El coste oculto de los modelos de precios de bases de datos vectoriales





Resumen
- Los precios «basados en el uso» de Vector DB ahora incluyen mínimos mensuales, lo que convierte las cargas de trabajo constantes en aumentos repentinos de los costes.
- Los costes ocultos (incrustaciones, reclasificación, copias de seguridad, reindexación y salida) pueden duplicar el gasto real de producción.
- Los costes de las consultas suelen variar en función del tamaño del índice, por lo que la misma búsqueda puede costar 10 veces más si los datos pasan de 10 GB a 100 GB.
- Con un volumen de consultas elevado y predecible, el autoalojamiento puede reducir los costes entre un 50 % y un 75 % y mejorar la previsibilidad del gasto.
- Elige los modelos de precios desde el principio: los mecanismos de facturación deben influir en la arquitectura, no sorprenderte después del lanzamiento.
Durante mucho tiempo, los precios basados en el uso parecían la forma más segura de gestionar una nueva infraestructura. El atractivo residía en empezar poco a poco, pagar muy poco y dejar que los costes aumentaran solo si el producto demostraba su eficacia. Para los equipos que experimentaban con la búsqueda semántica o los primeros sistemas de recuperación, esa compensación tenía sentido, sobre todo cuando los compromisos de infraestructura fija parecían más arriesgados que los patrones de uso inciertos.
Esa sensación de seguridad comenzó a desvanecerse en 2025, cuando varios proveedores de bases de datos vectoriales introdujeron precios mínimos y límites mínimos. Pinecone anunció un mínimo de 50 dólares al mes, Weaviate implementó un precio mínimo de 25 dólares al mes y cambios similares se extendieron por todo el mercado de bases de datos vectoriales gestionadas.
Las cargas de trabajo pequeñas y constantes experimentaron de repente cambios radicales en los costes sin el correspondiente aumento de la actividad, un patrón que reflejaba un cambio más amplio en el panorama del SaaS. La infraestructura de bases de datos vectoriales siempre activa ya no se ajusta a la economía de los precios mensuales de un solo dígito. Los costes de suscripción al SaaS de varios grandes proveedores aumentaron entre un 10 % y un 20 % en 2025, superando las previsiones de crecimiento del presupuesto de TI del 2,8 %, según Gartner.
Hoy en día, las bases de datos vectoriales impulsan los sistemas de producción a gran escala. Ejecutan búsquedas semánticas, recomendaciones, copilotos y herramientas de conocimiento interno. Los volúmenes de datos se mantienen relativamente estables y los patrones de tráfico siguen curvas predecibles. Sin embargo, para muchas organizaciones, la infraestructura de búsqueda vectorial se ha convertido en uno de los centros de costes más volátiles de la pila. No porque el uso varíe enormemente, sino porque los modelos de precios de las bases de datos vectoriales se comportan de manera diferente una vez que los sistemas maduran.
TL;DR
- Los precios de las bases de datos vectoriales nativas en la nube anuncian mínimos bajos y flexibilidad basada en el uso, pero los costes de producción cuentan una historia diferente.
- Las tarifas ocultas (incrustaciones, reindexación, copias de seguridad) pueden duplicar su factura.
- Los costes de las consultas varían en función del tamaño del conjunto de datos, lo que significa que la misma consulta se vuelve 10 veces más cara al pasar de 10 GB a 100 GB.
- El cambio de precios de octubre de 2025 introdujo mínimos de 50 dólares, lo que obligó a aumentar los costes entre un 400 % y un 500 % para las cargas de trabajo estables.
- Con entre 60 y 100 millones de consultas al mes, el autoalojamiento resulta entre un 50 % y un 75 % más barato que la nube.
- El modelo de precios debe ser una decisión arquitectónica, no una idea de último momento.
Lo que las páginas de precios omiten
Las páginas de precios de las bases de datos vectoriales dan prioridad a la adopción frente a los modelos de costes a largo plazo. Su función es facilitar la adopción, no explicar cómo se calcula la factura una vez que el sistema está en funcionamiento. La mayoría de las páginas destacan un conjunto de cifras familiares: almacenamiento por gigabyte, unidades de lectura y escritura, y un mínimo mensual bajo. Los niveles gratuitos se comercializan como suficientes para empezar, lo que hace que la experimentación parezca de bajo riesgo.
Lo que estas páginas rara vez explican es cómo interactúan esos elementos una vez que el uso se estabiliza. Por lo general, no modelan cómo cambian los costes de las consultas a medida que crecen los conjuntos de datos, cómo se acumula la actividad de escritura con el tiempo o cómo partes significativas del flujo de trabajo se sitúan completamente fuera de la base de datos. Los ejemplos de precios de Pinecone excluyen la importación inicial de datos, la inferencia para incrustaciones y reclasificación, y el uso del asistente. La calculadora de precios de Weaviate omite de manera similar los costes de copia de seguridad y las tarifas de salida de datos. Las estimaciones de Qdrant no tienen en cuenta los gastos generales de reindexación. Los mismos proveedores que dominan todas las listas comparativas se enfrentan ahora a preguntas sobre la sostenibilidad de sus precios. Estas advertencias están presentes, pero es fácil pasarlas por alto cuando se está centrado en enviar una prueba de concepto.
Se repite un patrón predecible. Alguien utiliza la calculadora y establece un presupuesto mensual. El sistema entra en funcionamiento. Unas semanas más tarde, la factura es entre dos y cuatro veces superior a lo esperado. No se ha roto nada, no se ha producido ningún pico de tráfico. La base de datos está haciendo exactamente lo que se diseñó para hacer. La página de precios simplemente no describía el coste total de su funcionamiento.
Cómo funciona la tarificación basada en el uso (y por qué resulta cara)
Los precios basados en el uso reducen el riesgo durante la experimentación cuando se desconoce el tráfico. El problema es que las bases de datos vectoriales en producción rara vez son impredecibles.
Una vez que el sistema está en funcionamiento, la mayoría de los grupos de ingeniería tienen un conocimiento razonable del tamaño de los datos y del volumen de consultas de referencia. Lo que les falta es una forma fiable de predecir la factura del mes siguiente, ya que las bases de datos vectoriales gestionadas cobran simultáneamente por varios conceptos: almacenamiento, escrituras y consultas.
Cada coste crece según su propia curva y ninguno se corresponde claramente con el valor para el usuario. La parte que pilla desprevenidos a los equipos de desarrollo es el precio de las consultas. En muchos modelos, el coste de las consultas aumenta a medida que crece el conjunto de datos, incluso cuando la consulta en sí misma sigue siendo la misma.
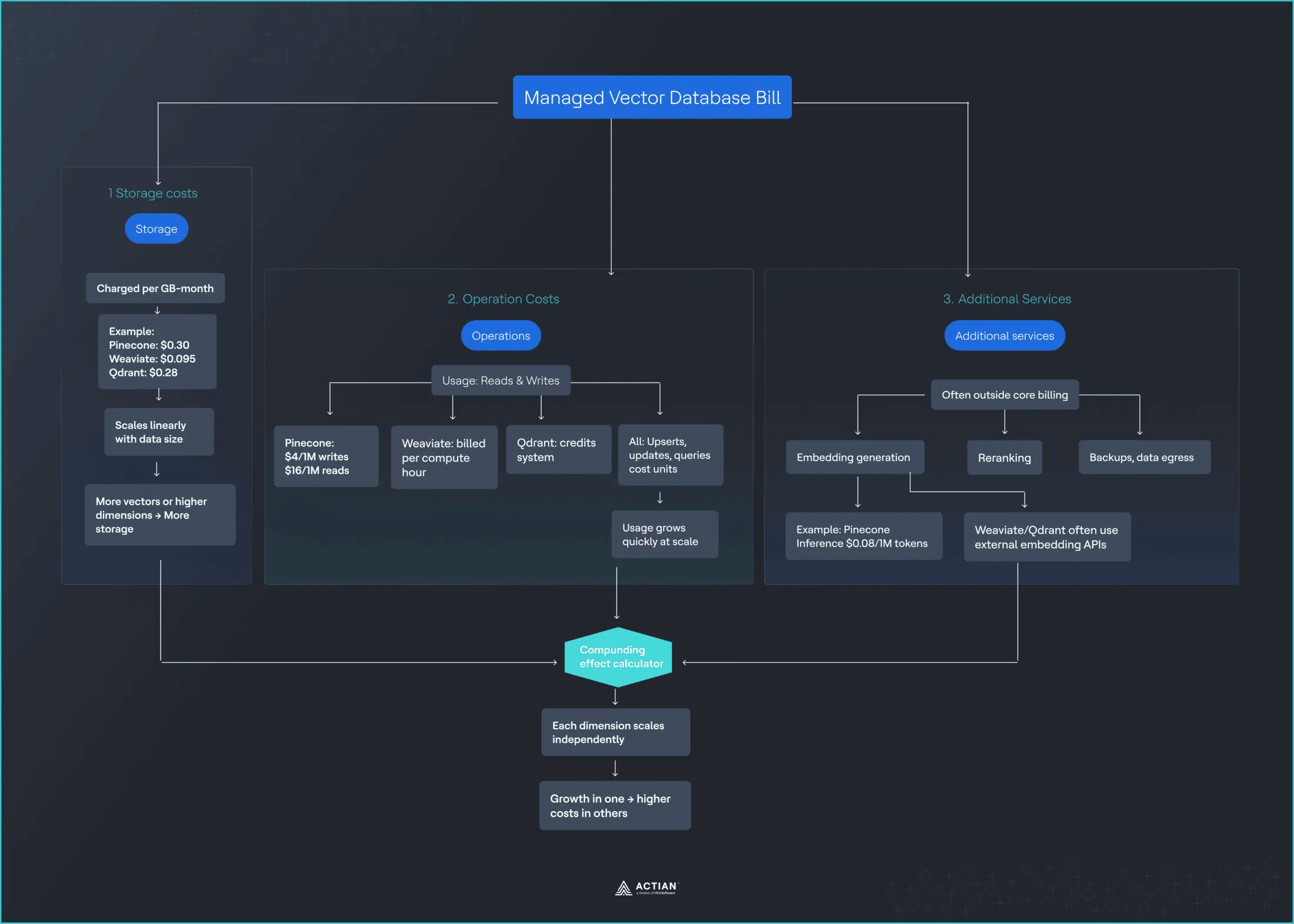
Los tres factores que realmente influyen en los costes que usted paga
Las bases de datos vectoriales gestionadas se facturan en función de tres dimensiones principales, aunque las tarifas exactas varían según el proveedor:
Almacenamiento
- Pinecone: 0,30 $/GB/mes.
- Weaviate: 0,095 $/GB/mes.
- Qdrant: 0,28 $/GB/mes.
- Se escala linealmente a medida que crece su conjunto de datos.
- Más dimensiones vectoriales = factura más elevada.
Operaciones
- Pinecone: Unidades de escritura (4 $/millón), unidades de lectura (16 $/millón).
- Weaviate: Por hora de unidad de cómputo (variable).
- Qdrant: Sistema basado en créditos.
- Cada upsert, actualización y consulta consume unidades.
- Las operaciones de búsqueda vectorial se acumulan rápidamente a gran escala.
Servicios adicionales
- Generación de incrustaciones: Pinecone Inference (0,08 $/millón de tokens).
- Weaviate/Qdrant: Requiere servicios externos (OpenAI, Cohere).
- El reordenamiento, las copias de seguridad y la transferencia de datos se facturan por separado.
- Añade otra relación con un proveedor y otra fuente de costes.
Cada dimensión de coste se escala de forma independiente, y su interacción crea efectos compuestos que las calculadoras de precios rara vez captan. Para comprender por qué estos costes se acumulan, es necesario analizar cómo funciona realmente la búsqueda vectorial, concretamente la indexación HNSW.
¿Por qué los costes se acumulan a medida que crece?
El aumento de los costes se deriva directamente del funcionamiento interno de la búsqueda vectorial.
Cómo funciona HNSW
La mayoría de las bases de datos vectoriales de producción utilizan algoritmos de vecino más cercano aproximado (ANN), como HNSW (Hierarchical Navigable Small World), para facilitar las búsquedas a gran escala.
HNSW construye un gráfico multicapa en el que cada capa representa vectores con diferentes niveles de granularidad, organizando así millones de dimensiones vectoriales en una estructura eficiente.
El impacto en los costes
La documentación de Pinecone indica que una consulta consume 1 RU por cada 1 GB de tamaño del espacio de nombres, con un mínimo de 0,25 RU por consulta. A medida que crece su conjunto de datos, también lo hace el gráfico:
| Tamaño del conjunto de datos | RU por consulta | Coste: 16 $/M RU | La misma consulta, un coste diferente |
|---|---|---|---|
| 10 GB | 10 RU | $0.00016 | Línea de base |
| 100 GB | 100 RU | $0.0016 | 10 veces más caro |
| 1 TB | 1000 RU | $0.016 | 100 veces más caro |
Resultado: Diez veces el coste, para la misma consulta, con la misma calidad de resultados.
A 16 dólares por millón de unidades leídas, los costes aumentan de forma lineal con el crecimiento de los datos, pero la funcionalidad que se ofrece a los usuarios sigue siendo la misma. Una consulta de búsqueda devuelve el mismo número de resultados con la misma precisión, independientemente de si su índice es de 10 GB o de 100 GB. Sus usuarios no notan ninguna diferencia, pero usted paga 10 veces más. Este es el momento en el que el crecimiento empieza a parecer una penalización. La estructura del gráfico necesita atravesar más dimensiones vectoriales a medida que su índice se expande, y usted paga por cada operación adicional.
El nivel gratuito que no es realmente gratuito
El nivel gratuito permite realizar pruebas iniciales, pero no predice la economía de la producción. Cuando se alcanzan los límites, los costes de cambio ya no son teóricos. La migración se percibe como cara y la gente acepta precios que antes habría cuestionado.
| Proveedor | Límites del nivel gratuito | Realidad de la producción | Es hora de superar |
|---|---|---|---|
| Piña | 2 GB, 1 millón de lecturas, 2 millones de escrituras (una sola región) | Más de 60 GB, más de 5 millones de lecturas típicas | 2-4 semanas |
| Weaviate | 1 millón de vectores, computación limitada | Más de 10 millones de vectores estándar | 1-3 semanas |
| Cuadrante | 1 GB de almacenamiento | Más de 60 GB de almacenamiento común | 1-2 semanas |
El cambio de precios de octubre de 2025 que lo cambió todo
Estos problemas estructurales se hicieron imposibles de ignorar cuando Pinecone realizó un cambio significativo en sus precios. A finales de 2025, los cambios en los precios de los principales proveedores de bases de datos vectoriales dejaron claro que el modelo de pago por uso (PAYG) no siempre se mantenía una vez que los sistemas alcanzaban una producción estable. La señal más visible llegó en octubre, cuando Pinecone implementó un mínimo mensual de 50 dólares en todos los planes Standard de pago.
Para las organizaciones que ya gastaban bastante más que eso, el cambio apenas se notó. Para cargas de trabajo más pequeñas pero estables, la situación era diferente. Algunos grupos habían diseñado intencionadamente su uso para mantenerse por debajo de los 10 dólares al mes.
No se trataba de proyectos abandonados, sino de herramientas internas, funciones de producción iniciales y sistemas de bajo volumen orientados al cliente que ya se habían estabilizado. El uso se mantuvo estable, pero en algunos casos la introducción de precios mínimos provocó un aumento de entre cinco y diez veces en los costes mensuales.
Lo que hizo que ese momento fuera importante no fue la cantidad en dólares. Fue la introducción de un mínimo fijo en un modelo comercializado como basado en el consumo. El bajo uso ya no garantizaba un bajo coste. Una vez que se rompió esa suposición, los mínimos dejaron de parecer un caso excepcional y empezaron a parecer un riesgo estructural.
| Coste mensual anterior | Nuevo mínimo | Aumentar |
|---|---|---|
| $8 | $50 | 525% |
| $12 | $50 | 317% |
| $25 | $50 | 100% |
La migración forzada
Para cualquiera que estuviera por debajo del nuevo mínimo de 50 dólares, la migración rara vez se planificaba. Era reactiva. Los propietarios de las plataformas tenían que evaluar alternativas, exportar datos, reconstruir índices y validar el comportamiento de las consultas bajo la presión del tiempo. En algunos casos, el esfuerzo de ingeniería necesario para la migración superaba el ahorro anual que suponía el cambio de proveedor. Muchos siguieron adelante de todos modos, porque la alternativa era comprometerse con unos precios que ya no se ajustaban a la carga de trabajo.
El impacto del cambio en los precios se hizo evidente en todas las comunidades de desarrolladores. Uno de ellos documentó públicamente su experiencia de migración y señaló que había logrado mantener las facturas por debajo de los 10 dólares al mes almacenando solo los datos esenciales en la base de datos vectorial. El anuncio de septiembre de 2025, que exigía un mínimo de 50 dólares al mes independientemente del uso real, provocó una búsqueda inmediata de alternativas.
El cálculo de la migración resultó ser todo un reto. Se optó por pasar a Chroma Cloud, pero el proceso reveló preocupaciones más profundas sobre los modelos de precios sin servidor. Como señaló el desarrollador, buscaban una solución verdaderamente sin servidor en la que los costes se escalaran linealmente con el uso, empezando por 0 dólares. El mínimo de 50 dólares eliminó esa posibilidad.
Este patrón se repitió en los hilos de Reddit y los foros de desarrolladores. Un hilo de debate titulado «El nuevo mínimo de 50 $ al mes de Pinecone acaba de acabar con mi proyecto aficionado» capturó el sentimiento general. Los equipos que gestionaban cargas de trabajo de producción estables y de bajo volumen se enfrentaban a una elección: aceptar un aumento de costes del 400-500 % o invertir tiempo de ingeniería en la migración.
El problema no era la cantidad absoluta en dólares. Para muchos equipos, 50 dólares al mes seguía siendo asequible. El problema era el precedente. Si un proveedor podía introducir un mínimo que quintuplicaba los costes sin previo aviso, ¿qué impedía futuros aumentos? El cambio en los precios transformó la selección de proveedores de una decisión técnica a un cálculo de gestión de riesgos.
Algunos patrones se repitieron en todas estas migraciones. La previsibilidad de los precios comenzó a ser más importante que la comodidad gestionada. Las opciones de código abierto y autohospedadas volvieron a entrar en las discusiones que anteriormente se habían centrado en la nube. El riesgo de los precios de los proveedores se convirtió en una preocupación arquitectónica de primer orden. Estas migraciones no fueron impulsadas por la insatisfacción con las características o el rendimiento. Fueron impulsadas por motivos económicos.
Lo que revela sobre el poder de fijación de precios de los proveedores
Una vez que se implementa una base de datos vectorial en producción, los proveedores pueden ajustar los precios de manera que afecte significativamente a los clientes, incluso si el uso permanece sin cambios.
Los precios basados en el uso reducen las barreras para la adopción, pero aumentan los costes de cambio con el tiempo, a medida que las API se integran, los formatos de datos se consolidan y las migraciones se vuelven más costosas.
En el caso del liderazgo en ingeniería, la pregunta de evaluación cambia:
- Era: «¿Cuánto cuesta esto hoy?»
- Se convirtió en: «¿En qué medida estamos expuestos a los cambios de precios una vez que esto entre en producción?».
Escenarios de costes reales (lo que realmente pagará)
Entender estas dinámicas en abstracto es una cosa. Ver cómo se desarrollan en los sistemas de producción reales es otra.
Para tener una visión completa, examinemos tres escenarios de producción habituales y comparemos los costes de los principales proveedores.
Escenario 1: Sistema RAG de atención al cliente
Imagina un asistente de atención al cliente basado en tickets históricos, documentación interna y artículos de ayuda. En esta fase, es posible que tengas que gestionar unos 10 millones de vectores (normalmente de 768 o 1536 dimensiones vectoriales) y alrededor de cinco millones de consultas al mes.
| Coste mensual anterior | Nuevo mínimo | Aumentar |
|---|---|---|
| $8 | $50 | 525% |
| $12 | $50 | 317% |
| $25 | $50 | 100% |
Conclusión principal: Incluso a pequeña escala, los costes reales son entre 3 y 5 veces superiores a las estimaciones de la calculadora básica debido a los mínimos y a las complejas estructuras de precios.
Escenario 2: Motor de recomendaciones para comercio electrónico
A medida que los sistemas crecen, la dinámica de los costes se hace más pronunciada. Con alrededor de 100 millones de vectores y decenas de millones de consultas al mes, los costes aumentan rápidamente. Los catálogos de productos, las incrustaciones de vectores de usuarios y la personalización en tiempo real introducen un tráfico sostenido y actualizaciones frecuentes.
| Proveedor | Almacenamiento | Consultas | Escribe | Incrustaciones | Gastos generales | Total |
|---|---|---|---|---|---|---|
| Piña | $180 | $192 | $8 | 200-300 dólares | 50-80 dólares | 1500-2500 dólares |
| Weaviate | $57 | Cálculo: 800-1000 dólares | Incluido | 200-300 dólares | 40-60 dólares | 1400-2200 dólares |
| Cuadrante | $168 | Créditos: 600-900 dólares | Incluido | 200-300 dólares | 40-60 dólares | 1300-2100 dólares |
Conclusión clave: A mediana escala, los costes convergen entre los distintos proveedores. Las tarifas de integración suelen superar los costes básicos de la base de datos.
Escenario 3: Plataforma SaaS multitenant
La economía cambia drásticamente a escala empresarial. Con 500 millones de vectores y 100 millones de consultas al mes, los precios basados en el uso se vuelven estructurales. Estos grandes conjuntos de datos contienen incrustaciones de vectores de alta dimensión de muchos clientes.
| Proveedor | Almacenamiento | Consultas | Escribe | Incrustaciones | Asistencia | Total |
|---|---|---|---|---|---|---|
| Piña | $921 | $1,200 | 100-150 dólares | 500-700 dólares | 300-500 dólares | 2500-4000 $ o más |
| Weaviate | $292 | Cálculo: 2000-3000 dólares | Incluido | 500-800 dólares | 200-400 dólares | 3000-4500 dólares |
| Cuadrante | $860 | Créditos: 1500-2200 dólares | Incluido | 500-800 dólares | 200-400 dólares | 2900-4200 dólares |
Conclusión clave: A escala empresarial, los costes anuales alcanzan entre 30 000 y 54 000 dólares. Es aquí donde la economía del autoalojamiento resulta atractiva.
Comparación de proveedores lado a lado
Para aclarar los aspectos económicos, a continuación se muestra cómo se comparan los principales proveedores de bases de datos vectoriales en las dimensiones más importantes para las implementaciones de producción:
| Característica | Piña | Weaviate | Cuadrante | PostgreSQL + pgvector |
|---|---|---|---|---|
| Modelo de precios | Basado en el uso | Basado en el uso | Basado en el uso | Autoalojado (fijo) |
| Mínimo mensual | $50 | $25 | Ninguno | Ninguno |
| Coste de almacenamiento | 0,30 $/GB | 0,095 $/GB | 0,28 $/GB | Solo coste del hardware |
| Consulta de precios | Escalas con datos | Basado en la computación | Basado en el crédito | Libre dentro de la capacidad |
| Coste adicional | Muchos | Moderado | Algunos | Ninguno |
| Previsibilidad de los costes | Bajo | Bajo-Medio | Medio | Alta |
| Coste del escenario 1 | 350-500 dólares | 300-400 dólares | 280-380 dólares | ~200-300 dólares |
| Coste del escenario 2 | 1500-2500 dólares | 1400-2200 dólares | 1300-2100 dólares | ~800-1200 dólares |
| Coste del escenario 3 | 2500-4000 $ o más | 3000-4500 dólares | 2900-4200 dólares | ~1500-2000 dólares |
| Ideal para | Prototipado rápido | Búsqueda híbrida | Equipos nativos de K8s | Estable, gran volumen |
Las tarifas ocultas que no aparecen en la calculadora
Estos escenarios revelan un patrón constante: los precios anunciados rara vez reflejan el coste total. Los sistemas de búsqueda vectorial de producción incurren en costes que rara vez se modelan de forma exhaustiva en las calculadoras. Comprender estos costes ocultos es fundamental para elaborar presupuestos precisos.
Tarifas de incrustación e inferencia
Pinecone Inference cobra 0,08 dólares por cada millón de tokens por generar incrustaciones vectoriales. Weaviate y Qdrant no ofrecen servicios de incrustación nativos, por lo que es necesario recurrir a proveedores externos como OpenAI (a partir de 0,10 dólares por cada millón de tokens) o Cohere.
La conversión de documentos a vectores tiene un coste adicional más allá de las operaciones de base de datos en todas las plataformas. La reclasificación añade tarifas adicionales por solicitud. Cohere-rerank-v3.5 no ofrece solicitudes gratuitas en ningún nivel, lo que significa que se factura cada operación de reclasificación.
Estos costes de incrustación e inferencia pueden igualar o superar el coste de la propia base de datos, dependiendo de la rotación de datos y los patrones de consulta. Cada vez que se generan nuevas incrustaciones vectoriales o se actualizan las existentes, se paga un coste adicional al coste básico de almacenamiento vectorial.
Costes de reindexación (el asesino silencioso)
El impacto en los costes se vuelve especialmente grave cuando es necesario cambiar de enfoque. Al cambiar los modelos de incrustación, es necesario volver a vectorizar todos los datos. Para un conjunto de datos de 100 millones de vectores, esto podría significar:
- Costes de integración: entre 8000 y 15 000 dólares por única vez.
- Aumento de las unidades de escritura durante la migración.
- Tiempo de procesamiento y sobrecarga computacional.
La experimentación con modelos se vuelve prohibitivamente costosa, lo que crea un bloqueo en las opciones de incrustación iniciales. El coste de generar incrustaciones vectoriales a gran escala hace que sea arriesgado mejorar el sistema.
El impuesto de apoyo
Los niveles de asistencia técnica suponen un coste significativo para todos los proveedores gestionados. Los niveles de asistencia técnica de Pinecone van desde foros comunitarios gratuitos hasta 499 $ al mes por cobertura 24/7. Weaviate cobra 500 $ al mes por su nivel de asistencia técnica profesional. La asistencia técnica empresarial de Qdrant tiene un precio similar.
| Nivel | Piña | Weaviate | Cuadrante |
|---|---|---|---|
| Gratis | Solo para la comunidad | Solo para la comunidad | Solo para la comunidad |
| Desarrollador | 29 $ al mes | N/A | N/A |
| Pro/Empresa | 499 $ al mes | 500 $ al mes | Personalizado |
Costes de distribución geográfica
La implementación multirregional para optimizar la latencia aumenta los costes de transferencia de datos y los gastos generales de infraestructura regional, y puede incrementar los costes básicos entre un 30 % y un 50 %, dependiendo de la configuración. La búsqueda vectorial en varias regiones de proveedores de nube agrava estos gastos.
Cuando el autoalojamiento se vuelve un 75 % más barato
Dados estos costes ocultos y la volatilidad de los precios, muchos equipos acaban llegando a una encrucijada. Hay un punto en el que el precio de las bases de datos vectoriales deja de ser una cuestión de comodidad y se convierte en una cuestión económica. Ese punto suele llegar antes de lo que mucha gente espera.
Las comparativas de rendimiento muestran que PostgreSQL + pgvector es un 75 % más barato que Pinecone, al tiempo que ofrece una latencia P95 28 veces más rápida en comparación con el nivel optimizado para almacenamiento de Pinecone. El punto de inflexión en el que el autoalojamiento se vuelve sustancialmente más barato suele producirse entre 60 y 100 millones de consultas al mes.
El punto de equilibrio de costes
- Menos de 10 millones de consultas al mes:
- 10-60 millones de consultas al mes:
- 60-100 millones de consultas al mes: el autoalojamiento resulta entre un 50 % y un 75 % más barato. Con este volumen, las matemáticas se vuelven difíciles de ignorar.
¿Cuánto cuesta realmente el autoalojamiento?
- Servidor: 400-800 dólares al mes.
- Configuración: aproximadamente 40 horas de esfuerzo inicial (entre 4000 y 8000 dólares, pago único).
- Mantenimiento continuo: 10-15 horas/mes (1500-2250 $/mes en tiempo de ingeniería).
- Monitorización de la pila: entre 50 y 200 dólares al mes.
- Almacenamiento de copias de seguridad: entre 100 y 300 dólares al mes.
Total: entre 2050 y 3550 dólares al mes, frente a los 5000-10 000 dólares o más de Pinecone a escala empresarial.
Ahorro neto: 2950-6450 $ al mes = 35 000-77 000 $ al año.
Las matemáticas se vuelven más convincentes a medida que se amplía la escala. Con grandes conjuntos de datos que contienen cientos de millones de dimensiones vectoriales, la brecha se amplía sustancialmente.
Ventajas de rendimiento más allá del coste
El argumento económico es sólido, pero el rendimiento también es importante. Las pruebas comparativas de tiempos demuestran que PostgreSQL con pgvector alcanza una latencia P95 28 veces menor que el nivel de almacenamiento de Pinecone: 63 ms frente a 1763 ms. Además, PostgreSQL alcanza un rendimiento de consultas 16 veces mayor con un 99 % de recuperación.
Más allá del rendimiento, el autoalojamiento ofrece:
- Control: Ajuste según su carga de trabajo específica y las dimensiones del vector.
- Sin limitaciones ni restricciones de velocidad.
- Ventajas en materia de soberanía de datos y cumplimiento normativo.
- Escalabilidad predecible en la que los costes están vinculados a la capacidad, no al uso.
- Flexibilidad de búsqueda híbrida para combinar la búsqueda vectorial con las consultas tradicionales.
El coste oculto de lo gratuito y sin servidor
Los niveles gratuitos y los precios sin servidor están diseñados para transmitir seguridad. Reducen la fricción, disminuyen el compromiso inicial y facilitan el inicio de la construcción. En la práctica, a menudo retrasan la visibilidad de los costes en lugar de eliminarla.
Que no haya servidor no significa que la infraestructura sea gratis. Significa que la infraestructura se abstrae y se factura indirectamente según el uso. Para cargas de trabajo constantes, esa abstracción suele tener un costo extra. Se mide cada consulta, cada vector almacenado, cada actualización de incrustación y cada operación en segundo plano. Con el tiempo, la comodidad reemplaza a la previsibilidad.
Los niveles gratuitos siguen un patrón similar. Son útiles para experimentar, pero no son representativos de la economía de la producción. Cuando se alcanzan los límites de tiempo, el trabajo de integración ya está hecho, las API están integradas y la migración resulta cara. En ese momento, los equipos tienden a aceptar precios que antes habrían cuestionado.
Una forma práctica de elegir
Una vez que aparece la volatilidad de los precios, la pregunta ya no es qué base de datos es la más barata hoy en día. Una vez que el sistema se estabiliza, queda claro qué modelo de precios sigue funcionando.
Hay tres factores que son los más importantes:
- Escala: cuántos vectores almacenas, cuántas consultas realizas al mes y con qué rapidez crecen esas cifras.
- Previsibilidad: si el uso es irregular e incierto, o constante y previsible durante los próximos seis a doce meses.
- Control: cuánta responsabilidad operativa puede asumir realmente tu equipo y cuán sensible es el negocio a las variaciones presupuestarias.
Al principio, los servicios gestionados en la nube suelen tener sentido. Optimizan la velocidad, la experimentación y la demanda desconocida. A medida que las cargas de trabajo se estabilizan y los volúmenes de consultas alcanzan decenas de millones al mes, los precios basados en el uso comienzan a perder su ventaja. Los costes aumentan más rápido que el valor, y las previsiones se vuelven más difíciles, en lugar de más fáciles.
Más allá de unos 60-100 millones de consultas al mes, muchos equipos alcanzan un punto de inflexión. A esa escala, las implementaciones autohospedadas o locales suelen ser considerablemente más baratas y mucho más predecibles, incluso después de tener en cuenta los gastos generales de infraestructura y operativos.
Cuando cada opción encaja
Los servicios gestionados en la nube funcionan mejor cuando:
- El tráfico es impredecible o muy irregular.
- La velocidad de iteración es más importante que el coste a largo plazo.
- La capacidad de DevOps es limitada.
- Las cargas de trabajo siguen siendo exploratorias.
Las implementaciones autohospedadas o locales tienen sentido cuando:
- El volumen de consultas es alto y estable.
- La previsibilidad de los costes es un requisito empresarial.
- Los presupuestos deben defenderse con antelación.
- El cumplimiento normativo o la residencia de los datos son importantes.
- Los objetivos de rendimiento son exigentes.
La elección correcta depende de que tu modelo de precios se ajuste a tu comportamiento real de producción.
Factores desencadenantes de decisiones que ayudan
En lugar de debatir continuamente sobre la arquitectura, muchos equipos definen desencadenantes claros:
- Si el gasto mensual en bases de datos vectoriales supera los 1500 dólares, reevalúe las opciones de implementación.
- Si el volumen de consultas supera los 50 millones al mes, calcule el coste total de propiedad de la infraestructura propia.
- Si los cambios en los precios superan el 20 %, reevalúe el riesgo del proveedor.
- Si los objetivos de latencia no se cumplen de forma sistemática, evalúe alternativas.
Estos factores hacen que la fijación de precios pase de ser una sorpresa a convertirse en un punto de decisión planificado.
Lo esencial
El precio de las bases de datos vectoriales parece sencillo al principio. Los niveles gratuitos, los mínimos bajos y la facturación basada en el uso sugieren que solo se paga por lo que se utiliza. En la producción, la economía cambia. Los costes se acumulan entre el almacenamiento, las consultas, las incrustaciones y las operaciones en segundo plano.
La misma consulta se vuelve más costosa a medida que crecen los conjuntos de datos, incluso cuando ofrece el mismo valor. La previsibilidad desaparece en la etapa en la que más importa. Para cargas de trabajo sostenidas, existe un punto de inflexión claro en el que la propiedad se vuelve más barata y fácil de justificar. Los equipos que evitan las facturas exorbitantes no son los que negociaron mejores descuentos, sino los que trataron los precios como una decisión arquitectónica desde el principio.
Para las organizaciones que valoran los presupuestos fijos, los gastos predecibles y el control a largo plazo, esta es la razón por la que las bases de datos vectoriales locales están volviendo a ser objeto de serios debates arquitectónicos. La base de datos vectorial local de Actian, diseñada en torno a licencias transparentes en lugar de la volatilidad basada en el uso, refleja ese cambio.
Haga los cálculos de costes antes de tener que migrar. Siempre sale más barato así.
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)