Aceleración de Spark con Actian Vector en Hadoop





Uno de los proyectos más candentes en la comunidad Apache Hadoop es Spark, y en Actian nos complace anunciar un conector Spark-Vector para la plataforma Actian Vector in Hadoop (VectorH) que une a ambos. VectorH proporciona la solución SQL en Hadoop más rápida y completa, y la conexión con Spark abre interfaces a nuevos formatos de datos y funcionalidades como el streaming y el aprendizaje automático.
¿Por qué utilizar VectorH con Spark?
VectorH es un sistema de gestión de bases de datos SQL analíticas de haute performance y compatible con ACID que aprovecha Hadoop Distributed File System (HDFS) o MapR-FS para el almacenamiento y Hadoop YARN para la gestión de recursos. Si quieres escribir en SQL y realizar tareas SQL complejas, necesitas VectorH. SparkSQL es sólo un subconjunto de SQL y debe invocarse desde un programa escrito en Scala, R, Python o Java.
VectorH es un RDBMS maduro, de nivel empresarial, con un optimizador de consultas avanzado, soporte para actualizaciones incrementales y certificación con los outils bi más populares. También incluye funciones avanzadas de seguridad y gestión de la carga de trabajo. El formato de datos en columnas de VectorH y la compresión optimizada se traducen en un rendimiento más rápido de las consultas y una utilización más eficiente del almacenamiento que otros formatos habituales de Hadoop.
¿Por qué utilizar Spark con VectorH?
Spark ofrece un motor computacional distribuido que amplía la funcionalidad a nuevos servicios como el procesamiento estructurado, el streaming, el aprendizaje automático y el análisis de gráficos. Spark, como plataforma para el científico de datos, permite trabajar con Scala, R, Python o Java.
Este conector Spark-Vector amplía drásticamente el acceso de VectorH al mayor alcance de la conectividad y funcionalidad de Spark. Un caso de uso muy potente es la capacidad de transferir datos de Spark a VectorH de forma altamente paralela. Esta capacidad ETL es uno de los casos de uso más comunes para Apache Spark.
Si aún no eres un programador de Spark, el conector proporciona un sencillo cargador de línea de comandos que aprovecha Spark internamente y te permite cargar archivos CSV, Parquet y ORC sin tener que escribir una sola línea de código Spark. Spark es un componente estándar soportado con todas las principales distribuciones de Hadoop, por lo que deberías ser capaz de utilizar el conector siguiendo la información del sitio del conector.
¿Cómo funciona?
El conector carga los datos de Spark en Vector y recupera los datos a través de SQL desde VectorH. La primera parte se realiza en paralelo: los datos procedentes de cada partición RDD de entrada se serializan utilizando el protocolo binario de Vector y se transfieren a través de conexiones socket a los puntos finales de Vector utilizando la API DataStream de Vector. La mayoría de las veces este conector asignará sólo particiones RDD locales dentro de cada punto final de Vector para preservar la localidad de los datos y evitar cualquier retraso incurrido por las comunicaciones de red. En el caso de récupération des données desde Vector a Spark, los datos se exportan desde Vector y se ingestan en Spark utilizando una conexión JDBC al nodo líder de Vector. El conector funciona tanto con Vector SMP como con VectorH MPP, y con Spark 1.5.x. A continuación se muestra una visión general del movimiento de datos:
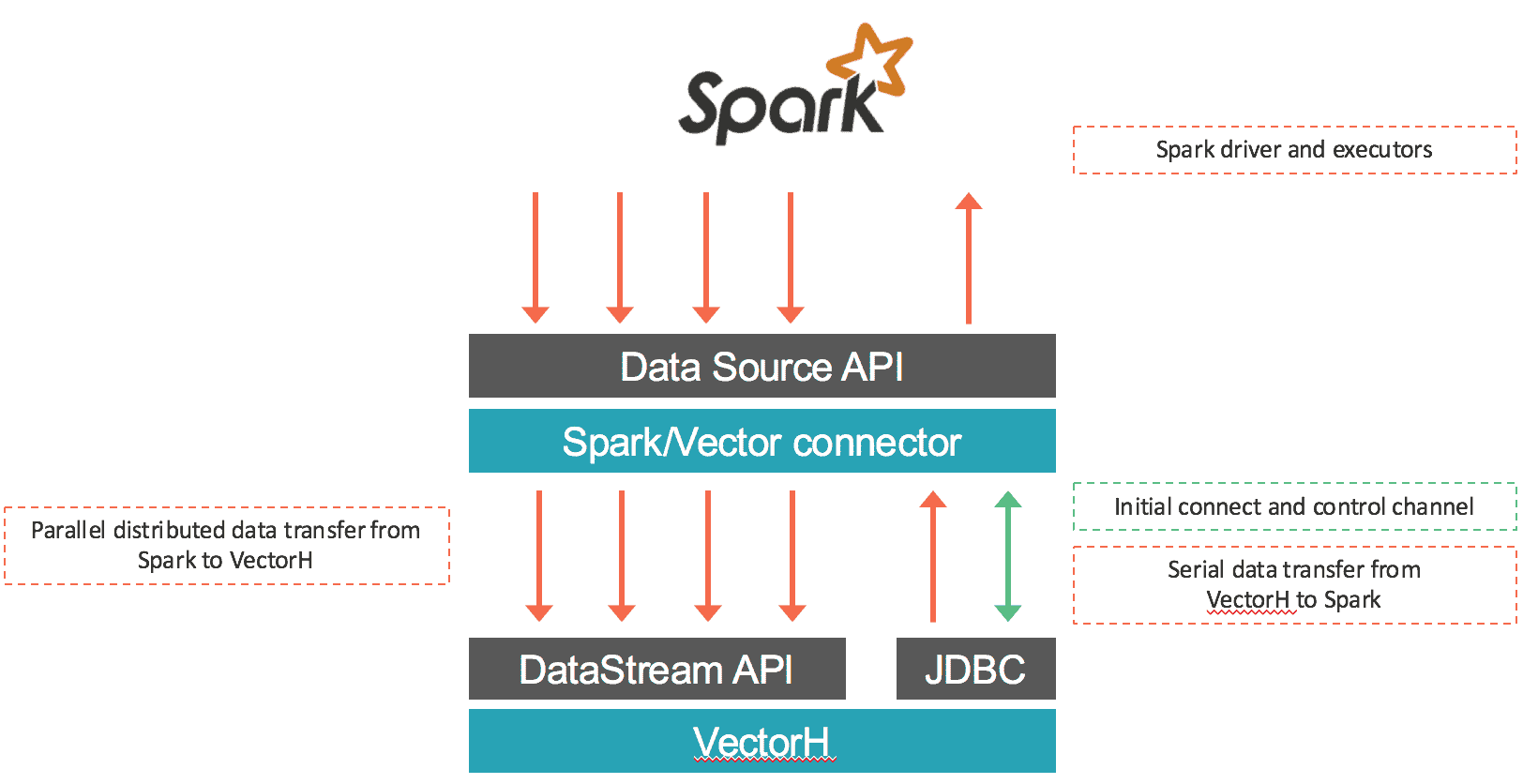
¿Qué más hay?
Esta última versión de VectorH (4.2.3) también incluye las siguientes novedades:
- Soporte de YARN en MapR, además de las distribuciones de Cloudera y Hortonworks ya certificadas. Con el soporte nativo en YARN, puede ejecutar varias cargas de trabajo en el mismo Cluster Hadoop para compartir todo el conjunto de recursos.
- Los archivos por perfil de consulta pueden escribirse en un directorio específico, incluido un directorio HDFS. Esta función proporciona más flexibilidad y control para gestionar y compartir perfiles de consulta entre distintos usuarios.
- Nuevas opciones para mostrar el estado de los servicios del clúster, incluido el estado básico del nodo, el acceso Kerberos si está activado, el acceso MPI, HDFS Safemode y HDFS fsck.
- Una nueva opción para crear índices MinMax en un subconjunto de columnas, así como una mejor gestión de la memoria de MinMax, lo que se traduce en una menor sobrecarga processeur y de la memoria.
Obtenga más información en https://www.actian.com/products/ o póngase en contacto con sales@actian.com para hablar con un representante.
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)