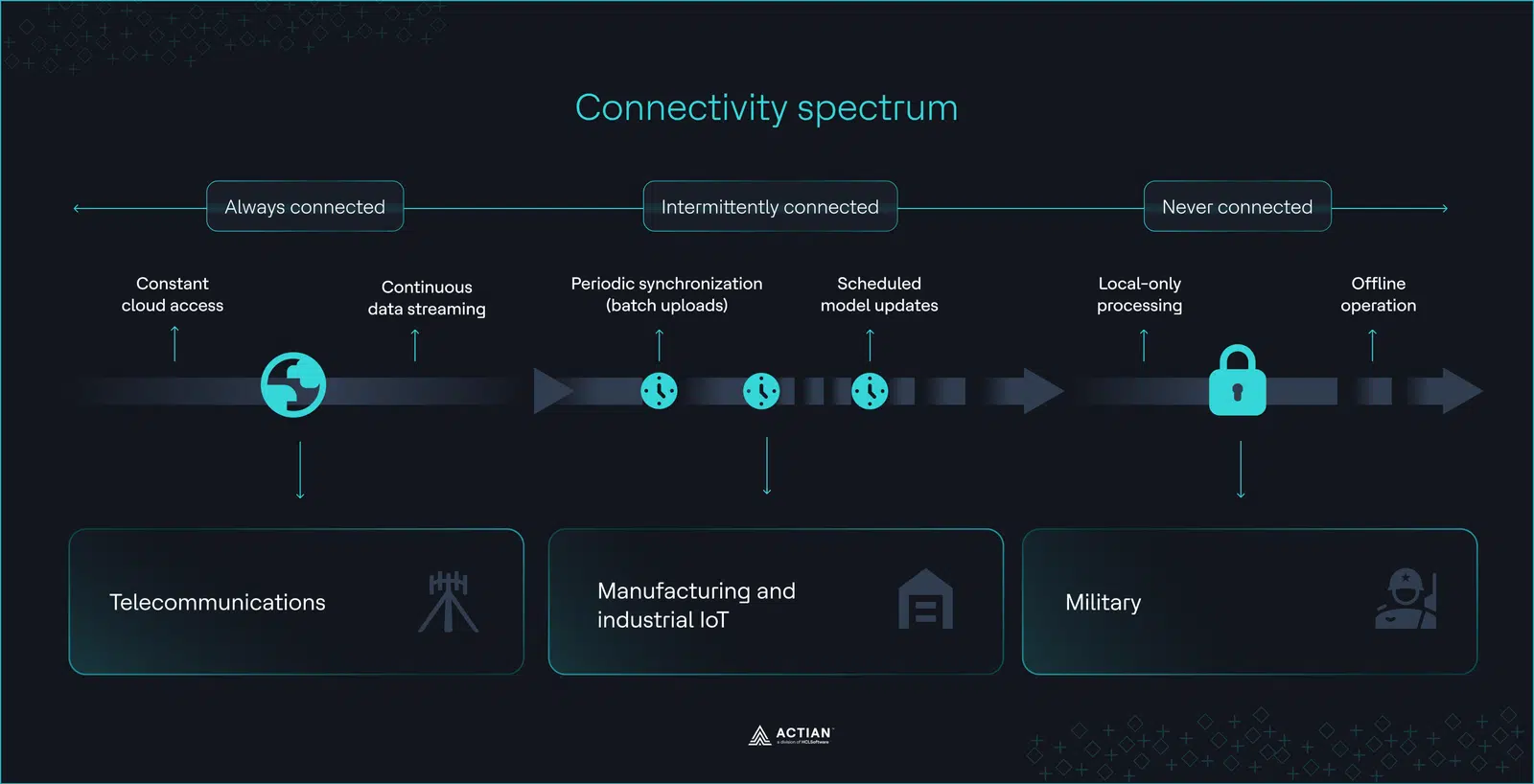
En estos entornos operativos, las capacidades de IA en el borde destacan especialmente, ya que permiten el procesamiento de datos en tiempo real, la baja latencia, la optimización del ancho de banda y la gestión de datos que requieren los entornos sin conexión.
Precedence Research estima que el mercado mundial de la IA en el borde alcanzará los 143 000 millones de dólares en 2034, lo que supone un aumento potencial del 472 % con respecto a los 25 000 millones de dólares de 2025. Para una parte significativa de este mercado, la conectividad constante a la nube no es viable. Sin embargo, la inferencia, el almacenamiento local de datos y la toma de decisiones en tiempo real deben continuar independientemente del estado de la red o de la ubicación.
Es precisamente en la desconexión donde la IA periférica demuestra su valor
Los entornos sin conexión, como las explotaciones mineras, las plantas de fabricación, las operaciones militares, los parques eólicos marinos y las ciudades inteligentes, ponen de manifiesto las limitaciones de las soluciones actuales de implementación de IA en el borde.
Rio Tinto opera en explotaciones mineras situadas a una distancia de hasta 1.500 kilómetros de la cobertura móvil, donde los operadores no pueden contar con una infraestructura centralizada. Necesitan robots de inspección autónomos que utilicen inteligencia artificial en el borde para realizar un seguimiento del personal y los vehículos, interpretando en tiempo real los datos procedentes de LiDAR 3D, imágenes térmicas y sensores de gas.
En la región de Pilbara, de Rio Tinto, operan al menos 300 camiones de transporte autónomos. Cada camión procesa aproximadamente 5 TB de datos al día a través de túneles subterráneos con conectividad limitada, lo que requiere redes LTE privadas para el procesamiento del IoT en los propios dispositivos.
Los parques eólicos marinos se enfrentan a una limitación similar. Las turbinas y los buques de inspección dejan de funcionar cuando las conexiones por satélite fallan debido a condiciones meteorológicas adversas o a la obstrucción de la línea de visión, y cada turbina registra una media de aproximadamente 8,3 fallos al año. Estos parques necesitan sistemas de IA en el borde que detecten los problemas de forma temprana, supervisen el tráfico marítimo en tiempo real, analicen los datos SCADA locales y activen inspecciones en función de las condiciones eólicas del momento.
En entornos de fabricación remotos, los directores de planta también necesitan la IA periférica para automatizar las inspecciones de calidad, predecir las averías de las máquinas y proteger la salud de los trabajadores.
Una necesidad similar de procesamiento local y seguro impulsa las operaciones militares, en las que los sistemas funcionan dentro de redes aisladas físicamente en entornos denegados, interrumpidos, intermitentes y limitados (DDIL) para mantener la confidencialidad y la integridad de los datos. Los soldados deben comunicarse con las unidades de mando y analizar datos de combate en tiempo real sin depender de centros de datos en la nube ni de grandes recursos informáticos.
Estos son los entornos en los que la implementación de la IA en el borde tiene un mayor impacto. Según Dell, el procesamiento de datos empresariales se trasladará a centros de datos distribuidos en 2026, pero la mayoría de las arquitecturas documentadas siguen haciendo hincapié en la transmisión de datos de vuelta a los centros de datos en la nube.
Las limitaciones del hardware condicionan la implementación del modelo
Las exigencias en materia de computación de IA y el escalado de cargas de trabajo en el perímetro también impulsan las recomendaciones de implementación en la nube y el perímetro.
Un modelo de aprendizaje profundo con 3 000 millones de parámetros puede requerir hasta 4 GB de RAM, pero los dispositivos periféricos, como los microcontroladores y los sensores del IoT, suelen disponer de menos de 1 GB en total para el sistema operativo, las cargas de trabajo y el almacenamiento. Las arquitecturas de entornos conectados dan por sentada una gran capacidad de cálculo que no existe en el borde.
Las arquitecturas de IA periférica deben partir, desde el primer momento, de supuestos que den prioridad al funcionamiento sin conexión y tengan en cuenta las limitaciones del hardware. Incorporar a posteriori la capacidad de funcionamiento sin conexión en los sistemas en la nube no compensará las interrupciones en la conectividad ni los recursos de hardware limitados. A continuación, detallamos cinco patrones arquitectónicos diseñados específicamente para entornos sin conexión.
Modelo 1: El «Drone» (IA periférica autónoma de un solo nodo)
En entornos donde no hay conectividad y la latencia operativa no permite los tiempos de ida y vuelta de la red, el límite de la implementación se reduce a un único dispositivo. La inferencia no puede delegarse, sincronizarse ni aplazarse. Los dispositivos periféricos, como los drones, los vehículos submarinos y los robots de inspección remota, deben tomar decisiones utilizando únicamente la capacidad de cálculo, la memoria y los datos de los sensores disponibles localmente.
Esta restricción define la arquitectura del dron. Toda la lógica de IA se ejecuta en un único dispositivo, sin necesidad de coordinación externa ni de descarga a la nube.
Cuando el dispositivo es toda la pila
Los sistemas móviles que deben funcionar de forma autónoma en entornos sin conexión son los que más se benefician de este patrón.
Sin una capa de coordinación externa, la captura de datos, el preprocesamiento, la inferencia, el almacenamiento y la lógica de control se llevan a cabo dentro de un paquete autónomo. Este paquete se ejecuta en un único nodo sin necesidad de conectarse en red con otros nodos ni de distribuir el entrenamiento del modelo.
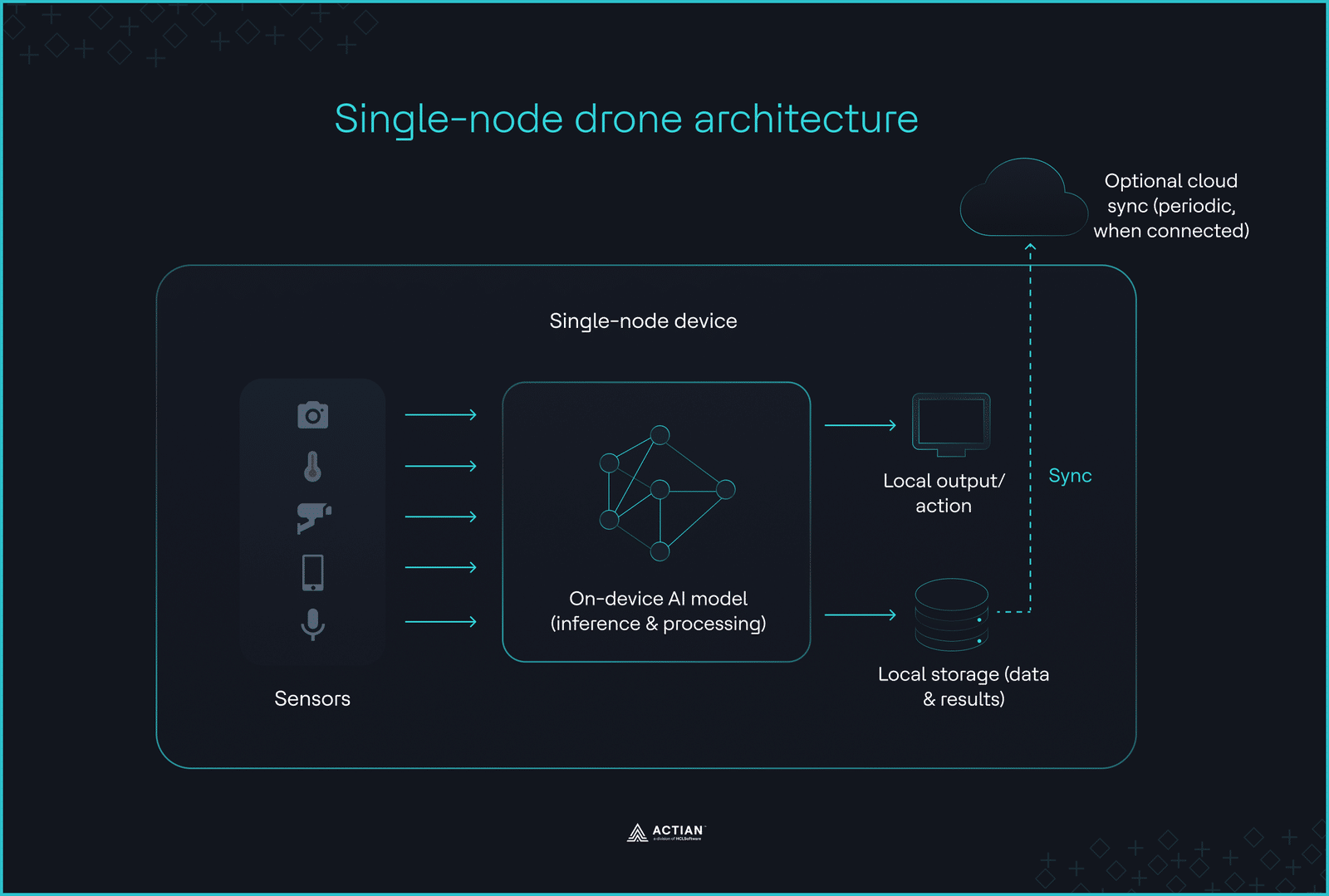
La lógica de decisión integrada permite que los dispositivos periféricos ejecuten operaciones predefinidas incluso cuando están desconectados. Una vez que un dispositivo captura datos, filtra la información redundante y conserva únicamente los datos relevantes para su posterior recuperación manual.
Los drones autónomos que realizan la detección de objetos y la clasificación del terreno en zonas mineras no pueden interrumpir su funcionamiento mientras esperan una inferencia externa. La arquitectura del dron elimina la dependencia de la red al centrarse en la inferencia en el propio dispositivo.
Esto lo convierte en el modelo más viable para entornos DDIL en los que la conectividad se deniega o se ve mermada de forma activa. Los drones de defensa no pueden dar por sentado que la red se recuperará ni que la señal de comando llegará. Toda coordinación en el campo de batalla debe poder ejecutarse únicamente desde el propio dispositivo.
GE Aerospace, que gestiona más de 45 000 motores de aviones comerciales y recopila más de 480 000 instantáneas de datos al día por aeronave, implementa esta arquitectura a gran escala. Los modelos de IA a bordo gestionan el mantenimiento predictivo en estricta conformidad con la norma DO-178C, que exige a GE Aerospace verificar todos los sistemas de a bordo frente a todas las posibles condiciones de fallo antes de que el avión despegue. Este control de calidad se ajusta al requisito arquitectónico del dron de no necesitar soporte externo tras la implementación del modelo.
El procesamiento local en un solo nodo requiere modelos de aprendizaje automático que ocupen poco espacio.
Optimización de la inteligencia en el borde
Los dispositivos periféricos funcionan con límites estrictos de memoria y energía, que se miden en megabytes y milivatios. Cuando las redes de precisión completa superan la memoria RAM disponible o los presupuestos energéticos, es necesario optimizar la capacidad del modelo antes de que la inferencia sea viable.
No todas las cargas de trabajo en el borde requieren una red neuronal. En entornos con limitaciones, como los parques eólicos marinos, los métodos estadísticos clásicos, como el algoritmo de Welford y la regresión lineal, suelen ofrecer mejores resultados que las redes neuronales en el procesamiento de datos en tiempo real.
Un microcontrolador que procesa los datos de los sensores mediante el algoritmo de Welford actualiza las estadísticas de forma secuencial, sin conservar los puntos de datos anteriores, lo que permite mantener bajos el consumo de memoria y de energía. Antes de llevar una red neuronal al límite de su capacidad de hardware, hay que valorar si la propia clase del modelo es adecuada para el caso de uso.
Cuando las redes neuronales son la opción más adecuada para la carga de trabajo, la cuantificación resuelve sus limitaciones de hardware reduciendo la precisión numérica de sus pesos, sesgos y activaciones. La reducción de 32 a 8 bits reduce el tamaño del modelo en aproximadamente un 75 %, con una pérdida de precisión inferior al 1 %.
Otra técnica de compresión de modelos, la poda, elimina los parámetros redundantes que contribuyen mínimamente a la precisión de los resultados. La poda de un modelo de detección de objetos como YOLOv5 puede reducir el número de parámetros y el coste computacional en un 40 % antes de su implementación.
Los marcos de trabajo TinyML, como TensorFlow Lite para microcontroladores, ONNX Runtime y PyTorch Mobile, permiten implementar modelos compactos. El siguiente código muestra un ejemplo de cuantificación con TensorFlow Lite.
import tensorflow as tf
import numpy as np
# Cuantificación posterior al entrenamiento utilizando el conversor TFLite
# Convierte números flotantes de 32 bits en enteros de 8 bits
def representative_dataset():
for i in range(100):
yield [X_train[i:i+1]]
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_quant_model = converter.convert()
Start with quantization for higher speedup rates without significant accuracy loss, followed by pruning to compress the model’s size further. For the drone architecture, the target size on a single microcontroller is <1MB. Plumerai’s person detection model demonstrates how compression techniques can achieve this goal. The model achieved 737KB on an ARM Cortex-M7 microcontroller with less than 256KB of on-chip RAM using binarized neural networks.
A nivel de hardware, los procesadores de bajo consumo como el NVIDIA Jetson Nano, el Google Edge TPU y el ARM Cortex-M ejecutan modelos de IA directamente en dispositivos periféricos, diseñados específicamente para cargas de trabajo de visión artificial y fusión de sensores. Las variantes del ARM Cortex-M ofrecen hasta 600 gigaoperaciones por segundo (GOPS) con una eficiencia energética media de 3 teraoperaciones por segundo por vatio (TOPS/W), dependiendo de la configuración.
El despliegue de drones introduce una rigidez arquitectónica. Dada la limitada capacidad de intervención durante el tiempo de ejecución, la arquitectura debe prever todos los estados de fallo durante la fase de diseño. La norma DO-178C refuerza esta restricción al exigir una validación completa del sistema antes de su despliegue. Los equipos deben diseñar cada actualización del modelo y cada corrección de comportamiento sin disponer de un margen de tiempo para la coordinación.
Modelo 2: La fábrica (IA periférica multinodo con opción de nube)
Durante las interrupciones de red en instalaciones industriales y grandes centros comerciales, la inferencia debe continuar de forma interna en múltiples máquinas. La arquitectura de la fábrica cumple este requisito distribuyendo las cargas de trabajo de IA entre clústeres periféricos locales, lo que permite mantener el control operativo dentro de los límites de la instalación.
La sincronización en la nube sigue siendo opcional y se utiliza únicamente para el reentrenamiento de modelos o el análisis por lotes, y no como una dependencia de tiempo de ejecución. La prioridad es mantener la resiliencia y la independencia operativa en todos los nodos, independientemente de la disponibilidad de la red.
La inferencia se queda en la planta de producción
La arquitectura de la fábrica se basa en tres componentes: puertas de enlace periféricas, nodos de cálculo y almacenamiento local.
Una pasarela periférica redirige las solicitudes de los sensores a los nodos periféricos, que extraen el contexto de bases de datos locales como Actian Zen, actúan en función de la inferencia del modelo y vuelven a escribir los resultados en la base de datos. La toma de decisiones y el procesamiento local se mantienen en las instalaciones. Los sistemas en la nube solo se encargan de actualizar los modelos periódicamente o cuando se activa un desencadenante.
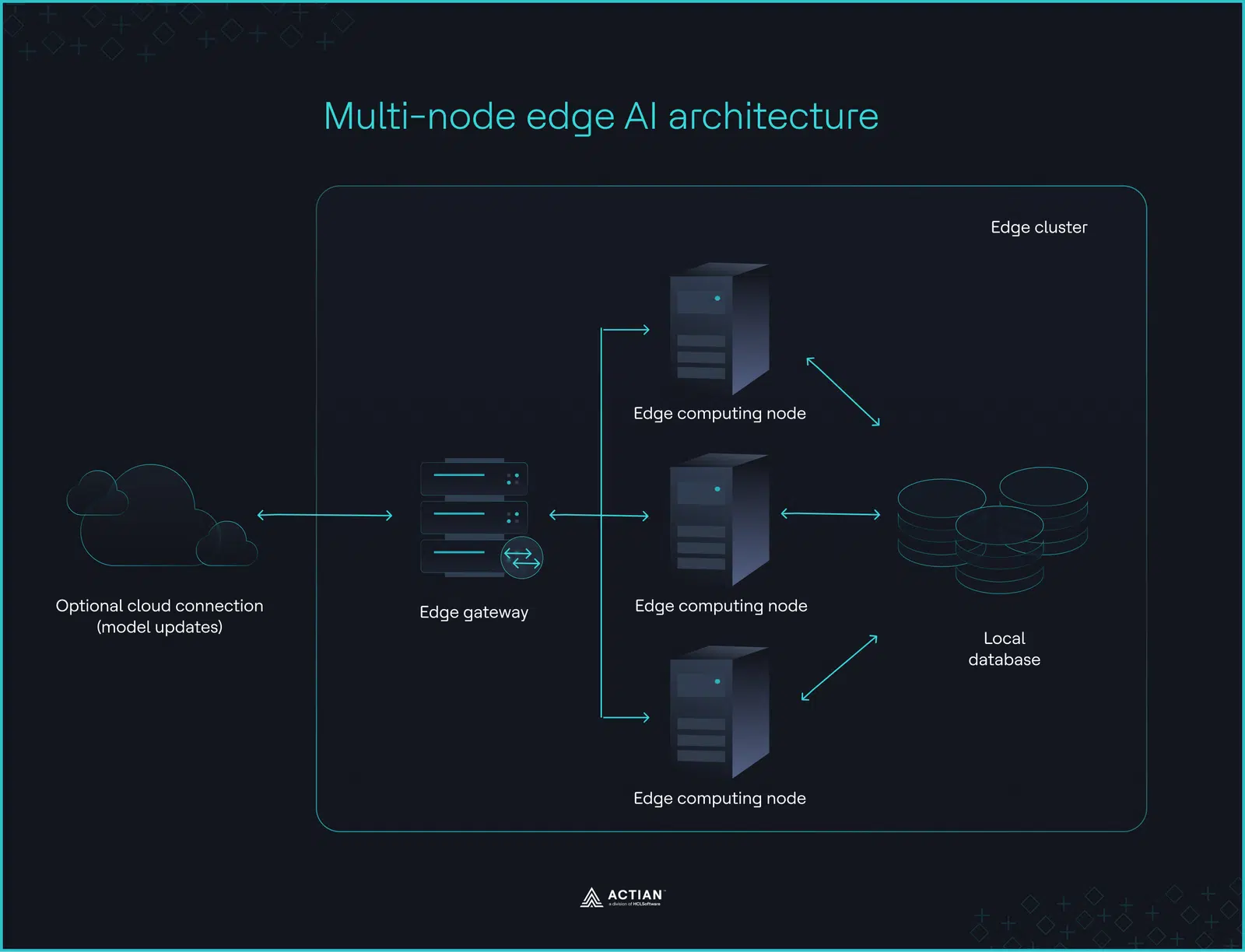
Los entornos industriales generan continuamente grandes volúmenes de datos de telemetría procedentes de sensores, controladores y sistemas de inspección. La distribución de la inferencia entre múltiples nodos periféricos permite mantener un alto rendimiento de inferencia. Sin embargo, sin una capa de coordinación local que gestione la distribución y el ciclo de vida de los modelos, los nodos periféricos funcionan como procesadores aislados en lugar de como un sistema coordinado.
K3s, AWS IoT Greengrass, Azure IoT Edge y Siemens Industrial Edge son herramientas de orquestación muy utilizadas para gestionar clústeres en el borde. Cada una de ellas se diferencia en su forma de gestionar la implementación de modelos y la administración de nodos.
K3s implementa modelos en contenedores como clústeres de nodos de trabajo con un plano de control que permite supervisar el estado del sistema. Al configurar el parámetro del punto final del almacén de datos, los equipos pueden almacenar datos locales en bases de datos locales como PostgreSQL y Actian Zen, sustituyendo así el SQLite predeterminado. Chick-fil-A utiliza K3s en el perímetro para procesar las transacciones en los puntos de venta de más de 3.000 restaurantes.
AWS IoT Greengrass implementa modelos de IA compilados en la nube como componentes con funciones de inferencia predefinidas en placas NVIDIA Jetson TX2, Intel Atom y dispositivos basados en Raspberry Pi. La inferencia se realiza de forma local, y los datos se exportan opcionalmente a AWS IoT Core para la optimización de los modelos. Las plantas de fabricación de Pfizer utilizan AWS IoT Greengrass para la monitorización de biorreactores casi en tiempo real con el fin de minimizar el riesgo de contaminación.
Siemens Industrial Edge implementa modelos en contenedores Docker directamente en la planta de producción, lo que permite conocer el estado de las máquinas en tiempo real. La fábrica de electrónica de Siemens en Erlangen redujo el tiempo de implementación de los modelos en un 80 % y las deteccioneserróneas de anomalías en las placas de circuito impreso (PCB) en un 50 % gracias a este orquestador. Al ejecutar la inferencia sobre las imágenes de las PCB de forma local y externalizar a la nube únicamente el reentrenamiento de los modelos, la fábrica ha reducido los costes de almacenamiento de datos en un 90 %.
Azure IoT Edge utiliza un manifiesto de implementación JSON para especificar qué modelos en contenedores se deben descargar en los dispositivos periféricos. El procesamiento de datos se lleva a cabo en el borde, y Azure IoT Hub proporciona una supervisión centralizada, mientras que los dispositivos mantienen su autonomía. Thomas Concrete Group utiliza Azure IoT Edge para recopilar datos de sensores integrados en el hormigón fresco, calcular el tiempo de fraguado del hormigón y enviar las predicciones a Azure IoT Hub.
La siguiente tabla muestra las diferencias entre cada orquestador.
| Criterios | K3s | Azure IoT Edge | AWS IoT Greengrass | Siemens Industrial Edge |
| Gestión de nodos | Gestiona los nodos a través de un plano de control ligero | Gestiona los nodos de forma remota a través de Azure IoT Hub | Gestiona los nodos a través de AWS IoT Core | Gestiona los nodos a través de la plataforma Siemens Industrial Edge Management |
| Implementación del modelo | Implementa modelos como pods de Kubernetes utilizando imágenes de contenedor estándar | Configura las implementaciones mediante un manifiesto JSON que define qué módulos, que contienen los modelos entrenados, se ejecutan en cada nodo | Implementa modelos como componentes con funciones de inferencia predefinidas | Implementa modelos directamente en las plantas de producción como contenedores Docker |
| Integración en la nube | Se puede integrar en una infraestructura central | Compatible con Azure IoT Hub | Se integra con AWS IoT Core | Admite la integración con los servicios de AWS |
Cuando la red OT constituye el perímetro de seguridad
Las empresas industriales están fusionando sus redes de TI y de tecnología operativa (OT) para dar soporte a las integraciones de IA e IoT en sus instalaciones. Sin embargo, esta fusión amplía su superficie de ataque. El 75 % de los ataques a la tecnología operativa (OT) se originan en entornos de TI, y el 80 % de los fabricantes señalan un aumento de las amenazas de seguridad en sus redes de TI y OT.
Para los equipos que estén considerando la implementación en fábrica de sistemas industriales, la segmentación de la red debe convertirse en una prioridad absoluta. Las soluciones de IA en el borde deben funcionar exclusivamente dentro de la red OT, de conformidad con el modelo Purdue. Los datos confidenciales y los procesos de inferencia permanecen cerca de las máquinas, los sensores y los controladores lógicos programables (PLC) que los necesitan. Este perímetro de seguridad minimiza el movimiento lateral de las amenazas procedentes de la red de TI.
Modelo 3: Aprendizaje federado jerárquico (cliente-periferia-nube)
El aprendizaje federado jerárquico (HFL) se basa en una infraestructura de tres capas diseñada para equipos que deben hacer frente a restricciones de movilidad de datos en el borde.
En el nivel más bajo, los dispositivos cliente realizan el entrenamiento local, optimizando los parámetros del modelo mediante el método de descenso de gradientes local. Los servidores periféricos del nivel intermedio agrupan los pesos actualizados del modelo procedentes de todos los dispositivos cliente para garantizar la coherencia estadística. Una ronda final de agrupación a cargo de un servidor en la nube constituye el nivel superior, dando lugar a un modelo global que los servidores periféricos vuelven a distribuir a los dispositivos cliente. Dado que solo las actualizaciones de los parámetros recorren esta jerarquía, la conectividad intermitente no detiene el progreso del entrenamiento.
La imagen siguiente muestra esta iteración, que continúa hasta que el modelo global alcanza la precisión deseada o converge.
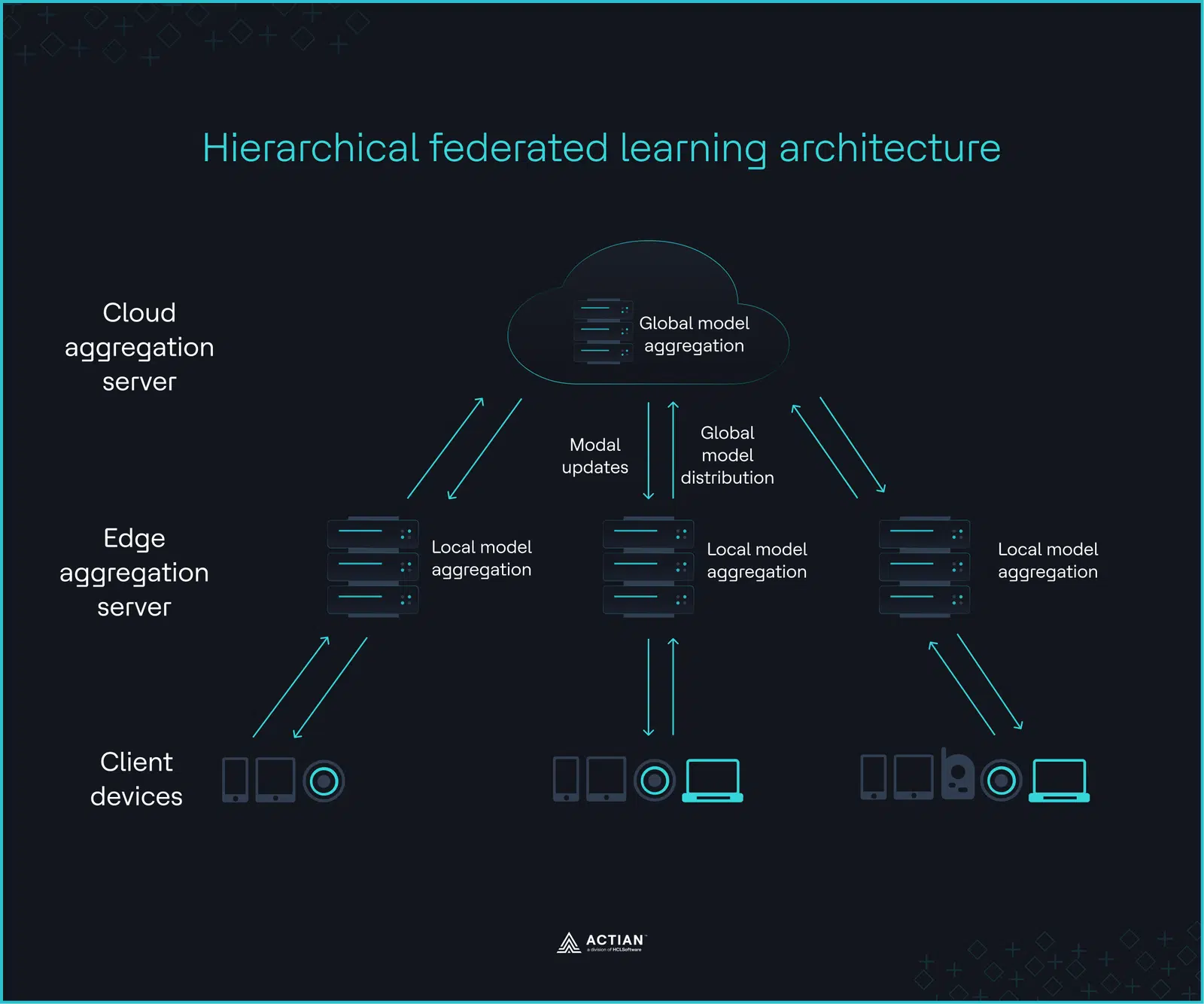
Sectores como la sanidad y los servicios financieros, en los que los datos sin procesar están vinculados a su origen por restricciones de privacidad, requisitos normativos y limitaciones de ancho de banda, constituyen casos de uso ideales para la HFL. Las normas sobre soberanía de datos y las tensiones geopolíticas añaden otra capa a esta restricción, limitando dónde y cómo fluyen los datos a nivel de infraestructura.
Un estudio realizado por BARC reveló que el 19 % de las empresas tiene previsto aumentar sus inversiones en infraestructuras locales, impulsadas por esta necesidad de soberanía de datos. HFL permite que un modelo compartido mejore en todos los nodos distribuidos sin que los datos subyacentes crucen nunca una frontera jurisdiccional.
Un reciente entrenamiento experimental de HFL en el ámbito sanitario alcanzó una precisión del 94,23 % en un conjunto de datos modificado del Instituto Nacional de Estándares y Tecnología, al tiempo que los datos se mantuvieron en los dispositivos de los clientes. Solo la información agregada relevante llega a la nube, con el fin de preservar la privacidad y reducir los riesgos de fuga de datos.
En el ámbito sanitario, los dispositivos portátiles (capa inferior) transmiten datos sin procesar al servidor periférico local del hospital (capa intermedia), que agrupa los datos procedentes de múltiples dispositivos portátiles y los envía a un centro de investigación regional (capa superior) para su agrupación final, sin revelar los datos de los pacientes.
HFL es el patrón más complejo de implementar. El soporte de herramientas sigue siendo fragmentado y, a diferencia de otros patrones analizados, actualmente carece de soporte nativo dentro del ecosistema de Actian. Los equipos deben sopesar esta carga de implementación antes de comprometerse con esta arquitectura.
La arquitectura HFL presenta tres variantes en función de la capa que coordina las decisiones relativas a los datos.
1. Aprendizaje federado jerárquico orquestado en la nube
El servidor central en la nube coordina el proceso de entrenamiento, las comunicaciones entre el cliente y el perímetro, los horarios de sincronización y la topología general, sin que sea necesario realizar rondas de agregación adicionales desde los servidores perimetrales.
El HFL orquestado en la nube resulta adecuado para las instituciones financieras, donde una conectividad fiable ocasional puede mantener el ciclo de coordinación. En una implementación para la detección de fraudes, varias entidades bancarias podrían entrenar modelos utilizando datos de transacciones y enviar actualizaciones a la nube, que se encarga de agregar, validar y redistribuir el modelo mejorado de vuelta a los bancos.
2. Aprendizaje federado jerárquico orquestado en el borde
Los servidores periféricos gestionan de forma autónoma las asignaciones de los clientes locales, agregando las actualizaciones de estos para generar un modelo mejorado a nivel local sin necesidad de intercambios de datos con la nube. Los sistemas en la nube solo intervienen periódicamente para el reentrenamiento masivo de los modelos. Entornos como los parques eólicos marinos, donde la conectividad inestable es la norma, son los que más se benefician de esta variante. Las turbinas envían las actualizaciones del modelo a un servidor periférico local, que se encarga de la agregación y de la mejora independiente del modelo.
3. Agregación entre pares
Esta variante se basa en un modelo de tipo «gossip» sin un coordinador central. Los clientes intercambian los pesos de sus modelos con otros nodos, lo que reduce los conflictos de gradientes en entornos con datos heterogéneos.
Mientras que el patrón HFL básico reduce los costes de entrada en la nube mediante actualizaciones agregadas, la agregación entre pares mantiene tanto el entrenamiento como la agregación dentro de los nodos participantes. En entornos distribuidos como las ciudades inteligentes, los sensores de tráfico intercambian actualizaciones de detección de anomalías directamente con los dispositivos vecinos hasta que, de forma orgánica, convergen en un modelo mejorado en toda la red.
Las tres variantes difieren en sus requisitos funcionales, tal y como se destaca en la tabla siguiente.
| Característica | Orquestado en la nube | Orquestado en el borde | Agregación entre pares |
| Modelo de orquestación | Cloud coordina toda la agregación y la distribución de modelos | El servidor periférico realiza la agregación de datos a nivel local y se sincroniza periódicamente con la nube | No hay un coordinador; las actualizaciones se propagan entre los clientes hasta que se alcanza la convergencia |
| Nivel de privacidad | Medium; la nube controla las actualizaciones del modelo | Alto; los datos sin procesar permanecen en los servidores periféricos locales | Alto; no hay un punto central que supervise las actualizaciones agregadas |
| Requisitos de ancho de banda | Alta; todas las actualizaciones se envían a la nube | Medio; solo las actualizaciones agregadas llegan a la nube | Bajo; las actualizaciones solo se transmiten entre pares vecinos |
| Tolerancia a la desconexión | Bajo; la desconexión de las nubes interrumpe la coordinación | Alto; el servidor periférico funciona de forma independiente durante los cortes de suministro | Media; las particiones de red tienen una convergencia lenta |
La infraestructura por capas de HFL permite el entrenamiento de modelos a gran escala mediante la distribución del cálculo y la comunicación entre múltiples nodos de la jerarquía. El reto que plantea este diseño de varios niveles radica en gestionar la sobrecarga de comunicación, los modelos globales obsoletos y las reconfiguraciones de los nodos.
En HFL, el coste de la comunicación es directamente proporcional al tamaño de la actualización del modelo. Las técnicas de compresión de gradientes, como la dispersión aleatoria y el redondeo estocástico, reducen el volumen de datos de actualización hasta en un 98 % antes de la transmisión.
El ciclo de actualización asíncrono de HFL, en el que el modelo global incorpora las actualizaciones de los clientes a medida que llegan, también aumenta la probabilidad de que los parámetros del modelo queden obsoletos. La agregación ponderada limita la influencia de las actualizaciones obsoletas, evitando que los dispositivos más lentos deterioren el modelo global.
Los cambios en la topología plantean un reto adicional. Los clientes se reasignan a diferentes servidores periféricos, las funciones cambian entre los nodos de cliente y los de agregación, y se incorporan nuevos dispositivos en pleno proceso de entrenamiento. Cada reconfiguración retrasa la convergencia y reduce la precisión si los nuevos servidores periféricos carecen de un historial de entrenamiento previo.
Patrón 4: Inferencia desconectada de «almacenamiento y reenvío»
En entornos sin conexión, los periodos de conectividad intermitente pueden prolongarse durante horas o días. La arquitectura de almacenamiento y reenvío tiene en cuenta esta realidad, ya que permite el procesamiento y el almacenamiento de datos a gran escala durante los periodos de inactividad, y reenvía los resúmenes a la nube una vez que el sistema se vuelve a conectar.
En entornos de automatización industrial, como las operaciones petrolíferas y gasísticas remotas y los buques que navegan a kilómetros de distancia de las torres de telefonía móvil, esta arquitectura resuelve el problema fundamental de mantener la continuidad de los datos a pesar de las interrupciones de la red.
La inferencia no espera a la nube
La implementación de «almacenamiento y reenvío» sigue un enfoque híbrido. El entrenamiento comienza en la nube, pero la ejecución se traslada al borde tras la implementación del modelo. Cuando se interrumpe la conectividad, la toma de decisiones, los bucles de control y la activación de alarmas continúan a nivel local sin interrupción, y el sistema almacena en búfer los resultados, provistos de marca de tiempo, en una base de datos local en el borde hasta que se restablezca la sincronización.
Una vez restablecida la red, la pasarela periférica transfiere todos los eventos almacenados en el búfer a una infraestructura central en la nube, proporcionando los datos necesarios para implementar modelos actualizados y optimizar los flujos de trabajo de IA.
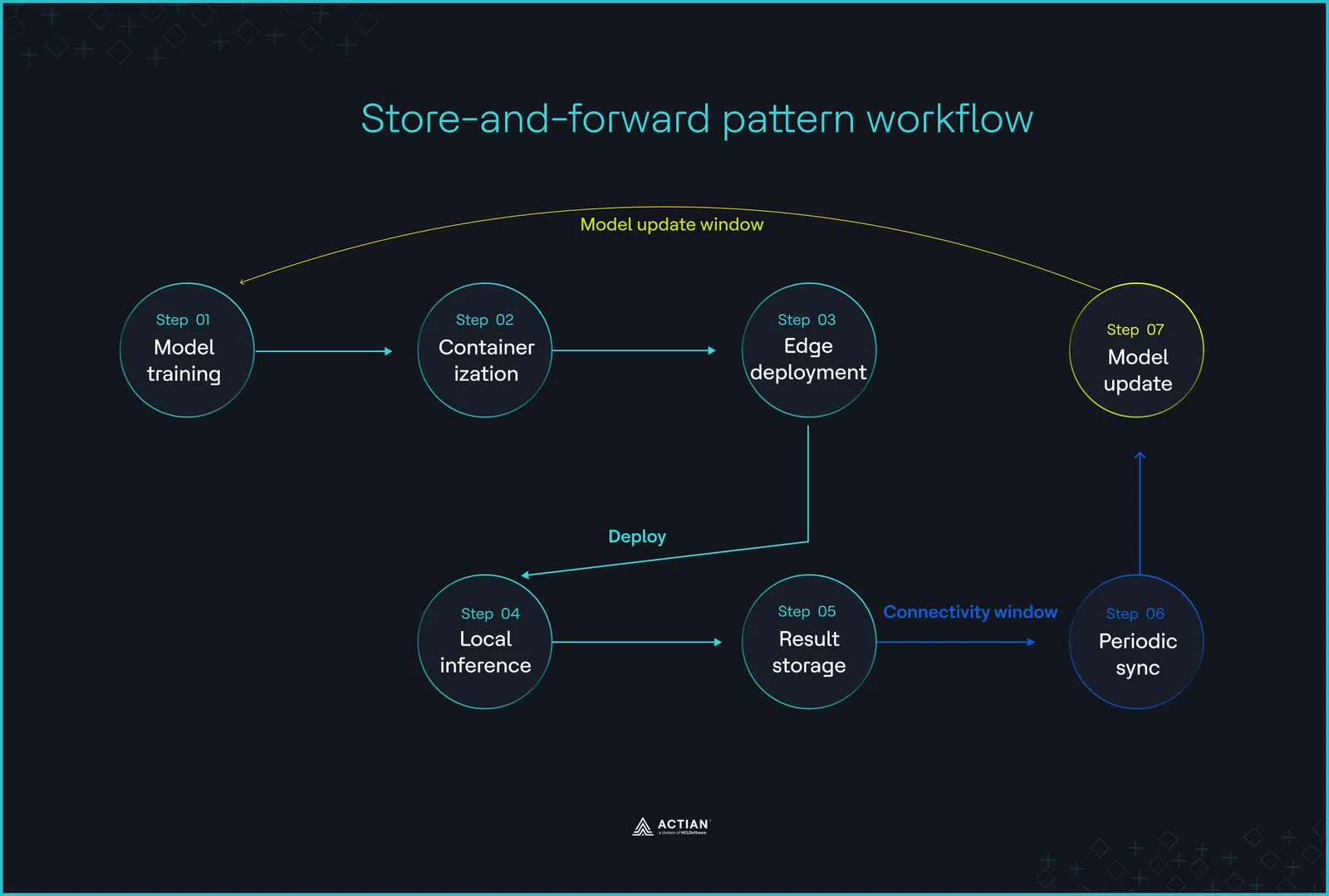
La arquitectura de almacenamiento y reenvío crea un bucle de retroalimentación que evita la pérdida de datos durante la desconexión. En las plantas de fabricación, los sistemas SCADA siguen recopilando datos de los PLC, las unidades terminales remotas (RTU) y las pasarelas periféricas hasta que se restablece la conexión.
Cuando los datos por fin se transfieren
La parte «delante» de esta arquitectura se basa en protocolos de comunicación ligeros, como el Protocolo de transporte de telemetría con colas de mensajes (MQTT), diseñado para redes inestables y entornos con ancho de banda limitado.
El modelo de publicación-suscripción de MQTT canaliza las actualizaciones en cola desde las pasarelas periféricas hacia la nube a través de servidores intermediarios como Mosquitto. Los emisores (sensores) envían mensajes a un tema (temperatura), y los suscriptores (servidores en la nube) reciben mensajes de los temas en los que se han registrado. Los mensajes se reproducen exactamente en el orden cronológico en que se recibieron.
El fragmento de código de Python que se muestra a continuación ilustra una implementación básica utilizando la biblioteca Paho MQTT. Utiliza la calidad de servicio (QoS) 1, una sesión persistente que permite a Mosquitto poner los mensajes en cola mientras el suscriptor está desconectado.
# pip install paho-mqtt
import paho.mqtt.publish as publish
import sys
if len(sys.argv) < 3:
print("Usage: publisher.py <topic> <message>")
sys.exit(1)
# Production code will add retry logic, local queue persistence, and message deduplication
topic = sys.argv[1]
message = sys.argv[2]
publish.single(topic, message, hostname="localhost", qos=1)
Para iniciar la transferencia de datos tras la reconexión, el script siguiente crea una sesión persistente utilizando clean_session=False y loop_forever().
import paho.mqtt.client as mqtt
import sys
if len(sys.argv) < 2:
print("Usage: subscriber.py <topic>")
sys.exit(1)
topic = sys.argv[1]
client_id = "test-client"
def on_connect(client, userdata, flags, rc):
print(f"Connected with result code {rc}")
client.subscribe(topic, qos=1)
def on_message(client, userdata, msg):
print(f"{msg.topic}: {msg.payload.decode()}")
client = mqtt.Client(client_id=client_id, clean_session=False)
client.on_connect = on_connect
client.on_message = on_message
client.connect("localhost", 1883, 60)
client.loop_forever()
La arquitectura de almacenamiento y reenvío puede provocar inconsistencias en la replicación de datos durante la sincronización de las pasarelas. El sistema requiere una política de arbitraje, como la de «la última escritura prevalece», que aplica los cambios basándose en la marca de tiempo de cada actualización. Cuando las marcas de tiempo son idénticas, estructuras de datos como los tipos de datos replicados sin conflictos (CRDT) fusionan las copias para lograr un estado final coherente en todas las pasarelas periféricas.
La sincronización delta mejora aún más los resultados de los CRDT. Mientras que la replicación completa del conjunto de datos se activa con cada cambio en los registros, la sincronización delta resuelve los conflictos a nivel de propiedad, abordando únicamente los campos modificados.
Patrón 5: La red (estructura distribuida de extremo a extremo)
Este modelo de despliegue de redes aborda la falta de tolerancia a fallos y de procesamiento distribuido que caracteriza a las operaciones con múltiples emplazamientos desconectados, como las redes logísticas y las redes eléctricas inteligentes.
La coordinación de dispositivos periféricos en múltiples ubicaciones a través de un sistema en la nube se ve rápidamente limitada fuera del alcance de la red. Por eso, la arquitectura de red sigue un patrón de comunicación este-oeste, lo que permite a los nodos periféricos intercambiar datos directamente con otros nodos sin necesidad de una coordinación central.
La comunicación en malla gestiona la inteligencia distribuida
El modelo de despliegue de la red adopta un diseño no jerárquico, conectando múltiples dispositivos IoT a través de una red en malla para mejorar el tiempo de actividad del sistema durante las interrupciones del servicio. Cada nodo se comunica dinámicamente con sus vecinos, formando una red bidireccional que transmite datos a entornos remotos a través de rutas de múltiples saltos.
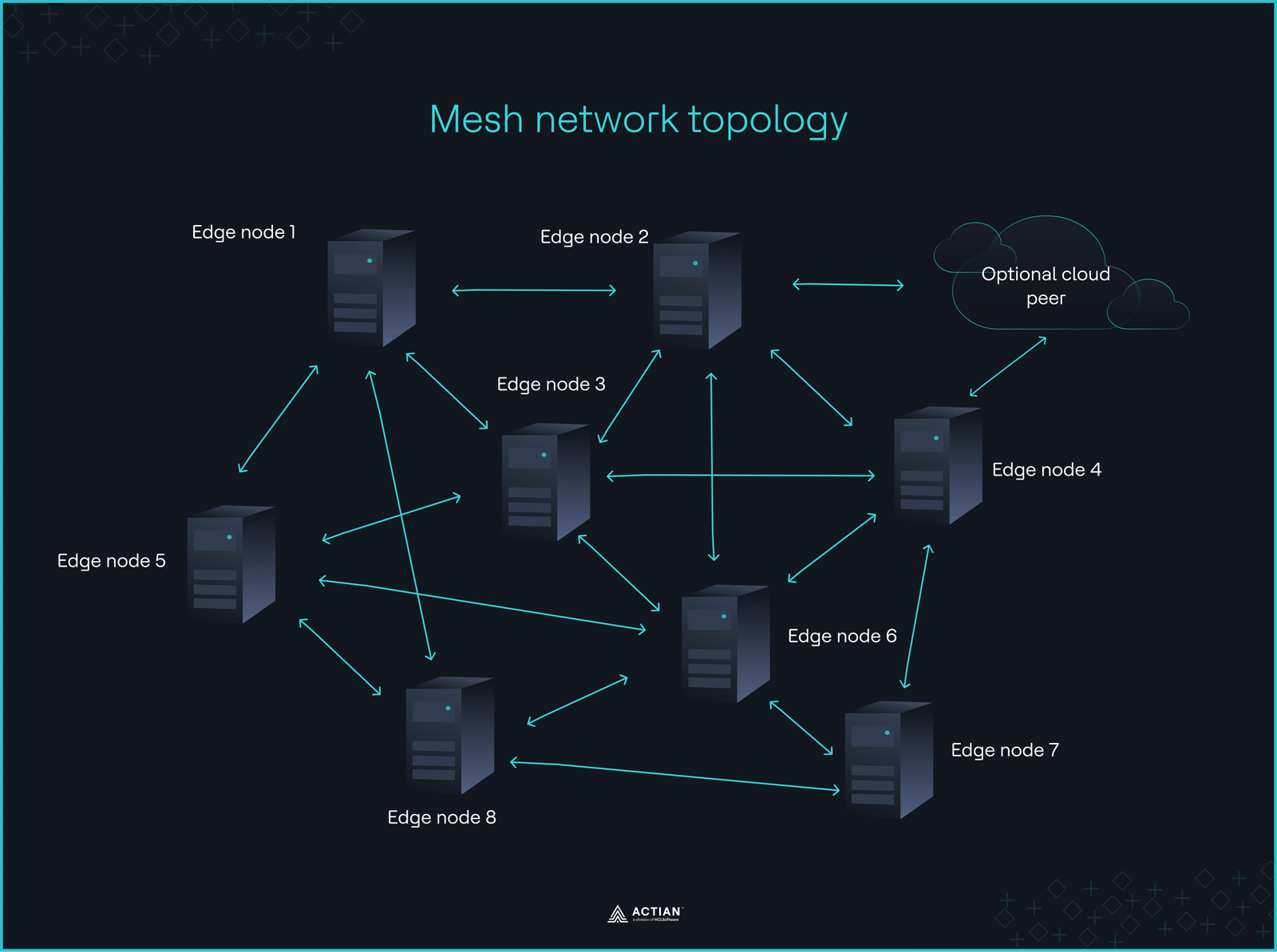
La nube solo se conecta como un nodo más para la sincronización opcional, pero el procesamiento principal sigue realizándose en la red, sin control centralizado.
Las redes inteligentes son ideales para esta arquitectura, en la que la teleprotección exige una latencia de entre 10 y 20 ms. Una red de subestaciones de transmisión supervisa continuamente el flujo de electricidad y los patrones de consumo en tiempo real para detectar desequilibrios antes de que se agraven. Esa visibilidad en tiempo real permite la redistribución dinámica de la carga y la gestión autónoma de las microrredes.
Los vehículos aéreos no tripulados (UAV) militares constituyen otro caso de uso. Cuando el GPS falla en entornos DDIL, los UAV se transmiten datos de ISR entre sí a través de redes en malla. El enrutamiento adaptativo de interferencias garantiza un flujo de datos fiable, mientras que la transmisión en línea de visión reduce la latencia.
Este modelo de implementación está optimizado para la redundancia de red. El protocolo Gossip y los algoritmos de consenso distribuido, como Raft, eliminan los puntos únicos de fallo. Cuando un nodo pierde la conexión, la red sigue funcionando y redirige los datos a través de otros nodos.
El protocolo Gossip permite la detección de pares en tiempo real mediante intercambios de información continuos y ligeros. Cada nodo dispone en todo momento de una visión actualizada de su red local. Raft sigue un enfoque basado en un líder, en el que un nodo líder elegido se encarga de todas las escrituras, y la replicación del registro garantiza que los nodos seguidores mantengan un estado compartido. Las bases de datos periféricas replican los datos entre varios nodos para mejorar la coherencia.
Considerar Gossip y Raft como opciones que compiten entre sí pasa por alto lo que realmente importa. Lo importante es comprender el lugar que ocupa cada uno en el teorema CAP y las compensaciones que introducen en una red distribuida.
La disyuntiva entre la coherencia y la disponibilidad
Cuando las particiones de red dividen la malla, Raft garantiza una fuerte consistencia de los datos, mientras que Gossip proporciona una solución alternativa de disponibilidad y consistencia eventual cuando se combina con enfoques como los CRDT.
En la computación periférica, donde la conexión es limitada y los nodos son numerosos, la tolerancia a las particiones es imprescindible. Los sistemas de IA periférica deben decidir si dar prioridad a la consistencia o a la disponibilidad a la hora de implementar la arquitectura de red.
La disponibilidad suele ser óptima, ya que los nodos periféricos siguen funcionando de forma independiente tras la desconexión. Los diseños centrados en la consistencia, como Raft, corren el riesgo de que se produzcan suspensiones de escritura y lecturas obsoletas durante las particiones de red.
| Característica | Balsa | Chismes |
| Arquitectura | Elección de líder y replicación de registros | Entre pares |
| Latencia | Moderado; requiere que al menos un quórum de nodos de la red esté disponible | Baja; los mensajes se transmiten rápidamente, pero las rondas de propagación pueden ralentizar la velocidad |
| Garantías de calidad | Consistencia fuerte | Consistencia eventual |
| Tolerancia a fallos | Moderada; podría no sobrevivir a una partición | Alto; restaura las particiones más rápido |
Speed and data delivery trade-offs are another critical constraint of the network architecture. Mesh networking adds latency with each hop as the node count increases. If your system needs data back in <50ms or your latency requirements can tolerate >100ms, this trade-off should shape your design decision.
Elegir el modelo adecuado de implementación de IA en el borde
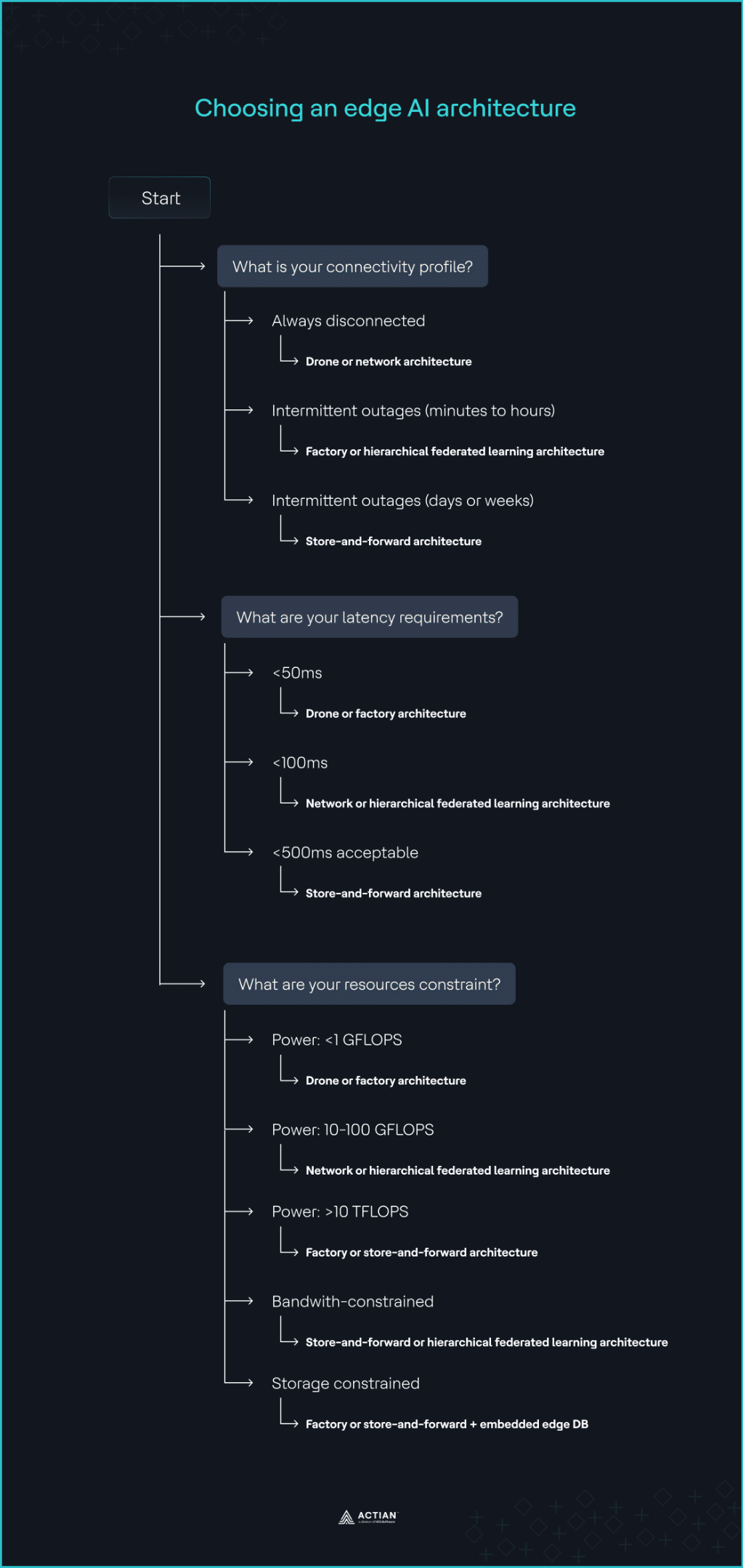
No existe un patrón específico «correcto» para la implementación de IA en el borde en entornos sin conexión. Una implementación arquitectónica sólida comienza por comprender claramente las limitaciones, los objetivos y las características específicas de la aplicación de destino. Esto implica tener en cuenta todo el ciclo de vida de la carga de trabajo, incluyendo el perfil de conectividad, los recursos de computación disponibles y los requisitos de latencia.
1. Evaluar la estabilidad de la red
La estabilidad de la red es el factor clave de cualquier estrategia de implementación de IA en el borde. Determina cuánta resiliencia debe incorporarse en los nodos periféricos en función de la duración prevista de la desconexión.
- Si el sistema está siempre desconectado: utilice arquitecturas de tipo «drone» o de red, ya que están diseñadas para funcionar completamente sin conexión, independientemente del estado de la conectividad.
- Si la interrupción dura solo unos minutos u horas: utilice la arquitectura de fábrica o HFL para continuar con la agregación de datos y la inferencia sin interrupciones. El sistema sigue funcionando durante la interrupción, ya que todas las dependencias necesarias ya se encuentran dentro del perímetro operativo.
- Si la conectividad intermitente se prolonga durante días o semanas: utilice la arquitectura de almacenamiento y reenvío para almacenar temporalmente los resultados de la inferencia y los datos operativos a nivel local hasta que vuelva a estar disponible la ventana de conectividad programada.
2. Evaluar los requisitos de latencia
Defina la latencia máxima aceptable para su aplicación concreta teniendo en cuenta los saltos de red, la disponibilidad de los nodos y la proximidad geográfica de los nodos periféricos. Los umbrales que se indican a continuación reflejan patrones de implementación habituales. Compruébelos en función de las condiciones específicas de su hardware y su red.
- If the system requires <50ms latency: Use the drone deployment pattern. Its single-node architecture keeps inference directly on sensors, cameras, or gateways, enabling near-real-time responses. Factory architecture also minimizes latency by running on edge servers within the same facility or on the factory floor.
- If the system requires <100ms latency: Use the network or HFL architecture to distribute model improvement workloads across multiple nodes.
- If <500ms latency is acceptable: Use store-and-forward architecture for non-critical IoT data that requires batch processing or long-term analytics. It batch-offloads data-intensive tasks to the cloud.
3. Evaluar las limitaciones de recursos
Las aplicaciones de IA en el borde difieren en cuanto a potencia de procesamiento, almacenamiento y consumo de ancho de banda, lo que repercute en la velocidad de inferencia, la agregación de datos y el análisis en tiempo real. Evalúa cada límite de recursos por separado:
- Power constraint: For compute power <1 GFLOPS, common in microcontrollers used for sensor inference, the drone architecture is most suitable. It runs on constrained IoT devices using lightweight, inference-only models. At 10–100 GFLOPS, common in edge gateways, HFL and network architectures become more effective as they handle data aggregation needs well at this level. For edge GPU clusters that scale to >10 TFLOPS, factory and store-and-forward architecture support clustered inference pipelines, since they run on-premises.
- Limitación de ancho de banda: utilice una arquitectura de almacenamiento y reenvío o HFL para almacenar y procesar datos sin procesar y de gran volumen en el perímetro, reenviando a la nube únicamente actualizaciones resumidas cuando sea necesario.
- Restricción de almacenamiento de datos: utilice arquitecturas de tipo «factory» o «store-and-forward» combinadas con bases de datos integradas para almacenar datos de series temporales de forma local y escalar verticalmente dentro de las instalaciones. Las bases de datos como Actian Zen están optimizadas para casos de uso de IA en el borde y también pueden sincronizarse con la nube una vez que se restablezca la conectividad.
4. Plantéate un enfoque híbrido
Los sistemas industriales suelen combinar las ventajas de múltiples arquitecturas en un sistema coordinado que ofrece resiliencia y flexibilidad. Las operaciones mineras de Rio Tinto ilustran cómo es una implementación híbrida a gran escala.
En la mina de mineral de hierro de Greater Nammuldi, más de 50 camiones autónomos operan en rutas predefinidas, utilizando sensores integrados para detectar obstáculos, lo que constituye un ejemplo de la arquitectura de drones. En 17 emplazamientos de Australia Occidental, estos camiones transmiten datos operativos al Centro de Operaciones de Rio Tinto en Perth, lo que refleja la arquitectura de red. Por último, un sistema ferroviario autónomo transporta el mineral extraído, sincronizándose con el Centro de Operaciones al llegar a las instalaciones portuarias. Esto se ajusta a la arquitectura de almacenamiento y reenvío.
Rio Tinto demuestra que los modelos de implementación no son mutuamente excluyentes. Si tu caso de uso requiere varias arquitecturas, plantéate ejecutarlas en la capa del sistema donde mejor se adapten, en lugar de imponer una única arquitectura en toda la operación.
La siguiente tabla relaciona distintos escenarios de implementación con su patrón óptimo de implementación de IA periférica sin conexión, con el fin de orientar su decisión.
| Escenarios de implementación | Patrón recomendado | Justificación |
| Drones de inspección autónomos sobre yacimientos petrolíferos o parques eólicos marinos | Drone (autónomo de un solo nodo) | Un entorno de ejecución de inferencias autónomo con almacenamiento local integrado elimina la necesidad de realizar cálculos distribuidos para adaptarse a las limitaciones del hardware |
| Líneas de montaje de automóviles que utilizan modelos de detección de defectos | Factory (IA periférica multinodo) | La dependencia de la nube supone un riesgo demasiado elevado para los requisitos de disponibilidad, por lo que los clústeres periféricos se ejecutan dentro de las instalaciones |
| Redes hospitalarias en las que, en virtud de la HIPAA, los datos de los pacientes no pueden salir de cada centro | Aprendizaje federado jerárquico | Los modelos se entrenan localmente y solo se envían a la nube las actualizaciones de los pesos, por lo que los datos sin procesar permanecen en el sitio local, en cumplimiento de los principios de soberanía de datos y privacidad. |
| Los buques de carga en el mar sincronizan los datos operativos en el puerto | Almacenamiento y reenvío | Un búfer local garantiza que no se pierda ningún resultado de inferencia ni ningún evento operativo durante las interrupciones de conectividad, que pueden durar varios días |
| Gestión inteligente del tráfico urbano en cruces distribuidos sin depender de un servidor central | Red (estructura distribuida de extremo a extremo) | Los nodos se comunican entre sí mediante consenso, por lo que la pérdida de un nodo reduce la capacidad sin afectar al funcionamiento general de la red |
Lo esencial
Las empresas que operan en entornos remotos, subterráneos, marítimos y geográficamente dispersos necesitan arquitecturas nativas de perímetro que recopilen información en tiempo real y mantengan en funcionamiento los activos críticos sin depender de la nube.
Los modelos de implementación analizados dan prioridad a lo que más importa en entornos desconectados: la inferencia local, la ausencia de latencia por centralización, unos menores costes de comunicación y la autonomía del sistema.
Antes de decidirse por un patrón, compruebe tres aspectos en su propio entorno: cuánto tiempo puede soportar su sistema una interrupción de la red antes de que la pérdida de datos tenga un impacto operativo significativo; si su hardware periférico puede soportar las exigencias de computación de la arquitectura elegida sin que se vea afectada la calidad de la inferencia; y si su equipo cuenta con las herramientas necesarias para gestionar el ciclo de vida del modelo en el borde sin depender de la nube. Compare sus limitaciones con el marco de decisión anterior.
Es posible que la respuesta correcta no sea un único modelo. Solo se deben incorporar enfoques híbridos cuando las ventajas en materia de resiliencia justifiquen la complejidad operativa.
Cada modelo depende de una infraestructura de datos capaz de funcionar, almacenar y sincronizarse íntegramente en el borde. Para los equipos que necesitan ir más allá del almacenamiento estructurado y realizar búsquedas semánticas en sus datos locales sin exportar las representaciones vectoriales a un servidor en la nube, Actian VectorAI DB está optimizada para este caso de uso. Apúntate a la lista de espera para obtener acceso anticipado.
Únete a la comunidad de Actian en Discord para debatir sobre patrones de arquitectura de IA en el borde con ingenieros que realizan implementaciones en entornos desconectados.

Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)