Cómo evaluar las bases de datos vectoriales en 2026




Resumen
- La mayoría de las pruebas comparativas de bases de datos vectoriales están optimizadas por los propios proveedores y no reflejan las condiciones reales de producción, como la concurrencia, el filtrado y la ingesta continua.
- Entre los principales riesgos de producción se incluyen la latencia de cola (P95/P99), la disminución del rendimiento con el paso del tiempo y el aumento del coste total de propiedad a gran escala.
- El sector está evolucionando hacia el concepto de «vector como característica», dando preferencia a plataformas integradas como PostgreSQL + pgvector o Actian VectorAI DB frente a las bases de datos vectoriales independientes.
- Una evaluación eficaz requiere pruebas en condiciones reales con datos de alta dimensión, cargas de trabajo simultáneas y modelos de costes a largo plazo.
En 2026, una crisis de rendimiento sintético pone a prueba el mercado de las bases de datos vectoriales. Una búsqueda en GitHub de «vector database benchmark» muestra repositorios muy cuidados, con paneles de control y gráficos de rendimiento. Sin embargo, los proveedores suelen crear estas herramientas para evaluar sus propios productos y presentar las ventajas específicas de su arquitectura como comparaciones objetivas.
Zilliz mantiene VectorDBBench. Redis y Qdrant publican conjuntos de pruebas de rendimiento que ponen de relieve sus propios sistemas. Incluso las evaluaciones de «vecino más cercano aproximado» (ANN) más citadas, como ANN-Benchmarks, se basan en conjuntos de datos de baja dimensión, como la Transformación de Características Invariante a la Escala (SIFT) y los Árboles de Búsqueda Generalizados (GIST). Las incrustaciones de los modelos de lenguaje a gran escala (LLM) modernos suelen alcanzar las 3072 dimensiones. Estas pruebas de rendimiento no reflejan esa realidad.
Las tablas de clasificación premian el rendimiento en condiciones estáticas, pero los sistemas de producción deben soportar escrituras continuas, filtros de metadatos y picos de concurrencia. Como señaló acertadamente el ingeniero de software Simon Frey en una publicación que se hizo viral: «La mejor base de datos vectorial es la que ya tienes». Esto refleja el cambio que se producirá en el mercado en 2026, lo que llevará a los equipos a pasar de los silos especializados a las bases de datos en las que ya confían y con las que ya trabajan.
Esta guía adopta un enfoque centrado en la producción. Definimos las cinco pruebas fundamentales para 2026 y analizamos por qué es posible que su base de datos vectorial óptima ya exista dentro de su arquitectura actual, ya sea PostgreSQL con pgvector o un motor híbrido empresarial como Actian VectorAI DB.
TL;DR
- El sesgo: La mayoría de los conjuntos de pruebas de rendimiento proceden de los propios proveedores y están optimizados para obtener ventajas arquitectónicas específicas.
- La realidad: Las cargas de trabajo de producción incluyen la ingesta continua, el filtrado de metadatos y picos de concurrencia que las pruebas sintéticas ignoran.
- El riesgo: La latencia de cola (P99), la fragmentación de índices y la amplificación de escritura deterioran los sistemas mucho antes de que disminuya el QPS medio.
- La curva de costes: Los servicios de vectores gestionados suelen aplicar precios no lineales a medida que aumenta el tamaño del conjunto de datos.
- La tendencia: En 2026 se preferirán las plataformas integradas, desde extensiones relacionales consolidadas (PostgreSQL + pgvector) hasta sistemas híbridos empresariales (Actian VectorAI DB), frente a los silos «exclusivamente vectoriales».
Por qué todas las pruebas de rendimiento que has visto están optimizadas por los proveedores
Las pruebas de rendimiento dan una impresión de objetividad, pero a menudo esconden supuestos arquitectónicos. Herramientas como VectorDBBench (Zilliz) favorecen la escalabilidad distribuida, mientras que las suites de Redis y Qdrant hacen hincapié en las operaciones en memoria. Para obtener datos objetivos, los arquitectos deben recurrir a congresos académicos revisados por pares, como NeurIPS y VLDB (Very Large Databases), que anteponen el rigor algorítmico al marketing.
Antes de analizar qué es lo que importa en la producción, conviene comprender cómo influyen las herramientas de evaluación comparativa habituales en los resultados.
| Herramienta de evaluación comparativa | Creador principal | Enfoque en la optimización | Sesgo típico |
|---|---|---|---|
| VectorDBBench | Zilliz (Milvus) | Escalabilidad de alto rendimiento | Favorece los clústeres de gran tamaño; penaliza los sistemas de un solo nodo. |
| vector-db-benchmark | Redis/Qdrant | Operaciones en memoria | Favorece las arquitecturas con gran consumo de RAM; no tiene en cuenta el coste total de propiedad (TCO) de la memoria. |
| ANN-Pruebas de rendimiento | Académico | Eficiencia del algoritmo en bruto | Utiliza conjuntos de datos obsoletos y de baja dimensión (SIFT/GIST). |
| NeurIPS / VLDB | Compañeros de estudios | Robustez algorítmica | Se centra en las matemáticas y la teoría; ignora la realidad operativa y los acuerdos de nivel de servicio. |
Las reglas ocultas del benchmarking
Un obstáculo importante es la «cláusula DeWitt», una disposición legal incluida en muchos acuerdos de licencia de usuario final (EULA) que prohíbe a los usuarios publicar pruebas de rendimiento independientes sin el permiso del proveedor. En 2024, BenchANT descubrió que el 30 % de las principales bases de datos vectoriales prohíben legalmente revelar que sus productos son lentos.
Además, estas pruebas de rendimiento suelen realizarse en el «tiempo cero», es decir, el intervalo artificial que sigue inmediatamente a la ingesta de datos pero que precede a las actualizaciones en tiempo real. En entornos de producción, los sistemas deben insertar y eliminar datos constantemente, lo que obliga al índice a reoptimizarse en tiempo real. Las pruebas de rendimiento de los proveedores suelen omitir los errores por falta de memoria (OOM) que se producen como consecuencia de ello.
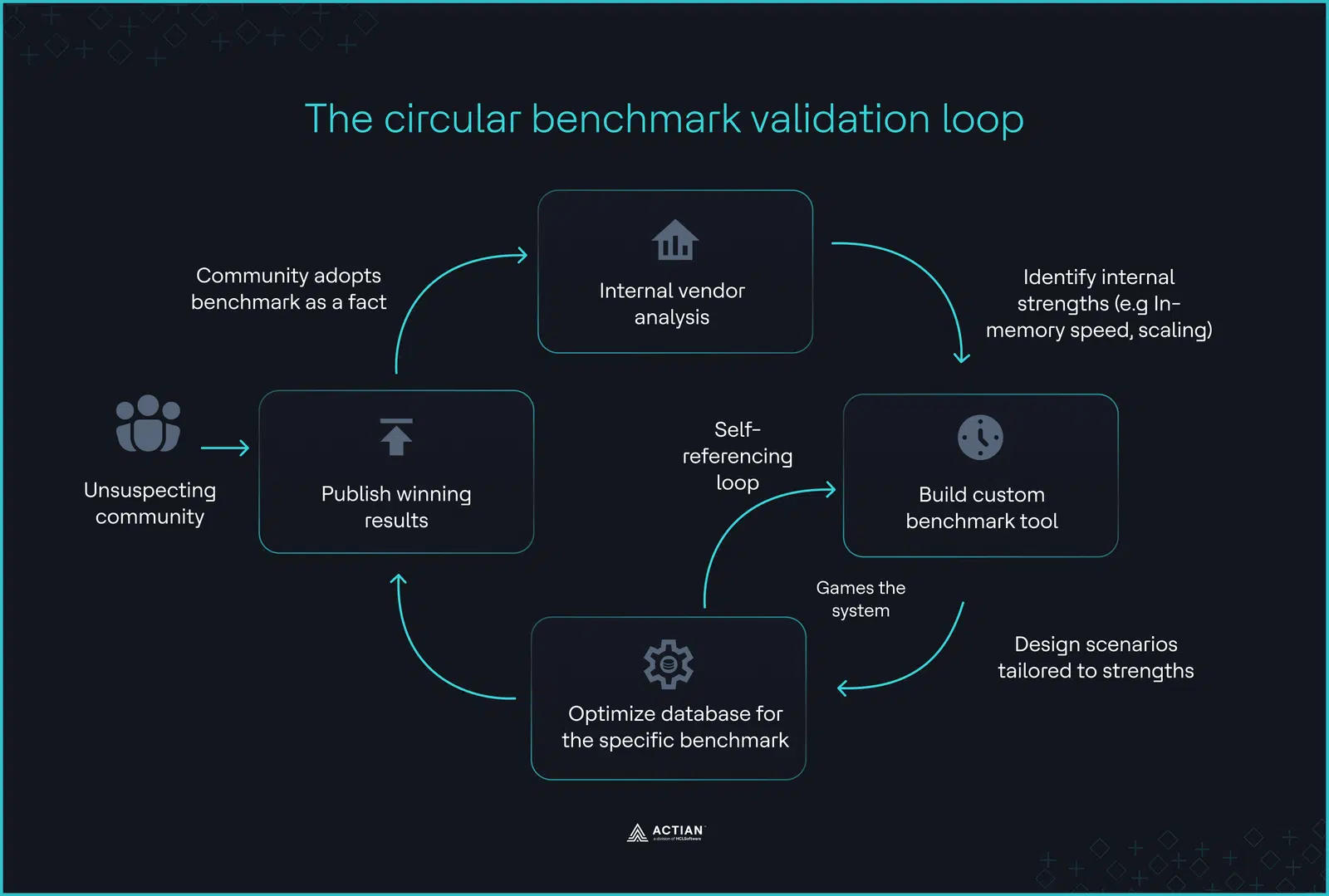
El bucle de validación circular
Las cinco pruebas de producción que realmente importan
La mayoría de las pruebas de rendimiento miden el rendimiento tras cargar los datos, antes de que se produzcan actualizaciones reales. Sin embargo, el entorno de producción es un proceso ininterrumpido e impredecible. Para encontrar una base de datos capaz de gestionar usuarios reales, debes realizar estas cinco pruebas de estrés.
1. Filtrado bajo carga simultánea
Las búsquedas basadas exclusivamente en la similitud vectorial son poco frecuentes en la vida real. En entornos de producción, lo más habitual es realizar búsquedas del tipo «Recomendaciones de productos DONDE la categoría sea ‘zapatos’ Y el stock sea > 0».
El equipo de ingeniería de Reddit, que gestiona más de 340 millones de vectores, identificó el filtrado de metadatos como el principal cuello de botella en el rendimiento de su implementación de 2025. Descubrieron que, a medida que aumentaba el número de usuarios simultáneos, la base de datos dedicaba más tiempo a resolver los filtros de metadatos que a calcular las distancias de similitud.
- La realidad: la producción implica más de 100 clientes simultáneos que acceden a diferentes conjuntos de metadatos.
- La diferencia: VectorDBBench solo realiza pruebas con un único cliente. En situaciones reales, el traslado de datos entre el grafo vectorial y el almacén de metadatos relacional puede hacer que la latencia P99 se multiplique por diez, ya que la CPU tiene que esperar a que se complete la E/S del disco.
2. Deterioro del rendimiento con el paso del tiempo
Aunque los sistemas de generación aumentada por recuperación de archivos (RAG) pueden utilizar técnicamente bases de conocimiento estáticas, las aplicaciones de producción en 2026 deben reflejar datos en tiempo real, como los tickets de los clientes o el inventario de productos. Tal y como admitió el equipo de ingeniería de Milvus: «Las pruebas de rendimiento se realizan una vez finalizada la ingesta de datos, pero los datos de producción nunca dejan de fluir». Si la base de datos no puede reindexarse tan rápido como ingiere datos, tu IA podría proporcionar respuestas obsoletas o incorrectas durante horas.
Las pruebas de rendimiento que omiten una prueba de «escritura y consulta continuas durante 72 horas» no aportan ningún valor. Debes determinar si el rendimiento de las consultas se ve afectado tras seis meses de mantenimiento continuo de los índices.
3. Latencia de cola bajo carga (P95/P99)
La latencia media puede ser engañosa y no refleja lo que realmente experimentan los usuarios. Por ejemplo, un tiempo de respuesta medio de 10 ms no sirve de nada si el 1 % de las consultas más lentas (P99) tarda 800 ms. Esto hace que tu agente de IA parezca lento y poco fiable. Solo las pruebas de alta concurrencia revelan estos picos, que suelen producirse durante la recolección de basura o el bloqueo de índices.
4. Coste total de propiedad (TCO)
En 2025, los proveedores gestionados introdujeron un complejo sistema de precios basado en «unidades de lectura». Esto generó una «penalización por crecimiento»: si tu índice pasa de 10 GB a 100 GB, podrías llegar a pagar diez veces más por el mismo resultado de consulta.
| Escala métrica | Base de datos vectorial gestionada (basada en el uso) | Plataforma integrada/híbrida | Repercusión en el coste total de propiedad |
|---|---|---|---|
| Inicial (10 GB) | Alta (cuota de la plataforma + uso) | Moderado (recursos fijos) | El valor integrado es aproximadamente un 40 % inferior |
| Crecimiento (100 GB) | Alto (depende del volumen) | Bajo (escalado vertical) | diferencia de coste de 8 veces |
| Empresa (1 TB o más) | Prohibitivo (crecimiento lineal) | Optimizado (capacidad reservada) | Más del 90 % de ahorro a largo plazo |
Esta realidad económica es la principal impulsora del cambio del mercado hacia el modelo «Vector as a Feature», en el que los equipos dan prioridad a las capacidades locales y a una escalabilidad predecible frente a los silos basados en el uso.
5. Madurez operativa
Las comparativas no tienen en cuenta el «impuesto de soporte operativo», que cuantifica el coste y el riesgo que supone mantener una infraestructura especializada. Es fácil encontrar un experto en PostgreSQL, ya que la comunidad lleva 30 años en pleno auge, pero contratar a alguien con conocimientos avanzados en una base de datos vectorial especializada que lleva solo tres años en el mercado suele suponer un cuello de botella.
Evalúa el ecosistema: ¿Funciona la base de datos con herramientas de copia de seguridad estándar? ¿Se puede integrar con Prometheus? ¿Cuánto tiempo se tarda en reconstruir un índice tras un fallo del sistema?
A continuación se muestra una comparación entre las afirmaciones de los estudios comparativos y la realidad de la producción.
| Métrico | Enfoque comparativo | Realidad de la producción |
|---|---|---|
| Ingestión | QPS estático tras la finalización | QPS constante durante las operaciones de escritura continuas |
| Latencia | Latencia media | Latencia de P95/P99 bajo carga simultánea |
| Filtrado | Búsqueda filtrada para un solo cliente | Más de 100 consultas simultáneas filtradas por metadatos |
| Coste | Coste de infraestructura por consulta | Coste total de propiedad (TCO) con más de 100 millones de consultas al mes |
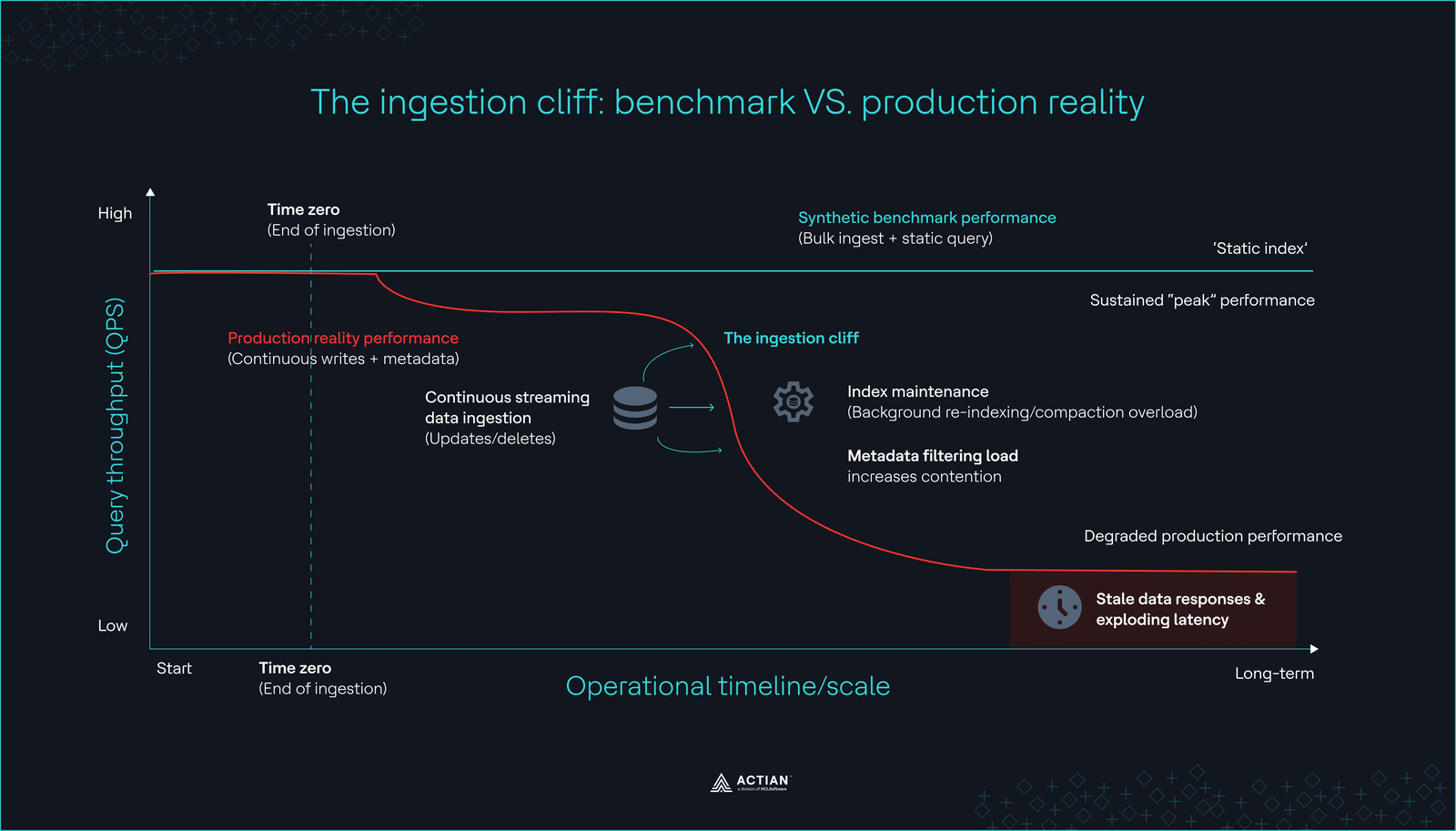 El precipicio de la ingesta
El precipicio de la ingestaDetectar estos cuellos de botella ocultos es el primer paso para crear un sistema sólido. En 2026, la solución rara vez consiste en utilizar una base de datos más rápida y especializada. En su lugar, los ingenieros están incorporando estas funciones a las herramientas que ya conocen y en las que confían.
El cambio hacia la consolidación: Vector como característica
Corey Quinn, economista jefe especializado en la nube, dijo en una ocasión: «Vector es una funcionalidad, no un producto». Esta predicción marca la pauta del mercado en 2026. Los equipos están dejando de lado las bases de datos especializadas «solo vectoriales» y optando por plataformas integradas «también vectoriales». El traslado de datos entre una base de datos principal y una base de datos vectorial independiente suele causar más problemas de los que resuelve.
El renacimiento de PostgreSQL
Los ingenieros suelen argumentar en plataformas como Hacker News que alrededor del 80 % de los casos de uso de RAG (concretamente aquellos con incrustaciones inferiores a 2 millones) no requieren una base de datos vectorial especializada. Para estas cargas de trabajo, los silos independientes suelen generar más fricciones operativas de las que aportan en ganancias de rendimiento. Instacart lo validó a gran escala al migrar de Elasticsearch a PostgreSQL, logrando un ahorro de costes del 80 % y reduciendo la carga de trabajo de escritura en 10 veces tras eliminar la necesidad de coordinar y conciliar datos entre arquitecturas fragmentadas.
Recientemente, pgvectorscale alcanzó las 471 consultas por segundo con un 99 % de recuperación en 50 millones de vectores, superando las 41 QPS de Qdrant en un hardware de AWS idéntico. Las pruebas de rendimiento de los proveedores suelen omitir este resultado porque demuestra que la mayoría de las aplicaciones RAG no requieren un proveedor especializado.
| Indicador de rendimiento | PostgreSQL (pgvector + pgvectorscale) | Qdrant (especializado) | El Delta |
|---|---|---|---|
| Rendimiento (QPS) | 471.57 | 41.47 | 11,4 veces más rápido en Postgres |
| Latencia del P95 | 60,42 ms | 36,73 ms | Qdrant es un 39 % más rápido en la parte final |
| Latencia P99 | 74,60 ms | 38,71 ms | Qdrant es un 48 % más rápido en la parte final |
| Hardware | AWS r6id.4xlarge (16 vCPU) | AWS r6id.4xlarge (16 vCPU) | Paridad |
La brecha de la empresa integrada
Para cargas de trabajo que superan las capacidades básicas, Actian VectorAI DB cubre esa necesidad al integrar un motor de alto rendimiento con soporte vectorial nativo. Los equipos pueden aplicar filtros de metadatos y realizar búsquedas por similitud dentro de un único sistema, lo que reduce el movimiento de datos y simplifica la ejecución de consultas.
| Plataforma | Estrategia arquitectónica | Capacidad prevista en materia de inteligencia artificial |
|---|---|---|
| Base de datos Actian VectorAI | Híbrido de alto rendimiento | Diseñado para ofrecer análisis integrados y compatibilidad nativa con vectores. |
| PostgreSQL | Funcionalidad integrada | Apalancamientos pgvector dentro del SQL estándar. |
| Vectores de AWS S3 | Centrado en el almacenamiento | Diseñado para realizar consultas en miles de millones de vectores almacenados en un sistema de almacenamiento de objetos. |
| MongoDB Atlas | API unificada para documentos y vectores | Integra la búsqueda vectorial nativa directamente en el flujo de trabajo actual del almacén de documentos. |
A medida que el mercado se consolida, cambia nuestra forma de evaluar las bases de datos. Los equipos ya no se preguntan: «¿Quién tiene el gráfico más rápido?». Ahora se preguntan: «¿Qué arquitectura ofrece el motor de consultas más fiable?». No existe una solución única que valga para todos. En su lugar, los equipos se enfrentan a una serie de compensaciones entre la velocidad especializada y la fiabilidad integrada.
El proceso de evaluación concede ahora mayor importancia a la solidez operativa, la flexibilidad en el mundo real y la compatibilidad con la búsqueda híbrida. La ejecución fiable de las consultas se está convirtiendo en la máxima prioridad, sobre todo teniendo en cuenta la creciente demanda de búsqueda híbrida.
La realidad de la búsqueda híbrida que ocultan las pruebas de rendimiento de Pure Vector
La búsqueda vectorial pura suele suspender la prueba de «fundamentación», que mide en qué medida la respuesta de una IA se basa estrictamente en el material de referencia proporcionado. Una puntuación alta en fundamentación garantiza que el modelo de lenguaje grande (LLM) evite inventarse cosas y se ciña fielmente a tus datos internos.
Según un análisis publicado en el blog de desarrolladores de Microsoft Azure, la búsqueda vectorial pura por sí sola presenta dificultades en cuanto a la precisión factual, con una puntuación mediocre de 2,79 sobre 5 en cuanto a la fiabilidad. La solución es la búsqueda híbrida, que combina la similitud vectorial semántica con la coincidencia tradicional de palabras clave (BM25).
La pérdida de rendimiento del 20-40 %
La búsqueda híbrida requiere un esfuerzo computacional considerable. La base de datos debe clasificar los resultados de dos motores diferentes, como el léxico y el semántico, y luego fusionarlos mediante un algoritmo de fusión. Las implementaciones en producción suelen experimentar una pérdida de rendimiento de entre el 20 % y el 40 % al pasar de la búsqueda vectorial pura a la búsqueda híbrida. La fusión de clasificaciones recíprocas (RRF) genera la mayor parte de esta «pena de fusión», que, según la investigación de Elastic, puede aumentar significativamente la latencia de las consultas en comparación con las búsquedas en un único índice.
Las bases de datos que integran la búsqueda vectorial con el filtrado, la búsqueda de texto completo y la ejecución de consultas en un único motor ejecutan consultas híbridas en una sola instrucción atómica. El optimizador de consultas puede evaluar a la vez los filtros de metadatos, las condiciones de texto completo y la similitud vectorial. Esto permite al optimizador generar mejores planes de ejecución y mover menos datos.
Por el contrario, los silos vectoriales especializados fragmentan la ruta de la consulta. Las aplicaciones dirigen las solicitudes a través de múltiples sistemas y fusionan los resultados fuera de la base de datos. Esto aumenta la complejidad del sistema e introduce una latencia impredecible bajo carga.
Las plataformas híbridas, como Actian VectorAI DB, resuelven este problema al integrar la búsqueda vectorial en el motor de la base de datos. Este diseño elimina las uniones entre sistemas, simplifica las operaciones y reduce la sobrecarga arquitectónica a largo plazo.
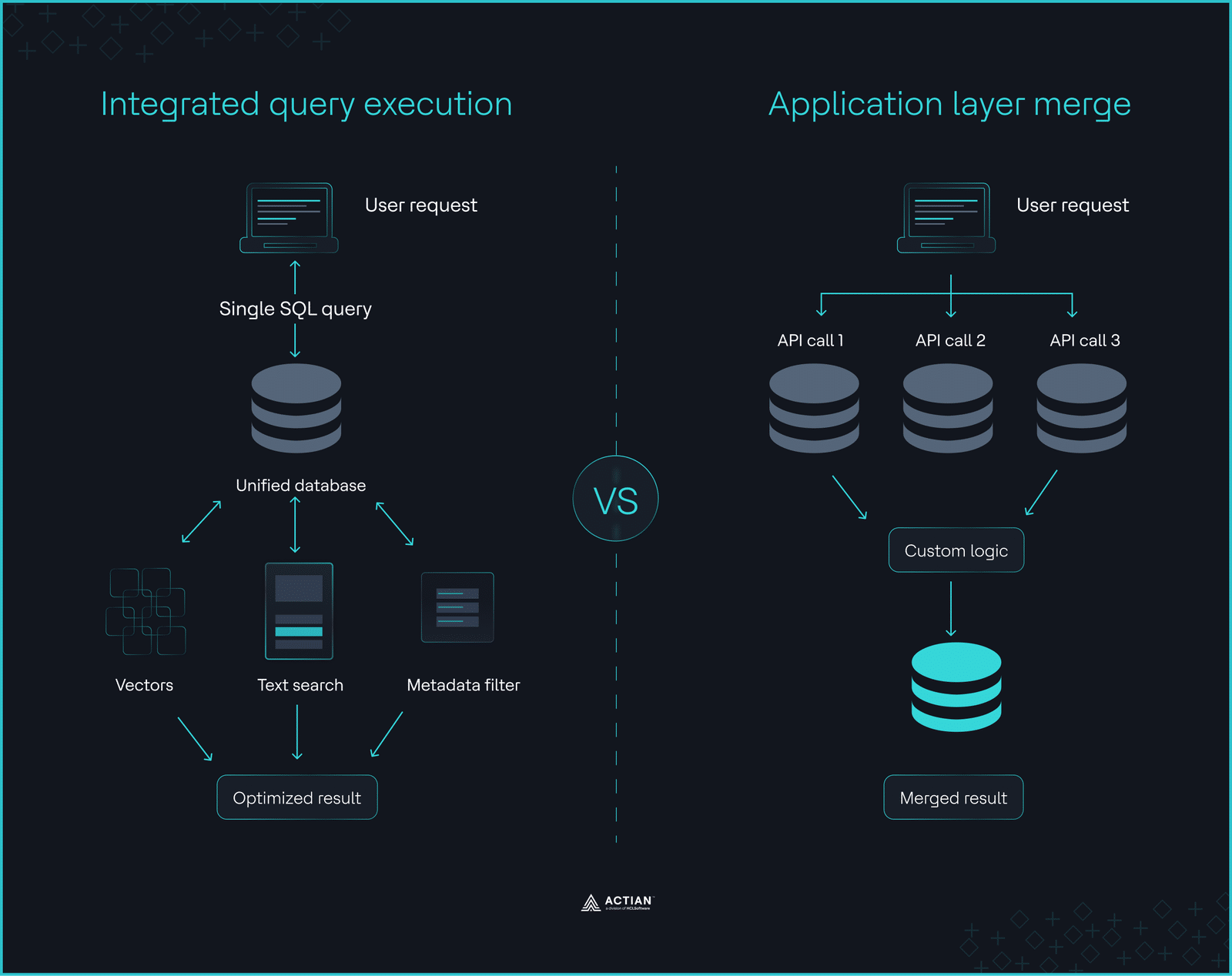 Ejecución integrada de consultas frente a la fusión en la capa de aplicación
Ejecución integrada de consultas frente a la fusión en la capa de aplicaciónCrea tu propio marco de evaluación
Deja de preguntarte qué base de datos ha ganado una clasificación de GitHub. Empieza a preguntarte qué arquitectura se adapta a tus limitaciones. En 2026, estas limitaciones girarán en torno a la ubicación de los datos, la escalabilidad y la experiencia del equipo.
Argumentos a favor de las soluciones híbridas y locales
La residencia de datos ya no es una opción para las empresas internacionales. Dado que las sanciones previstas en la Ley de IA de la UE pueden alcanzar los 35 millones de euros o el 7 % de los ingresos globales, las bases de datos vectoriales que operan exclusivamente en la nube no son una opción viable desde el punto de vista legal para los sectores regulados.
- Sovereignty: El 60 % de las entidades financieras fuera de EE. UU. tiene previsto adoptar soluciones de vectorización soberanas o locales de aquí a 2028.
- Coste: Cuando el volumen de consultas alcanza los 100 millones al mes, el «impuesto de la nube» se hace patente. El autoalojamiento o el uso de plataformas híbridas como Actian pueden reducir a la mitad los gastos de infraestructura.
- Experiencia: Si ya gestionas una base de datos relacional, tu equipo cuenta con el 90 % de las habilidades necesarias.
El árbol de decisión sobre la arquitectura de 2026
- ¿Es necesario almacenar los datos en las propias instalaciones por motivos de cumplimiento normativo? → Da prioridad a Actian VectorAI DB o a PostgreSQL autohospedado.
- ¿Tu volumen de consultas supera los 100 millones al mes? → Evita las tarifas gestionadas basadas en el uso; opta por la opción autohospedada o la capacidad reservada.
- ¿Necesitas aplicar filtros complejos a los metadatos? → Un motor relacional/vectorial integrado es imprescindible.
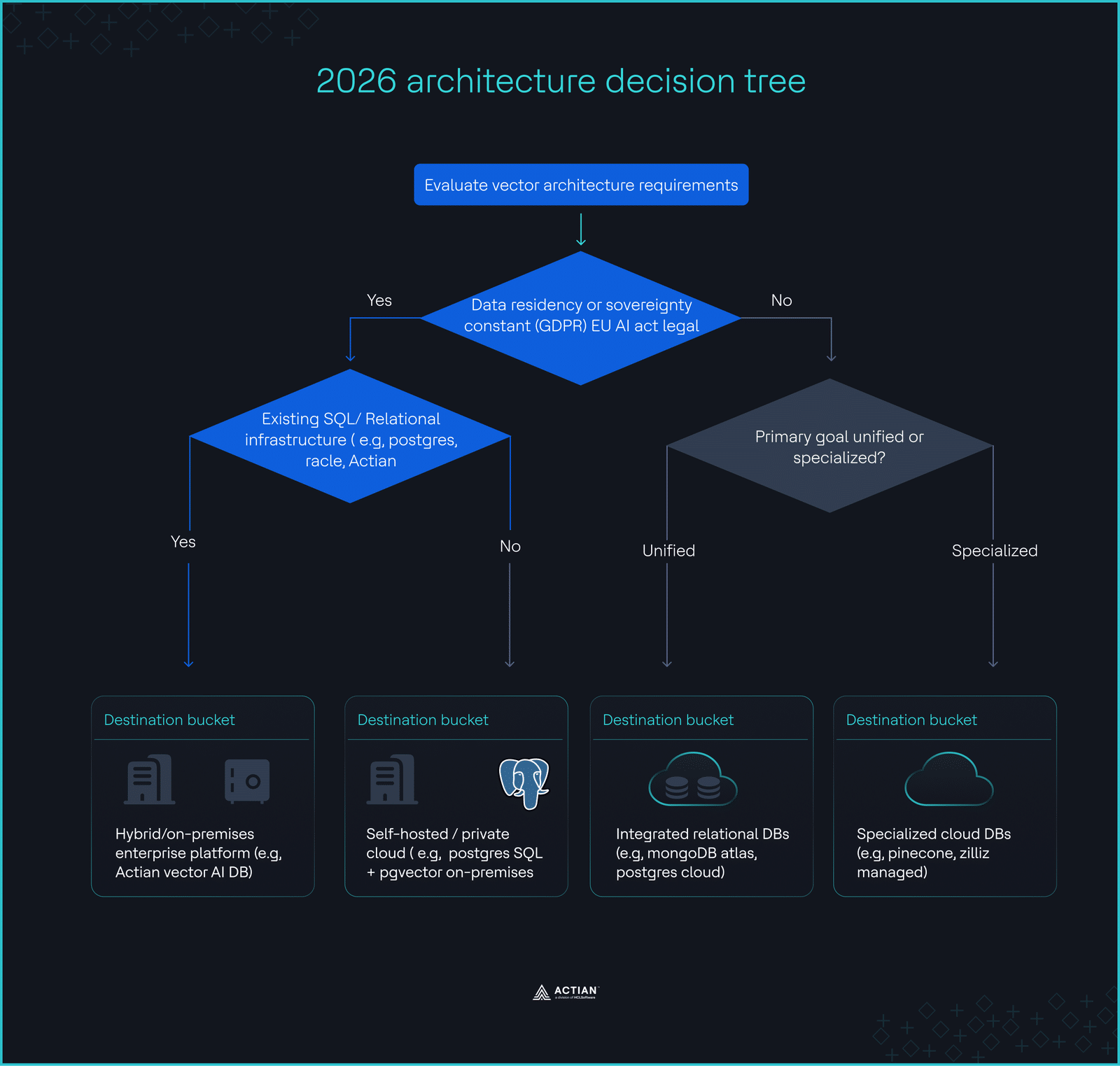 El árbol de decisión sobre la arquitectura de 2026
El árbol de decisión sobre la arquitectura de 2026Cómo evaluar a los evaluadores
Para evitar que las pruebas comparativas de los proveedores te induzcan a error, examina la herramienta de evaluación con el mismo detenimiento con el que examinas la base de datos. Para detectar una prueba sesgada, no te fijes solo en las cifras de QPS que aparecen en los titulares y comprueba las condiciones exactas en las que se obtuvieron.
Utiliza la siguiente rúbrica de evaluación para revisar cualquier informe de referencia antes de que influya en tus decisiones arquitectónicas.
| Indicador de evaluación | Bandera roja (Descartar resultado) | Bandera verde (resultado fiable) |
|---|---|---|
| Estado de ingestión | Las consultas se ejecutan en un índice estático e inmutable sin escrituras en segundo plano. | Pruebas de «lectura-mientras-se-escribe», en las que las consultas se ejecutan durante la ingesta continua de datos. |
| Paridad de hardware | Instancias locales «optimizadas» del proveedor en la nube frente a instancias «predeterminadas» de la competencia, que no son compatibles. | Se verificó que todas las configuraciones de CPU, RAM y E/S de disco fueran idénticas en todos los sistemas sometidos a prueba. |
| Selectividad de los datos | Filtros de «alta selectividad» (que eliminan el 99 % de los datos) que ocultan las ineficiencias de las operaciones de unión y exploración. | Pruebas de «baja selectividad» (filtrado del 10-20 %) que obligan al motor a gestionar recorridos de índices a gran escala. |
| Dimensionalidad | Pruebas con conjuntos de datos históricos de 128 dimensiones (SIFT/GIST). | Pruebas con vectores de 1.536 o 3.072 dimensiones que coinciden con los resultados de los modelos de lenguaje grande (LLM) actuales. |
| Métrica de latencia | Se centra exclusivamente en la «latencia media» o el «tiempo medio de respuesta». | Publica claramente la latencia de cola P95 y P99 bajo una carga concurrente elevada. |
Lista de verificación previa al compromiso
- Prueba con representaciones de alta dimensión (3.072 dimensiones o más) representativas del entorno de producción.
- Mide la latencia de P99 con más de 100 usuarios simultáneos que aplican diversos filtros de metadatos.
- Calcule el coste total de propiedad (TCO) a tres años, incluyendo el aumento del almacenamiento, las tarifas de salida de datos y las tarifas de reindexación.
- Asegúrate de que tu equipo sea capaz de gestionar la observabilidad y las copias de seguridad de la nueva pila.
Reflexiones finales
Una evaluación real requiere realizar pruebas con tus propios datos, tus propios patrones y tu propia escala. Carga datos representativos de tu entorno de producción, ejecuta una prueba de estabilidad de una semana de duración bajo carga simultánea y mide la latencia P99 y el coste total de propiedad (TCO).
Si tu carga de trabajo requiere cumplimiento normativo, una implementación híbrida o una madurez operativa de nivel de producción que las bases de datos vectoriales gestionadas no ofrecen, entonces el acceso anticipado a Actian VectorAI DB es el siguiente paso adecuado.
Únete a la comunidad de Actian en Discord para hablar sobre la arquitectura vectorial con ingenieros que resuelven problemas reales de producción.

Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)