Beschleunigung von Spark mit Actian Vector in Hadoop





Action Vector 7.0 wird ab Version 8.0 in Actian Analytics Engine umbenannt
Eines der heißesten Projekte in der Apache Hadoop-Community ist Spark, und wir bei Actian freuen uns, einen Spark-Vector Konnektor für die Actian Vector in Hadoop Plattform (VectorH) anzukündigen, der die beiden miteinander verbindet. VectorH bietet die schnellste und vollständigste SQL in Hadoop-Lösung, und die Verbindung zu Spark eröffnet Schnittstellen zu neuen Datenformaten und Funktionen wie Streaming und Maschinelles Lernen.
Warum VectorH mit Spark verwenden?
VectorH ist ein High-Performance, ACID-konformes analytisches SQL-Datenbankmanagementsystem, das das Hadoop Distributed File System (HDFS) oder MapR-FS für die Speicherung und Hadoop YARN für die Ressourcenverwaltung nutzt. Wenn Sie in SQL schreiben und komplexe SQL-Aufgaben durchführen möchten, benötigen Sie VectorH. SparkSQL ist nur eine Teilmenge von SQL und muss von einem in Skala, R, Python oder Java geschriebenen Programm aufgerufen werden.
VectorH ist ein ausgereiftes, unternehmenstaugliches RDBMS mit einem fortschrittlichen abfragen , Unterstützung für inkrementelle Updates und Zertifizierung mit den gängigsten BI-Tools. Es enthält auch erweiterte Sicherheitsfunktionen und Workload . Das spaltenförmige Datenformat in VectorH und die optimierte Komprimierung bedeuten eine schnellere abfragen und eine effizientere Speichernutzung als bei anderen gängigen Hadoop-Formaten.
Warum Spark mit VectorH verwenden?
Spark bietet eine verteilte Rechenmaschine, die die Funktionalität um neue Dienste wie strukturierte Verarbeitung, Streaming, Maschinelles Lernen und Graphenanalyse erweitert. Spark, als Plattform für den Data-Scientist, ermöglicht jedem, der mit Skala, R, Python oder Java arbeiten möchte.
Dieser Spark-Vector Konnektor erweitert den Zugang von VectorH zu den breiteren Möglichkeiten der Spark-Konnektivität und -Funktionalität erheblich. Ein sehr leistungsfähiger use case ist die Fähigkeit, Daten von Spark in VectorH auf hochparallele Weise zu übertragen. Diese ETL-Fähigkeit ist einer der häufigsten Anwendungsfälle für Apache Spark.
Wenn Sie noch kein Spark-Programmierer sind, bietet der Konnektor einen einfachen Kommandozeilen-Loader, der Spark intern nutzt und es Ihnen ermöglicht, CSV-, Parquet und ORC-Dateien zu laden, ohne dass Sie eine einzige Zeile Spark-Code schreiben müssen. Spark ist eine standardmäßig unterstützte Komponente in allen wichtigen Hadoop-Distributionen, so dass Sie den Konnektor verwenden können, wenn Sie den Informationen auf der Konnektor folgen.
Wie funktioniert es?
Der Konnektor lädt Daten von Spark in Vector und holt Daten per SQL aus VectorH. Der erste Teil wird parallel durchgeführt: Die Daten kommen von jedem Input RDD Partition werden mit Hilfe des binären Protokolls von Vector serialisiert und über Socket-Verbindungen zu den Vector-Endpunkten unter Verwendung der DataStream-API von Vector übertragen. Die meiste Zeit wird dieser Konnektor nur lokale RDD innerhalb jedes Vector-Endpunkts zuweisen, um die Lokalität der Daten zu erhalten und Verzögerungen durch Netzwerkkommunikation zu vermeiden. Im Falle des Datenabruf von Vector in Spark werden die Daten aus Vector exportiert und über eine JDBC-Verbindung zum führenden Vector-Knoten in Spark eingespeist. Der Konnektor funktioniert sowohl mit Vector SMP als auch mit VectorH MPP und mit Spark 1.5.x. Ein Überblick über die Datenbewegung ist unten dargestellt:
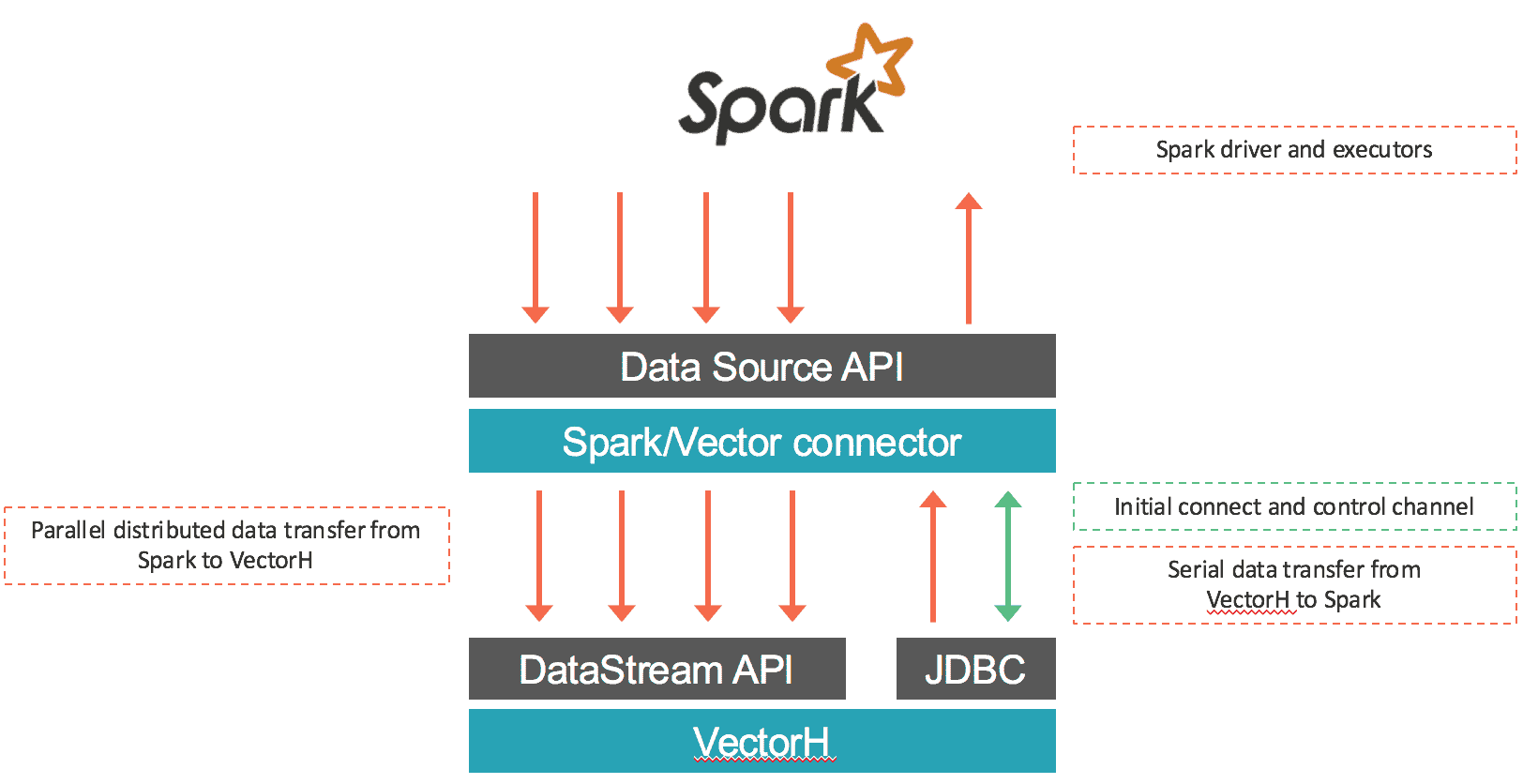
Was gibt es sonst noch?
Diese neueste Version von VectorH (4.2.3) enthält auch die folgenden neuen Funktionen:
- YARN-Unterstützung für MapR, zusätzlich zu den bereits zertifizierten Distributionen von Cloudera und Hortonworks. Mit der nativen Unterstützung in YARN können Sie mehrere Workloads im selben Cluster ausführen und den gesamten Ressourcenpool gemeinsam nutzen.
- Pro abfragen können Profildateien in ein bestimmtes Verzeichnis, einschließlich eines HDFS-Verzeichnisses, geschrieben werden. Diese Funktion bietet mehr Flexibilität und Kontrolle bei der verwalten und gemeinsamen Nutzung von abfragen durch verschiedene Benutzer.
- Neue Optionen zur Anzeige des Status der Cluster , einschließlich des grundlegenden Zustands der Knoten, des Kerberos-Zugriffs (falls aktiviert), des MPI-Zugriffs, des HDFS-Safemodus und des HDFS-fsck.
- Eine neue Option zur Erstellung von MinMax-Indizes auf einer Teilmenge von Spalten sowie eine verbesserte Speicherverwaltung von MinMax, was zu einem geringeren CPU und Speicher-Overhead führt.
Erfahren Sie mehr unter https://www.actian.com/products/ oder kontaktieren Sie sales@actian.com, um mit einem Vertreter zu sprechen.
Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)