Décomposer la lignée des données : Typologies et granularité





En tant que concept, le lignage des données semble universel : quel que soit le secteur d'activité, toute partie prenante d'une organisation axée sur les données a besoin de connaître l'origine (lignage en amont) et la destination (lignage en aval) des données qu'elle manipule ou qu'elle interprète. Ce besoin a d'importantes motivations sous-jacentes.
Pour un catalogue de données la capacité à gérer le Data Lineage est cruciale pour son offre. Mais comme souvent, derrière une question simple et universelle se cache un monde de complexité difficile à appréhender. Cette complexité est en partie liée à l'hétérogénéité des réponses qui varient d'un interlocuteur à l'autre dans l'entreprise.
Dans cet article, nous expliquons notre approche de la décomposition de la lignée de données en fonction de la nature de l'information recherchée et de sa granularité.
La typologie du lignage des données : à la recherche de l'origine des données
Il existe de nombreuses réponses possibles quant à l'origine d'une donnée. Certains voudront connaître la formule ou la sémantique exacte des données. D'autres voudront savoir de quel(s) système(s), application(s), machine(s) ou usine elles proviennent. Certains s'intéresseront aux processus commerciaux ou opérationnels qui ont produit les données. D'autres s'intéresseront à l'ensemble de la chaîne de traitement technique en amont et en aval. Difficile de s'y retrouver dans ce dédale de considérations !
Une approche par couches
Pour structurer l'information lignagère, nous proposons de nous inspirer de ce qui se pratique dans le domaine de la géocartographie en distinguant plusieurs couches superposables. géocartographie en distinguant plusieurs couches superposables. On peut en en identifier trois :
- La couche physiqueLa couche physique, qui comprend les objets du système d'information - applications, systèmes, bases de données, ensembles de données, programmes d'intégration ou de transformation, etc.
- La couche métierqui contient les éléments organisationnels - domaines, processus ou activités commerciales, entités, gestionnaires, contrôles, comités, etc.
- La couche sémantiquequi traite de la signification des données - formules de calcul, définitions, ontologies, etc.
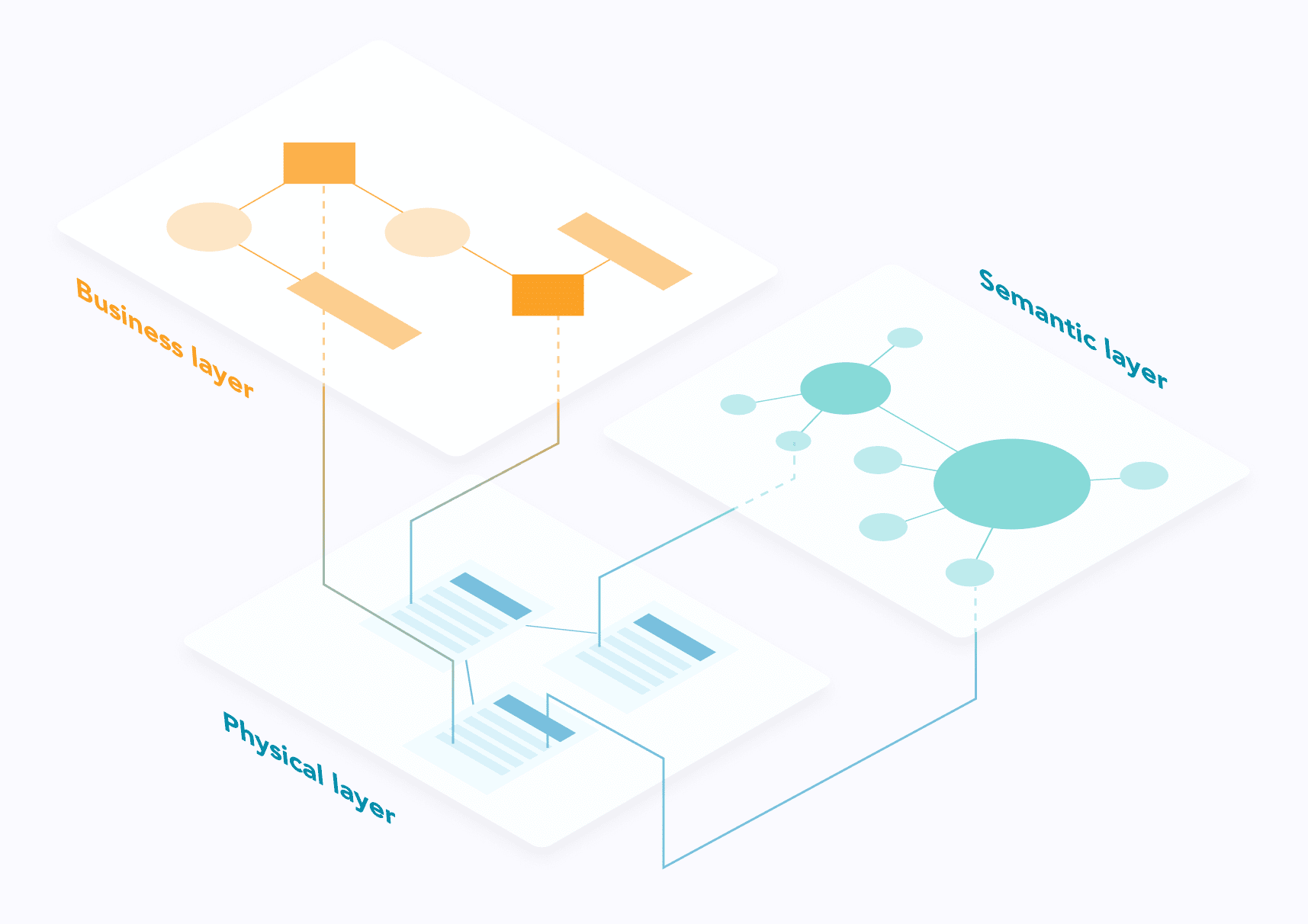
La couche physique en point de mire
La couche physique est le canevas de base sur lequel toutes les autres couches peuvent être ancrées. Cette approche est à nouveau similaire à ce qui se pratique en géocartographie : au-dessus de la carte physique, il est possible de superposer d'autres couches contenant des informations spécifiques.
La couche physique représente la dimension technique de la lignée ; elle est matérialisée par des artefacts techniques tangibles - bases de données, systèmes de fichiers, intergiciels d'intégration, outils bi, scripts et programmes, etc. En théorie, la structure de la lignée physique peut être extraite de ces systèmes, puis largement automatisée, ce qui n'est généralement pas le cas pour les autres couches.
Le point suivant semble fondamental : pour que cette approche ascendante fonctionne, il est nécessaire que la lignée physique soit complète.
Cela ne signifie pas que la lignée de tous les objets physiques doit être disponible, mais pour les objets qui ont une lignée, celle-ci doit être complète. Il y a deux raisons à cela. La première est qu'un lignage partiel (et donc faux) risque d'induire en erreur la personne qui le consulte, mettant en péril l'adoption du catalogue. Deuxièmement, la couche physique sert de point d'ancrage aux autres couches, ce qui signifie que toute lacune dans sa lignée sera propagée.
Outre cette représentation couche par couche, abordons un autre aspect fondamental du lignage : sa granularité.
Granularité dans la lignée des données
En ce qui concerne la granularité de la lignée, nous identifions 4 niveaux distincts : les valeurs, les champs (ou colonnes), les jeux de données et les applications.
Les valeurs peuvent être abordées rapidement. Leur but est de suivre toutes les étapes du calcul d'une donnée particulière (nous faisons référence à des valeurs spécifiques, et non à la définition d'une donnée spécifique). Pour les applications de tarification au modèle, par exemple, l'historique des prix doit inclure toutes les données brutes (horodatage, fournisseur, valeur), les valeurs dérivées de ces données brutes ainsi que les versions de tous les algorithmes utilisés dans le calcul.
Les exigences réglementaires existent dans de nombreux domaines (banque, finance, assurance, santé, pharmacie, IOT, etc.), mais généralement de manière très localisée. Elles sont clairement hors de portée d'un catalogue de données, dans lequel il est difficile d'imaginer gérer chaque valeur de données ! Répondre à ces exigences nécessite soit un progiciel spécialisé, soit un développement spécifique.
Les trois autres niveaux concernent les métadonnées et relèvent clairement d'un catalogue de données. Détaillons-les rapidement.
Le niveau niveau du champ est le niveau le plus détaillé. Il consiste à retracer toutes les étapes (au niveau physique, métier ou sémantique) d'une information dans un jeu de données (table ou fichier), un rapport, un tableau de bord, etc. qui permettent de renseigner le champ en question.
Au niveau du jeu de données Au niveau du jeu de données, le lineage n'est plus défini pour chaque champ mais au niveau du conteneur de champ, qui peut être une table dans une base de données, un fichier dans un data lake, une API, etc. À ce niveau, les étapes qui permettent de peupler le jeu de données dans son ensemble sont représentées, typiquement à partir d'autres jeux de données (on trouve également à ce niveau d'autres artefacts tels que des rapports, des tableaux de bord, des modèles ML ou même des algorithmes).
Enfin, le niveau de l'application permet de documenter la lignée de manière macroscopique, en se concentrant sur les éléments logiques de haut niveau du système d'information. Le terme "application" est utilisé ici de manière générique pour désigner un regroupement fonctionnel de plusieurs jeux de données.
Il est bien sûr possible d'imaginer d'autres niveaux au-delà de ces trois-là (en regroupant les applications en domaines d'activité, par exemple), mais l'augmentation de la complexité relève davantage de la cartographie des flux que de la lignée.
Enfin, il est important de garder à l'esprit que chaque niveau est imbriqué dans le niveau supérieur. Cela signifie que la lignée du niveau supérieur peut être élaborée à partir de la lignée du niveau inférieur (si je connais la lignée de tous les champs d'un jeu de données, je peux en déduire l'âge de la lignée de ce jeu de données).
Nous espérons que cette décomposition du lignage de données vous aidera à mieux le comprendre pour votre organisation. Dans un prochain article, nous partagerons notre approche afin que chaque entreprise puisse tirer le maximum de valeur du lignage grâce à notre typologie/granularité/matrice d'entreprise.
Restez connecté
Des informations exploitables à votre disposition.
(par exemple, sales@..., support)