Actian Vector para Hadoop para una funcionalidad SQL más completa y datos actuales
Corporación Actian
7 de junio de 2020

En esta segunda de una serie de blog de tres partes (parte 1), explicaremos cómo la ejecución de SQL en Actian Vector en Hadoop (VectorH) es mucho más funcional y listo para funcionar en un entorno operativo, y cómo la capacidad de VectorH para manejar las actualizaciones de datos de manera eficiente puede permitir a su entorno de producción para mantenerse al día con el estado de su negocio. En la primera parte de este blog post de tres partes, mostramos la tremenda ventaja de rendimiento que VectorH tiene sobre otras alternativas SQL en Hadoop. La tercera parte cubrirá las ventajas del formato de archivo VectorH.
Mejor funcionalidad SQL para la productividad empresarial
Una de las barreras originales para obtener valor de Hadoop es la necesidad de conocimientos de MapReduce, que son escasos y caros, y llevan tiempo aplicarlos a una determinada cuestión analítica. Estas dificultades dieron lugar al surgimiento de numerosas alternativas SQL en Hadoop, muchas de las cuales son ahora proyectos del ecosistema Apache para Hadoop. Aunque esos distintos proyectos abren el acceso a los millones de usuarios empresariales que ya dominan la escritura de consultas SQL, en muchos casos exigen otras contrapartidas: diferencias en la sintaxis, limitaciones en determinadas funciones y extensiones, tecnología de optimización inmadura e implementaciones ineficaces. ¿Existe una forma mejor de introducir SQL en Hadoop?
Sí. Actian VectorH 6.0 soporta una implementación mucho más completa, con soporte completo ANSI SQL:2003, además de extensiones analíticas como CUBE, ROLLUP, GROUPING SETS, y WINDOWING para analytique avancée. Veamos la carga de trabajo que evaluamos en nuestra ponencia de SIGMOD, basada en las 22 consultas del benchmark TPC-H.
Cada una de las otras alternativas SQL en Hadoop tuvo problemas al ejecutar las consultas SQL estándar que componen la prueba comparativa TPC-H, lo que significa que los usuarios empresariales que conocen SQL pueden tener que realizar cambios manualmente o sufrir malos resultados o incluso consultas fallidas:
- Apache Hive 1.2.1 no pudo completar la consulta número 5.
- El rendimiento de Cloudera Impala 2.3 se ve dificultado por las uniones de un solo núcleo y el procesamiento de agregación, lo que crea cuellos de botella para explotar los recursos de procesamiento paralelo.
- Apache Drill 1.5 no pudo completar la consulta número 21, y sólo 9 de las consultas se ejecutaron sin modificar su código SQL.
- Dado que la versión 1.5.2 de Apache Spark SQL es un subconjunto limitado de ANSI SQL, la mayoría de las consultas tuvieron que reescribirse en Spark SQL para evitar subconsultas IN/EXISTS/NOT EXISTS, y algunas consultas requirieron la definición manual de órdenes de unión en Spark SQL. VectorH cuenta con un optimizador de consultas maduro que reordenará las uniones basándose en métricas de coste para mejorar el rendimiento y reducir los requisitos de ancho de banda de E/S.
- Apache Hawq versión 1.3.1 se basa en PostgreSQL, por lo que sus fundamentos tecnológicos más antiguos no pueden competir con el rendimiento de un motor de consulta vectorizado.
Actualizaciones eficaces para una visión más coherente de la empresa
Otro obstáculo para la adopción de Hadoop es que se trata de un sistema de archivos de sólo anexión, lo que limita la capacidad del sistema de archivos para gestionar inserciones y eliminaciones. Sin embargo, muchas aplicaciones empresariales requieren actualizaciones de los datos, lo que hace que el sistema de gestión de bases de datos tenga que gestionar esos cambios. VectorH puede recibir y aplicar actualizaciones de fuentes de datos transaccionales para garantizar que los análisis se realizan sobre la representación más actual de su negocio, no de hace una hora, o de ayer, o de la última carga por lotes en su almacén de datos.
- Como parte de la carga de trabajo de apoyo a la toma de decisiones ad hoc que representa, TPC-H tiene el requisito de ejecutar inserciones y eliminaciones como parte de la carga de trabajo. Hay dos flujos de actualización que realizan inserciones y eliminaciones en las seis tablas de hechos.
- Cuatro de las alternativas SQL en Hadoop no admiten actualizaciones en HDFS: Impala, Drill, SparkSQL y Hawq. No podrían cumplir los requisitos para obtener un resultado auditado completo.
- El quinto, Hive, sí admite actualizaciones, pero incurre en una importante penalización de rendimiento al ejecutar consultas después de gestionar las actualizaciones.
- VectorH ejecutó las actualizaciones más rápidamente que Hive. Con su patente pendiente Positional Delta Trees, VectorH rastrea las inserciones y eliminaciones por separado de los bloques de datos, manteniendo el cumplimiento completo de ACID y conservando el mismo nivel de rendimiento de consulta (¡sin penalización!).
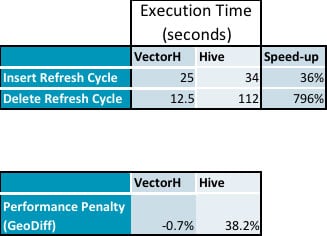
- A continuación se muestran los datos resumidos de nuestras pruebas que muestran la penalización de rendimiento en Hive mientras que no hay impacto en VectorH por la ejecución de actualizaciones (a continuación se detallan los datos):
- Las inserciones tardaron un 36% más y las eliminaciones requirieron un 796% más de tiempo en Hive que en VectorH.
El rendimiento posterior de las consultas muestra que los PDT no tienen una sobrecarga apreciable, en comparación con la penalización del 38% en el rendimiento de Hive:
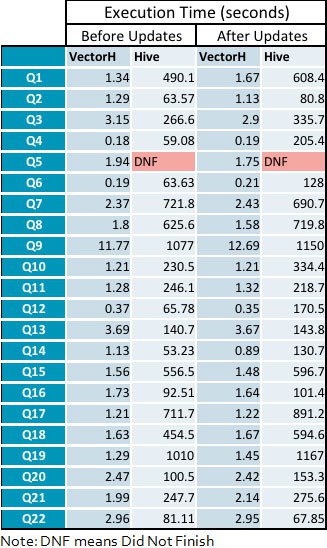
- La velocidad media de VectorH con respecto a Hive aumenta de 229x antes de los ciclos de actualización a 331x después de aplicar las actualizaciones, con un rango de 23 a 1141 en consultas individuales.
Apéndice: Tiempos detallados de ejecución de consultas
Suscríbase al blog de Actian
Suscríbase al blog de Actian para recibir información sobre datos directamente en su correo electrónico.
- Manténgase informado: reciba lo último en análisis de datos directamente en su bandeja de entrada.
- No se pierda ni una publicación: recibirá actualizaciones automáticas por correo electrónico que le avisarán cuando se publiquen nuevas publicaciones.
- Todo depende de usted: cambie sus preferencias de entrega para adaptarlas a sus necesidades.
Suscríbase a
(por ejemplo, ventas@..., soporte@...)