Actian Vector Dateneingang





Die Nützlichkeit einer Analytics Database ist eng mit ihrer Fähigkeit verbunden, große Datenmengen aufzunehmen, zu speichern und zu verarbeiten. Die Daten werden in der Regel aus verschiedenen Quellen wie operativen Datenbanken, CSV-Dateien und kontinuierlichen Datenströmen aufgenommen. In den meisten Fällen beläuft sich das tägliche Datenaufkommen auf Dutzende oder Hunderte von Millionen Zeilen, so dass der herkömmliche SQL INSERT-Mechanismus für diese Datenmengen nicht geeignet ist.
In diesem Blog-Beitrag stellen wir Actian Vector vor, unsere kolumnare Datenbank, die sich ideal für analytische Anwendungen eignet, und bewerten eine Reihe von Dateneingang , die mit den erforderlichen Datenraten arbeiten. In zukünftigen Beiträgen werden wir Actian VectorH in einer Hadoop-Umgebung und den Dateneingang aus Streaming untersuchen.
Der Zweck dieser Übung ist nicht der Leistungsvergleich von Dateneingang , sondern die Bewertung der relativen Geschwindigkeit verschiedener Methoden in derselben Hardwareumgebung. Wir werden SQL INSERT als Basis, SQL COPY TABLE, Befehlszeilen-Vwload und die ETL/Workflow-Tools Pentaho Data Integration (auch bekannt als Kettle), Talend Open Studio for Data Integration und Apache NiFi bewerten. Talend und Pentaho sind traditionelle ETL-Tools, die sich weiterentwickelt haben und eine Vielzahl von Bulk-Loadern und anderen so genannten Big Data und -Technologien umfassen; beide basieren auf der Eclipse-Oberfläche. NiFi wurde der Apache Foundation von der Nationalen Sicherheitsbehörde der USA (NSA) als Open Source zur Verfügung gestellt und ist ein allgemeines Tool zur Automatisierung des Datenflusses zwischen Softwaresystemen; es verwendet eine webbasierte Nutzer .
Alle drei implementieren ein Konzept eines gerichteten Graphen, bei dem die Daten von einem Operator zum nächsten fließen und die Operatoren parallel ausgeführt werden. Pentaho und Talend haben Community- und Abonnement-Editionen, während NiFi Open Source von Apache ist.
Der Vector-Server ist ein AMD Opteron 6234 Hex-Core-Prozessor der Desktop-Klasse mit 64 GB Speicher und SATA-Festplatten (Hardwarekosten ca. $2.500), auf dem Single-Node-Vector Version 5.0 läuft.
Als Vergleichsbasis fügen wir etwa 24 Millionen Datensätze in die TPCH-Benchmark-Zeilentabelle ein. Die Struktur dieser Tabelle ist:
l_orderkey bigint NOT NULL, l_partkey INT NOT NULL, l_lieferschlüssel INT NOT NULL, l_Zeilennummer INT NOT NULL, l_Menge NUMERIC(19,2) NOT NULL, l_erweiterterPreis NUMERIC(19,2) NOT NULL, l_Rabatt NUMERIC(19,2) NOT NULL, l_Steuer NUMERIC(19,2) NOT NULL, l_returnflag CHAR(1) NOT NULL, l_linestatus CHAR(1) NOT NULL, l_shipdate DATE NOT NULL, l_commitdate DATE NOT NULL, l_Receiptdate DATE NOT NULL, l_shipinstruct CHAR(25) NOT NULL, l_shipmode CHAR(10) NOT NULL, l_Bemerkung VARCHAR(44) NOT NULL
SQL INSERT
Da Vector ANSI-SQL-kompatibel ist, ist der naheliegendste Einfügemechanismus vielleicht das Standard-SQL-Konstrukt INSERT. Dies ist in der Regel die am wenigsten leistungsfähige Option, da sie zu Einfügeoperationen in Form von Singles führt. Einfügungen können bis zu einem gewissen Grad durch Parametrisierung und das Einfügen von Datensätzen in Stapeln optimiert werden, aber auch das kann nicht das erforderliche Leistungsniveau bieten.
Für den SQL INSERT-Test erstellen wir einen einfachen Pentaho-Workflow mit zwei Schritten, einem zum Lesen der CSV-Datendatei und einem zum Einfügen dieser Zeilen in eine Vector-Datenbank. Wir führen den Workflow sowohl auf demselben Knoten wie die Vector-Instanz als auch auf einem entfernten Knoten aus, um die Auswirkungen des Netzwerk-Overheads zu messen.

In dieser Situation schneidet das Laden von einem entfernten Knoten geringfügig besser ab als das Laden vom lokalen Knoten, und die Leistung verbessert sich im Allgemeinen mit zunehmender Stapelgröße bis zu etwa 100K Datensätzen und flacht dann ab. Damit soll nicht gesagt werden, dass 100K immer die optimale Stapelgröße ist; sie variiert höchstwahrscheinlich je nach Zeilengröße.
Vektor COPY TABLE
Das Vector COPY TABLE-Konstrukt wird verwendet, um Daten in großen Mengen aus einer CSV-Datei in die Datenbank zu laden. Wenn dieser Ansatz von einem entfernten Knoten aus ausgeführt wird, erfordert er eine Vector Client Runtime-Installation, nämlich Ingres Net und den Ingres SQL Terminal Monitor. Die Client Runtime ist frei verfügbar und unterliegt keinen Lizenzierungsanforderungen. Sowohl Pentaho als auch Talend haben eine integrierte Unterstützung für dieses Konstrukt, obwohl die Implementierung leicht unterschiedlich ist. Pentaho verwendet Named Pipes, um Daten in den Operator zu leiten, während Talend eine Zwischendatei erstellt und dann den Operator aufruft.
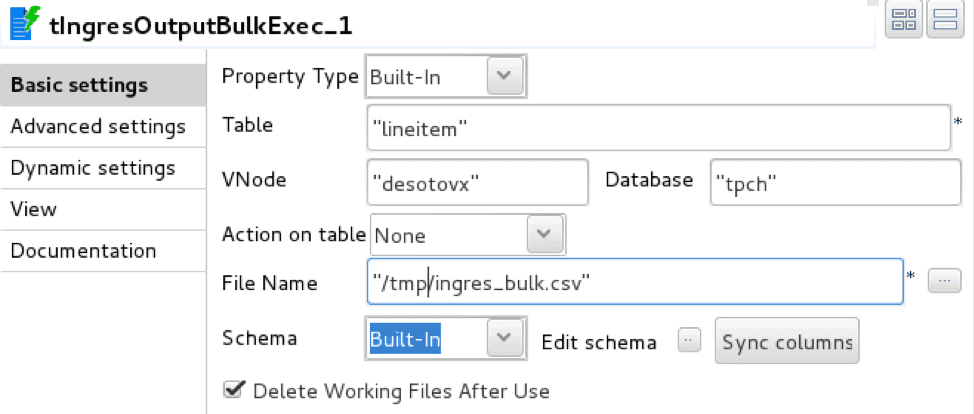
Die Talend-Implementierung verwendet zwei Operatoren: tFileInputDelimited, ein Leseprogramm für begrenzte Dateien, und tIngresOutputBulkExec, ein Ingres/Vector COPY TABLE-Lader

Der Lader wird mit den Details der Datenbankverbindung, der Zieltabelle und der Zwischenbereitstellungsdatei konfiguriert.
Die Pentaho-Implementierung verwendet zwei äquivalente Operatoren, CSV-Dateieingabe, Lesegerät für begrenzte Dateien, und Ingres VectorWise Bulk Loader, Datenbank-Tabellenlader.

Der Lader wird mit einer Vector-Verbindung und einer Zieltabelle konfiguriert. Im Gegensatz zu Talend verwendet der Pentaho-Lader keine Staging-Zwischendatei.

Die Leistung beider Tools ist im Wesentlichen gleich, aber etwa 6x schneller als SQL INSERT. Apache NiFi bietet keine native Unterstützung für Vector COPY TABLE, und die Simulation dieses Ansatzes durch separates Starten des Terminalmonitors und Verbinden mit Named Pipes ist relativ mühsam.
Vektor vwload
Das von Vector bereitgestellte Dienstprogramm vwload ist ein High-Performance Bulk-Loader für Actian Vector und VectorH. Es ist ein Kommandozeilen-Dienstprogramm, das eine oder mehrere Dateien in eine Vector- oder VectorH-Tabelle aus dem lokalen Dateisystem oder aus dem HDFS lädt. Wir werden die HDFS-Variante in einem späteren Beitrag untersuchen.
Vwload kann eigenständig oder als Datenlademechanismus für die von Pentaho, Talend oder NiFi erzeugten Workflow-Datenströme aufgerufen werden. Pentaho verfügt über eine integrierte Vwload-Unterstützung, während Talend und NiFi einen Mechanismus bereitstellen, um Workflow-Datenströme an Vwload zu leiten, ohne sie vorher auf der Festplatte zu speichern.
Die Talend-Implementierung verwendet tFileInputDelimited, um die CSV-Quelldatei zu lesen und tFileOutputDelimited, um die Zeilen der Quelldatei in eine benannte Pipe zu schreiben. Um den Datenstrom in Vector zu laden, müssen wir vwload mit der gleichen Named Pipe wie die Quelldatei ausführen.
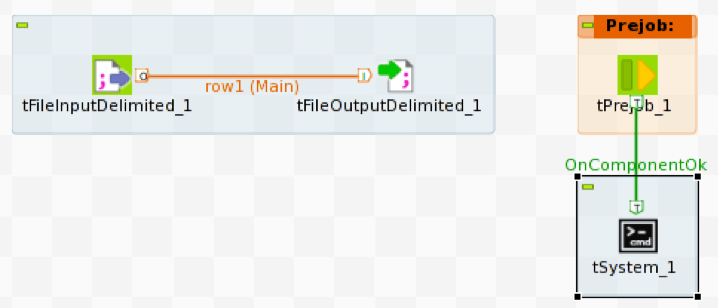
Um vwload zu starten, verwenden wir das Prejob-Konstrukt, um den tSystem-Operator auszulösen. tSystem ist der Mechanismus zur Ausführung von Befehlen auf Betriebssystemebene oder Shell-Skripten. Der Prejob-Operator wird beim Auftragsstart automatisch vor allen anderen Workflow-Operatoren ausgelöst und ist so konfiguriert, dass er den tSystem-Operator auslöst.
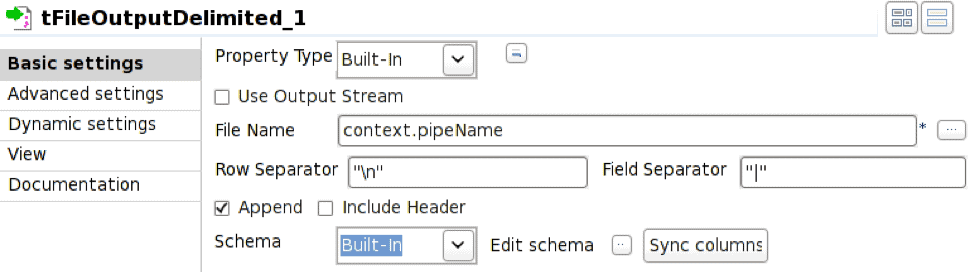
Der Operator tFileOutputDelimited ist so konfiguriert, dass er in die benannte Pipe schreibt, die durch die Umgebungsvariable context.pipeName definiert ist. Die benannte Pipe muss zum Zeitpunkt der Auftragsausführung existieren und Append muss aktiviert sein.
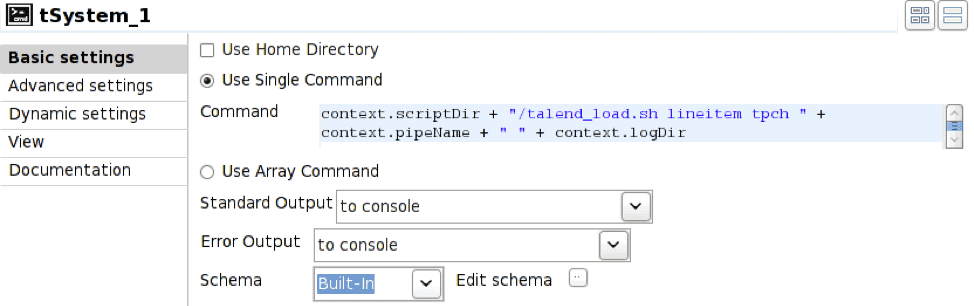
In diesem Fall führt der tSystem-Operator das Shell-Skript talend_load.sh aus und übergibt Parameter für den Tabellennamen, den Datenbanknamen, den Pipe-Namen und das Verzeichnis der resultierenden Protokolldatei. Die Notation context. ist der Mechanismus für die Referenzierung von Umgebungsvariablen, die mit dem Job verbunden sind; dadurch können Jobs parametrisiert werden. Das Shell-Skript ist:
#!/bin/bash nohup vwload -m -t $1 $2 $3 > $4/log_`date +%Y%m%d_%H%M%S`.log 2>&1 &
Die sich daraus ergebende Ausführungsreihenfolge ist:
- Prejob-Operator ausführen
- Pre-Job-Auslöser tSystem operator
- tSystem-Operator führt Shell-Skript aus
- Shell-Skript startet vwload im Hintergrund und kehrt zurück; vwload liest jetzt aus der benannten Pipe und wartet auf die Ankunft von Zeilen
- Start von tFileInputDelimited zum Lesen von Zeilen aus der Quelldatei
- tFileOutputDelimited starten, um eingehende Zeilen zu empfangen und in eine benannte Pipe zu schreiben
Die Pentaho-Implementierung verwendet die CSV-Dateieingabe und die Ingres VectorWise Loader-Operatoren wie im Fall von COPY TABLE, aber der Bulk Loader ist so konfiguriert, dass er stattdessen vwload verwendet.
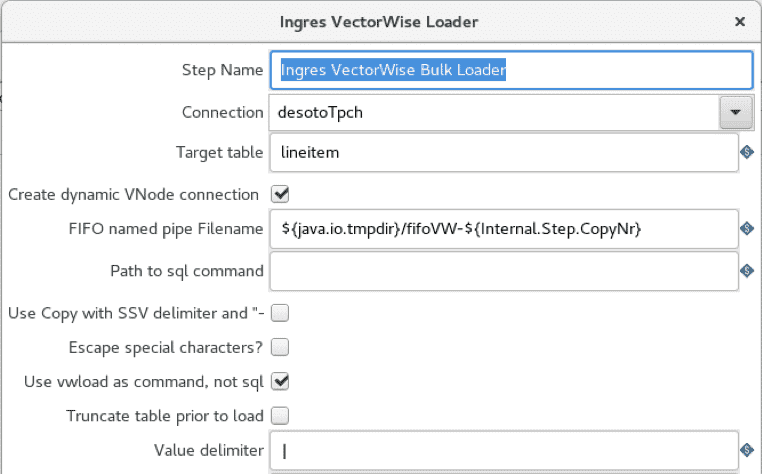
Die Option "vwload verwenden" ist ausgewählt, und das Feld "Pfad zum sql-Befehl" ist ausgefüllt. Auf diese Weise wird das Dienstprogramm vwload aufgerufen.
Die Apache-NiFi-Implementierung verwendet drei Operatoren: GetFile, der ein Verzeichnis-Listener ist, FetchFile, der die eigentliche Datei liest, und ExecuteStreamCommand, der die Streaming an den Hintergrundprozess vwload übergibt.
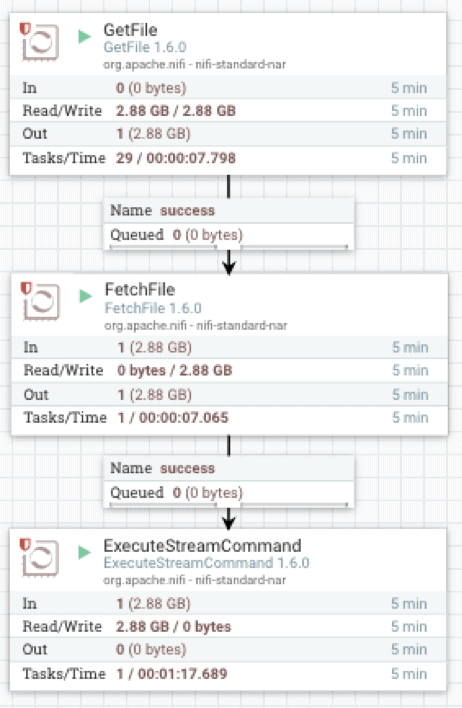
FetchFile übergibt den Quelldatenstrom an ExecuteStreamCommand, das für die Ausführung eines Shell-Skripts konfiguriert ist.
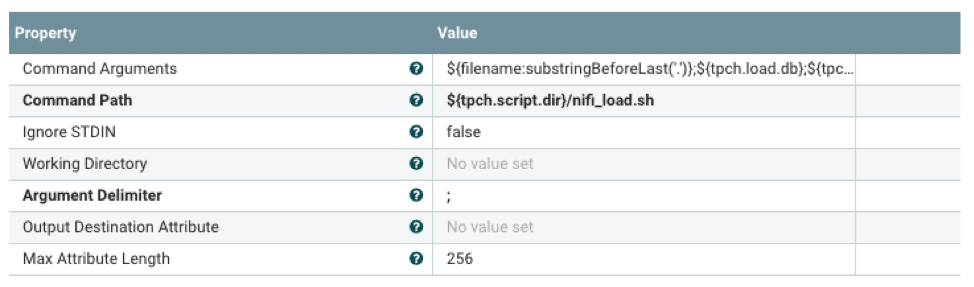
Das Shell-Skript startet vwload im Hintergrund und leitet den Datenstrom über eine benannte Pipe an vwload weiter. Die Notation ${} ist der Mechanismus, um auf Eigenschaften zu verweisen, die mit einer externen Eigenschaftsdatei konfiguriert wurden. Dies ermöglicht die Konfiguration des Flussprozessors zur Laufzeit.
#!/bin/bash tabellenname=$1 dbName=$2 LadeRohr=$3 logDir=$4 echo "`date +%Y-%m-%d\ %H:%M:%S` vwload -m -t $tableName db $dbName $loadPipe " >> $logDir/load.log vwload -uactian -m -t $Tabellenname $dbName $loadPipe >> $logDir/load.log 2>&1 & cat /dev/stdin >>$loadPipe
In den vorangegangenen Pentaho-, Talend- und NiFi-Workflows wird die Kommandozeile vwload als Lademechanismus verwendet. Zum Vergleich laden wir denselben Datensatz auch mit Standalone vwload auf dem lokalen Vector-Rechner sowie vom Remote-Client mit Ingres Net.

Die spezifischen Laufzeiten und Einzugsraten sind je nach Hardware und Zeilengröße sehr unterschiedlich.
Zusammenfassend lässt sich sagen, dass die Optionen für Dateneingang , in der Reihenfolge der Leistungssteigerung, SQL INSERT, SQL COPY TABLE und vwload sind. Für große Datenmengen ist vwload in Verbindung mit einem geeigneten ETL-Tool in der Regel die richtige Wahl. Die Wahl des ETL-Tools wird in der Regel durch Leistung und Funktionalität bestimmt. Zumindest sollte ein Mechanismus vorhanden sein, der eine Schnittstelle zur Ingestion-Methode der Wahl bietet. Die Anforderungen an die Funktionalität hängen hauptsächlich von der Menge und der Art der Umwandlung ab, die an dem eingehenden Datenstrom vorgenommen werden muss. Selbst wenn die eingehenden Daten unverändert geladen werden sollen, kann ein ETL-Tool für die Erkennung eingehender Dateien, die Auftragsplanung und die Fehlerberichterstattung nützlich sein.
Die obigen Arbeitsabläufe stellen den trivialen Fall für die Aufnahme von CSV-Dateien dar, bei dem in der Regel nur eine Quelldatendatei gelesen und in Vector geladen wird. Als solche stellen sie auch den besten Leistungsfall für jede der Ingestionsmethoden dar. Die meisten realen Anwendungsfälle beinhalten ein gewisses Maß an Transformationslogik im Workflow, wobei die Datenflussraten in Abhängigkeit von der Komplexität der Transformation abnehmen. Die Messung der Workflow-Datenraten ermöglicht es uns, die Ingestion-Methode auszuwählen, die diesen Anforderungen gerecht wird.
Erfahren Sie mehr über Actian Vector
Sie können mehr über Actian Vector erfahren, indem Sie die folgenden Ressourcen besuchen:
Erfahren Sie mehr über unsere Actian Vector Community-Editionen auf:
Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)