El catálogo de datos moderno: una guía estratégica para la inteligencia de datos
Según Gartner, la mala calidad de los datos cuesta a las organizaciones una media de 12,9 millones de dólares al año, mientras que una investigación de IBM de 2025 muestra que las organizaciones tardan una media de 258 días en identificar y contener una filtración de datos. Estas estadísticas revelan una verdad básica: la gobernanza ya no puede consistir en un remedio a posteriori o un proceso manual; debe automatizarse, centralizarse e integrarse en las operaciones de datos.
Un catálogo de datos es un sistema centralizado de metadatos que ayuda a las organizaciones a descubrir, entender y gobernar sus datos. Dentro de una plataforma de inteligencia de datos, el catálogo de datos da la base contextual y de descubrimiento que conecta los metadatos, el linaje, la gobernanza y la observabilidad en toda la empresa. Brinda descubrimiento, linaje, clasificación y aplicación de políticas de forma automática, para que los equipos encuentren rápido datos fiables y los usen con responsabilidad.
Un catálogo de datos moderno, con descubrimiento automatizado, metadatos centralizados y aplicación de políticas, convierte una gobernanza de datos fragmentada e insegura en un acceso proactivo, fiable y de autoservicio, que mejora el cumplimiento normativo, calidad y decisiones. Supone el cambio de una gestión reactiva a una administración estratégica de los datos, para que las organizaciones gobiernen a gran escala pero acelerando el análisis e innovación.
Los catálogos de datos empresariales no solo exigen una búsqueda básica e inventario. Entre las capacidades esenciales están el descubrimiento automatizado de metadatos, la alineación integrada del glosario empresarial, el linaje continuo, los controles de acceso según roles, la aplicación de políticas, el mercado de datos y las señales de calidad y observabilidad de datos. Si se ofrecen dentro de una plataforma de inteligencia de datos, estas capacidades garantizan la disponibilidad de datos fiables y gobernados donde se usan de verdad el análisis y la IA.
¿Qué es un catálogo de datos?
Un catálogo de datos es un sistema centralizado que inventaría, organiza y enriquece los metadatos, para que los usuarios descubran, comprendan, confíen y gobiernen los datos en toda la organización. Los catálogos de datos modernos automatizan la recopilación de metadatos, hacen un seguimiento del linaje, aplican políticas de gobernanza y muestran indicadores de calidad y confianza para respaldar iniciativas de análisis, cumplimiento e IA.
Principales ventajas de un catálogo de datos
Los catálogos de datos modernos ofrecen ventajas transformadoras en gobernanza, cumplimiento normativo y eficiencia operativa.
- Centraliza los metadatos de todas las fuentes en un único repositorio con búsqueda, eliminando silos de datos.
- Mejora la calidad y fiabilidad de los datos mediante la supervisión, validación y puntuación de calidad continuas.
- Automatiza la clasificación y la aplicación de políticas, lo que garantiza un tratamiento consistente de datos confidenciales.
- Acelera el análisis y el acceso de autoservicio, al hacer que los datos fiables sean localizables en minutos y no en semanas.
- Facilita el cumplimiento del RGPD, HIPAA y normativas sectoriales.
- Brinda linaje para entender el origen, transformaciones y uso de los datos en todo el ecosistema.
- Reduce el riesgo operativo y el trabajo manual de gobernanza, permitiendo a los equipos centrarse en iniciativas estratégicas.
- Permite la democratización de los datos a la vez que preserva la seguridad y el control con acceso según roles.
- Acelera las iniciativas de IA y ML al facilitar datos de entrenamiento fiables y bien documentados.
- Mejora la colaboración entre los equipos técnicos y empresariales con un entendimiento común.
Entender los principales retos de gobernanza de datos
La gobernanza de datos es el conjunto de políticas, roles y procesos para que los datos estén disponibles y sean utilizables, precisos y seguros en toda la empresa. A medida que las organizaciones ingieren más datos de diversas fuentes, la gobernanza gana importancia y complejidad.
Entre los principales retos están los metadatos fragmentados en sistemas desconectados, lo que genera vistas inconsistentes e impide una gobernanza para toda la empresa. Los silos de datos persisten porque los sistemas departamentales no se comunican entre sí, lo que duplica los datos y hace del control de versiones una pesadilla. La inconsistencia en la terminología empresarial significa que un mismo concepto puede tener diferentes nombres en los distintos equipos, como «cliente» o «consumidor», mientras que conceptos distintos comparten el mismo nombre, lo que genera confusión y errores.
Los procesos manuales de cumplimiento normativo siguen siendo lentos y propensos a errores. Los inventarios de datos basados en hojas de cálculo quedan obsoletos muy rápido. Las revisiones de acceso se hacen trimestral o anualmente, lo que prolonga permisos indebidos durante meses. La clasificación depende del etiquetado manual, que pasa por alto datos confidenciales o aplica etiquetas sin consistencia. La preparación de las auditorías lleva semanas de recopilación manual de pruebas.
La falta de visibilidad perjudica a las organizaciones: los equipos no ubican conjuntos de datos que ya existen, lo que provoca un trabajo duplicado y un mal aprovechamiento de recursos. No pueden evaluar la calidad sin conocimientos tribales o una investigación laboriosa. No pueden rastrear el linaje para entender de dónde vienen los datos o qué depende de ellos, lo que impide el análisis del impacto, y la investigación de la causa raíz es terriblemente lenta.
Sin una propiedad y administración claras, la calidad de los datos se deteriora, ya que nadie se responsabiliza de su exactitud, integridad u oportunidad. La confianza se erosiona si los usuarios ven problemas de calidad de continuo y dejan de usar las fuentes de datos oficiales, optando por alternativas no controladas.
Las consecuencias van más allá de la ineficacia: sanciones reglamentarias, incidentes de seguridad e iniciativas de análisis o IA estancadas. Las organizaciones que intentan escalar la IA ven que el desarrollo de modelos se detiene sin datos de entrenamiento fiables y bien documentados. Para escalar un autoservicio fiable y estar basadas en datos, las organizaciones necesitan una gobernanza automatizada, centralizada e integrada en los flujos de trabajo cotidianos.
Automatizar el descubrimiento de datos y la recopilación de metadatos
El descubrimiento automatizado escanea de continuo bases de datos, archivos, almacenamiento en la nube y aplicaciones para identificar activos de datos, lo que elimina los inventarios manuales y garantiza una cobertura exhaustiva. Las herramientas de descubrimiento modernas detectan ubicaciones de fuentes, esquemas, relaciones y patrones de uso, mejorando la precisión con el tiempo gracias al aprendizaje automático.
La recopilación automatizada de metadatos extrae información mucho más rica que lo imaginable con documentación manual. Los metadatos técnicos incluyen detalles del esquema, tipos de datos, nulidad, unicidad, cardinalidad y perfiles estadísticos que muestran distribuciones de valores e indicadores de calidad. Los metadatos empresariales capturan el fin, propiedad, puntuaciones de calidad y directrices de uso. Los metadatos operativos hacen un seguimiento de los patrones de acceso, el rendimiento de las consultas, los programas de actualización de datos y el linaje que muestra las transformaciones.
Estos procesos automatizados mantienen el catálogo sincronizado con la realidad. Si los desarrolladores implementan cambios de esquema mediante canalizaciones CI/CD, el descubrimiento los detecta en horas. Si se ponen online nuevas fuentes de datos, aparecen automáticamente en el catálogo. Si se retiran conjuntos de datos, el catálogo refleja su eliminación. Esta sincronización evita que el catálogo se vuelva un sistema de documentación obsoleto más, que los equipos ignoran.
La automatización reduce drásticamente los tiempos de incorporación de nuevas fuentes, de semanas o meses a horas o días, por lo que los proyectos de análisis arrancan más rápido. Al mismo tiempo, las políticas de gobernanza y controles de acceso se aplican desde la ingesta.
Cree un catálogo de datos exhaustivo y centralizado
Un catálogo de datos centralizado indexa y organiza todos los activos de datos empresariales en una única interfaz con búsqueda, lo que elimina los silos y crea una única fuente de información. Esta consolidación supone ventajas prácticas inmediatas. Los usuarios tardan unos minutos en encontrar conjuntos de datos, sin pasarse días haciendo preguntas. El trabajo duplicado se reduce drásticamente si los equipos pueden ver lo que ya existe. Las políticas de gobernanza se aplican de manera uniforme, pues hay un único lugar para definirlas y aplicarlas. La preparación de las auditorías se acelera, ya que todas las pruebas están en un único sistema con un registro exhaustivo.
Capacidades de búsqueda y descubrimiento: los catálogos modernos ofrecen múltiples paradigmas de búsqueda para las distintas necesidades de los usuarios. La búsqueda por palabras clave posibilita búsquedas rápidas por nombre o descripción. La búsqueda semántica entiende los conceptos empresariales y encuentra conjuntos de datos de «ingresos» si los usuarios buscan «ventas». La búsqueda por facetas permite filtrar por sistema de origen, dominio de datos, propietario, clasificación, puntuación de calidad o actualidad. Los usuarios pueden explorar taxonomías y jerarquías, o seguir recomendaciones según su rol y patrones de uso previos.
Indicadores de fiabilidad y calidad de los datos: cada conjunto de datos muestra métricas de calidad calculadas con reglas de perfilado y validación: porcentajes completados, puntuaciones de exactitud, indicadores de oportunidad y medidas de consistencia. Las valoraciones y comentarios de usuarios dan información cualitativa. Las estadísticas de uso muestran la popularidad: los conjuntos de datos muy usados por analistas sénior suelen indicar más confianza que los activos poco consultados. Los distintivos de certificación indican la revisión y aprobación formal por administradores.
Análisis de uso: el catálogo controla quién accede a los conjuntos de datos, cuándo y para qué. Esta visibilidad revela los productos de datos más populares que merecen una inversión adicional, identifica activos infrautilizados y candidatos a archivado, y ayuda a los administradores a entender el impacto de sus datos. Los análisis también detectan patrones de acceso inusual, que podrían indicar problemas de seguridad o infracciones de políticas.
Funciones colaborativas: los usuarios pueden comentar los conjuntos de datos, plantear preguntas o compartir ideas. Pueden valorar la calidad de los datos según su experiencia. Los administradores pueden adjuntar ejemplos de uso con consultas comunes o patrones de análisis. Los hilos de discusión sobre activos de datos crean un conocimiento institucional que, de otro modo, seguiría en los canales de Slack o hilos de correo electrónico, dificultando su búsqueda posterior.
Contexto empresarial y estandarización: la centralización impone un lenguaje empresarial consistente con definiciones, clasificaciones y glosarios estandarizados. Si «cliente» tiene una definición autorizada vinculada a cada conjunto de datos con información sobre clientes, la confusión interdepartamental se desvanece. Los equipos armonizan la terminología, lo que reduce los malentendidos que generan análisis incorrectos o duplicación del trabajo.
Los catálogos modernos almacenan metadatos técnicos y empresariales, ejemplos de uso y evaluaciones de calidad, para que los usuarios entiendan qué significan los datos, cómo se generan, su fiabilidad y los casos de uso y limitaciones aplicables.
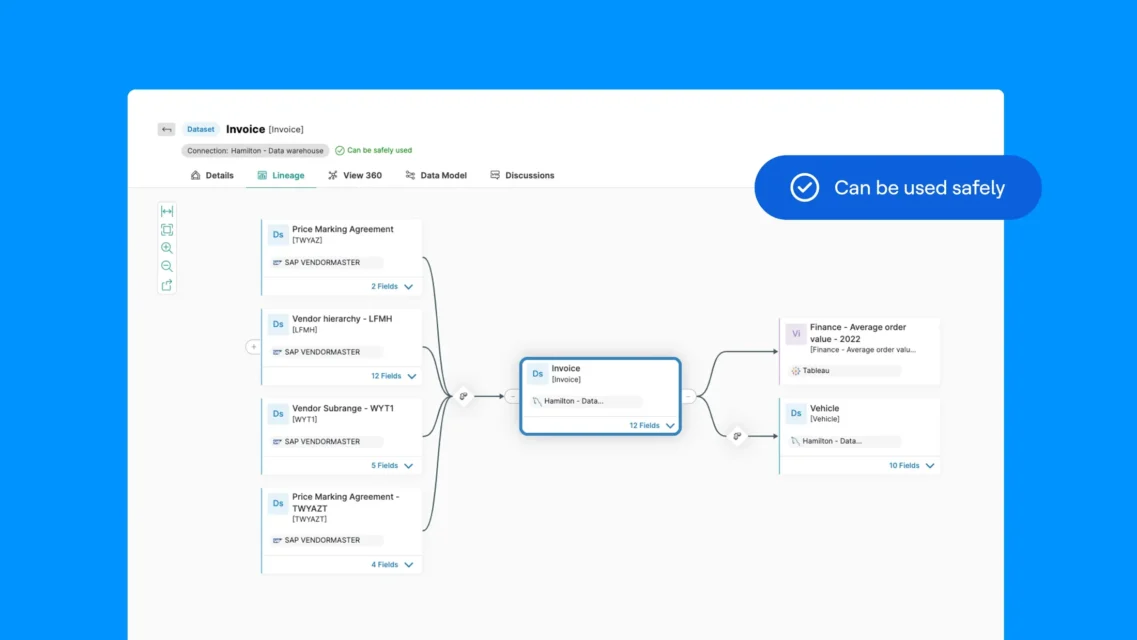
Linaje de datos y análisis de impacto
La visualización del linaje de datos es una de las capacidades de gobernanza más potentes, al mostrar cómo fluyen los datos de los sistemas de origen, mediante transformaciones, integraciones y análisis, hasta los puntos de consumo finales. El linaje completo responde a preguntas críticas muy complejas para la documentación manual: ¿de dónde viene este valor? ¿qué transformaciones se aplicaron? ¿qué informes y modelos dependen de este conjunto de datos? Si cambio esta tabla, ¿qué se rompe en etapas posteriores?
Visualización del flujo continuo: los catálogos modernos crean gráficos de linaje completos que abarcan toda la infraestructura de datos. Esta visibilidad abarca tecnologías y plataformas, mostrando el linaje incluso cuando los datos cruzan los límites del sistema.
Linaje a nivel de columna: para cumplimiento normativo y análisis de impacto profundo, el linaje a nivel de tabla suele ser insuficiente. El linaje a nivel de columna realiza un seguimiento de los campos individuales en las transformaciones, mostrando que «ingresos_anuales» en un informe se deriva al final de «ventas_totales» en el sistema de origen, tras la conversión de divisas y agregación. Esta granularidad resulta esencial para las normativas de privacidad que exigen documentar el flujo de datos personales por los sistemas, y para investigaciones de calidad que exigen una identificación precisa de la causa raíz.
Análisis de causas raíz para problemas de calidad: si surgen problemas de calidad de datos, el linaje permite una investigación rápida. Si un panel de control muestra valores incorrectos, los equipos rastrean el linaje en fases previas, a través de las transformaciones, para ver dónde se añadieron los errores. ¿Eran datos fuente erróneos? ¿Un error lógico en el código de transformación? ¿Un valor nulo inesperado que alteró los cálculos? El linaje reduce el tiempo de investigación de días a horas, al dar una hoja de ruta directa al problema.
Gobernanza del modelo de aprendizaje automático: a medida que las organizaciones implementan más modelos de aprendizaje automático, el linaje se vuelve esencial para la gobernanza y explicabilidad del modelo. Documenta qué datos de entrenamiento se usaron, cómo se diseñaron las características, qué preprocesamiento se hizo y si alguno de esos componentes cambió desde la implementación del modelo. Si el rendimiento del modelo baja, el linaje ayuda a diagnosticar si la causa es una desviación de datos o de conceptos, o bien los cambios en las fuentes de datos previas.
Desarrollo de productos de datos: las organizaciones que crean productos de datos internos (conjuntos de datos gestionados y publicados para reusarlos entre equipos) dependen del linaje para entender las dependencias y garantizar la fiabilidad. Los propietarios de productos pueden ver todas las fuentes previas de las que depende su producto y todos los consumidores posteriores que dependen de ellos, para gestionar bien los cambios y cumplir los SLA.
Aplicar controles de acceso según roles y políticas de seguridad
El control de acceso según roles (RBAC) asigna permisos por rol, para que solo los usuarios autorizados accedan a datos confidenciales, pero permitiendo un uso empresarial legítimo. En un catálogo, el RBAC asigna funciones de trabajo a derechos específicos de visualización, edición y uso, lo que garantiza un acceso consistente y auditable.
La integración del RBAC con las políticas de seguridad de la empresa centraliza la aplicación y simplifica las auditorías de cumplimiento. La automatización de las decisiones de acceso según reglas predefinidas reduce la carga para TI y elimina las prácticas de permisos ad hoc, que crean brechas. Si se incorporan nuevos analistas, reciben automáticamente permisos estándar de analista, según su departamento y antigüedad. Si los empleados se trasladan, sus permisos se ajustan automáticamente. Si abandonan la empresa, se revoca de inmediato el acceso en todos los sistemas gobernados. Esta automatización elimina el proceso manual de solicitud de acceso con tickets, que genera retrasos e inconsistencias.
El RBAC avanzado puede considerar el contexto (adaptando los permisos por hora, ubicación, dispositivo o fin), equilibrando la protección estricta de la información confidencial con la flexibilidad operativa para flujos de trabajo legítimos.
Este sofisticado enfoque equilibra la protección estricta de la información confidencial con la flexibilidad operativa para los flujos de trabajo legítimos. Un científico de datos puede acceder a los registros completos de clientes para entrenar modelos en un portátil de empresa en horario laboral, pero solo verá estadísticas agregadas en un dispositivo personal en su hogar. Un contratista puede acceder a conjuntos de datos específicos de un proyecto mientras esté en vigor su contrato, pero perderá automáticamente el acceso al finalizar el mismo.
Implementar la clasificación y aplicación de políticas de forma automática
La clasificación automatizada aplica algoritmos y ML para etiquetar los datos por tipo, confidencialidad y requisitos normativos, lo que permite un manejo consistente en toda la infraestructura de datos. Esto sustituye al etiquetado manual, propenso a errores, y garantiza la identificación fiable de registros confidenciales (IIP, datos financieros, IP).
Las clasificaciones abarcan múltiples dimensiones: el tipo de datos identifica si los datos son de información de identificación personal o de seguros médicos, financiera, de propiedad intelectual o pública. El nivel de sensibilidad clasifica los datos como públicos, internos, confidenciales o restringidos. El ámbito normativo etiqueta los datos sujetos al RGPD, HIPAA, PCI DSS, CCPA o normas específicas del sector. Los requisitos de retención especifican cuánto tiempo deben conservarse los datos y cuándo eliminarlos. Las restricciones geográficas indican dónde se pueden almacenar los datos y quién puede acceder a ellos según las leyes de residencia de datos.
La aplicación de políticas usa esas clasificaciones para aplicar controles de forma automática (restricciones de acceso, enmascaramiento, reglas de retención y supervisión), al tiempo que busca sin cesar infracciones de las políticas. La plataforma puede señalar accesos inusuales, generar alertas y activar flujos de trabajo de corrección, para reducir errores humanos y retrasos en la aplicación.
Los informes de cumplimiento automatizados generan los registros de auditoría e informes (quién accedió a qué, cuándo y con qué controles) exigidos por el RGPD, HIPAA y otras normas, reduciendo el esfuerzo y riesgo de los informes manuales.
Mantener registros de auditoría y permitir una supervisión proactiva del cumplimiento de la normativa
Los registros de auditoría recogen las acciones cronológicas en los activos de datos (accesos, ediciones, cambios en metadatos y actualizaciones de linaje), dando pruebas clave para rendir cuentas, investigar incidentes y afrontar auditorías reglamentarias. Los registros capturan el uso directo e indirecto (informes, análisis, canalizaciones), para respaldar el análisis forense y la evaluación de riesgos.
La supervisión proactiva del cumplimiento analiza de continuo los patrones de acceso, el cumplimiento de políticas y las anomalías de uso, para detectar problemas a tiempo. Cuando surgen anomalías, el sistema puede alertar a las partes interesadas, iniciar flujos de trabajo de corrección o aplicar correcciones automáticas según la gravedad.
La supervisión avanzada puede ofrecer información predictiva a partir de patrones históricos, ayudando a los equipos a anticiparse y prevenir los riesgos de cumplimiento, en vez de reaccionar a posteriori.
Facilite la colaboración con documentación basada en plantillas
La documentación basada en plantillas estandariza la recopilación y presentación de metadatos, contexto empresarial, asignaciones de administradores y políticas, reduciendo la variabilidad y el esfuerzo manual. Los formularios guiados y de arrastrar y soltar permiten a los colaboradores no técnicos añadir contexto, reglas empresariales y orientaciones de uso, sin conocimientos especializados.
Las plataformas suelen ofrecer módulos adaptados a cada rol: módulos Studio para que los administradores gestionen los flujos de trabajo y políticas, y módulos Explorer para que los usuarios empresariales descubran activos y aporten su conocimiento del dominio. Las plantillas admiten registros de activos, glosarios, asignaciones de administración, declaraciones de políticas y directrices de uso, todo ello con flujos de trabajo de aprobación y control de versiones, para garantizar la exactitud.
Este enfoque estructurado y colaborativo distribuye el trabajo de documentación, preserva la calidad y garantiza que la información publicada se revise y gobierne.
Buenas prácticas para implementar bien un catálogo de datos
Para implementar un catálogo con éxito, hay que abordar tanto la tecnología como las personas. Las prácticas clave incluyen:
- Asigne una administración clara: designe propietarios y administradores para todos los dominios de datos principales, con responsabilidades definidas en documentación, calidad y gobernanza del acceso.
- Desarrolle y mantenga un glosario empresarial estandarizado: armonice la terminología entre los equipos usando definiciones autorizadas de términos, métricas y conceptos empresariales. El glosario se vuelve la base semántica, para que todos hablen el mismo idioma.
- Automatice la sincronización de metadatos: integre las actualizaciones del catálogo con implementaciones de canalizaciones CI/CD y de datos, para que los metadatos sigan actualizados automáticamente.
- Dé entrenamiento según roles: adapte el entrenamiento a los administradores, ingenieros de datos, analistas y usuarios empresariales, con escenarios prácticos que muestren el valor del catálogo para cada rol.
- Integre el catálogo en los flujos de trabajo: incorpore capacidades de catálogo donde ya trabajan los usuarios, para que la gobernanza quede integrada y no sea un paso adicional.
Las organizaciones que aplican estas prácticas informan de una mejor visibilidad de datos, una obtención más rápida de información, una mejor auditabilidad y más confianza en los resultados analíticos. El catálogo pasa de un requisito de cumplimiento a una capacidad estratégica, fomentando una innovación segura y rápida.
En qué se diferencian los catálogos de datos modernos de las herramientas de catálogo tradicionales
Las herramientas tradicionales de catálogo de datos se centran sobre todo en inventario y búsqueda. Aunque son útiles, suelen carecer de sincronización de metadatos en tiempo real, un glosario empresarial unificado, un linaje profundo, una gobernanza integrada y las señales de calidad necesarias para análisis e IA a escala empresarial.
Los catálogos de datos modernos funcionan como parte de una plataforma de inteligencia de datos más amplia. Recopilan de continuo metadatos técnicos, empresariales y operativos, conectan el linaje, observabilidad y definiciones del glosario empresarial, e incorporan directamente políticas de gobernanza sobre cómo se accede y se usan los datos. Este cambio transforma el catálogo, de un sistema de referencia pasivo a una capa activa de control y confianza para datos empresariales.
Catálogo de datos frente a soluciones tradicionales y puntuales
Muchas organizaciones adoptan soluciones puntuales para la catalogación de datos, glosarios empresariales, linaje o calidad de los datos. Aunque estas herramientas resuelven necesidades concretas, suelen crear experiencias fragmentadas y difíciles de escalar.
Un catálogo de datos moderno dentro de una plataforma de inteligencia de datos unifica el descubrimiento, las definiciones del glosario empresarial, el linaje, la gobernanza y la observabilidad en un solo sistema. Esto elimina las herramientas desconectadas, reduce el trabajo de integración manual y garantiza que las políticas de gobernanza y señales de confianza se apliquen con consistencia en todos los flujos de trabajo de análisis e IA.
A diferencia de las herramientas de catálogo independientes, un enfoque integrado permite a las organizaciones ir más allá del inventario, pasando a una gobernanza activa, un autoservicio fiable y datos listos para la IA a escala empresarial.
Preguntas frecuentes
Un catálogo de datos es un sistema centralizado de metadatos que ayuda a los equipos a descubrir, entender y gobernar los datos empresariales. Funciona escaneando automáticamente las fuentes de datos, recopilando metadatos, clasificando información confidencial, mapeando el linaje y aplicando políticas de gobernanza, para que los usuarios encuentren rápido datos fiables para análisis e IA.
Un catálogo de datos respalda la inteligencia de datos al hacer de capa principal de descubrimiento y contexto, que conecta los metadatos, linaje, gobernanza y calidad de los datos en toda la empresa.
Dentro de una plataforma de inteligencia de datos, el catálogo recopila de continuo metadatos técnicos, empresariales y operativos, para poder buscar, entender y gobernar los activos de datos a gran escala. Da visibilidad sobre la propiedad, uso, linaje e indicadores de confianza, de modo que los equipos de análisis, sistemas de IA y usuarios empresariales elijan con confianza los datos adecuados para sus necesidades.
Sin un catálogo de datos, la inteligencia de datos no tiene una interfaz práctica para descubrimiento y adopción. El catálogo garantiza que la inteligencia no solo se documente, sino que se use activamente en análisis, IA y flujos de trabajo operativos.
Un catálogo de datos da la visibilidad y control que necesitan los equipos de gobernanza. Centraliza los metadatos, estandariza definiciones, aplica políticas de acceso y automatiza la supervisión del cumplimiento. Esto reduce el riesgo, mejora la calidad de los datos y garantiza una gobernanza consistente en toda la infraestructura de datos.
Un catálogo de datos resuelve los principales retos que impiden a las organizaciones confiar en el uso de los datos y escalarlo. Elimina los metadatos fragmentados, reduce el trabajo analítico duplicado, y facilita la búsqueda y comprensión de datos gobernados de alta calidad.
Los catálogos de datos modernos abordan problemas comunes como definiciones empresariales inconsistentes, visibilidad limitada del linaje, procesos de cumplimiento manuales y poca confianza en los resultados analíticos. Al centralizar los metadatos, linaje, contexto de gobernanza e indicadores de calidad, un catálogo de datos permite unas decisiones más rápidas, un mejor cumplimiento e iniciativas de IA y análisis fiables.
Los catálogos de datos empresariales no solo exigen una búsqueda básica e inventario. Las características esenciales incluyen el descubrimiento automatizado de metadatos, el linaje continuo, los controles de acceso según roles, la aplicación de políticas, las señales de calidad y observabilidad de datos, y la compatibilidad con entornos híbridos y multinube.
En la práctica, estas capacidades solo se escalan si el catálogo opera como parte de una plataforma de inteligencia de datos más amplia, donde los flujos de trabajo de gobernanza, los indicadores de confianza y el contexto empresarial se aplican directamente a cómo se accede y se usan los datos en los análisis y sistemas de IA. Sin esta base, los catálogos difícilmente irán más allá de los equipos pequeños o de casos de uso solo para cumplimiento normativo.
La IA mejora un catálogo de datos al automatizar el descubrimiento, clasificación y enriquecimiento de metadatos. El aprendizaje automático identifica patrones de datos, detecta anomalías, recomienda activos relacionados, señala problemas de calidad y predice posibles riesgos de cumplimiento. Estas capacidades ayudan a las organizaciones a escalar la gobernanza con menos trabajo manual.
Sí. Un catálogo de datos moderno juega un papel clave en IA y aprendizaje automático, al dar los metadatos, linaje y contexto de calidad de los que dependen los modelos.
Las iniciativas de IA exigen datos de entrenamiento fiables, canalizaciones de características explicables y visibilidad de los cambios de los datos en el tiempo. Un catálogo de datos lo hace posible al documentar el origen de los datos, las transformaciones, las señales de calidad y las restricciones de uso, lo que reduce el riesgo, sesgo y desviación del modelo, a la vez que mejora la transparencia y gobernanza.
Los catálogos de fuente abierta dan flexibilidad a los equipos que desean personalizar sus propias herramientas, pero que pueden necesitar más recursos de ingeniería. Los catálogos de datos empresariales dan automatización integrada, flujos de trabajo de gobernanza, controles de seguridad, escalabilidad, soporte e integración con plataformas de datos más amplias, lo que los adapta mejor a entornos regulados o a gran escala.


