Procesamiento de datos en tiempo real con Actian Zen y conectores Kafka





Bienvenido de nuevo al mundo de Actian Zen, una versátil y potente solución de gestión de datos de borde diseñada para ayudarle a crear aplicaciones integradas de baja latencia. En parte 1 exploramos cómo aprovechar BtrievePython para ejecutar aplicaciones Btrieve2 Python, utilizando el motor de base de datos Zen 16.0 Enterprise/Server.
Esta es la segunda parte de la serie de blogs de inicio rápido que se centra en ayudar a los desarrolladores de aplicaciones Embarqué a empezar a utilizar Actian Zen. En esta entrada del blog, vamos a caminar a través de la configuración de una demostración de Kafka utilizando Actian Zen, lo que demuestra cómo gestionar y procesar las transacciones financieras en tiempo real sin problemas. Esto incluye la configuración de variables de entorno, el uso de un script de orquestación, la generación de datos de transacciones simuladas, el aprovechamiento de Docker para un déploiement optimizado y la utilización de Docker Compose para la orquestación.
Introducción a Actian Zen Kafka Connectors
En el dinámico mundo de las finanzas, es imprescindible procesar y gestionar las transacciones en tiempo real de forma eficiente. Los Conectores Kafka de Actian Zen ofrecen una solución robusta para el streaming de datos de transacciones entre sistemas financieros y temas Kafka. Los Conectores Kafka de Actian Zen facilitan una integración perfecta entre las bases de datos Actian Zen y Apache Kafka. Estos conectores admiten operaciones tanto de origen como de destino, lo que le permite transmitir datos de una base de datos Zen Btrieve a temas Kafka o viceversa.
Fuente Conector
El conector Zen Source transmite datos JSON desde una base de datos Zen Btrieve a un tema Kafka. Emplea el sondeo de captura de cambios para recoger nuevos datos a intervalos definidos por el usuario, lo que garantiza que sus temas de Kafka se actualicen siempre con la información más reciente de sus bases de datos Zen.
Conector de fregadero
El conector Zen Sink transmite datos JSON desde un tema Kafka a una base de datos Zen Btrieve. Puede elegir transmitir datos a una base de datos existente o crear una nueva al iniciar el conector.
Configuración de variables de entorno
Antes de sumergirse en la configuración, es esencial establecer las variables de entorno necesarias. Estas variables aseguran que las rutas del sistema y de las librerías están correctamente configuradas, y que aceptas el Acuerdo de Licencia de Usuario Final (EULA) de Zen.
Aquí tienes un ejemplo de las variables de entorno que debes configurar:
export PATH="/usr/local/actianzen/bin:/usr/local/actianzen/lib64:$PATH"
export LD_LIBRARY_PATH="/usr/local/actianzen/lib64:/usr/lib64:/usr/lib"
export CLASSPATH="/usr/local/actianzen/lib64"
export CONNECT_PLUGIN_PATH='/usr/share/java'
export ZEN_ACCEPT_EULA="YES"
Configuración de los conectores Kafka
Los parámetros de configuración de los conectores Kafka se proporcionan como pares clave-valor. Estas configuraciones pueden establecerse mediante un archivo de propiedades, la API REST de Kafka o mediante programación. A continuación se muestra un ejemplo de configuración JSON para un conector de origen:
{ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.Kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.Kafka.connect.storage.StringConverter", "value.converter": "org.apache.Kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }
También puede definir consultas de usuario para un filtrado de datos más granular utilizando el lenguaje de consulta JSON detallado en la documentación de la API de Btrieve2. Por ejemplo, para filtrar las transacciones mayores o iguales a $1000:
"\"Transaction\":{\"Amount\":{\"$gte\":1000}}"
Script de orquestación: kafkasetup.py
El sitio kafkasetup.py automatiza el proceso de arranque y parada de los conectores Kafka. Aquí hay un fragmento que muestra cómo el script configura los conectores:
import requests import json def main(): requestMap = {} requestMap["Financial Transactions"] = ({ "name": "financial-transactions-source", "config": { "connector.class": "com.actian.zen.kafka.connect.source.BtrieveSourceConnector", "db.filename.param": "transactions.mkd", "server.name.param": "financial_db", "poll.interval.ms": "2000", "tasks.max": "1", "topic": "transactionLog", "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.storage.StringConverter", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "-1", "topic.creation.default.partitions": "-1" } }, "8083") for name, requestTuple in requestMap.items(): input("Press Enter to continue...") (request, port) = requestTuple print("Now starting " + name + " connector") try: r = requests.post("https://localhost:"+port+"/connectors", json=request) print("Response:", r.json) except Exception as e: print("ERROR: ", e) print("Finished setup!...") input("\n\nPress Enter to begin shutdown") for name, requestTuple in requestMap.items(): (request, port) = requestTuple try: r = requests.delete("https://localhost:"+port+"/connectors/"+request["name"]) except Exception as e: print("ERROR: ", e) if __name__ == "__main__": main()
Cuando ejecutes el script, te pedirá que inicies cada conector uno por uno, asegurándote de que todo está configurado correctamente.
Generación de datos de transacciones con generador_datos.py
El sitio generador_datos.py simula datos de transacciones financieras, creando registros de transacciones a intervalos especificados. He aquí un vistazo a la función central:
importar sys importar os import signal import json import random from time import sleep from datetime import datetime sys.path.append("/usr/local/actianzen/lib64") import btrievePython como BP
clase GracefulKiller:
kill_now = False def __init__(self): signal.signal(signal.SIGINT, self.exit_gracefully) signal.signal(signal.SIGTERM, self.exit_gracefully) def exit_gracefully(self, *args): self.kill_now = True def generate_transactions(): client = BP.BtrieveClient() assert(client != None) collection = BP.BtrieveCollection() assert(collection != None) collectionName = os.getenv("GENERATOR_DB_URI") rc = client.CollectionCreate(collectionName) rc = client.CollectionOpen(collection, collectionName) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) interval = int(os.getenv("GENERATOR_INTERVAL")) kill_condition = GracefulKiller() while not kill_condition.kill_now: transaction = { "Transaction": { "ID": random.randint(1000, 9999), "Amount": round(random.uniform(10.0, 5000.0), 2), "Currency": "USD", "Timestamp": str(datetime.now()) } } print(f"Generated transaction: {transaction}") documentId = collection.DocumentCreate(json.dumps(transaction)) if documentId < 0: print("DOCUMENT CREATE ERROR: " + BP.Btrieve.StatusCodeToString(collection.GetLastStatusCode())) sleep(interval) rc = client.CollectionClose(collection) assert(rc == BP.Btrieve.STATUS_CODE_NO_ERROR), BP.Btrieve.StatusCodeToString(rc) if __name__ == "__main__": generate_transactions()
Este script ejecuta un bucle infinito, generando e insertando continuamente datos de transacciones en una colección Btrieve.
Utilización de Docker para déploiement
Para facilitar esta configuración, utilizamos un contenedor Docker. Aquí está el Dockerfile que configura el entorno para ejecutar nuestro script generador de datos:
DESDE actian/zen-client:16.00 USUARIO root EJECUTAR apt update && apt install python3 -y COPIAR --chown=zen-svc:zen-data data_generator.py /usr/local/actianzen/bin ADD _btrievePython.so /usr/local/actianzen/lib64 ADD btrievePython.py /usr/local/actianzen/lib64 USUARIO zen-svc CMD ["python3", "/usr/local/actianzen/bin/data_generator.py"]
Este Dockerfile se extiende desde la imagen del cliente Actian Zen, instala Python, e incluye el script de generación de datos. Al construir y ejecutar este contenedor Docker, podemos generar y transmitir datos de transacciones en temas Kafka según lo configurado.
Docker Compose para la orquestación
Para gestionar y orquestar varios contenedores, incluidos Kafka, Zookeeper y nuestro generador de datos, utilizamos Docker Compose. Aquí está el archivo docker-compose.yml que lo reúne todo:
versión: '3.8 servicios: zookeeper: imagen: wurstmeister/zookeeper:3.4.6 puertos: - "2181:2181" kafka imagen: wurstmeister/kafka:2.13-2.7.0 puertos: - "9092:9092" entorno: KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT KAFKA_LOG_RETENTION_HOURS: 1 KAFKA_MESSAGE_MAX_BYTES: 10485760 KAFKA_BROKER_ID: 1 volúmenes: - /var/run/docker.sock:/var/run/docker.sock actianzen: build: . environment: GENERATOR_DB_URI: "transacciones.mkd" GENERATOR_LOCALE: "Austin" INTERVALO_GENERADOR: "5" volúmenes: - ./data:/usr/local/actianzen/data
Este docker-compose.yml configura Zookeeper, Kafka y nuestro generador de datos Actian Zen en una única configuración. Al ejecutar docker-compose uppodemos poner en marcha toda la pila y comenzar a transmitir datos de transacciones financieras a temas de Kafka en tiempo real.
Visualización del flujo Kafka
Para que entiendas mejor el flujo de datos en esta configuración, aquí tienes un diagrama que ilustra el flujo Kafka:

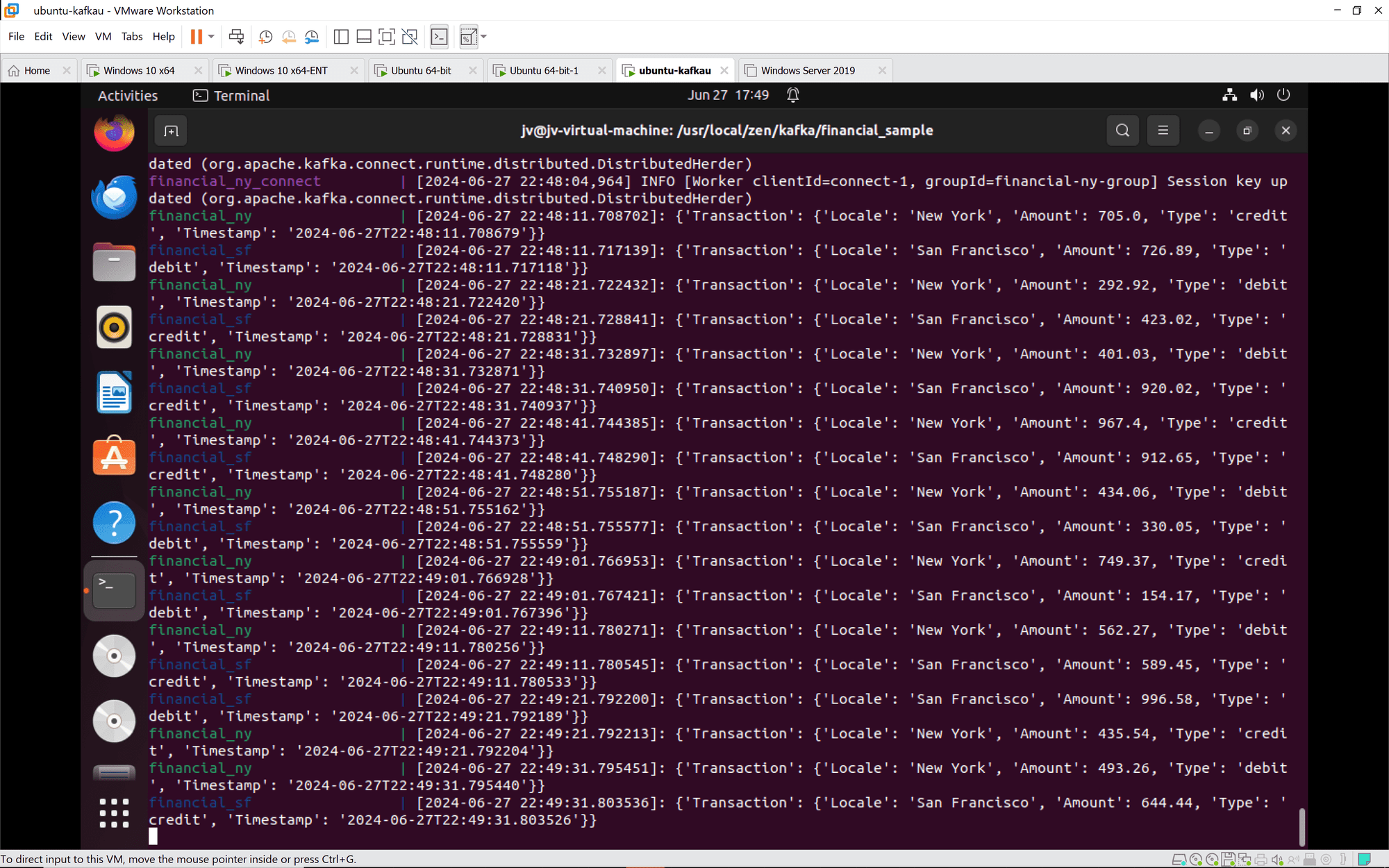
En este diagrama, los datos de las transacciones financieras fluyen desde la base de datos Actian Zen a través del conector de origen Kafka hacia los temas Kafka. A continuación, los datos pueden ser consumidos y procesados por diversas aplicaciones posteriores.
Conexión Kafka: Las instancias de Kafka Connect se unen correctamente a los grupos y se sincronizan. Las tareas y los conectores se configuran e inician según lo previsto.
Transacciones financieras: Las transacciones de Nueva York y San Francisco se procesan y registran correctamente. Las transacciones incluyen diversas acciones de crédito y débito con importes y marcas de tiempo variables.
Conclusión
La integración de Actian Zen con Kafka Connectors proporciona una potente solución para la transmisión y el procesamiento de datos en tiempo real. Siguiendo esta guía, puede configurar un sistema robusto para manejar transacciones financieras, asegurando que los datos se transmiten, procesan y almacenan de manera eficiente. Esta configuración no sólo demuestra las capacidades de Actian Zen y Kafka, sino que también destaca la facilidad de déploiement utilizando Docker y Docker Compose. Tanto si se trata de transacciones financieras como de otras aplicaciones con un uso intensivo de datos, esta solución ofrece un enfoque escalable y fiable para la gestion des données en tiempo real.
Para más detalles y guías visuales, consulte la Academia Actian y la completa documentación. ¡Feliz programación!

Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)