Marquez: La solución de descubrimiento de metadatos en WeWork





Creada en 2010, WeWork es una empresa global de alquiler de oficinas y espacios de trabajo. Su objetivo es proporcionar espacios de colaboración a equipos de cualquier tamaño, ya sean startups, pymes o grandes empresas. Para lograrlo, lo que WeWork ofrece puede dividirse en tres categorías diferentes:
- Espacio: Para garantizar a las empresas un espacio óptimo, WeWork debe proporcionar la infraestructura adecuada, que consiste en reservar salas para entrevistas / one on ones o incluso edificios enteros para grandes corporaciones. También deben asegurarse de que están equipados con las instalaciones adecuadas, como cocinas para el almuerzo y las pausas para el café, baños, etc.
- Comunidad: A través de la aplicación interna de WeWork, la empresa permite a los miembros de WeWork conectarse entre sí, ya sea localmente dentro de su propio espacio WeWork, o globalmente. Por ejemplo, si una empresa necesita opiniones para un proyecto de determinados puestos de trabajo (como un desarrollador o un diseñador de UX), puede pedir directamente opiniones y sugerencias a través de la aplicación a cualquier miembro, independientemente de su ubicación.
- Servicios: WeWork también ofrece a sus miembros servicios informáticos completos en caso de problemas, así como otros servicios como nóminas, servicios públicos, etc.
En 2020, WeWork representa:
- Más de 600.000 afiliaciones.
- Ubicaciones en 127 ciudades de 33 países diferentes.
- 850 oficinas en todo el mundo.
- Generó unos ingresos de 1.820 millones de dólares.
Está claro que WeWork trabaja con todo tipo de datos de su personal y sus clientes, ya sean particulares o empresas. Por lo tanto, la enorme empresa necesitaba una plataforma en la que sus expertos en datos pudieran ver, recopilar, agregar y visualizar los metadatos de su ecosistema de datos. Esto se resolvió con la creación de Marquez.
Este artículo se centrará en la implementación de Márquez por parte de WeWork, principalmente a través de documentación gratuita y accesible proporcionada en varios sitios web, para ilustrar la importancia de contar con una plataforma de metadatos en toda la empresa con el fin de convertirse realmente en data-driven.
¿Por qué gestionar y utilizar metadatos?
En su charla "A Metadata Service for Data Abstraction, Data Lineage & Event-Based Triggers" en el Data Council allá por 2018, Willy Lulciuc, Ingeniero de Software del proyecto Marquez en WeWork explicó que los metadatos son cruciales por tres razones:
- Garantizar la calidad de los datos: Cuando los datos no tienen contexto, es difícil que los ciudadanos confíen en sus activos de datos: ¿faltan campos? ¿Está actualizada la documentación? ¿Quién es el propietario de los datos y sigue siéndolo? Estas preguntas se responden mediante el uso de metadatos.
- Comprender el linaje de los datos: Conocer los orígenes y las transformaciones de tus datos es clave para poder saber realmente por qué etapas han pasado tus datos a lo largo del tiempo.
- Democratización de los conjuntos de datos: Según Willy Lulciuc, la democratización de los datos en la empresa es fundamental. Disponer de un portal central o una interfaz de usuario para que los usuarios puedan buscar y explorar sus conjuntos de datos es una de las formas más importantes que tienen las empresas de crear una verdadera cultura de autoservicio de datos.
En resumen: crear un ecosistema de datos saludable. Willy explica que ser capaz de gestionar y utilizar metadatos crea una cultura de datos sostenible en la que las personas ya no necesitan pedir ayuda para encontrar y trabajar con los datos que necesitan. En su diapositiva, repasa tres categorías diferentes que conforman un ecosistema de datos saludable:
- Ser un ecosistema de autoservicio, donde los usuarios de datos y de negocio tienen la posibilidad de descubrir los datos y metadatos que necesitan, y explorar los activos de datos de la empresa cuando no saben exactamente lo que están buscando. Proporcionar datos contextualizados permite a todos los usuarios y ciudadanos de datos trabajar eficazmente en sus casos de uso de datos.
- Ser autosuficientes permitiendo a los usuarios de datos la libertad de experimentar con sus conjuntos de datos, así como tener la flexibilidad de trabajar en todos los aspectos de sus conjuntos de datos, ya sean de entrada o de salida, por ejemplo.
- Y, por último, en lugar de depender de determinadas personas o grupos, un ecosistema de datos saludable permite que todos los empleados sean responsables de sus propios datos. Cada usuario tiene la responsabilidad de conocer sus datos, sus costes (¿están estos datos produciendo suficiente valor?), así como de hacer un seguimiento de la documentación de sus datos para generar confianza en torno a sus conjuntos de datos.
Reserva de habitaciones Antes
Como ya se ha dicho, la utilización de metadatos es crucial para que los usuarios de datos puedan encontrar los datos que necesitan. En su presentación, Willy compartió una situación real para demostrar que los metadatos son esenciales: El proceso de datos de WeWork para reservar una habitación.
Para un "WeWorker", los pasos son los siguientes:
- Busca una ubicación (el ejemplo era un complejo de edificios en San Francisco).
- Elegir el tamaño adecuado de la sala (normalmente se divide en función del número de asistentes; en este caso eligieron una sala que podía acoger de 1 a 4 personas).
- Elija la fecha en la que se realizará la reserva.
- Decide la franja horaria para la que se reserva la sala, así como la duración de la reunión.
- Confirme la reserva.
Ahora que tenemos un ejemplo de cómo funciona su canal de reservas, Willy procede a demostrar cómo funcionaría un equipo de datos típico que quisiera extraer datos sobre las reservas de WeWork. En este caso, el ejercicio de ejemplo consistía en encontrar el edificio con más reservas de habitaciones y extraer esos datos para enviarlos a la dirección. Los pasos que indicó fueron los siguientes:
- Leer las reservas de habitaciones de una fuente de datos (normalmente desconocida).
- Suma todas las reservas de habitaciones y devuelve las mejores ubicaciones.
- Una vez calculada la ubicación superior, el siguiente paso es escribirla en alguna fuente de datos de salida.
- Ejecuta el trabajo una vez cada hora.
- Procesa los datos mediante archivos .csv y almacénalos en algún sitio.
Sin embargo, Willy afirma que, aunque estos pasos parezcan suficientes, suelen surgir problemas. Repasa tres tipos de problemas durante el proceso de trabajo:
- ¿Dónde puedo encontrar el conjunto de datos de entrada de trabajo?
- ¿Tiene propietario el conjunto de datos? ¿Quién es?
- ¿Con qué frecuencia se actualiza el conjunto de datos?
La mayoría de estas preguntas son difíciles de responder y los trabajos acaban fracasando. Sin estar seguro y confiar en esta información, puede ser difícil presentar números a la dirección. Este tipo de problemas y cuestiones son los que hicieron que WeWork desarrollara Marquez.
¿Qué es Márquez?
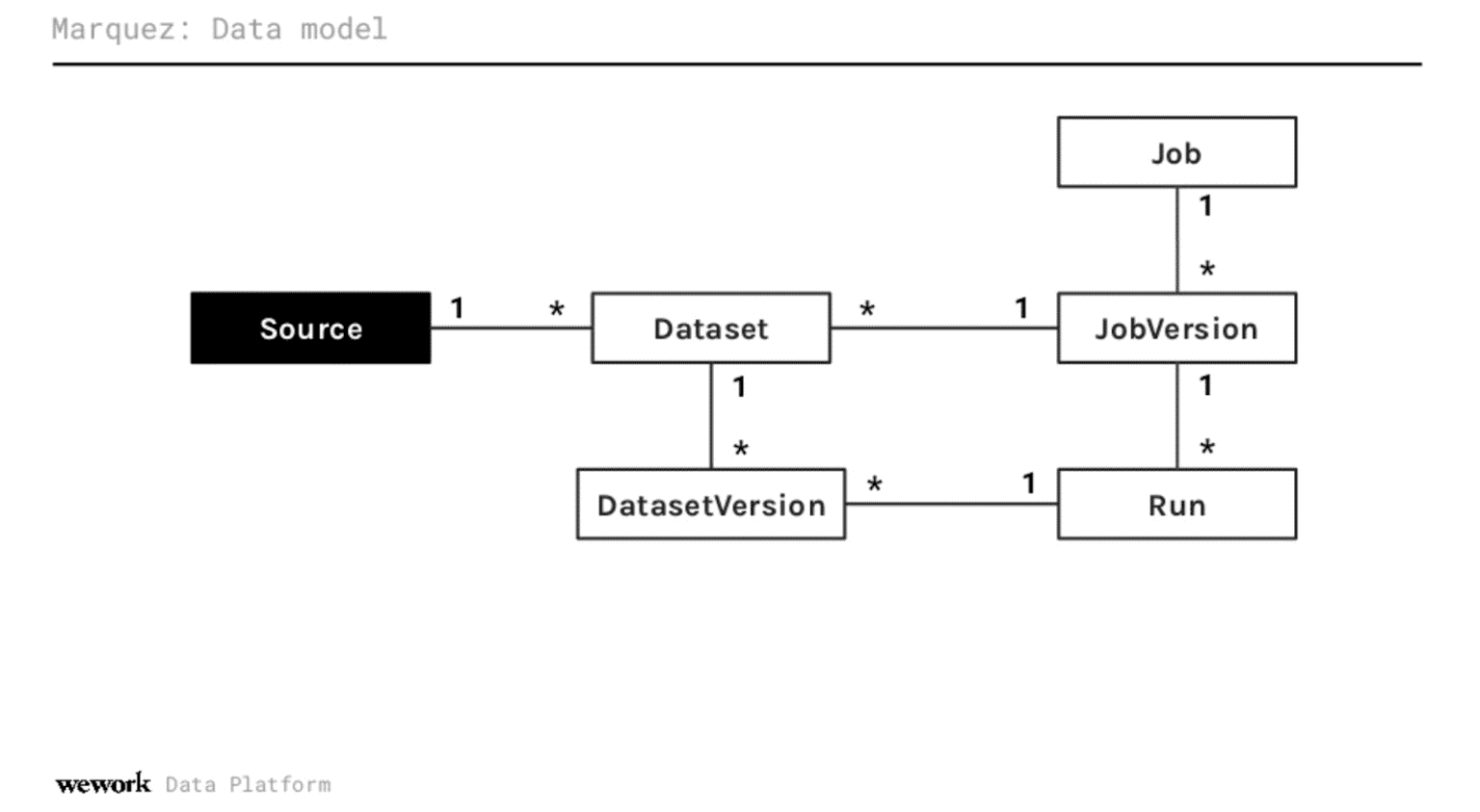
Willy define la plataforma como una "solución de código abierto para la agregación, recopilación y visualización de metadatos del ecosistema de datos [de WeWork]". De hecho, Marquez es un sistema modular y se diseñó como una solución para la gestión de metadatos altamente escalable y extensible independientemente de la plataforma. Consta de los siguientes componentes
- Repositorio de metadatos: Almacena todos los metadatos de trabajos y conjuntos de datos, incluido un historial completo de ejecuciones de trabajos y estadísticas a nivel de trabajo (es decir, ejecuciones totales, tiempos medios de ejecución, éxitos/fracasos, etc.).
- API de metadatos: API RESTful que permite a un conjunto diverso de clientes comenzar a recopilar metadatos en torno a la producción y el consumo de conjuntos de datos.
- Interfaz de metadatos: Se utiliza para descubrir conjuntos de datos, conectar múltiples conjuntos de datos y explorar su gráfico de dependencias.
Diseño de Márquez
Marquez proporciona clientes específicos para cada idioma que implementan la API de metadatos. Esto permite a un conjunto diverso de aplicaciones de procesamiento de datos crear una colección de metadatos. En su versión inicial, ofrecían soporte tanto para Java como para Python.
La API de metadatos extrae información sobre la producción y el consumo de conjuntos de datos. Es una capa sin estado responsable de especificar tanto la persistencia como la agregación de metadatos. La API permite a los clientes recopilar y/u obtener información sobre conjuntos de datos del repositorio de metadatos.
Los metadatos deben recopilarse, organizarse y almacenarse de forma que permitan realizar consultas exploratorias a través de la interfaz de usuario de metadatos. El repositorio de metadatos sirve como catálogo de la información del conjunto de datos encapsulada y limpiamente abstraída por la API de metadatos.
Según Willy, lo que hace que un ecosistema de datos sea muy sólido es la capacidad de buscar información y conjuntos de datos. En Márquez, los conjuntos de datos se indexan y clasifican mediante el uso de una palabra o frase clave basada en un motor de búsqueda, así como en la documentación de un conjunto de datos: cuanto más contextualizado esté un conjunto de datos, más probabilidades tendrá de aparecer el primero en los resultados de búsqueda. Ejemplos de la documentación de un conjunto de datos son su descripción, propietario, esquema, etiqueta, etc.
Puede ver más detalles del modelo de datos de Márquez en la propia presentación aquí: https://www.youtube.com/watch?v=dRaRKob-lRQ&ab_channel=DataCouncil
El futuro de la gestión de datos en WeWork
Dos años después del proyecto, Márquez ha demostrado ser de gran ayuda para la gigantesca empresa de leasing. Su hoja de ruta a largo plazo es centrarse únicamente en la interfaz de usuario de su solución, incluyendo más visualizaciones y representaciones gráficas para ofrecer a los usuarios formas más sencillas y divertidas de interactuar con sus datos.
También ofrecen varias comunidades en línea a través de su página de Github, así como grupos en LinkedIn para que los interesados en Marquez hagan preguntas, reciban consejos o incluso informen de problemas en la versión actual de Marquez.
Fuentes
A Metadata Service for Data Abstraction, Data Lineage & Event-Based Triggers, WeWork. Youtube: https://www.youtube.com/watch?v=dRaRKob-lRQ&ab_channel=DataCouncil
29 asombrosas estadísticas de WeWork - La nueva era del coworking, TechJury.com: https://techjury.net/blog/wework-statistics/
Márquez: Recopilar, agregar y visualizar los metadatos de un ecosistema de datos, https://marquezproject.github.io/marquez/
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)