Laut Gartnerkostet schlechte Datenqualität Unternehmen durchschnittlich 12,9 Millionen Dollar pro Jahr, während eine IBM-Studie aus dem Jahr 2025 zeigt, dass Unternehmen durchschnittlich 258 Tage benötigen, um eine Datenverletzung zu identifizieren und einzudämmen. Diese Statistiken offenbaren eine grundlegende Wahrheit: Governance kann nicht länger eine nachträgliche Überlegung oder ein manueller Prozess sein, sondern muss automatisiert, zentralisiert und in den Datenbetrieb eingebettet werden.
Ein Datenkatalog ist ein zentralisiertes Metadatensystem, das Unternehmen dabei hilft, ihre Daten zu finden, zu verstehen und zu verwalten. Innerhalb einer Data-Intelligence-Plattform bildet der Datenkatalog die Grundlage für die Suche und den Kontext, der Metadaten, Herkunft, Governance und Beobachtbarkeit im gesamten Unternehmen miteinander verbindet. Er bietet automatisierte Suche, Herkunftsangaben, Klassifizierung und Durchsetzung von Richtlinien, sodass Teams schnell vertrauenswürdige Daten finden und verantwortungsbewusst nutzen können.
Ein moderner Datenkatalog mit automatisierter Erkennung, zentralisierten Metadaten und Durchsetzung von Richtlinien verwandelt fragmentierte, riskante Data Governance in einen proaktiven, vertrauenswürdigen Self-Service-Zugriff, der die Compliance, Qualität und Entscheidungsfindung verbessert. Er steht für den Wandel von reaktiver Brandbekämpfung zu strategischer Daten-Stewardship und ermöglicht es Unternehmen, Daten in großem Umfang zu verwalten und gleichzeitig Analytics und Innovationen zu beschleunigen.
Datenkataloge erfordern mehr als nur eine einfache Suche und Bestandsaufnahme. Zu den wesentlichen Funktionen gehören die automatisierte Erkennung von Metadaten, die integrierte Abstimmung mit dem Geschäftsglossar, eine durchgängige Herkunftsverfolgung, rollenbasierte Zugriffskontrollen, die Durchsetzung von Richtlinien, ein Datenmarktplatz sowie Signale zur Datenqualität und Beobachtbarkeit. Wenn diese Funktionen als Teil einer Datenintelligenzplattform bereitgestellt werden, stellen sie sicher, dass vertrauenswürdige, kontrollierte Daten dort verfügbar sind, wo Analysen und KI tatsächlich eingesetzt werden.
Was ist ein Datenkatalog?
Ein Datenkatalog ist ein zentralisiertes System, das Metadaten inventarisiert, organisiert und anreichert, damit Nutzer Daten innerhalb eines Unternehmens finden, verstehen, vertrauen und verwalten können. Moderne Datenkataloge automatisieren die Metadatensammlung, verfolgen die Herkunft, wenden Governance-Richtlinien an und zeigen Qualitäts- und Vertrauensindikatoren an, um Analytics, Compliance und KI-Initiativen zu unterstützen.
Die wichtigsten Vorteile eines Datenkatalog
Moderne Datenkataloge bieten transformative Vorteile in den Bereichen Governance, Compliance und betriebliche Effizienz.
- Zentralisiert Metadaten aus allen Quellen in einem einzigen durchsuchbaren Repository, wodurch Datensilos vermieden werden.
- Verbessert die Datenqualität und das Vertrauen durch kontinuierliche Überwachung, Validierung und Qualitätsbewertung.
- Automatisiert die Klassifizierung und Durchsetzung von Richtlinienund gewährleistet so eine einheitliche Behandlung sensibler Daten.
- Beschleunigt Analysen und Self-Service , indem vertrauenswürdige Daten innerhalb von Minuten statt Wochen auffindbar gemacht werden.
- Verbessert die Einhaltung mit DSGVO, HIPAA und Branchenvorschriften.
- Bietet Herkunftsinformationen , um die Herkunft, Transformationen und Verwendung von Daten im gesamten Ökosystem zu verstehen.
- Reduziert das Betriebsrisiko und den manuellen Verwaltungsaufwand, sodass sich die Teams auf strategische Initiativen konzentrieren können.
- Ermöglicht die Demokratisierung von Daten und gewährleistet gleichzeitig Sicherheit und Kontrolle durch rollenbasierten Zugriff.
- Beschleunigt KI- und ML-Initiativen durch Bereitstellung vertrauenswürdiger, gut dokumentierter Trainingsdaten .
- Verbessert die Zusammenarbeit zwischen technischen und geschäftlichen Teams durch ein gemeinsames Verständnis.
Die wichtigsten Herausforderungen im Bereich Data Governance verstehen
Data Governance umfasst alle Richtlinien, Rollen und Prozesse, die sicherstellen, dass Daten im gesamten Unternehmen verfügbar, nutzbar, korrekt und sicher sind. Da Unternehmen immer mehr Daten aus unterschiedlichen Quellen erfassen, wird die Governance immer schwieriger und wichtiger.
Zu den größten Herausforderungen zählen fragmentierte Metadaten in voneinander getrennten Systemen, die zu inkonsistenten Ansichten führen und eine unternehmensweite Governance unmöglich machen. Datensilos bestehen weiterhin, da die Systeme der einzelnen Abteilungen nicht miteinander kommunizieren, was zu Datenduplikaten und Alpträumen bei der Versionskontrolle führt. Inkonsistente Geschäftsterminologie bedeutet, dass ein und dasselbe Konzept in verschiedenen Teams unterschiedliche Bezeichnungen haben kann, wie beispielsweise „Kunde” oder „Client”, während unterschiedliche Konzepte denselben Namen haben, was zu Verwirrung und Fehlern führt.
Manuelle Compliance-Prozesse sind nach wie vor langsam und fehleranfällig. Auf Tabellenkalkulationen basierende Datenbestände sind schnell veraltet. Zugriffsüberprüfungen finden vierteljährlich oder jährlich statt, sodass unangemessene Berechtigungen monatelang bestehen bleiben. Die Klassifizierung basiert auf manueller Kennzeichnung, wodurch sensible Daten übersehen oder Labels inkonsistent vergeben werden. Die Vorbereitung von Audits erfordert wochenlange manuelle Beweissicherung.
Schlechte Sichtbarkeit plagt Unternehmen: Teams können bereits vorhandene Datensätze nicht finden, was zu Doppelarbeit und verschwendeten Ressourcen führt. Ohne Insiderwissen oder zeitaufwändige Recherchen können sie die Qualität nicht beurteilen. Sie können die Herkunft der Daten nicht zurückverfolgen, um zu verstehen, woher sie stammen oder was davon abhängt, was eine Wirkungsanalyse unmöglich macht und die Untersuchung der Ursachen quälend langsam.
Ohne klare Zuständigkeiten und Verantwortlichkeiten verschlechtert sich die Datenqualität, da niemand die Verantwortung für Genauigkeit, Vollständigkeit oder Aktualität übernimmt. Das Vertrauen schwindet, wenn Nutzer wiederholt auf Qualitätsprobleme stoßen, und sie hören auf, offizielle Datenquellen zu nutzen, und greifen stattdessen auf unkontrollierte Alternativen zurück.
Die Folgen gehen über Ineffizienz hinaus: Bußgelder, Sicherheitsvorfälle und ins Stocken geratene Analyse- oder KI-Initiativen. Unternehmen, die versuchen, KI zu skalieren, stellen fest, dass die Modellentwicklung ohne zuverlässige, gut dokumentierte Trainingsdaten zum Erliegen kommt. Um vertrauenswürdigen Self-Service zu skalieren und datengesteuert zu werden, benötigen Unternehmen eine automatisierte, zentralisierte und in die täglichen Workflows integrierte Governance.
Automatisierung der Daten-Discovery und der Sammlung von Metadaten
Die automatisierte Erkennung durchsucht kontinuierlich Datenbanken, Dateien, Cloud-Speicher und Anwendungen, um Datenbestände zu identifizieren, wodurch manuelle Bestandsaufnahmen entfallen und eine umfassende Abdeckung gewährleistet wird. Moderne Discovery-Tools erkennen Quellspeicherorte, Schemata, Beziehungen und Nutzungsmuster und verbessern die Genauigkeit im Laufe der Zeit durch maschinelles Lernen.
Durch automatisiertes Metadaten-Harvesting lassen sich weitaus umfangreichere Informationen extrahieren, als dies mit manueller Dokumentation jemals möglich wäre. Technische Metadaten umfassen Schemadetails, Datentypen, Nullbarkeit, Eindeutigkeit, Kardinalität und statistische Profile, die Werteverteilungen und Qualitätsindikatoren zeigen. Geschäftliche Metadaten erfassen Zweck, Eigentumsverhältnisse, Qualitätsbewertungen und Nutzungsrichtlinien. Operative Metadaten verfolgen Zugriffsmuster, Performance der Abfragen, Datenaktualisierungspläne und Herkunftsangaben, die Transformationen aufzeigen.
Diese automatisierten Prozesse sorgen dafür, dass der Katalog stets mit der Realität synchronisiert ist. Wenn Entwickler Schemaänderungen über CI/CD-Pipelines bereitstellen, werden diese innerhalb weniger Stunden erkannt. Wenn neue Datenquellen online gehen, erscheinen sie automatisch im Katalog. Wenn Datensätze außer Betrieb genommen werden, spiegelt der Katalog deren Entfernung wider. Diese Synchronisation verhindert, dass der Katalog zu einem weiteren veralteten Dokumentationssystem wird, das von den Teams ignoriert wird.
Die Automatisierung verkürzt die Einarbeitungszeit für neue Quellen drastisch – von Wochen oder Monaten auf Stunden oder Tage –, sodass Analyseprojekte schneller gestartet werden können. Gleichzeitig gelten Governance-Richtlinien und Zugriffskontrollen ab dem Zeitpunkt der Erfassung.
Aufbau eines zentralisierten, umfassenden Datenkatalog
Ein zentralisierter Datenkatalog indexiert und organisiert alle Datenbestände des Unternehmens in einer einzigen durchsuchbaren Oberfläche, wodurch Silos aufgebrochen werden und schafft eine verlässliche zentrale Datenquelle. Diese Konsolidierung bringt unmittelbare praktische Nutzen mit sich. Nutzer benötigen nur noch wenige Minuten, um Datensätze zu finden, anstatt tagelang herumzufragen. Doppelte Arbeit wird drastisch reduziert, wenn Teams sehen können, was bereits vorhanden ist. Governance-Richtlinien werden einheitlich angewendet, da es einen einzigen Ort gibt, an dem sie definiert und durchgesetzt werden können. Die Vorbereitung von Audits wird beschleunigt, da alle Nachweise in einem System mit umfassender Protokollierung gespeichert sind.
Such- und Auffindungsfunktionen: Moderne Kataloge bieten mehrere Suchparadigmen, um unterschiedlichen Anforderungen der Nutzer gerecht zu werden. Die Stichwortsuche ermöglicht eine schnelle Suche nach Namen oder Beschreibung. Die semantische Suche versteht Geschäftskonzepte und findet Datensätze zum Thema „Umsatz“, wenn Nutzer nach „Verkäufen“ suchen. Die facettierte Suche ermöglicht das Filtern nach Quellsystem, Datendomäne, Eigentümer, Klassifizierung, Qualitätsbewertung oder Aktualität. Nutzer können Taxonomien und Hierarchien durchsuchen oder Empfehlungen basierend auf ihrer Rolle und früheren Nutzungsmustern folgen.
Datenqualität und Vertrauensindikatoren: Jeder Datensatz zeigt Qualitätsmetriken an, die anhand von Profiling- und Validierungsregeln berechnet wurden: Vollständigkeitsprozentsätze, Genauigkeitswerte, Aktualitätsindikatoren und Beständigkeit. Nutzerbewertungen und Kommentare liefern qualitatives Feedback. Nutzungsstatistiken zeigen die Beliebtheit an – Datensätze, die von erfahrenen Analysten häufig genutzt werden, signalisieren oft ein höheres Vertrauen als selten genutzte Ressourcen. Zertifizierungsabzeichen weisen auf eine formelle Überprüfung und Genehmigung durch die Verwalter hin.
Nutzungsanalyse: Der Datenkatalog verfolgt, wer wann und zu welchem Zweck auf Datensätze zugreift. Diese Transparenz macht beliebte Datenprodukte sichtbar, die zusätzliche Investitionen rechtfertigen, identifiziert ungenutzte Ressourcen, die für die Archivierung in Frage kommen könnten, und hilft den Verantwortlichen, die Auswirkungen ihrer Daten zu verstehen. Die Analytics erkennen auch ungewöhnliche Zugriffsmuster, die auf Sicherheitsprobleme oder Verstöße gegen Richtlinien hinweisen könnten.
Kollaborative Funktionen: Nutzer können Datensätze kommentieren, Anfragen stellen oder Erkenntnisse austauschen. Sie können die Datenqualität anhand ihrer Erfahrungen bewerten. Datenverwalter können Anwendungsbeispiele anhängen, die häufige Abfragen oder Analysemuster zeigen. Diskussionsstränge zu Datenbeständen schaffen institutionelles Wissen, das sonst in Slack-Kanälen oder E-Mail-Threads gespeichert wäre und später nur schwer wiederzufinden wäre.
Geschäftskontext und Standardisierung: Die Zentralisierung sorgt durch standardisierte Definitionen, Klassifizierungen und Glossare für eine beständige Geschäftssprache. Wenn „Kunde“ eine verbindliche Definition hat, die mit jedem Datensatz verknüpft ist, der Kundendaten enthält, gibt es keine Verwirrung mehr zwischen den Abteilungen. Die Teams stimmen sich in Bezug auf die Terminologie ab, wodurch Missverständnisse reduziert werden, die zu falschen Analysen oder doppelter Arbeit führen.
Moderne Kataloge speichern technische und geschäftliche Metadaten, Anwendungsbeispiele und Qualitätsbewertungen, damit Nutzer verstehen, was Daten bedeuten, wie sie erzeugt werden, wie zuverlässig sie sind und welche Use Cases und Einschränkungen für sie gelten.
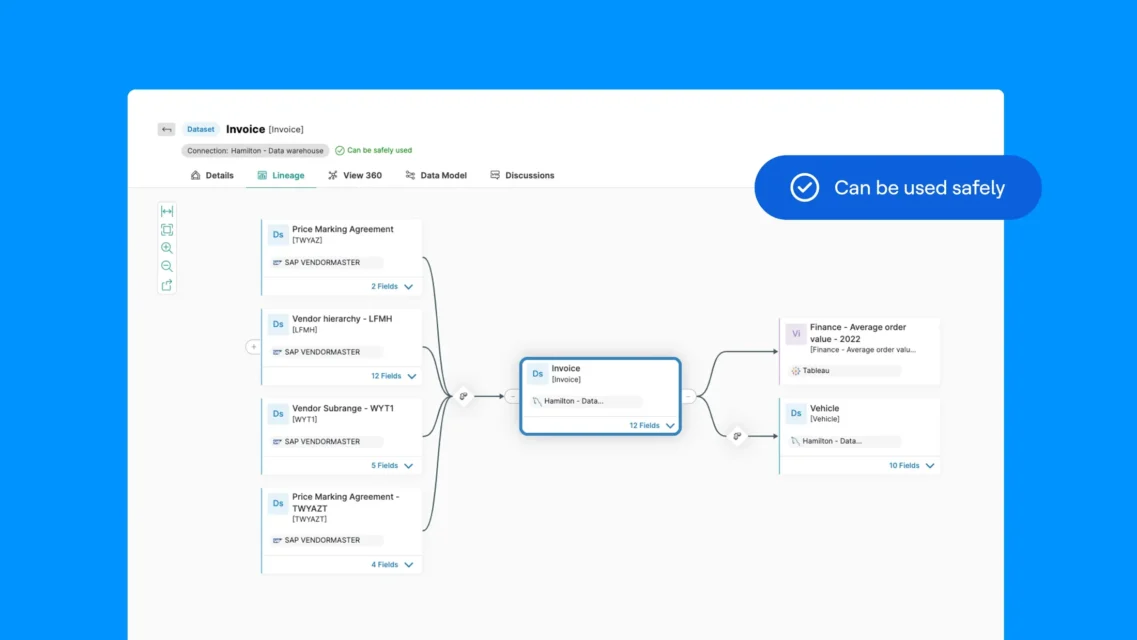
Datenherkunft und Auswirkungsanalyse
Die Visualisierung der Datenherkunft ist eine der leistungsstärksten Governance-Fähigkeiten. Sie zeigt, wie Daten von Quellsystemen über Transformationen, Integrationen und Analytics bis hin zu den endgültigen Verbrauchsstellen fließen. Eine vollständige Herkunftsangabe beantwortet wichtige Fragen, die mit manueller Dokumentation nur schwer zu beantworten sind: Woher stammt dieser Wert? Welche Transformationen wurden angewendet? Welche Berichte und Modelle basieren auf diesem Datensatz? Was wird nachgelagert beeinträchtigt, wenn ich diese Tabelle ändere?
End-to-End-Flussvisualisierung: Moderne Kataloge erstellen umfassende Herkunftsdiagramme, die sich über die gesamte Datenlandschaft erstrecken. Diese Transparenz erstreckt sich über Technologien und Plattformen hinweg und zeigt die Herkunft auch dann, wenn Daten Systemgrenzen überschreiten.
Abstammung auf Spaltenebene: Für die Einhaltung gesetzlicher Vorschriften und eine gründliche Auswirkungsanalyse reicht die Herkunftsnachverfolgung auf Tabellenebene oft nicht aus. Die Herkunftsnachverfolgung auf Spaltenebene verfolgt einzelne Felder durch Transformationen und zeigt, dass „annual_revenue” in einem Bericht letztendlich aus „total_sales” im Quellsystem nach Währungsumrechnung und Aggregation stammt. Diese Granularität erweist sich als unerlässlich für Datenschutzbestimmungen, die eine Dokumentation des Flusses personenbezogener Daten durch Systeme erfordern, sowie für Qualitätsuntersuchungen, die eine genaue Identifizierung der Ursachen erfordern.
Ursachenanalyse für Qualitätsprobleme: Wenn Probleme mit der Datenqualität auftreten, ermöglicht die Herkunftsanalyse eine schnelle Untersuchung. Wenn ein Dashboard falsche Werte anzeigt, verfolgen Teams die Herkunft durch Transformationen zurück, um festzustellen, wo Fehler entstanden sind. Waren es fehlerhafte Quelldaten? Ein Logikfehler im Transformationscode? Ein unerwarteter Nullwert, der die Berechnungen beeinträchtigt hat? Die Herkunftsanalyse verkürzt die Untersuchungszeit von Tagen auf Stunden, indem sie einen direkten Weg zum Problem aufzeigt.
ML-Modell-Governance: Da Unternehmen immer mehr maschinelles Lernen einsetzen, wird die Herkunft für die Modell-Governance und die Erklärbarkeit unerlässlich. Sie dokumentiert, welche Trainingsdaten verwendet wurden, wie Merkmale entwickelt wurden, welche Vorverarbeitung stattgefunden hat und ob sich seit dem Deployment Änderungen an diesen Komponenten ergeben haben. Wenn die Modellleistung nachlässt, hilft die Herkunft dabei, zu diagnostizieren, ob die Ursache Datenabweichungen, Konzeptabweichungen oder Änderungen in den vorgelagerten Datenquellen sind.
Entwicklung von Datenprodukten: Unternehmen, die interne Datenprodukte entwickeln – kuratierte Datensätze, die zur teamübergreifenden Wiederverwendung veröffentlicht werden – sind auf die Herkunft der Daten angewiesen, um Abhängigkeiten zu verstehen und die Zuverlässigkeit sicherzustellen. Produktverantwortliche können alle vorgelagerten Quellen, von denen ihr Produkt abhängt, und alle nachgelagerten Verbraucher, die davon abhängig sind, einsehen, was ein ordnungsgemäßes Änderungsmanagement und SLA ermöglicht.
Durchsetzung rollenbasierter Zugriffskontrollen und Sicherheitsrichtlinien
Die rollenbasierte Zugriffskontrolle (RBAC) weist Berechtigungen nach Rollen zu und stellt so sicher, dass nur autorisierte Benutzer auf sensible Daten zugreifen können, während eine legitime geschäftliche Nutzung ermöglicht wird. In einem Katalog ordnet RBAC Jobfunktionen bestimmten Anzeige-, Bearbeitungs- und Nutzungsrechten zu und gewährleistet so einen konsistenten und überprüfbaren Zugriff.
Die Integration von RBAC in die Sicherheitsrichtlinien des Unternehmens zentralisiert die Durchsetzung und vereinfacht Compliance-Audits. Die Automatisierung von Zugriffsentscheidungen auf der Grundlage vordefinierter Regeln reduziert den IT-Aufwand und beseitigt Ad-hoc-Berechtigungsverfahren, die Lücken schaffen. Wenn neue Analysten hinzukommen, erhalten sie automatisch Standardberechtigungen für Analysten, die auf ihrer Abteilung und ihrem Dienstalter basieren. Bei Versetzungen von Mitarbeitern werden deren Berechtigungen automatisch angepasst. Wenn Mitarbeiter das Unternehmen verlassen, wird ihr Zugriff sofort in allen verwalteten Systemen widerrufen. Diese Automatisierung macht den manuellen, ticketbasierten Prozess für Zugriffsanfragen überflüssig, der zu Verzögerungen und Inkonsistenzen führt.
Erweitertes RBAC kann kontextsensitiv sein – Berechtigungen werden je nach Zeit, Ort, Gerät oder Zweck angepasst –, wodurch ein Gleichgewicht zwischen strengem Schutz sensibler Informationen und operativer Flexibilität für legitime Workflows hergestellt wird.
Dieser ausgeklügelte Ansatz schafft ein Gleichgewicht zwischen dem strengen Schutz sensibler Informationen und der operativen Flexibilität für legitime Workflows. Ein Data-Scientist kann während der Geschäftszeiten auf einem Firmenlaptop auf vollständige Kundenaufzeichnungen für das Modelltraining zugreifen, sieht jedoch auf seinem privaten Gerät zu Hause nur aggregierte Statistiken. Ein Auftragnehmer kann während seiner Vertragslaufzeit auf projektspezifische Datensätze zugreifen, verliert jedoch automatisch den Zugriff, wenn das Arbeitsverhältnis endet.
Implementierung einer automatisierten Klassifizierung und Durchsetzung von Richtlinien
Die automatisierte Klassifizierung verwendet Algorithmen und maschinelles Lernen, um Daten nach Typ, Sensibilität und regulatorischen Anforderungen zu kennzeichnen, wodurch eine Beständigkeit in der Handhabung im gesamten Datenbestand ermöglicht wird. Dies ersetzt die fehleranfällige manuelle Kennzeichnung und stellt sicher, dass sensible Aufzeichnungen (personenbezogene Daten, Finanzdaten, geistiges Eigentum) zuverlässig identifiziert werden.
Klassifizierungen umfassen mehrere Dimensionen: Datentyp gibt an, ob es sich um personenbezogene Daten, Gesundheitsdaten, Finanzdaten, geistiges Eigentum oder öffentliche Informationen handelt. Sensitivitätsstufe stuft Daten als öffentlich, intern, vertraulich oder eingeschränkt ein. Regulatorischer Geltungsbereich kennzeichnet Daten, die der DSGVO, HIPAA, PCI DSS, CCPA oder branchenspezifischen Vorschriften unterliegen. Aufbewahrungsvorschriften legen fest, wie lange Daten aufbewahrt werden müssen und wann sie gelöscht werden sollten. Geografische Beschränkungen Geben an, wo Daten gespeichert werden dürfen und wer auf sie zugreifen darf, basierend auf den Gesetzen zur Datenresidenz.
Die Durchsetzung von Richtlinien nutzt diese Klassifizierungen, um automatisch Kontrollen anzuwenden – Zugriffsbeschränkungen, Maskierung, Aufbewahrungsregeln und Überwachung – und gleichzeitig kontinuierlich nach Verstößen gegen Richtlinien zu suchen. Die Plattform kann ungewöhnliche Zugriffe kennzeichnen, Warnmeldungen generieren und Workflows auslösen, um menschliche Fehler und Verzögerungen bei der Durchsetzung zu reduzieren.
Das automatisierte Compliance-Reporting erstellt Protokolle und Berichte (wer wann und unter welchen Kontrollen auf welche Daten zugegriffen hat), die für die DSGVO, HIPAA und andere Vorschriften erforderlich sind, und reduziert so den Aufwand und das Risiko des manuellen Reportings.
Protokolle pflegen und proaktive Compliance-Überwachung ermöglichen
Protokolle zeichnen chronologische Aktionen an Datenbeständen auf – Zugriffe, Bearbeitungen, Metadatenänderungen und Aktualisierungen der Herkunft – und liefern wichtige Nachweise für die Rechenschaftspflicht, die Untersuchung von Vorfällen und behördliche Audits. Protokolle erfassen direkte und indirekte Nutzungen (Berichte, Analytics, Pipelines), um forensische Analysen und Risikobewertungen zu unterstützen.
Proaktive Compliance-Überwachung analysiert kontinuierlich Zugriffsmuster, die Einhaltung von Richtlinien und Anomalien in der Nutzung, um Probleme zu erkennen, bevor sie eskalieren. Wenn Anomalien auftreten, kann das System je nach Schweregrad die Stakeholder benachrichtigen, Workflows einleiten oder automatische Korrekturen durchsetzen.
Fortgeschrittene Überwachung kann vorausschauende Erkenntnisse aus historischen Mustern liefern und Teams dabei helfen, Compliance-Risiken zu antizipieren und zu verhindern, anstatt erst nachträglich darauf zu reagieren.
Erleichtern Sie die Zusammenarbeit mit vorlagengesteuerter Dokumentation
Vorlagenbasierte Dokumentation standardisiert die Erfassung und Darstellung von Metadaten, Geschäftskontext, Steward-Zuweisungen und Richtlinien, wodurch Variabilität und manueller Aufwand reduziert werden. Dank Drag-and-Drop-Funktion und geführten Formularen können auch nicht-technische Mitwirkende ohne spezielle Kenntnisse Kontext, Geschäftsregeln und Anwendungshinweise hinzufügen.
Plattformen bieten in der Regel auf bestimmte Rollen zugeschnittene Module: Studio-Module für Datenverwalter verwalten und Richtlinien sowie Explorer-Module für Geschäftsanwender, um Assets zu entdecken und Fachwissen beizusteuern. Vorlagen unterstützen Asset-Register, Glossare, Verwaltungsaufgaben, Richtlinienerklärungen und Nutzungsrichtlinien, allesamt mit Genehmigungs-Workflows und Versionskontrolle, um die Genauigkeit zu gewährleisten.
Dieser strukturierte, kollaborative Ansatz verteilt die Dokumentationsarbeit, gewährleistet die Qualität und stellt sicher, dass veröffentlichte Informationen überprüft und durch Governance kontrolliert werden.
Bewährte Verfahren für eine erfolgreiche Implementierung eines Datenkatalogs
Die erfolgreiche Implementierung eines Katalogs erfordert die Berücksichtigung sowohl technologischer als auch personeller Aspekte. Zu den wichtigsten Vorgehensweisen gehören:
- Zuweisung einer klaren Zuständigkeit: Benennen Sie Eigentümer und Datenverwalter alle wichtigen Datenbereiche mit definierten Verantwortlichkeiten für Dokumentation, Qualität und Zugriffskontrolle.
- Entwicklung und Pflege eines standardisierten Geschäftsglossars: Vereinheitlichen Sie die Terminologie aller Teams durch verbindliche Definitionen von Geschäftsbegriffen, Kennzahlen und Konzepten. Das Glossar bildet die semantische Grundlage und sorgt dafür, dass alle dieselbe Sprache sprechen.
- Automatisierung von Metadaten : Integrieren Sie Katalogaktualisierungen in CI/CD- und Datenpipeline-Deployments, damit Metadaten automatisch auf dem neuesten Stand bleiben.
- Bereitstellung rollenbasierter Schulungen: Passen Sie Training Datenverwalter, Dateningenieure, Analysten und Geschäftsanwender mit praktischen Szenarien an, die den Wert des Katalogs für jede Rolle aufzeigen.
- Integrieren Sie den Katalog in Ihre Workflows:Betten Sie Katalogfunktionen dort ein, wo Nutzer bereits arbeiten, damit die Governance eingebettet ist und kein weiterer Schritt mehr erforderlich ist.
Unternehmen, die diese Praktiken anwenden, berichten von einer besseren Datentransparenz, schnelleren Erkenntnissen, einer stärkeren Überprüfbarkeit und einem höheren Vertrauen in die Analytics-Ergebnisse. Der Datenkatalog wandelt sich von einer Compliance-Anforderung zu einer strategischen Funktion, die sichere und schnelle Innovationen ermöglicht.
Wie sich moderne Datenkataloge von herkömmlichen Katalogtools unterscheiden
Herkömmliche Datenkatalog-Tools konzentrieren sich in erster Linie auf Bestandsaufnahme und Suche. Diese Tools sind zwar nützlich, verfügen jedoch häufig nicht über die für Analysen und KI im Unternehmensmaßstab erforderlichen Funktionen wie Echtzeit-Metadaten-Synchronisierung, ein einheitliches Geschäftsglossar, umfassende Herkunftsangaben, eingebettete Governance und Qualitätssignale.
Moderne Datenkataloge sind Teil einer umfassenderen Data-Intelligence-Plattform. Sie erfassen kontinuierlich technische, geschäftliche und betriebliche Metadaten, verbinden Herkunft, Beobachtbarkeit und Definitionen aus dem Geschäftsglossar miteinander und betten Governance-Richtlinien direkt in die Art und Weise ein, wie auf Daten zugegriffen und diese genutzt werden. Durch diesen Wandel wird der Katalog von einem passiven Referenzsystem zu einer aktiven Kontroll- und Vertrauensschicht für Unternehmensdaten.
Datenkatalog vs. traditionelle und Punktlösungen
Viele Unternehmen setzen Punktlösungen für den Datenkatalog, Geschäftsglossare, Herkunft oder Datenqualität ein. Diese Tools erfüllen zwar einzelne Anforderungen, führen jedoch häufig zu fragmentierten Erfahrungen, die schwer skalierbar sind.
Ein moderner Datenkatalog einer Data-Intelligence-Plattform vereint Discovery, Definitionen aus dem Geschäftsglossar, Herkunft, Governance und Beobachtbarkeit einem einzigen System. Dadurch werden isolierte Tools überflüssig, der manuelle Integrationsaufwand reduziert und sichergestellt, dass Governance-Richtlinien und Vertrauenssignale konsistent in allen Analyse- und KI-Workflows angewendet werden.
Im Gegensatz zu eigenständigen Katalogtools ermöglicht ein integrierter Ansatz Unternehmen, über die Bestandsaufnahme hinaus zu einer aktiven Governance, Self-Service vertrauenswürdigen Self-Service und KI-fähigen Daten im Unternehmensmaßstab zu gelangen.
FAQ
Ein Datenkatalog ist ein zentralisiertes Metadaten-System, das Teams dabei hilft, Unternehmensdaten zu finden, zu verstehen und zu verwalten. Er scannt automatisch Datenquellen, sammelt Metadaten, klassifiziert sensible Informationen, ordnet Herkunftsbeziehungen zu und setzt Governance-Richtlinien durch, sodass Nutzer schnell vertrauenswürdige Daten für Analytics und KI finden können.
Ein Datenkatalog unterstützt die Datenintelligenz, indem er als primäre Erkennungs- und Kontextschicht fungiert, die Metadaten, Herkunft, Governance und Datenqualität im gesamten Unternehmen miteinander verbindet.
Innerhalb einer Data-Intelligence-Plattform sammelt der Datenkatalog kontinuierlich technische, geschäftliche und betriebliche Metadaten, wodurch Datenbestände durchsuchbar, verständlich und in großem Umfang verwaltet werden können. Er bietet Einblick in Eigentumsverhältnisse, Nutzung, Herkunft und Vertrauensindikatoren, sodass Analyseteams, KI-Systeme und Nutzer sicher die richtigen Daten für ihre Anforderungen auswählen können.
Ohne einen Datenkatalog fehlt der Datenintelligenz eine praktische Schnittstelle für die Ermittlung und Nutzung. Der Katalog stellt sicher, dass die Intelligenz nicht nur dokumentiert, sondern auch aktiv in Analysen, KI und operativen Workflows genutzt wird.
Ein Datenkatalog bietet die Transparenz und Kontrolle, die Governance-Teams benötigen. Er zentralisiert Metadaten, standardisiert Definitionen, setzt Zugriffsrichtlinien durch und automatisiert die Überwachung der Compliance. Dies reduziert Risiken, verbessert die Datenqualität und gewährleistet eine konsistente Governance über den gesamten Datenbestand hinweg.
Ein Datenkatalog löst die zentralen Herausforderungen, die Unternehmen daran hindern, Daten vertrauensvoll zu nutzen und deren Verwendung auszuweiten. Er beseitigt fragmentierte Metadaten, reduziert doppelte Analytics-Arbeiten und macht kontrollierte, hochwertige Daten leicht auffindbar und verständlich.
Moderne Datenkataloge befassen sich mit häufigen Problemen wie inkonsistenten Geschäftsdefinitionen, eingeschränkter Transparenz der Herkunft, manuellen Compliance-Prozessen und geringem Vertrauen in Analyseergebnisse. Durch die Zentralisierung von Metadaten, Herkunft, Governance-Kontext und Qualitätsindikatoren ermöglicht ein Datenkatalog eine schnellere Entscheidungsfindung, eine stärkere Compliance und zuverlässige KI- und Analytics-Initiativen.
Datenkataloge erfordern mehr als nur eine einfache Suche und Bestandsaufnahme. Zu den wesentlichen Funktionen gehören die automatisierte Erkennung von Metadaten, durchgängige Herkunftsnachverfolgung, rollenbasierte Zugriffskontrollen, Durchsetzung von Richtlinien, Signale zur Datenqualität und Beobachtbarkeit sowie Support für Hybrid- und Multi-Cloud-Umgebungen.
In der Praxis lassen sich diese Fähigkeiten dann skalieren, wenn der Katalog als Teil einer umfassenderen Data-Intelligence-Plattform betrieben wird, in der Governance-Workflows, Vertrauensindikatoren und der geschäftliche Kontext direkt auf den Zugriff und die Nutzung von Daten in Analyse- und KI-Systemen angewendet werden. Ohne diese Grundlage können Kataloge nur in kleinen Teams oder für reine Compliance-Anwendungsfälle eingesetzt werden.
KI verbessert einen Datenkatalog durch die Automatisierung von Erkennung, Klassifizierung und Anreicherung von Metadaten. Maschinelles Lernen identifiziert Datenmuster, erkennt Anomalien, empfiehlt verwandte Assets, kennzeichnet Qualitätsprobleme und prognostiziert potenzielle Compliance-Risiken. Diese Funktionen helfen Unternehmen dabei, ihre Governance mit weniger manuellem Aufwand zu skalieren.
Ja. Ein moderner Datenkatalog spielt eine entscheidende Rolle in der KI und beim maschinellen Lernen, indem er die Metadaten, die Herkunft und die Qualitätskontextmodelle bereitstellt, auf denen diese basieren.
KI-Initiativen erfordern vertrauenswürdige Training-Daten, nachvollziehbare Feature-Pipelines und Transparenz darüber, wie sich Daten im Laufe der Zeit verändern. Ein Datenkatalog ermöglicht dies, indem er Datenherkünfte, Transformationen, Qualitätssignale und Nutzungsbeschränkungen dokumentiert – wodurch Risiken, Verzerrungen und Modellabweichungen reduziert und gleichzeitig Transparenz und Governance verbessert werden.
Open-Source-Kataloge bieten Flexibilität für Teams, die ihre eigenen Tools anpassen möchten, aber möglicherweise mehr technische Ressourcen benötigen. Unternehmensdatenkataloge bieten integrierte Automatisierung, Governance-Workflows, Sicherheitskontrollen, Scalability, Support und Integration mit umfassenderen Datenplattformen, wodurch sie sich besser für regulierte oder groß angelegte Umgebungen eignen.


