Marquez: Die Metadaten bei WeWork





WeWork wurde 2010 gegründet und ist ein weltweit tätiges Unternehmen, das Büros und Arbeitsräume vermietet. Ihr Ziel ist es, Teams jeder Größe - von Start-ups über KMU bis hin zu Großunternehmen - Raum für die Zusammenarbeit zu bieten. Um dies zu erreichen, kann das Angebot von WeWork in drei verschiedene Kategorien unterteilt werden:
- Weltraum: Um den Unternehmen einen optimalen Raum zu bieten, muss WeWork die entsprechende Infrastruktur bereitstellen, d. h. Räume für Vorstellungsgespräche / Einzelgespräche oder sogar ganze Gebäude für große Unternehmen buchen. Sie müssen auch sicherstellen, dass sie mit den entsprechenden Einrichtungen wie Küchen für Mittagspausen und Kaffeepausen, Badezimmern usw. ausgestattet sind.
- Gemeinschaft: Über die interne Anwendung von WeWork ermöglicht das Unternehmen den WeWork-Mitgliedern, miteinander in Kontakt zu treten, sei es lokal in ihrem eigenen WeWork-Raum oder weltweit. Wenn ein Unternehmen beispielsweise Feedback für ein Projekt von bestimmten Berufsgruppen benötigt (z. B. Entwickler oder UX-Designer), kann es über die Anwendung jedes Mitglied direkt um Feedback und Vorschläge bitten, unabhängig von dessen Standort.
- Dienstleistungen: WeWork bietet seinen Mitgliedern auch einen umfassenden IT-Service bei Problemen sowie andere Dienstleistungen wie Lohnbuchhaltung, Versorgungsdienste usw.
Im Jahr 2020 steht WeWork für:
- Mehr als 600.000 Mitgliedschaften.
- Standorte in 127 Städten in 33 verschiedenen Ländern.
- 850 Büros weltweit.
- Erwirtschaftete 1,82 Milliarden Dollar an Einnahmen.
Es ist klar, dass WeWork mit allen Arten von Daten seiner Mitarbeiter und Kunden arbeitet, egal ob es sich dabei um Einzelpersonen oder Unternehmen handelt. Das große Unternehmen benötigte daher eine Plattform, auf der seine Datenexperten die Metadaten ihres Datenökosystems anzeigen, sammeln, aggregieren und visualisieren konnten. Diese Aufgabe wurde durch die Gründung von Marquez gelöst.
Dieser Artikel wird sich auf die Implementierung von Marquez durch WeWork konzentrieren, hauptsächlich durch die frei zugängliche Dokumentation, die auf verschiedenen Websites zur Verfügung gestellt wird, um die Bedeutung einer unternehmensweiten Metadaten zu veranschaulichen, um wirklich data-driven zu werden.
Warum Metadaten verwalten und nutzen?
In seinem Vortrag "A Metadaten Service for Data Abstraction, Data Lineage & Event-Based Triggers" auf dem Data Council im Jahr 2018 erklärte Willy Lulciuc, Software Engineer für das Marquez-Projekt bei WeWork, dass Metadaten aus drei Gründen entscheidend ist:
- Sicherstellung der Datenqualität: Wenn Daten keinen Kontext haben, ist es für die Bürger schwer, ihren Datenbeständen zu vertrauen: Fehlen Felder? Ist die Dokumentation auf dem neuesten Stand? Wer ist der Eigentümer der Daten und ist er es noch? Diese Fragen werden durch den Einsatz von Metadaten beantwortet.
- Verstehen der Datenherkunft: Die Kenntnis der Datenherkunft und -umwandlung ist der Schlüssel, um wirklich zu wissen, welche Phasen Ihre Daten im Laufe der Zeit durchlaufen haben.
- Demokratisierung von Datensätzen: Laut Willy Lulciuc ist die Demokratisierung von Daten im Unternehmen entscheidend! Ein zentrales Portal oder eine zentrale Benutzeroberfläche, über die Nutzer ihre Daten suchen und erkunden können, ist eine der wichtigsten Möglichkeiten für Unternehmen, eine echte Self-Service zu schaffen.
Zusammengefasst: Schaffung eines gesunden Datenökosystems. Willy erklärt, dass die Fähigkeit, Metadaten verwalten und zu nutzen, eine nachhaltige Datenkultur schafft, in der die Menschen nicht mehr um Hilfe bitten müssen, um die benötigten Daten zu finden und damit zu arbeiten. In seiner Folie geht er auf drei verschiedene Kategorien ein, die ein gesundes Daten-Ökosystem ausmachen:
- Ein Self-Service-Ökosystem zu sein, in dem Daten- und Geschäftsnutzer die Möglichkeit haben, die von ihnen benötigten Daten und Metadaten zu entdecken und die Datenbestände des Unternehmens zu erkunden, wenn sie nicht genau wissen, wonach sie suchen. Die Bereitstellung von Daten mit Kontext gibt allen Nutzern und Datenbürgern die Möglichkeit, effektiv an ihren Daten zu arbeiten.
- Selbstständigkeit, indem den Datennutzern die Freiheit gegeben wird, mit ihren Datensätzen zu experimentieren, und indem sie die Flexibilität haben, jeden Aspekt ihrer Datensätze zu bearbeiten, egal ob es sich beispielsweise um Eingabe- oder Ausgabedatensätze handelt.
- Und schließlich, anstatt sich auf bestimmte Personen oder Gruppen zu verlassen, ermöglicht ein gesundes Datenökosystem allen Mitarbeitern, für ihre eigenen Daten verantwortlich zu sein. Jeder Nutzer ist dafür verantwortlich, seine Daten und deren Kosten zu kennen (bringen diese Daten genug Wert?) und die Dokumentation seiner Daten im Auge zu behalten, um Vertrauen in seine Datensätze aufzubauen.
Zimmerbuchungs-Pipeline Vorher
Wie bereits erwähnt, ist die Verwendung von Metadaten von entscheidender Bedeutung für Datenbenutzer, um die von ihnen benötigten Daten zu finden. In seiner Präsentation teilte Willy eine reale Situation, um zu beweisen, dass Metadaten unerlässlich sind: Die Datenpipeline von WeWork für die Buchung eines Zimmers.
Für einen "WeWorker" sind die Schritte wie folgt:
- Finden Sie einen Standort (das Beispiel war ein Gebäudekomplex in San Francisco).
- Wählen Sie die geeignete Raumgröße (in der Regel nach der Anzahl der Teilnehmer aufgeteilt - in diesem Fall wurde ein Raum gewählt, der 1 - 4 Personen aufnehmen kann).
- Wählen Sie das Datum, an dem die Buchung stattfinden soll.
- Legen Sie das Zeitfenster fest, für das der Raum gebucht wird, sowie die Dauer der Sitzung.
- Bestätigen Sie die Buchung.
Nachdem wir nun ein Beispiel dafür haben, wie die Buchungspipeline funktioniert, demonstriert Willy, wie ein typisches Datenteam vorgehen würde, wenn es Daten über die Buchungen von WeWork auslesen wollte. In diesem Fall bestand die Beispielübung darin, das Gebäude mit den meisten Raumbuchungen zu finden und diese Daten zu extrahieren, um sie an das Management zu senden. Die Schritte, die er nannte, waren die folgenden:
- Lesen Sie die Raumbuchungen aus einer (meist unbekannten) Datenquelle.
- Fassen Sie alle Zimmerbuchungen zusammen und geben Sie die besten Standorte an.
- Sobald die oberste Position berechnet ist, besteht der nächste Schritt darin, sie in eine Ausgabedatenquelle zu schreiben.
- Führen Sie den Auftrag einmal pro Stunde aus.
- Verarbeiten Sie die Daten über .csv-Dateien und speichern Sie sie irgendwo.
Willy erklärte jedoch, dass, auch wenn diese Schritte gut genug zu sein scheinen, in der Regel doch Probleme auftreten. Er geht auf drei Arten von Problemen während des Arbeitsprozesses ein:
- Wo finde ich den Datensatz des Job-Inputs?
- Hat der Datensatz einen Eigentümer? Wer ist es?
- Wie oft wird der Datensatz aktualisiert?
Die meisten dieser Fragen sind schwer zu beantworten, und die Aufträge scheitern am Ende. Wenn man sich nicht sicher ist und diesen Informationen nicht vertraut, kann es schwierig sein, dem Management Zahlen zu präsentieren. Diese Art von Problemen und Fragen waren es, die WeWork dazu veranlassten, Marquez zu entwickeln.
Was ist Marquez?
Willy definiert die Plattform als eine "Open-Source-Lösung für die Aggregation, Sammlung und Visualisierung von Metadaten des Datenökosystems von [WeWork]". In der Tat ist Marquez ein modulares System und wurde als hoch skalierbar, hochgradig erweiterbare, plattformunabhängige Lösung für das Metadaten konzipiert. Es besteht aus den folgenden Komponenten:
- Metadaten Lager: Speichert alle Job- undMetadaten, einschließlich einer vollständigen Historie der Job-Läufe und Statistiken auf Job-Ebene (d.h. Gesamtläufe, durchschnittliche Laufzeiten, Erfolge/Misserfolge usw.).
- Metadaten API: RESTful API, die es einer Vielzahl von Kunden ermöglicht, Metadaten rund um die Datensatz und -nutzung zu sammeln.
- Metadaten UI: Dient derEntdeckung von Datensatz , der Verbindung mehrerer Datensätze und der Erkundung ihres Abhängigkeitsgraphen.
Marquez's Entwurf
Marquez bietet sprachspezifische Clients, die die Metadaten implementieren. Dies ermöglicht es einer Vielzahl von Datenverarbeitungsanwendungen, eine Metadaten aufzubauen. In der ersten Version wurden sowohl Java als auch Python unterstützt.
Die Metadaten extrahiert Informationen über die Produktion und den Verbrauch von Datensätzen. Es handelt sich um eine zustandslose Schicht, die für die Spezifikation der Persistenz und Aggregation von Metadaten verantwortlich ist. Die API ermöglicht es den Clients, Datensatz zu sammeln und/oder aus demLager zu beziehen.
Metadaten müssen so gesammelt, organisiert und gespeichert werden, dass sie über die Metadaten UI abgefragt werden können. DasLager dient als Katalog von Datensatz , die von der Metadaten gekapselt und sauber abstrahiert werden.
Laut Willy macht ein starkes Daten-Ökosystem die Fähigkeit aus, nach Informationen und Datensätzen zu suchen. Die Datensätze in Marquez werden durch die Verwendung eines suchmaschinenbasierten Schlüsselworts oder einer Phrase sowie der Dokumentation eines Datensatz indiziert und eingestuft: Je mehr Kontext ein Datensatz hat, desto wahrscheinlicher ist es, dass er in den Suchergebnissen an erster Stelle erscheint. Beispiele für die Dokumentation eines Datensatzsind seine Beschreibung, sein Eigentümer, sein Schema, sein Tag, usw.
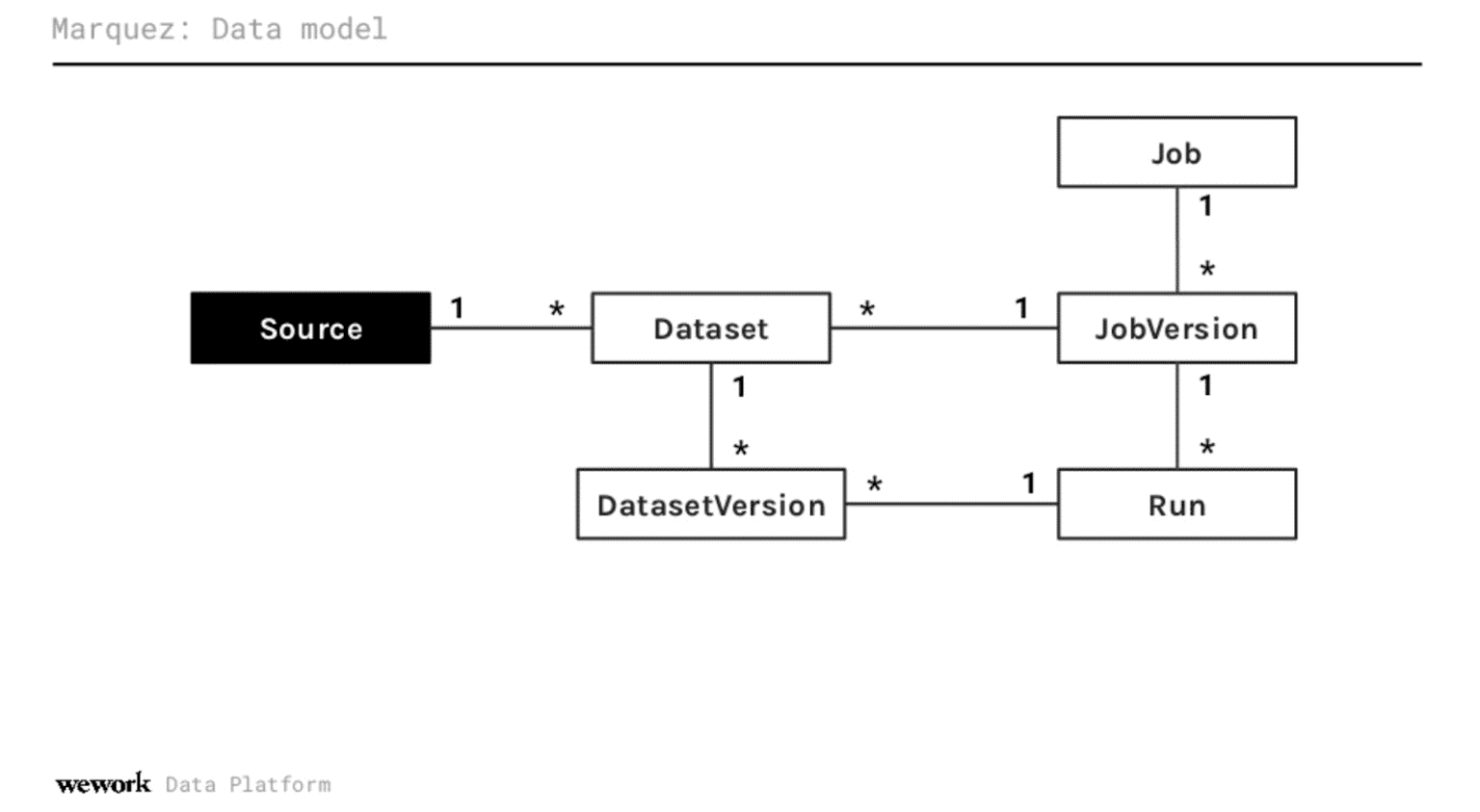
Weitere Details zu Marquez' Datenmodell finden Sie in der Präsentation selbst hier: https://www.youtube.com/watch?v=dRaRKob-lRQ&ab_channel=DataCouncil
Die Zukunft des Datenmanagement bei WeWork
Zwei Jahre nach dem Projekt hat sich Marquez als große Hilfe für die riesige Leasingfirma erwiesen. Die langfristige Roadmap des Unternehmens sieht vor, sich ausschließlich auf die Benutzeroberfläche der Lösung zu konzentrieren und mehr Visualisierungen und grafische Darstellungen einzubeziehen, um den Benutzern einfachere und unterhaltsamere Möglichkeiten zur Interaktion mit ihren Daten zu bieten.
Sie bieten auch verschiedene Online-Communities über ihre Github-Seite sowie Gruppen auf LinkedIn für diejenigen, die sich für Marquez interessieren, um Fragen zu stellen, Ratschläge zu erhalten oder sogar Probleme mit der aktuellen Marquez-Version zu melden.
Quellen
Ein Metadaten für Datenabstraktion, Data Lineage & ereignisbasierte Auslöser, WeWork. Youtube: https://www.youtube.com/watch?v=dRaRKob-lRQ&ab_channel=DataCouncil
29 verblüffende WeWork-Statistiken - Die neue Ära des Coworking, TechJury.com: https://techjury.net/blog/wework-statistics/
Marquez: Sammeln, aggregieren und visualisieren Sie die Metadaten eines Datenökosystems, https://marquezproject.github.io/marquez/
Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)