Cuándo elegir una base de datos vectorial local o en la nube




Resumen
- El aumento de las leyes sobre residencia de datos y la aplicación del RGPD están obligando a las empresas a reconsiderar la infraestructura de IA local.
- Las cargas de trabajo de IA en el borde exigen capacidad sin conexión y una latencia inferior a 100 ms que las implementaciones en la nube no siempre pueden satisfacer.
- A gran escala, los costes de las bases de datos vectoriales en la nube basadas en el uso pueden superar el coste total de propiedad previsible de las instalaciones locales.
- Las estrategias híbridas equilibran la agilidad de la nube para el desarrollo con el control local para el cumplimiento normativo y la producción.
Durante la mayor parte de la última década, el debate entre las instalaciones locales y la nube parecía zanjado. La computación en la nube era más barata, más rápida y más fácil de adoptar. Las empresas trasladaron sus cargas de trabajo de la infraestructura local a los servicios de nube pública, confiando en los principales proveedores de nube para gestionar la escalabilidad, el mantenimiento y la seguridad.
En 2026, esa suposición se está rompiendo y están apareciendo grietas en las revisiones legales, los proyectos financieros y las negociaciones de SLA. Las empresas se enfrentan a una presión cada vez mayor por normativas sobre residencia de datos, una aplicación más estricta y un escrutinio de los modelos de seguridad en la nube. Las restricciones de cumplimiento, los requisitos de seguridad de los datos, la previsibilidad de los costes y la latencia están obligando a los equipos a reconsiderar las soluciones locales, la computación en la nube privada y la infraestructura de nube híbrida.
Al mismo tiempo, la IA se está acercando al lugar donde se generan los datos. Las plantas de fabricación, las tiendas minoristas y los entornos sanitarios requieren cada vez más capacidad offline y una latencia inferior a 100 ms. Ese cambio ayuda a explicar por qué Oracle lanzó AI Database 26ai para su implementación local y por qué Google está impulsando Gemini en Distributed Cloud para entornos aislados. Este cambio indica que la IA empresarial a gran escala ya no encaja perfectamente en los entornos de nube.
En este artículo, analizaremos por qué está resurgiendo la infraestructura local, qué ventajas e inconvenientes hay que tener en cuenta y cómo tomar decisiones de implementación justificadas.
¿Qué está impulsando el resurgimiento de las instalaciones locales?
El renovado interés por la infraestructura local no supone una vuelta a los sistemas antiguos. Es una respuesta a los claros cambios que se producirán en la forma de construir y utilizar los sistemas de IA en 2025 y 2026. Para muchas empresas, las bases de datos vectoriales exclusivamente en la nube ya no se ajustan a sus necesidades de cumplimiento normativo, coste y fiabilidad.
Son muchos los factores que impulsan este resurgimiento actual de las instalaciones locales, pero en este artículo analizaremos cuatro causas clave.
Los grandes proveedores ahora admiten la IA local.
Los principales proveedores ya no consideran la IA local como un caso excepcional. El lanzamiento de AI Database 26ai por parte de Oracle y la decisión de Google de ejecutar Gemini en Distributed Cloud muestran un claro cambio en la forma en que se empaqueta y se ofrece la IA empresarial.
Estos productos están diseñados para grandes empresas, no para experimentos en fase inicial ni proyectos de investigación. Esa distinción es importante. Los grandes proveedores no invierten en plataformas de IA locales complejas a menos que exista una demanda fuerte y creciente por parte de los clientes. Estos anuncios confirman que muchas empresas desean ejecutar sistemas de IA dentro de sus propios entornos, cerca de sus datos y bajo su control operativo total. ¿Por qué?
La presión regulatoria es ahora un verdadero obstáculo.
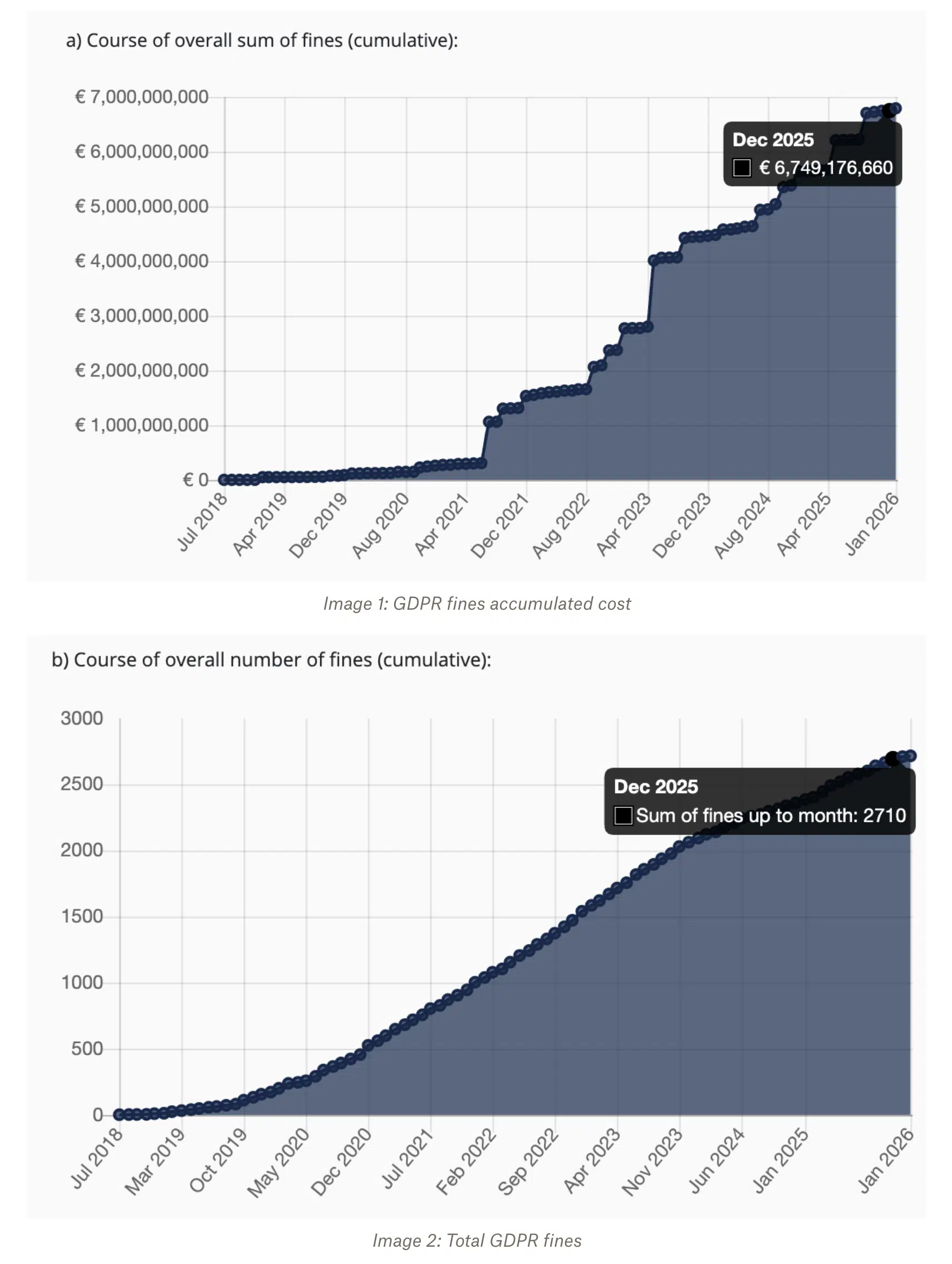
Los equipos solían planificar el riesgo normativo como una posibilidad futura. Ahora es una realidad cotidiana. La aplicación del RGPD alcanzó niveles récord en 2025, y la insuficiencia de la base jurídica para el tratamiento de datos fue la causa de las sanciones más elevadas. Solo ese año, los reguladores impusieron casi 2700 multas por un total de miles de millones de euros.
Desde el punto de vista de la seguridad de los datos, la aplicación del RGPD ha cambiado radicalmente la forma en que las empresas evalúan los servicios en la nube. Aunque los proveedores de servicios en la nube ofrecen herramientas de cumplimiento normativo, los equipos jurídicos se muestran cada vez más recelosos a la hora de confiar en terceros para el almacenamiento y el tratamiento de datos confidenciales.
La HIPAA añade otra capa de complejidad. Por ejemplo, en Florida, los médicos deben conservar los historiales médicos durante cinco años después del último contacto con el paciente, mientras que los hospitales deben conservarlos durante siete años según los requisitos estatales de conservación de registros. Esto hace que el movimiento repetido de datos sea arriesgado y costoso. Los servicios financieros y los contratistas gubernamentales se enfrentan a requisitos similares de soberanía de datos que limitan dónde se pueden almacenar y procesar los datos. En estas situaciones, las implementaciones en la nube añaden revisiones legales, trabajo de auditoría y riesgos continuos. Mantener los datos en las instalaciones suele ser la forma más sencilla de cumplir con estas obligaciones.
La IA periférica requiere un funcionamiento local y sin conexión.
Las cargas de trabajo de IA se implementan cada vez más cerca del lugar donde se crean los datos. Las instalaciones de fabricación pueden operar en entornos aislados o ubicaciones remotas con conectividad limitada. Los sistemas minoristas deben seguir funcionando durante las interrupciones de la red. Las aplicaciones sanitarias suelen requerir una latencia muy baja para el apoyo a la toma de decisiones en tiempo real.
En estos entornos, depender de un servicio remoto en la nube conlleva riesgos. Los retrasos y las interrupciones de la red afectan directamente a la fiabilidad del sistema. Las implementaciones locales y periféricas permiten que la búsqueda vectorial y la inferencia se ejecuten de forma local, sin depender de un acceso constante a la red. Para muchos casos de uso, esta ejecución local no es una optimización, sino un requisito.
En conjunto, estos cambios explican por qué las bases de datos vectoriales locales están ganando terreno de nuevo. El cambio viene impulsado por las realidades prácticas de implementar sistemas de IA de producción bajo restricciones reales en materia de normativa, costes y fiabilidad.
El cálculo del cumplimiento normativo
Para muchas empresas, el cumplimiento normativo es el factor decisivo en el debate entre las instalaciones locales y la nube. Aunque los proveedores de servicios en la nube ofrecen certificaciones de cumplimiento normativo, el verdadero reto no es si una plataforma puede cumplir con la normativa en teoría, sino si puede resistir el escrutinio legal, las auditorías y el control operativo a largo plazo en la práctica. Una vez que las bases de datos vectoriales entran en producción y comienzan a almacenar datos confidenciales o regulados, estas cuestiones se vuelven inevitables.
El RGPD y los límites de las transferencias transfronterizas
La sentencia Schrems II cambió la forma en que se pueden procesar los datos europeos fuera de la UE. El Escudo de Privacidad quedó invalidado, dejando las Cláusulas Contractuales Tipo como el principal mecanismo legal para las transferencias transfronterizas de datos. En sectores altamente regulados, como los servicios financieros y la sanidad, muchos equipos jurídicos consideran que las CCT son insuficientes debido a la incertidumbre en su aplicación y a los continuos retos legales.
En el caso de las bases de datos vectoriales, esto es importante porque las incrustaciones suelen contener datos personales derivados. Incluso si los registros sin procesar están enmascarados o tokenizados, las incrustaciones pueden seguir considerándose datos personales según el RGPD. Si los datos deben permanecer dentro del EEE o dentro de un país específico, las implementaciones en la nube que dependen de una infraestructura global introducen un riesgo legal. En estos casos, la implementación local o dentro de la región se convierte en un requisito más que en una preferencia.
La retención según la HIPAA y el coste real del traslado de datos
La HIPAA no exige explícitamente que los datos permanezcan en las instalaciones, pero sí exige largos períodos de retención y estrictos controles de acceso. Cuando se crean incrustaciones vectoriales a partir de estos datos, estas heredan los mismos requisitos de retención. La gobernanza de datos de la HIPAA debe aplicarse al considerar bases de datos vectoriales locales o en la nube.
El impacto en los costes se hace evidente cuando se incluyen las tarifas de salida. Consideremos un sistema que almacena 100 TB de incrustaciones en un entorno en la nube. A una tarifa de salida habitual de 0,09 dólares por GB, trasladar esos datos fuera de la nube durante un periodo de retención de siete años da como resultado:
100 TB × 0,09 $ por GB × 84 meses = más de 750 000 $ solo en costes de salida.
Esto no incluye los costes de computación, almacenamiento o indexación. Teniendo esto en cuenta, ¿los los almacenes de datos en la nube realmente ayudarán a reducir costes?
Servicios financieros y normas sobre soberanía de datos
Las instituciones financieras se enfrentan a restricciones adicionales más allá del RGPD. Normativas como la GLBA, APRAy los mandatos regionales de soberanía de datos a menudo exigen un control estricto sobre el lugar donde se almacenan y procesan los datos de los clientes. Los reguladores pueden exigir pruebas claras de los límites geográficos, los controles de acceso y la auditabilidad.
Los servicios en la nube pueden satisfacer algunos de estos requisitos, pero a menudo introducen configuraciones complejas, dependencias contractuales y revisiones de cumplimiento continuas. Para muchos bancos y aseguradoras, la implementación local simplifica las auditorías al mantener los datos dentro de una infraestructura controlada que los reguladores ya comprenden.
Restricciones del gobierno y del sector público
Los contratos gubernamentales introducen algunos de los requisitos de infraestructura más estrictos. Normas como FedRAMP a menudo exigen infraestructuras exclusivas de EE. UU., acceso restringido y entornos estrictamente controlados.
En estos casos, los servicios de nube pública suelen estar prohibidos o requieren autorizaciones exhaustivas. La implementación local suele ser la única opción viable para ejecutar bases de datos vectoriales que den soporte a las cargas de trabajo gubernamentales.
Cuando el cumplimiento normativo hace que la nube sea insostenible
Si los equipos jurídicos consideran que las transferencias transfronterizas de datos son inaceptables, las implementaciones en la nube se vuelven rápidamente inviables. Una vez que la residencia de datos es obligatoria, la implementación local ya no es una decisión de compromiso. Es un requisito de cumplimiento.
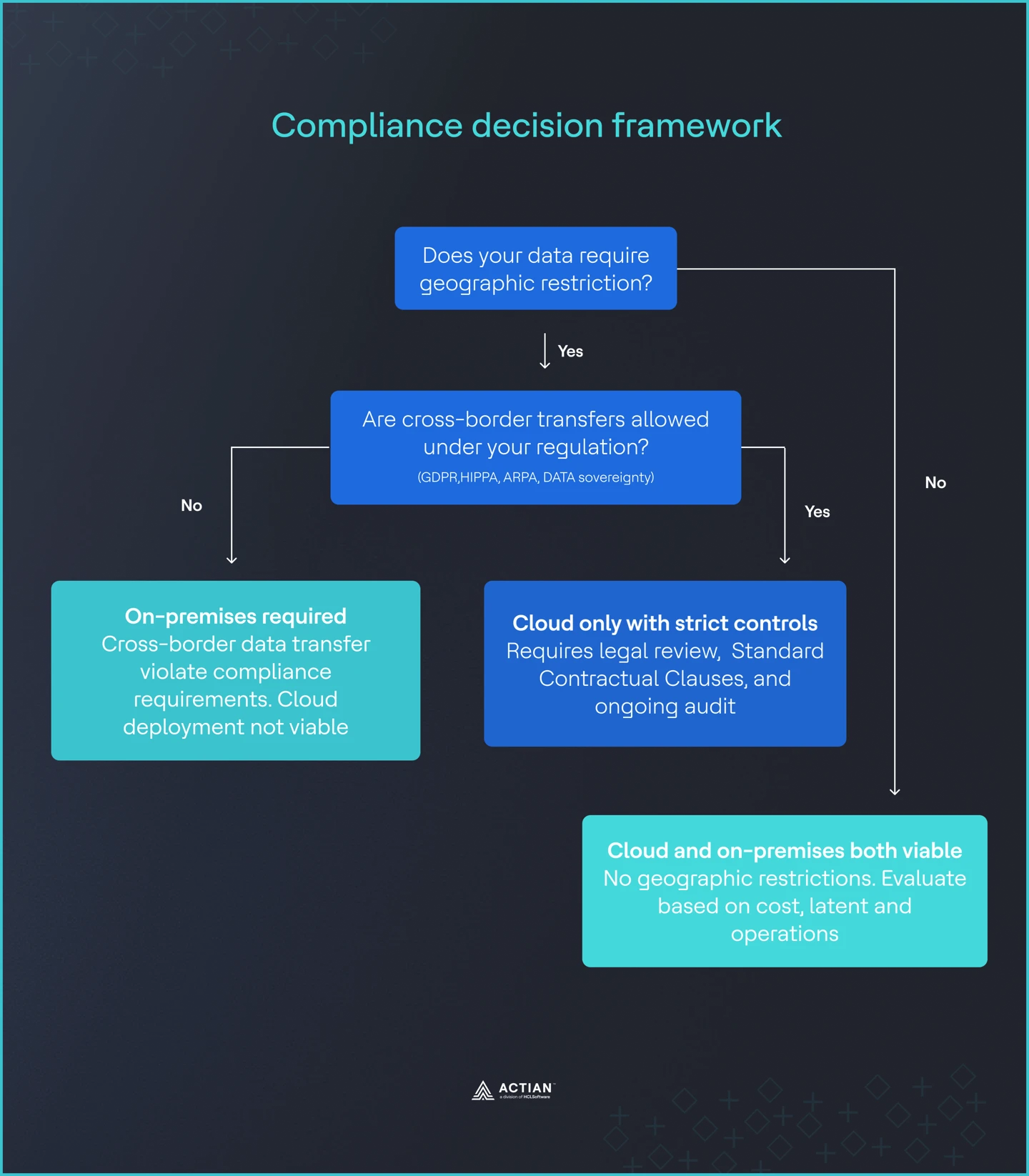
Imagen 3: Marco de cumplimiento
El análisis del desglose de costes
El coste suele ser la razón por la que los equipos reconsideran la decisión entre una solución local o en la nube. Para tomar una decisión defendible, los equipos deben comprender dónde divergen los costes y cuándo el autoalojamiento resulta económicamente racional.
¿Cuándo se alcanza el punto de equilibrio con el autoalojamiento?
La investigación de OpenMetal muestran un punto de equilibrio constante para las bases de datos vectoriales Pinecone a gran escala. Una vez que las cargas de trabajo alcanzan aproximadamente entre 80 y 100 millones de consultas al mes, las implementaciones autohospedadas tienden a ser más económicas que los servicios gestionados en la nube. Por debajo de este rango, los precios de la nube suelen ser competitivos. Por encima, la facturación basada en el uso comienza a dominar el coste total.
Este umbral es importante porque muchos sistemas RAG empresariales lo superan rápidamente. Los sistemas de atención al cliente, búsqueda de documentos, detección de fraudes y recomendaciones suelen atender decenas o cientos de millones de consultas al mes una vez implementados en todas las unidades de negocio o regiones.
El coste oculto en los precios de la nube
El precio de la nube rara vez es solo una tarifa por consulta. Las bases de datos vectoriales introducen varios factores de coste que son fáciles de pasar por alto durante la planificación.
Las tarifas de salida son un factor importante. La mayoría de los proveedores de servicios en la nube cobran alrededor de 0,09 dólares por GB por los datos que salen de su red. El traslado de incrustaciones entre regiones, la exportación de datos para su análisis o la migración a otro sistema conllevan estas tarifas. Con el tiempo, se convierten en una parte significativa del gasto total.
Por último, la búsqueda vectorial no se escala linealmente. A medida que aumenta el número de vectores y la dimensionalidad, los costes de las consultas aumentan más rápido de lo esperado. Lo que parece asequible con 10 millones de vectores puede resultar caro con 500 millones, incluso si el volumen de consultas crece de forma constante.
Los costes locales son fijos y predecibles.
Las implementaciones locales tienen costes reales, pero se comportan de manera diferente. El hardware suele amortizarse en un plazo de tres a cinco años. Las necesidades de personal se mantienen estables una vez que el sistema está en funcionamiento. Los costes de instalaciones y energía se conocen de antemano.
La diferencia clave es la previsibilidad. Los costes no se disparan debido a los patrones de uso o al movimiento de datos. Una vez que el sistema tiene el tamaño adecuado, el gasto mensual se mantiene prácticamente estable, incluso aunque aumente el volumen de consultas.
Un ejemplo real
Consideremos una aplicación de comercio electrónico de producción con la siguiente escala:
- 500 millones de vectores.
- 200 millones de consultas al mes.
- 1024 dimensiones vectoriales.
- 6M escribe mensualmente.
A esta escala, una base de datos vectorial Pinecone gestionada típica cuesta alrededor de 8500 dólares al mes, una vez incluidos los gastos generales de computación, almacenamiento y reconstrucción.
Coste mensual estimado
Coste total estimado: 8454 $ al mes
- Almacenamiento
- Uso: 845 GB
- Precio: 279 $
- Costes de consulta
- Configuración:
- 24 nodos b1
- 4 fragmentos × 6 réplicas
- Supuesto: 1 % de selectividad del filtro
- Coste estimado: 8074 dólares
- Nota: El coste real de la consulta puede variar. Compare su carga de trabajo en DRN para obtener estimaciones más precisas.
- Escribir costes
- Volumen de escritura: 30 millones de unidades de escritura (WU)
- Supuesto: Cada solicitud de escritura consume ≥ 5 WU
- Coste: 101 dólares
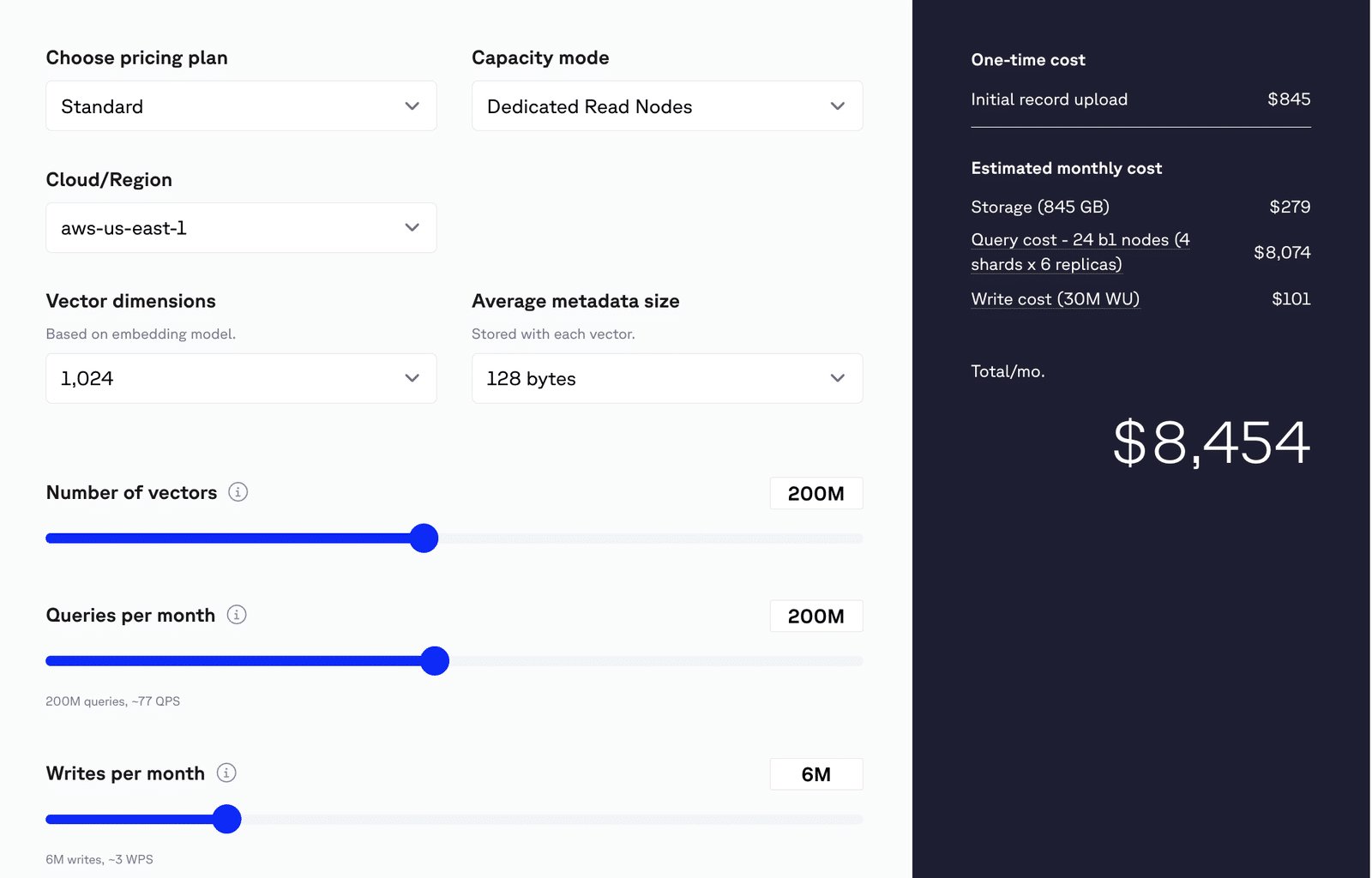
Imagen 4: Estimación del coste de Pinecone
Una implementación equivalente en las instalaciones podría costar aproximadamente la mitad de eso después de la amortización del hardware, suponiendo un período de recuperación de la inversión de 18 meses y uno o dos ingenieros que den soporte al sistema. Después de ese período de recuperación, los costos se reducen aún más, mientras que la capacidad sigue estando disponible.
Un estudio realizado por Enterprise Storage Forum muestra la proyección de costes de las cargas de trabajo locales y en la nube.
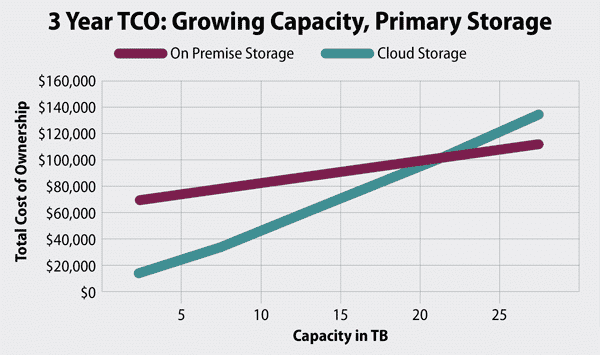
Imagen 5: Foro sobre almacenamiento empresarial TCO
El coste por sí solo no determina todas las implementaciones, pero una vez que las cargas de trabajo vectoriales alcanzan cierta escala, los aspectos económicos se vuelven difíciles de ignorar. Es fundamental comprender en qué punto de esta curva se encuentra su sistema antes de fijar una estrategia a largo plazo para la base de datos vectorial.
Cuando la latencia y la conectividad son importantes
La latencia y la conectividad suelen considerarse cuestiones secundarias en las decisiones arquitectónicas. Sin embargo, para muchas cargas de trabajo de IA, son decisivas. Una vez que las bases de datos vectoriales admiten sistemas en tiempo real, los viajes de ida y vuelta de la red y la dependencia de Internet pueden hacer que las implementaciones en la nube resulten poco prácticas o inseguras.
Requisitos de respuesta en tiempo real
Algunas aplicaciones tienen límites de tiempo de respuesta muy estrictos. En el sector sanitario, los sistemas de apoyo a la toma de decisiones clínicas y de diagnóstico suelen requerir respuestas en menos de 50 milisegundos. Este presupuesto incluye la recuperación de datos, la búsqueda vectorial y la inferencia de modelos. Del mismo modo, los bancos y las instituciones financieras suelen requerir una latencia muy baja para ofrecer la mejor experiencia posible al usuario.
Las implementaciones en la nube pública añaden una latencia de red inevitable. Incluso dentro de la misma región, la latencia de ida y vuelta suele añadir entre 20 y 80 milisegundos antes de que comience cualquier trabajo de computación. Para las aplicaciones con objetivos de latencia estrictos, esta sobrecarga por sí sola puede superar el tiempo de respuesta total permitido. Las implementaciones locales eliminan ese salto de red, lo que permite a los sistemas cumplir de forma constante los requisitos en tiempo real.
Sistemas que deben funcionar sin conexión
Muchos entornos no pueden depender de una conectividad constante. Los sistemas de punto de venta minorista deben seguir funcionando durante las interrupciones de la red. Las instalaciones de fabricación suelen estar ubicadas en zonas remotas con conexiones inestables. Las operaciones militares y marítimas pueden desarrollarse en entornos totalmente desconectados o clasificados.
En estos escenarios, la dependencia de la nube es un único punto de fallo. Si la red deja de funcionar, el sistema de IA deja de funcionar. Las implementaciones locales y periféricas permiten que la búsqueda vectorial y la inferencia se ejecuten localmente, lo que garantiza que el sistema siga funcionando incluso cuando no se dispone de conectividad externa.
El coste del tiempo de inactividad
No es ninguna novedad que se ha producido un aumento en el tiempo de inactividad de los proveedores de servicios en la nube. El 18 de noviembre de 2025, la interrupción de Cloudflare interrumpió gran parte de Internet, provocando tiempos de inactividad en las principales plataformas, como X, Amazon Web Services, Spotify, etc. El impacto de los fallos de conectividad no es teórico. En el sector manufacturero, el coste medio del tiempo de inactividad se se estima en 260 000 dólares por hora. Cuando los sistemas de IA dan soporte al control de calidad, al mantenimiento predictivo o a la automatización de procesos, cualquier interrupción afecta directamente a la producción.
Una arquitectura basada exclusivamente en la nube introduce un riesgo difícil de justificar en estos entornos. Incluso las interrupciones breves de la red pueden provocar pérdidas económicas importantes. Las implementaciones locales reducen este riesgo al eliminar las dependencias externas de las rutas de ejecución críticas.
Para cargas de trabajo con objetivos de latencia estrictos o conectividad limitada, la elección suele ser clara. Las bases de datos vectoriales basadas en la nube pueden funcionar durante el desarrollo, pero no cumplen los requisitos operativos en la producción.
La cuestión de la complejidad operativa
El argumento más sólido a favor de las bases de datos vectoriales en la nube es la simplicidad operativa. Los servicios gestionados eliminan la necesidad de aprovisionar hardware, gestionar clústeres, aplicar parches o gestionar fallos. Para equipos pequeños o proyectos en fase inicial, esta ventaja es real y, a menudo, decisiva. Las implementaciones en la nube permiten a los ingenieros centrarse en la lógica de las aplicaciones en lugar de en la infraestructura.
También es importante reconocer que las implementaciones locales modernas son muy diferentes a las de hace una década. Ya no es el mundo del aprovisionamiento manual de servidores y los scripts frágiles. Kubernetes, la infraestructura como código y los procesos de implementación automatizados han reducido significativamente los gastos operativos. Las actualizaciones continuas, el escalado automatizado y la supervisión son ahora prácticas habituales tanto en entornos locales como en la nube.
Muchas empresas adoptan enfoques híbridos para equilibrar la velocidad y el control. El desarrollo y la experimentación se llevan a cabo en la nube, donde los equipos pueden moverse rápidamente y realizar iteraciones. Los sistemas de producción se ejecutan en las instalaciones, donde los costes son predecibles y es más fácil garantizar el cumplimiento normativo. Este patrón permite a los equipos obtener lo mejor de ambos modelos sin comprometerse plenamente con ninguno de ellos.
Marco de decisión: ocho preguntas
La forma más rápida de tomar una decisión de implementación defendible es revisar un pequeño conjunto de preguntas de sí o no con los departamentos de ingeniería, legal, finanzas y operaciones.
- ¿Sus datos requieren restricciones geográficas?
Normativas como el RGPD, la HIPAA y las normas sobre servicios financieros pueden limitar los lugares donde se pueden almacenar o procesar los datos.
Si la respuesta es afirmativa, se debe considerar seriamente la implementación local, ya que proporciona un control total sobre la ubicación de los datos. Si la respuesta es negativa, la implementación en la nube sigue siendo viable.
- ¿Tienes patrones de consulta predecibles y de gran volumen?
Los costes de las bases de datos vectoriales en la nube varían en función del uso. Una forma sencilla de comprobarlo es multiplicar las consultas mensuales por el coste unitario.
Si el uso supera aproximadamente los 80 a 100 millones de consultas al mes, suele ser más barato utilizar una solución local. Por debajo de ese rango, los precios de la nube suelen ser más económicos.
- ¿Necesitas capacidad sin conexión?
Algunos sistemas deben seguir funcionando sin acceso a la red, como en entornos de fabricación, venta al por menor o periféricos.
Si la respuesta es sí, se requiere una instalación local. Si la respuesta es no, la nube sigue siendo una opción.
- ¿Puede tolerar una latencia adicional?
Las implementaciones en la nube añaden latencia a la red, a menudo entre 50 y 100 milisegundos.
Si su aplicación no puede tolerar esto, es necesario realizar una implementación local. Si puede, el rendimiento de la nube puede ser aceptable.
- ¿Dispone de equipos de infraestructura?
La capacidad operativa es importante.
Si ya utiliza sistemas locales, la carga adicional es limitada. Si no es así, los servicios gestionados en la nube ofrecen una clara ventaja operativa.
- ¿Es importante la previsibilidad de los costes?
La facturación basada en el uso introduce variabilidad en los costes.
Si lo que importa son los costes predecibles, las instalaciones locales proporcionan estabilidad. Si lo que importa es la flexibilidad, los precios de la nube pueden ser más adecuados.
- ¿Está ampliando la infraestructura informática existente?
El contexto de implementación influye en la decisión.
Si está ampliando sistemas existentes, las instalaciones locales aprovechan las inversiones actuales. Si está creando algo nuevo, la nube puede ser más rápida de implementar.
- ¿Qué tamaño tiene tu huella de datos?
El volumen de datos y la frecuencia de acceso influyen en el coste a largo plazo.
Si gestionas más de 10 TB con acceso frecuente, las instalaciones locales resultan atractivas. Si tus datos son más pequeños, la nube suele ser suficiente.
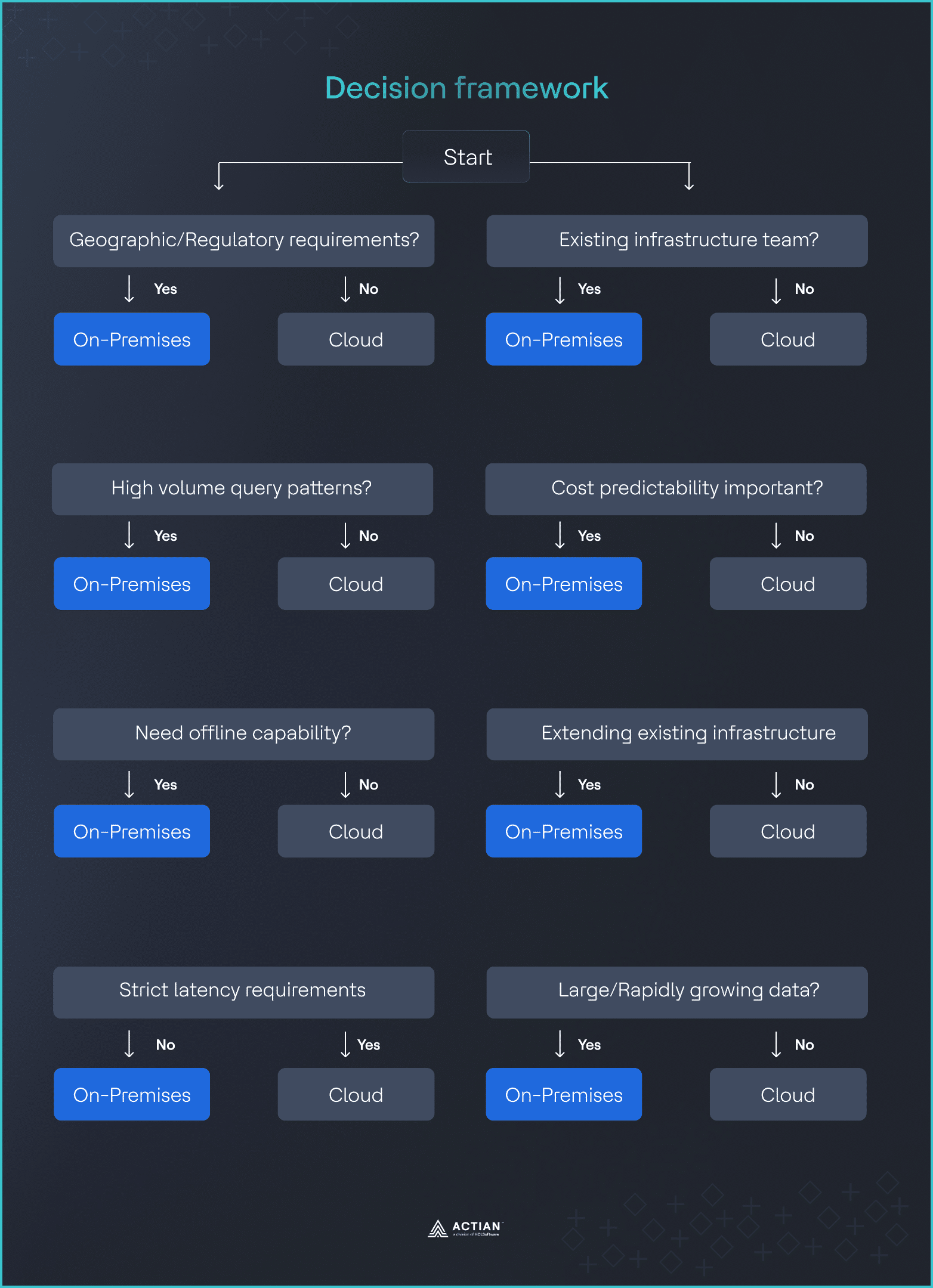
Imagen 6: Marco de decisión
Cuando varias respuestas apuntan en la misma dirección, la decisión resulta fácil de explicar y defender entre los equipos de ingeniería, jurídico, financiero y de operaciones.
Cuando la nube tiene sentido
La implementación local no siempre es la respuesta adecuada. En muchas situaciones, las bases de datos vectoriales basadas en la nube siguen siendo la mejor opción. Tener claros estos casos ayuda a evitar el exceso de ingeniería.
- Escalabilidad impredecible: las empresas emergentes y los nuevos productos suelen enfrentarse a un crecimiento incierto. Las plataformas en la nube permiten una rápida escalabilidad sin compromisos de infraestructura a largo plazo, lo que reduce el riesgo cuando la demanda es incierta.
- Volúmenes de datos pequeños: cuando el total de datos es inferior a 10 TB y el volumen de consultas se mantiene por debajo de unos 50 millones de consultas al mes, los precios de la nube suelen funcionar bien y son más sencillos que el autoalojamiento.
- Experimentación rápida: las pruebas de concepto, los proyectos de investigación y los primeros prototipos se benefician de una configuración rápida y un desmontaje sencillo. Los servicios en la nube permiten una rápida iteración con un esfuerzo operativo mínimo.
- Sin restricciones de cumplimiento: si la residencia de los datos, la soberanía y los requisitos normativos no suponen un problema, la implementación en la nube evita la complejidad legal y agiliza la entrega.
- Experiencia limitada en infraestructura: los equipos centrados en la lógica de las aplicaciones, en lugar de en las operaciones, pueden confiar en los servicios gestionados en lugar de mantener bases de datos, clústeres y hardware.
En estos casos, la nube es la opción más eficaz y práctica.
Estrategias de implementación híbrida
Las implementaciones híbridas actúan como término medio para las empresas que necesitan tanto velocidad como control. En lugar de tratar la nube y las instalaciones locales como mutuamente excluyentes, los equipos colocan cada parte del sistema donde mejor funciona.
Nube para la iteración, infraestructura local para la escalabilidad.
Un patrón habitual consiste en desarrollar y probar en la nube, donde los servicios gestionados y la infraestructura elástica permiten una rápida iteración. Una vez que los modelos, índices o canalizaciones son estables, se promueven a entornos de producción locales para cumplir los requisitos de cumplimiento, latencia y operativos. Esto preserva la velocidad de los desarrolladores sin comprometer las garantías de producción.
Segregación de datos por riesgo y regulación
Las arquitecturas híbridas también permiten a las organizaciones separar las cargas de trabajo según el perfil de riesgo. Los datos confidenciales o regulados permanecen en las instalaciones, mientras que el análisis, la formación o la búsqueda de datos derivados se ejecutan en la nube. La misma lógica se aplica a nivel regional: los datos de la UE pueden permanecer en las instalaciones o en entornos soberanos, mientras que las cargas de trabajo de EE. UU. se ejecutan en regiones de nube pública, evitando que los sistemas globales se vean limitados por la jurisdicción más estricta.
Coste y flexibilidad migratoria
La optimización de costes es otro factor impulsor. Los vectores a los que se accede con frecuencia o los servicios de baja latencia pueden ser más baratos y predecibles en las instalaciones locales, mientras que el almacenamiento en frío y las cargas de trabajo intermitentes se benefician de los precios de la nube. Muchos equipos comienzan por la nube y luego trasladan selectivamente los componentes a las instalaciones locales a medida que aumentan las presiones de escala o cumplimiento. La solución híbrida hace que esto sea una evolución controlada en lugar de una reescritura disruptiva.
Las investigaciones del sector demuestran que se trata de un modelo operativo estable. Google Distributed Cloud y otras plataformas similares definen explícitamente la hibridación como una estrategia a largo plazo, reconociendo que los sistemas modernos están diseñados para abarcar distintos entornos, no para reducirlos a uno solo.
El enfoque de Actian respecto a las bases de datos vectoriales locales
Para los equipos que concluyen que el modelo de implementación local es el adecuado, la siguiente pregunta es: ¿qué plataforma puede realmente satisfacer estos requisitos? El enfoque de Actian de Actian está diseñado específicamente para este público, sin dar por sentado que la nube es la opción predeterminada o el estado final.
Actian ofrece una base de datos vectorial de nivel empresarial que funciona íntegramente en su propio centro de datos o en entornos controlados. Usted mantiene el control total sobre la ubicación de los datos, las redes y las operaciones. No existe una dependencia forzada de servicios externos en la nube, lo que simplifica las auditorías y el diseño del sistema a largo plazo.
Los requisitos de cumplimiento se tratan como restricciones básicas. Al mantener los datos locales y eliminar las rutas de salida, Actian se ajusta al RGPD, la HIPAA, el FedRAMP y otros marcos normativos similares. Esto reduce la necesidad de controles compensatorios o soluciones legales complejas.
El comportamiento de los costes también es predecible. Actian evita los modelos de precios basados en el uso que se ajustan en función del número de consultas o vectores. Esto simplifica la elaboración de presupuestos y elimina sorpresas a medida que aumentan las cargas de trabajo.
También se tiene en cuenta el soporte periférico. La arquitectura de Actian admite el funcionamiento sin conexión y la inferencia local, lo que la hace adecuada para plantas de fabricación, establecimientos minoristas y otros entornos en los que la conectividad es limitada o poco fiable. El sistema está diseñado para seguir funcionando incluso cuando la red no lo hace.
Reflexiones finales
Elegir entre la nube y las instalaciones locales para las bases de datos vectoriales consiste en comprender cuáles son tus prioridades. La nube funciona bien para cargas de trabajo pequeñas, experimentación rápida y equipos sin grandes conocimientos de infraestructura. Las instalaciones locales tienen sentido cuando el cumplimiento normativo, la latencia, la previsibilidad de los costes o la escala son fundamentales.
Muchas empresas consideran que un enfoque híbrido es la mejor opción, ya que combina la flexibilidad de la nube con el control local. La clave está en tomar decisiones deliberadas basadas en sus datos, cargas de trabajo y necesidades normativas, en lugar de seguir las tendencias.
Actian permite a las empresas gestionar y controlar con confianza datos a gran escala. Las organizaciones confían en las soluciones de gestión e inteligencia de datos de Actian para optimizar entornos de datos complejos y acelerar la entrega de datos preparados para la inteligencia artificial. Como división de datos e inteligencia artificial de HCLSoftware, Actian ayuda a las empresas a gestionar y controlar datos a gran escala en entornos locales, en la nube e híbridos. Más información sobre Actian y cómo encaja en su estrategia de IA local.
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)