Integración de Actian Zen y Apache Kafka mediante Kafka Connect (JDBC)




Resumen
- Crea un canal de datos financieros en tiempo real transmitiendo datos de Actian Zen a Apache Kafka mediante los conectores JDBC Source y Sink.
- Las tablas de origen de solo adición y las operaciones de inserción o actualización idempotentes permiten una transmisión de eventos bursátiles con baja latencia, reproducible y lista para auditorías.
- Avro con Schema Registry garantiza una sólida gestión de esquemas y una evolución segura para las cargas de trabajo financieras.
- Esta arquitectura moderniza los sistemas por lotes, transformándolos en diseños centrados en el streaming sin necesidad de sustituir las bases de datos operativas.
Los sistemas financieros modernos ya no se basan en procesamientos por lotes nocturnos ni en tareas ETL periódicas. Los motores de fijación de precios, los sistemas de registro de operaciones, los paneles de control de riesgos y las plataformas de cumplimiento normativo dependen todos de flujos continuos de eventos que deben procesarse con baja latencia, alta fiabilidad y observabilidad total.
Al mismo tiempo, muchas organizaciones ya confían en bases de datos operativas de probada eficacia para almacenar datos transaccionales y dar soporte a aplicaciones críticas para el negocio. La sustitución de esos sistemas rara vez es una opción.
En este tutorial técnico se muestra cómo Actian Zen y Apache Kafka pueden trabajar juntos para formar un robusto canal de datos en tiempo real, sin necesidad de reescribir aplicaciones ni introducir código personalizado complejo. Mediante los conectores JDBC Source y Sink de Kafka Connect, transmitimos datos financieros similares a los de operaciones bursátiles desde Zen a Kafka y de vuelta a Zen, creando un patrón arquitectónico reutilizable adecuado para cargas de trabajo financieras del mundo real.
Por qué el streaming es importante en el sector financiero
Los datos financieros presentan una serie de características únicas:
- Urgencia: Los datos obsoletos pueden invalidar las decisiones.
- Ritmo irregular: La apertura y el cierre del mercado, así como la volatilidad, provocan picos.
- Correctitud estricta: No se aceptan duplicados ni eventos que falten.
- Auditabilidad: Los equipos deben repasar y explicar las decisiones tomadas anteriormente.
Las arquitecturas por lotes tradicionales tienen dificultades para cumplir estos requisitos. Por el contrario, las arquitecturas de streaming tratan cada registro como un evento inmutable y permiten que los sistemas posteriores reaccionen casi en tiempo real.
Kafka se ha convertido en la columna vertebral de los flujos de trabajo basados en eventos, pero Kafka por sí solo no resuelve la integración con bases de datos. Kafka Connect cubre esta carencia al transferir datos entre las bases de datos y Kafka mediante una configuración en lugar de código personalizado.
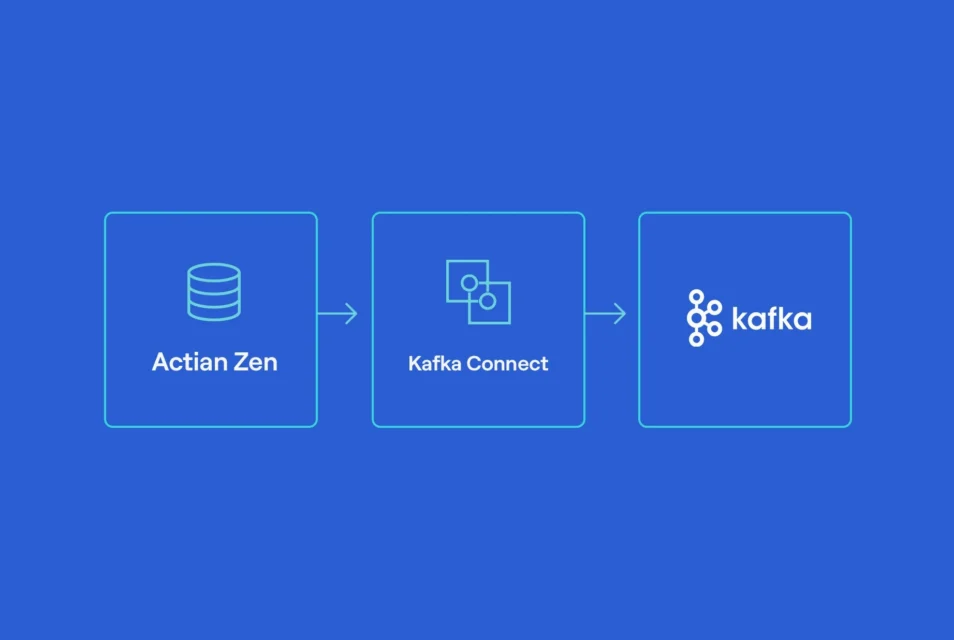
Lo que estamos construyendo
Este proceso muestra cómo se pueden transmitir datos de tipo financiero desde una base de datos Zen operativa a Kafka y, a continuación, volver a escribirlos en una tabla Zen posterior mediante los conectores JDBC Source y Sink:
El proceso es el siguiente:
- Un proceso de Python genera datos sintéticos de cotización.
- Cada entrada se inserta en una tabla de origen Zen (FinanceSource).
- Un conector de origen JDBC de Kafka Connect lee las nuevas filas de forma incremental.
- Los registros se publican en Kafka como mensajes Avro (el Registro de esquemas gestiona los esquemas).
- Un conector de destino JDBC de Kafka Connect procesa el tema.
- Los registros se insertan o actualizan en una tabla de destino de Zen (Finanzas).
Este patrón se aplica directamente a la ingesta de datos de mercado, la replicación de operaciones, el ETL en tiempo real y la elaboración de informes operativos.
Una mirada a la arquitectura
A grandes rasgos, la arquitectura consta de tres capas:
- Generación de datos y almacenamiento operativo: Actian Zen almacena los datos de cotización de las operaciones entrantes.
- Infraestructura de streaming: Kafka proporciona un registro de eventos duradero y reproducible.
- Integración y entrega: Kafka Connect lee desde Zen y escribe de nuevo en Zen.
Un principio clave del diseño es la desacoplamiento: los productores no dependen de los consumidores, y la base de datos sigue siendo el sistema de referencia.
El diseño de modelos de datos en la práctica
El diseño del esquema es fundamental. En esta demostración se utilizan dos tablas Zen con funciones claramente definidas:
Tabla de origen: FinanceSource (solo de adición)
CREATE TABLE FinanceSource ( id IDENTITY PRIMARY KEY, símbolo VARCHAR(16) NOT NULL, fecha_operación DATE NOT NULL, hora_operación TIME NOT NULL, precio DECIMAL(18,6) NOT NULL, volumen INTEGER NOT NULL, oferta DECIMAL(18,6), demanda DECIMAL(18,6), bolsa VARCHAR(16), divisa VARCHAR(8) DEFAULT 'USD', hora_registrada TIMESTAMP NOT NULL );
Hay dos columnas que son especialmente importantes para el streaming:
- id proporciona un cursor incremental estable.
- recorded_at proporciona la hora del evento y permite lecturas incrementales seguras.
Tabla de sumideros: Finanzas (Estado materializado)
CREATE TABLE Finanzas ( id ENTERO CLAVE PRIMARIA, símbolo VARCHAR(16), fecha_operación FECHA, hora_operación HORA, precio DECIMAL(18,6), volumen ENTERO, oferta DECIMAL(18,6), demanda DECIMAL(18,6), bolsa VARCHAR(16), divisa VARCHAR(8), registrado_a TIMESTAMP );
El fregadero utiliza id como clave principal, lo que permite inserciones y actualizaciones idempotentes durante la reproducción o el reinicio.
Generación de ticks bursátiles con Python
El generador simula un flujo de datos del mercado en tiempo real insertando un nuevo registro cada dos segundos. Cada evento incluye el símbolo, el precio, la oferta y la demanda, el volumen, la bolsa, la divisa y las marcas de tiempo.
La función generadora crea datos de mercado realistas:
def gen_tick(): symbol = random.choice(SYMBOLS) price = round(random.uniform(10, 1500), 6) spread = round(random.uniform(0.01, 0.50), 6) bid = round(price - spread/2, 6) ask = round(price + spread/2, 6) vol = random.randint(1, 5000) now = datetime.now() return { "symbol": symbol, "trade_date": date.today(), "trade_time": now.time().replace(microsecond=0), "price": price, "volume": vol, "bid": bid, "ask": ask, "exchange": random.choice(EXCHANGES), "currency": CURRENCY, "recorded_at": now, }
Instrucción INSERT:
sql = """ INSERT INTO FinanceSource ( símbolo, fecha_operación, hora_operación, precio, volumen, oferta, demanda, bolsa, divisa, hora_registro ) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) """
Este enfoque de solo adición encaja perfectamente con Kafka: cada fila es un evento inmutable que puede transmitirse, reproducirse y consumirse por múltiples servicios posteriores.
Transmisión de datos de Zen a Kafka con el conector de origen JDBC
El conector de origen JDBC de Kafka Connect consulta FinanceSource y publica mensajes en Kafka.
Mapa temático:
- Nombre del conector: demo-finance-source
- Prefijo del tema: finanzas.
- Tema: finanzas.FinanceSource
Modo incremental:
"modo": "marca de tiempo + incremento", "nombre_columna_marca_de_tiempo": "recorded_at", "nombre_columna_incremento": "id", "intervalo_sondeo_ms": "2000"
Este modo lee únicamente las filas nuevas, evita los escaneos completos y admite reinicios seguros. La consulta cada dos segundos mantiene baja la latencia sin añadir una carga innecesaria. La consulta cada dos segundos también equilibra la latencia y la carga para cargas de trabajo de demostración y moderadas; en producción, esto debería ajustarse en función de la frecuencia de inserción de filas y la capacidad de la base de datos.
Configuración completa del conector de fuente:
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url": "jdbc:pervasive://host.docker.internal:1583/DEMODATA", "dialect.name": "ZenDatabaseDialect", "mode": "timestamp+incrementing", "timestamp.column.name": "recorded_at", "incrementing.column.name": "id", "table.whitelist": "FinanceSource", "topic.prefix": "finance.", "poll.interval.ms": "2000", "value.converter": "io.confluent.connect.avro.AvroConverter"
Avro y el Registro de esquemas para la gestión de esquemas
Los esquemas financieros evolucionan: aparecen nuevas métricas, nuevos identificadores o ajustes en la precisión. Avro, junto con Schema Registry, ofrece tipado fuerte, control de versiones centralizado y controles de compatibilidad.
Configuración de los conectores:
"value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "http://schema-registry:8081"
Con esta configuración, los esquemas se registran automáticamente y los usuarios pueden evolucionar con seguridad a lo largo del tiempo. El Registro de esquemas solo es necesario cuando se utiliza Avro (o Protobuf/JSON Schema); los convertidores JSON pueden utilizarse para demostraciones más ligeras, a costa de la gestión de esquemas.
De Kafka a Zen con el conector de destino JDBC (Upsert)
El conector Sink lee el tema de Kafka y escribe en la tabla «Finance».
Configuración de Upsert:
"topics": "finance.FinanceSource", "table.name.format": "Finance", "insert.mode": "upsert", "pk.mode": "record_value", "pk.fields": "id", "auto.create": "false", "auto.evolve": "true"
Upsert es una opción muy recomendable porque los reinicios y las reproducciones siguen siendo idempotentes, y las correcciones que llegan más tarde pueden actualizar las claves existentes.
Implementación y orquestación
Todos los componentes de Kafka se ejecutan en Docker: el broker de Kafka, Schema Registry, Kafka Connect y la interfaz de usuario de Kafka (compatible con Kafbat y AKHQ). Actian Zen se ejecuta en el host.
Un único script de orquestación inicia la pila, inicializa las tablas, crea los conectores y pone en marcha el generador. Este modelo de «demostración con un solo comando» resulta útil para la formación, las pruebas de concepto y las pruebas repetibles.
Parámetros que se suelen utilizar durante la validación:
- Interfaz de usuario de Kafbat: http://localhost:8080
- Kafka Connect REST: http://localhost:8083
- Registro de esquemas: http://localhost:8081
Validación operativa
Para validar el flujo de principio a fin:
- Comprueba que el generador genere nuevos ticks cada dos segundos.
- Comprueba el estado del conector a través de Kafka Connect REST.
- Revisar los mensajes en la tema finance.FinanceSource .
- Consultar la tabla de sumideros de Zen Finanzas.
Llamadas de estado:
curl http://localhost:8083/connectors/demo-finance-source/status curl http://localhost:8083/connectors/demo-finance-sink/status
Si algo falla, los registros de Kafka Connect suelen ser la señal más rápida: archivos JAR de JDBC que faltan, problemas con el dialecto o dificultades de autenticación.
Aspectos relacionados con la producción
Esta demostración es deliberadamente sencilla, pero la arquitectura se adapta bien a la escalabilidad. En el entorno de producción, ten en cuenta lo siguiente:
- TLS y autenticación para Kafka y Connect.
- División de temas para el paralelismo (por ejemplo, por símbolo).
- Colas de mensajes no entregados para registros problemáticos.
- Aplicación de la compatibilidad de esquemas en el Registro de esquemas.
- Clústeres Multi-worker Connect para mayor rendimiento y resiliencia.
- Supervisión (Prometheus/Grafana).
El patrón básico —fuente de solo adición + sondeo incremental + Avro + inserciones y actualizaciones idempotentes en el destino— sigue siendo una sólida referencia.
Haz un recorrido visual
Las siguientes capturas de pantalla muestran el flujo de trabajo en acción, desde la generación de datos a través de Kafka hasta la tabla de destino final:
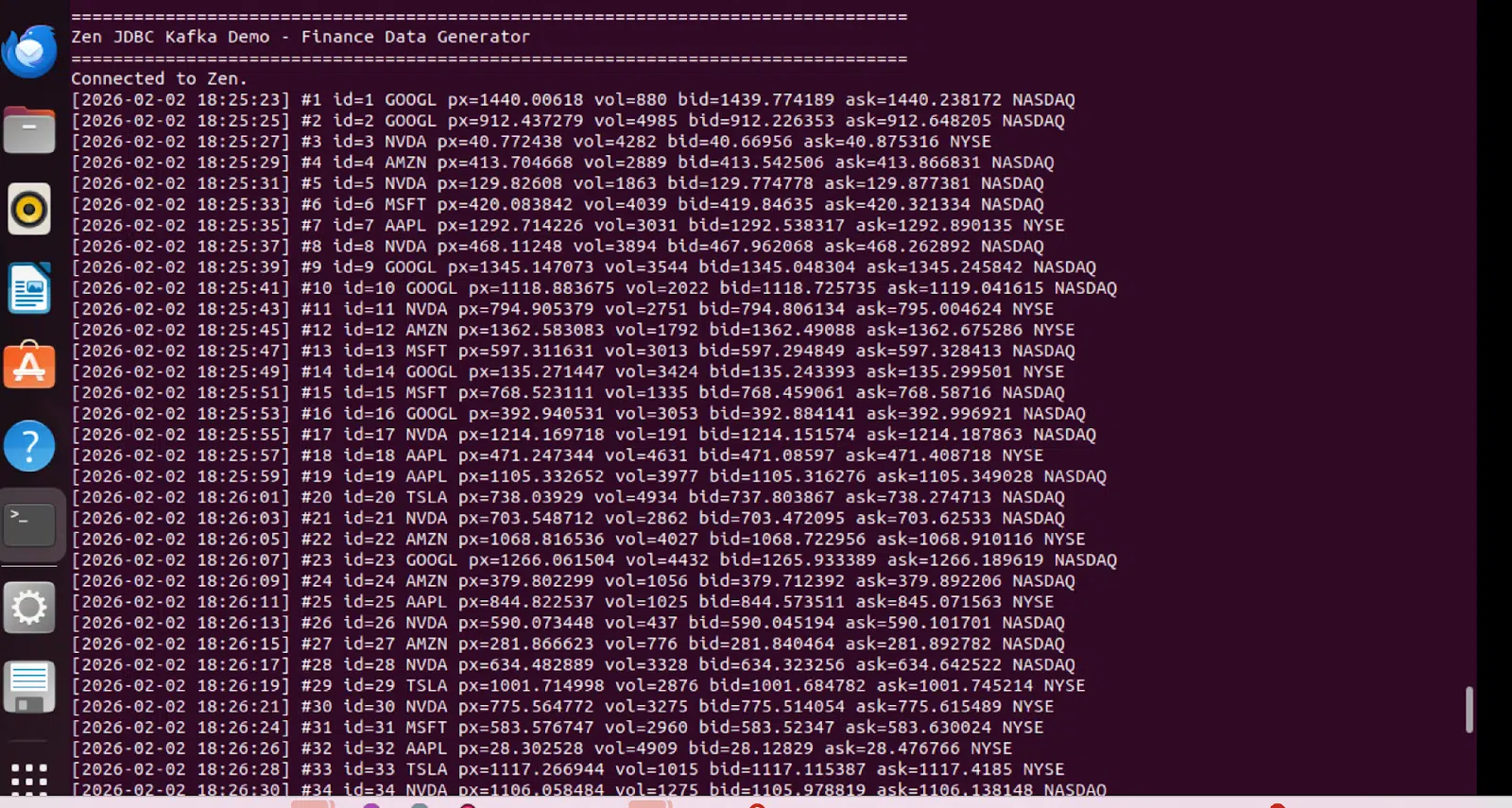
Salida del generador de datos
El generador de Python produce continuamente datos sintéticos de cotización cada dos segundos, simulando datos de mercado en tiempo real:
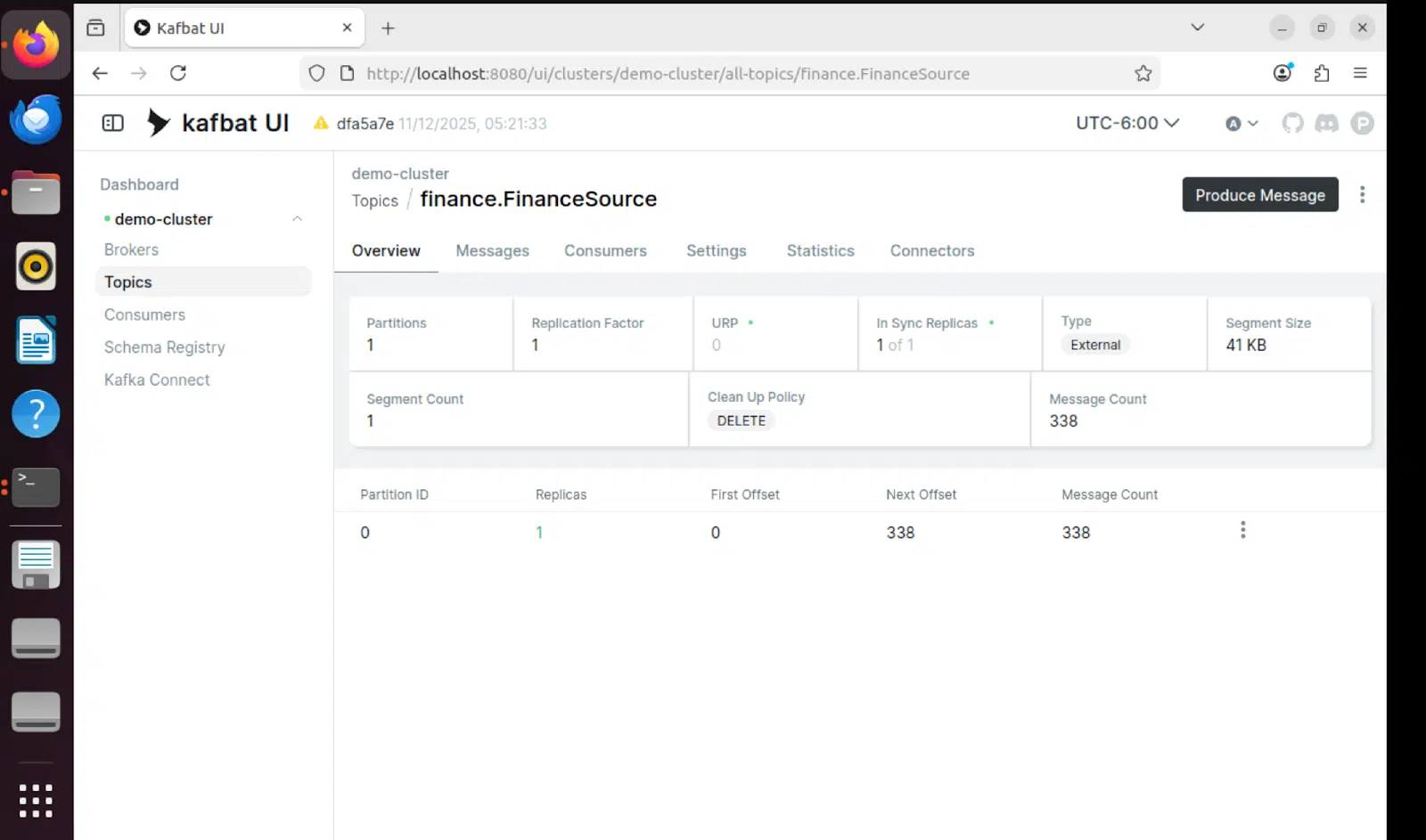
Interfaz de usuario de Kafbat: vista de temas
La interfaz de usuario de Kafbat ofrece una visión en tiempo real de los temas de Kafka, mostrando los mensajes que circulan por el canal:
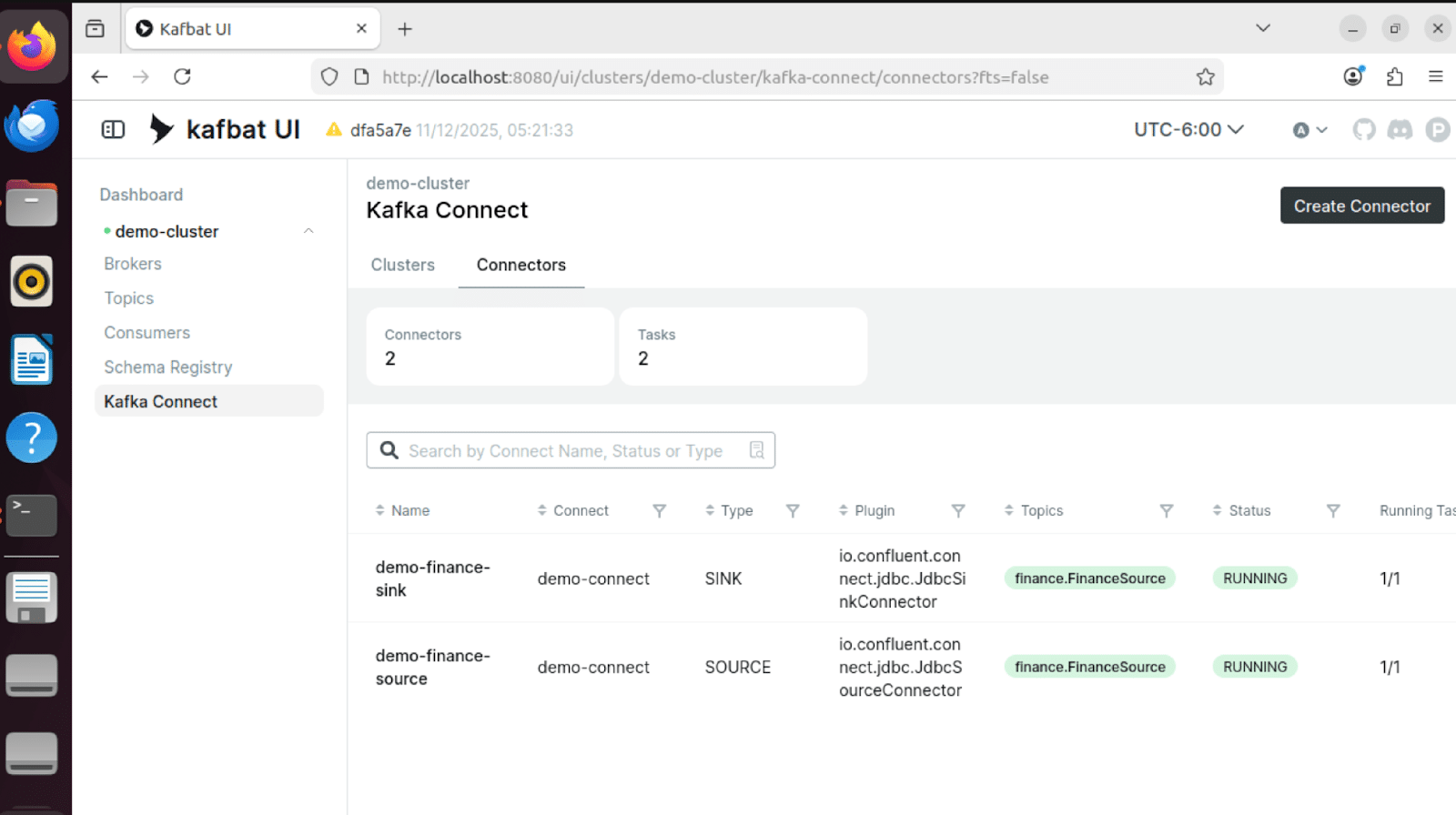
Estado del conector
Tanto el conector de origen como el de destino muestran el estado «RUNNING», lo que confirma que el canal está operativo:
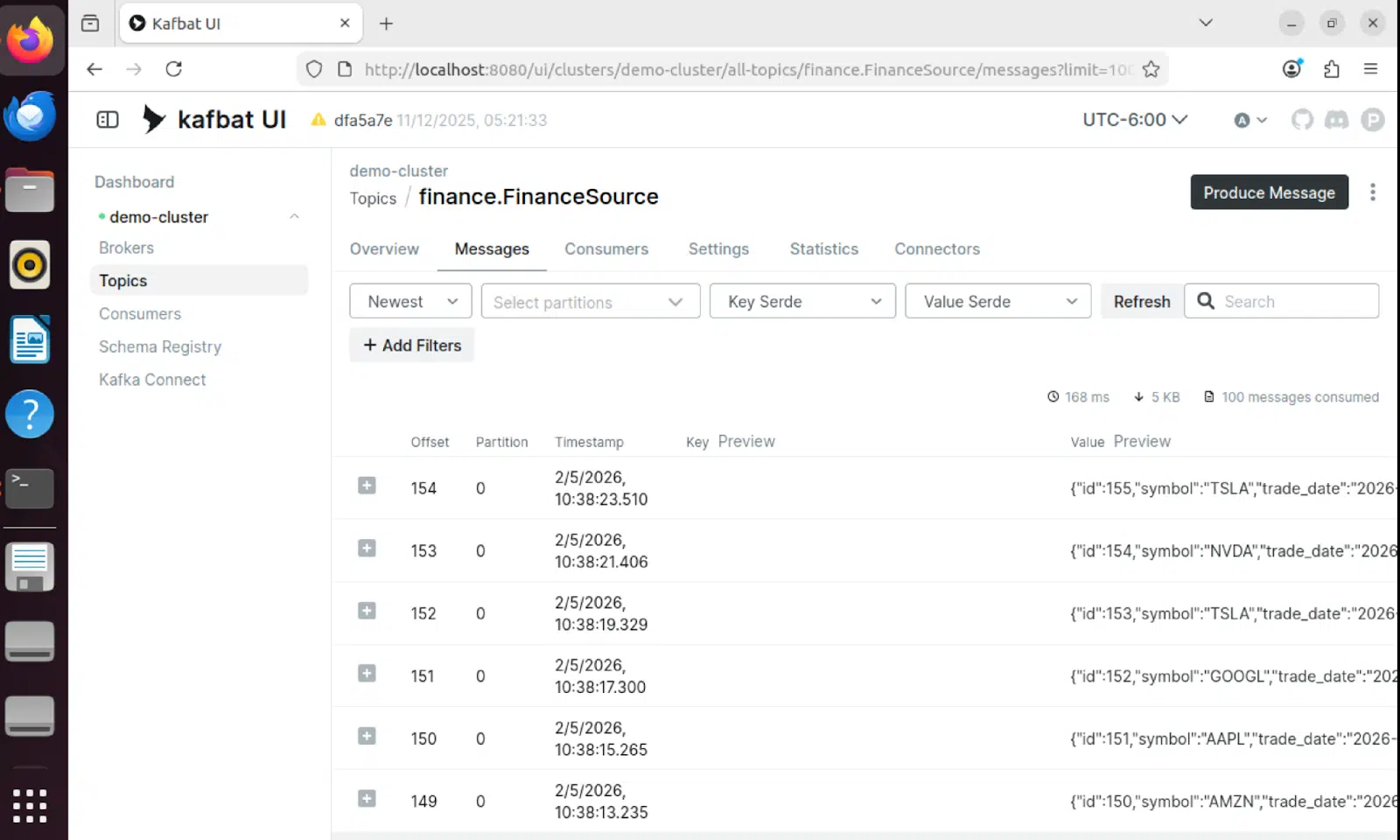
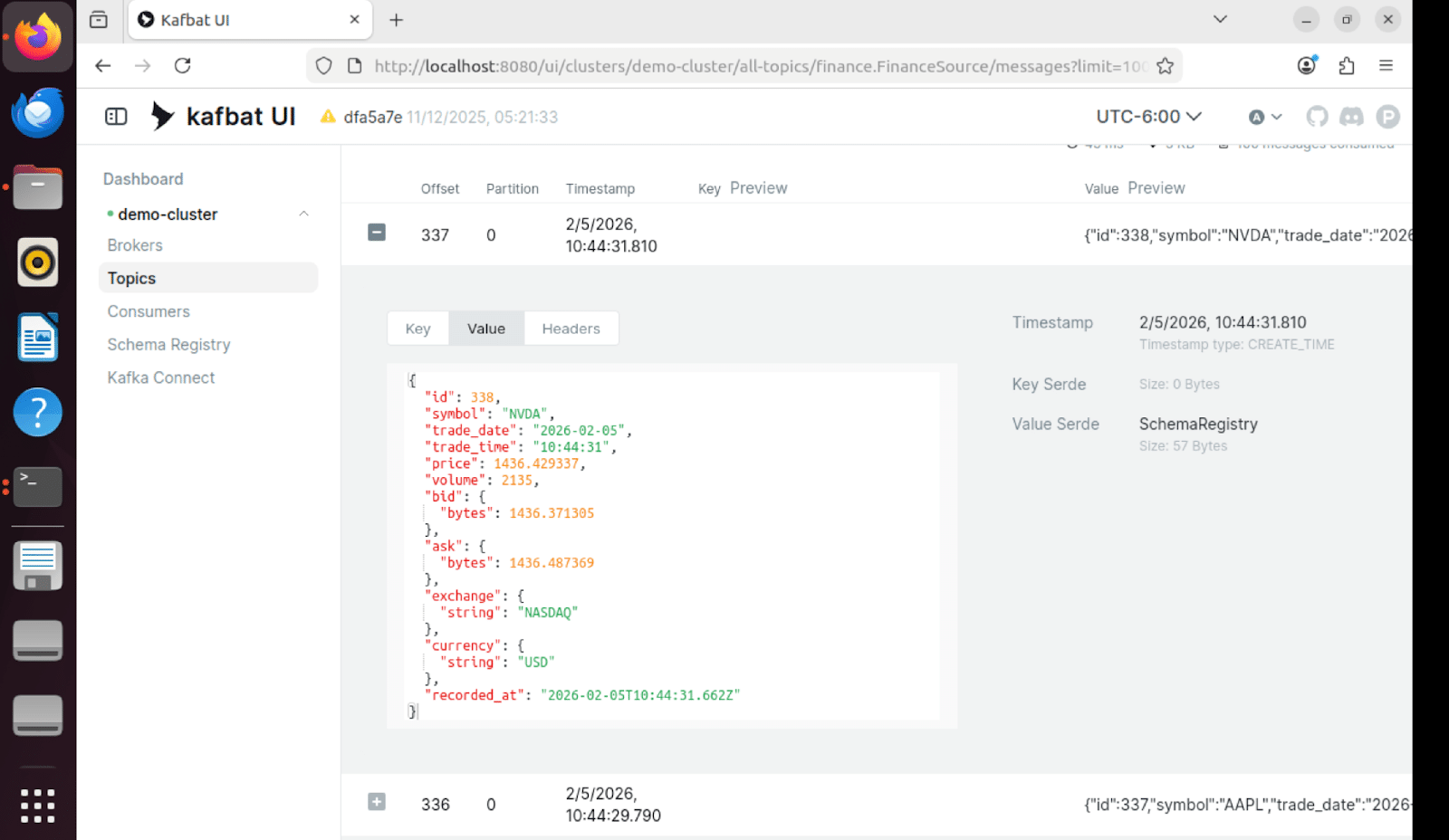
Contenido del mensaje
Los mensajes individuales en Kafka contienen los datos completos de las cotizaciones bursátiles en formato Avro con control de versiones del esquema:
Resultados de la tabla de sumideros
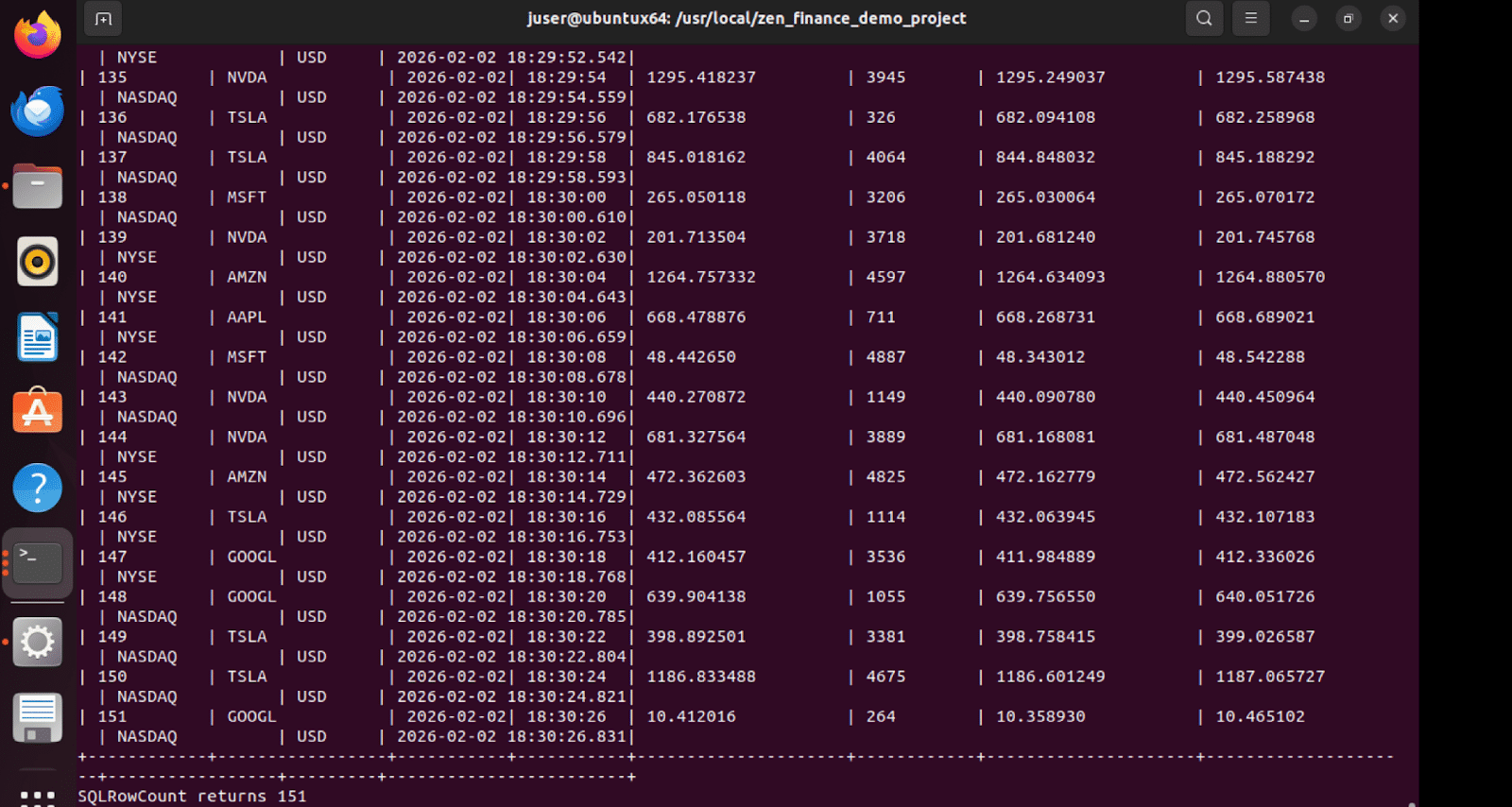
La tabla de sumideros de Finanzas en Zen recibe los datos transmitidos, lo que demuestra que el flujo de extremo a extremo se ha realizado correctamente.
Primeros pasos
La demostración incluye un completo script de orquestación que automatiza todo el proceso de configuración. Para ejecutar la demostración, basta con ejecutar un único script de Python.
Demostración de One-Command
El orquestador gestiona automáticamente cinco pasos clave:
- Iniciar la pila de Docker Compose (Kafka, Schema Registry, Connect, interfaz de usuario).
- Espera a que todos los servicios vuelvan a estar operativos (entre 45 y 60 segundos).
- Inicializar las tablas FinanceSource y Finance en Zen.
- Crear y configurar conectores de origen y destino JDBC.
- Ejecuta el generador de datos en segundo plano.
Lógica central de orquestación:
def run(self): # Paso 1: Iniciar Docker Compose self.start_docker_compose() # Paso 2: Esperar a que se inicien los servicios self.wait_for_services() # Paso 3: Inicializar bases de datos self.initialize_databases() # Paso 4: Configurar conectores self.setup_connectors() # Paso 5: Iniciar generador de datos self.start_data_generator() # Mostrar estado y continuar ejecutando self.show_status()
El script ofrece información clara sobre el estado en cada paso y se encarga de la limpieza en caso de interrupción (Ctrl+C).
Inicialización de la tabla
El script de inicialización crea ambas tablas con los esquemas adecuados y elimina las tablas existentes para garantizar un estado limpio:
def create_finance_source(conn): exec_sql(conn, "DROP TABLE IF EXISTS FinanceSource") create_sql = """ CREATE TABLE FinanceSource ( id IDENTITY PRIMARY KEY, symbol VARCHAR(16) NOT NULL, trade_date DATE NOT NULL, trade_time TIME NOT NULL, price DECIMAL(18,6) NOT NULL, volume INTEGER NOT NULL, bid DECIMAL(18,6), ask DECIMAL(18,6), exchange VARCHAR(16), currency VARCHAR(8) DEFAULT 'USD', recorded_at TIMESTAMP NOT NULL ) """ exec_sql(conn, create_sql)
Crea y saca partido de un proceso financiero en tiempo real
Esta solución muestra una forma práctica de crear un canal de datos financieros en tiempo real con Actian Zen y Kafka Connect:
- Zen almacena los registros operativos y sigue siendo el sistema de referencia.
- Kafka proporciona un flujo duradero y reproducible.
- Kafka Connect transfiere datos de forma fiable mediante su configuración.
- Avro y el Registro de esquemas garantizan la seguridad de los esquemas.
- La tabla de sincronización proporciona un estado materializado que se puede consultar.
Para las organizaciones que están modernizando sus flujos de datos financieros, esta arquitectura ofrece una vía clara para pasar del procesamiento por lotes a diseños centrados en el streaming sin tener que renunciar a las inversiones ya realizadas en bases de datos.
Lee más en nuestro blog serie , que se centra en ayudar a los desarrolladores de aplicaciones integradas a dar sus primeros pasos con Actian Zen.

Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)