Actian Vector für Hadoop für umfassendere SQL-Funktionalität und aktuelle Daten
Actian Germany GmbH
7. Juni 2020

In diesem zweiten Teil einer dreiteiligen Blogserie (Teil 1) erläutern wir, wie die SQL-Ausführung in Actian Vector in Hadoop (VectorH) viel funktioneller und betriebsbereiter ist und wie die Fähigkeit von VectorH, Datenaktualisierungen effizient zu verarbeiten, Ihre Produktionsumgebung in die Lage versetzen kann, mit dem Stand Ihres Unternehmens Schritt zu halten. Im ersten Teil dieses dreiteiligen Blogbeitrags haben wir den enormen Leistungsvorteil von VectorH gegenüber anderen SQL-on-Hadoop-Alternativen aufgezeigt. Im dritten Teil werden wir die Vorteile des VectorH-Dateiformats behandeln.
Bessere SQL-Funktionalität für mehr Produktivität im Unternehmen
Eines der ursprünglichen Hindernisse für die Nutzung von Hadoop ist die Notwendigkeit von MapReduce , die selten und teuer sind und deren Anwendung auf eine bestimmte analytische Fragestellung Zeit erfordert. Diese Herausforderungen führten zum Aufkommen zahlreicher SQL-on-Hadoop-Alternativen, von denen viele jetzt Projekte im Apache-Ökosystem für Hadoop sind. Diese verschiedenen Projekte eröffnen zwar den Zugang zu den Millionen von Geschäftsanwendern, die bereits fließend SQL-Abfragen schreiben können, doch in vielen Fällen erfordern sie andere Kompromisse: Unterschiede in der Syntax, Einschränkungen bei bestimmten Funktionen und Erweiterungen, unausgereifte Optimierungstechnologie und ineffiziente Implementierungen. Gibt es einen besseren Weg, SQL auf Hadoop zu bringen?
Ja! Actian VectorH 6.0 unterstützt eine viel umfassendere Implementierung, mit voller ANSI SQL:2003 Unterstützung, plus analytische Erweiterungen wie CUBE, ROLLUP, GROUPING SETS und WINDOWING für Advanced Analytics. Schauen wir uns den Workload an, den wir in unserem SIGMOD-Papier evaluiert haben, basierend auf den 22 Abfragen im TPC-H Benchmark.
Jede der anderen SQL-on-Hadoop-Alternativen hatte Probleme bei der Ausführung der Standard-SQL-Abfragen, die den TPC-H-Benchmark ausmachen, was bedeutet, dass Geschäftsanwender, die sich mit SQL auskennen, möglicherweise manuell Änderungen vornehmen müssen oder schlechte Ergebnisse oder sogar fehlgeschlagene Abfragen hinnehmen müssen:
- Apache Hive 1.2.1 konnte die Anfrage Nummer 5 nicht abschließen.
- Die Leistung von Cloudera Impala 2.3 wird durch Single-Core-Joins und Aggregationsverarbeitung beeinträchtigt, was zu Engpässen bei der Nutzung von Parallelverarbeitungsressourcen führt.
- Apache Drill 1.5 konnte die Anfrage Nummer 21 nicht beantworten, und nur 9 der Abfragen liefen ohne Änderung des SQL-Codes.
- Da Apache Spark SQL Version 1.5.2 eine begrenzte Teilmenge von ANSI SQL ist, mussten die meisten Abfragen in Spark SQL umgeschrieben werden, um IN/EXISTS/NOT EXISTS-Unterabfragen zu vermeiden, und einige Abfragen erforderten die manuelle Definition von Join-Reihenfolgen in Spark SQL. VectorH verfügt über einen ausgereiften Anfrage , der Joins auf der Grundlage von Kostenmetriken neu anordnet, um die Leistung zu verbessern und die E/A-Bandbreitenanforderungen zu reduzieren.
- Apache Hawq Version 1.3.1 basiert auf PostgreSQL, so dass seine älteren technologischen Grundlagen nicht mit der Leistung einer vektorisierten Anfrage konkurrieren können.
Effiziente Updates für eine konsistentere Sicht auf das Geschäft
Ein weiteres Hindernis für die Einführung von Hadoop ist die Tatsache, dass es sich um ein reines Dateisystem handelt, was die Fähigkeit des Dateisystems, Einfügungen und Löschungen zu verarbeiten, einschränkt. Viele Geschäftsanwendungen erfordern jedoch Datenaktualisierungen, so dass das Datenbankmanagementsystem mit diesen Änderungen konfrontiert wird. VectorH kann Aktualisierungen aus transaktionalen Datenquellen empfangen und anwenden, um sicherzustellen, dass Analysen auf der aktuellsten Darstellung Ihres Unternehmens durchgeführt werden und nicht von vor einer Stunde, gestern oder dem letzten Batch-Load in Ihr Data Warehouse.
- Als Teil des Workload , den er darstellt, muss TPC-H Einfügungen und Löschungen als Teil des Workload ausführen. Es gibt zwei Aktualisierungsströme, die Einfügungen und Löschungen in den sechs Faktentabellen vornehmen.
- Vier der SQL on Hadoop-Alternativen unterstützen keine Updates auf HDFS: Impala, Drill, SparkSQL und Hawq. Sie wären nicht in der Lage, die Anforderungen für ein vollständig geprüftes Ergebnis kennenlernen .
- Die fünfte, Hive, unterstützt zwar Aktualisierungen, verursacht aber einen erheblichen Leistungsverlust bei der Ausführung von Abfragen nach der Bearbeitung der Aktualisierungen.
- VectorH führte die Aktualisierungen schneller aus als Hive. Mit seinen zum Patent angemeldeten Positional Delta Trees verfolgt VectorH Einfüge- und Löschvorgänge getrennt von den Datenblöcken, so dass die ACID-Konformität vollständig erhalten bleibt, während das gleiche Maß an Anfrage beibehalten wird (keine Strafe!)
- Hier sind die zusammengefassten Daten aus unseren Tests, die die Leistungseinbußen bei Hive zeigen, während die Ausführung von Aktualisierungen keine Auswirkungen auf VectorH hat (detaillierte Daten folgen):
- Einfügungen dauerten 36 % länger und Löschungen benötigten 796 % mehr Zeit auf Hive als auf VectorH
Anfrage anschließende Anfrage zeigt, dass PDTs keinen messbaren Overhead haben, verglichen mit dem Leistungsverlust von 38 % bei Hive:
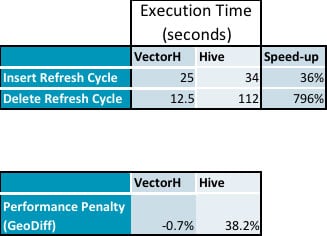
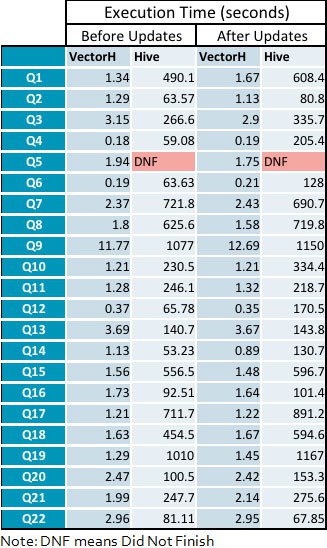
- Der durchschnittliche Geschwindigkeitszuwachs für VectorH gegenüber Hive steigt von 229x vor den Aktualisierungszyklen auf 331x nach der Anwendung von Aktualisierungen, mit einer Spanne von 23 bis 1141 bei einzelnen Abfragen.
Anhang: Detaillierte Anfrage
Abonnieren Sie den Actian Blog
Abonnieren Sie den Blog von Actian, um direkt Dateneinblicke zu erhalten.
- Bleiben Sie auf dem Laufenden: Holen Sie sich die neuesten Informationen zu Data Analytics direkt in Ihren Posteingang.
- Verpassen Sie keinen Beitrag: Sie erhalten automatische E-Mail-Updates, die Sie informieren, wenn neue Beiträge veröffentlicht werden.
- Ganz wie sie wollen: Ändern Sie Ihre Lieferpräferenzen nach Ihren Bedürfnissen.
Abonnieren
(d.h. sales@..., support@...)