Was ist der Unterschied zwischen einem Data Analytics Hub und einem Lakehouse?





In der ersten Folge dieser Blogserie - Data Lakes, Data Warehouses und Data Hubs: Brauchen wir eine andere Wahl? gehe ich der Frage nach, warum eine einfache Migration dieser On-Premise-Plattformen für Datenintegration, -management und -analyse in die Cloud den Anforderungen moderner Data Analytics nicht gerecht wird. Beim Vergleich dieser drei Plattformen wird deutlich, dass sie alle bestimmte kritische Anforderungen erfüllen, aber keine von ihnen die Bedürfnisse der Endbenutzer im Unternehmen ohne erhebliche Unterstützung durch die IT-Abteilung erfüllt. Im zweiten Blog in dieser Reihe - Was ist ein Data Analytics Hub? - führe ich den Begriff Data Analytics Hub ein, um eine Plattform zu beschreiben, die die optimalen operativen und analytischen Elemente von Data Hubs, Lakes und Warehouses mit Cloud und -Funktionalität kombiniert, um direkt die operativen Echtzeit- und Selbstbedienungsanforderungen von Geschäftsanwendern (und nicht ausschließlich von IT-Anwendern) zu erfüllen. Ich nehme mir auch einen Moment Zeit, um eine vierte verwandte Technologie zu untersuchen, den Analytik-Hub. In Anbetracht der titelgebenden Nähe des Analytik-Hubs zum Data Analytics Hub ist es nur sinnvoll, klarzustellen, dass ein Analytik-Hub eine ebenso unvollständige Lösung für moderne Analytik bleibt wie ein Daten-Lake, Hub und Warehouse.
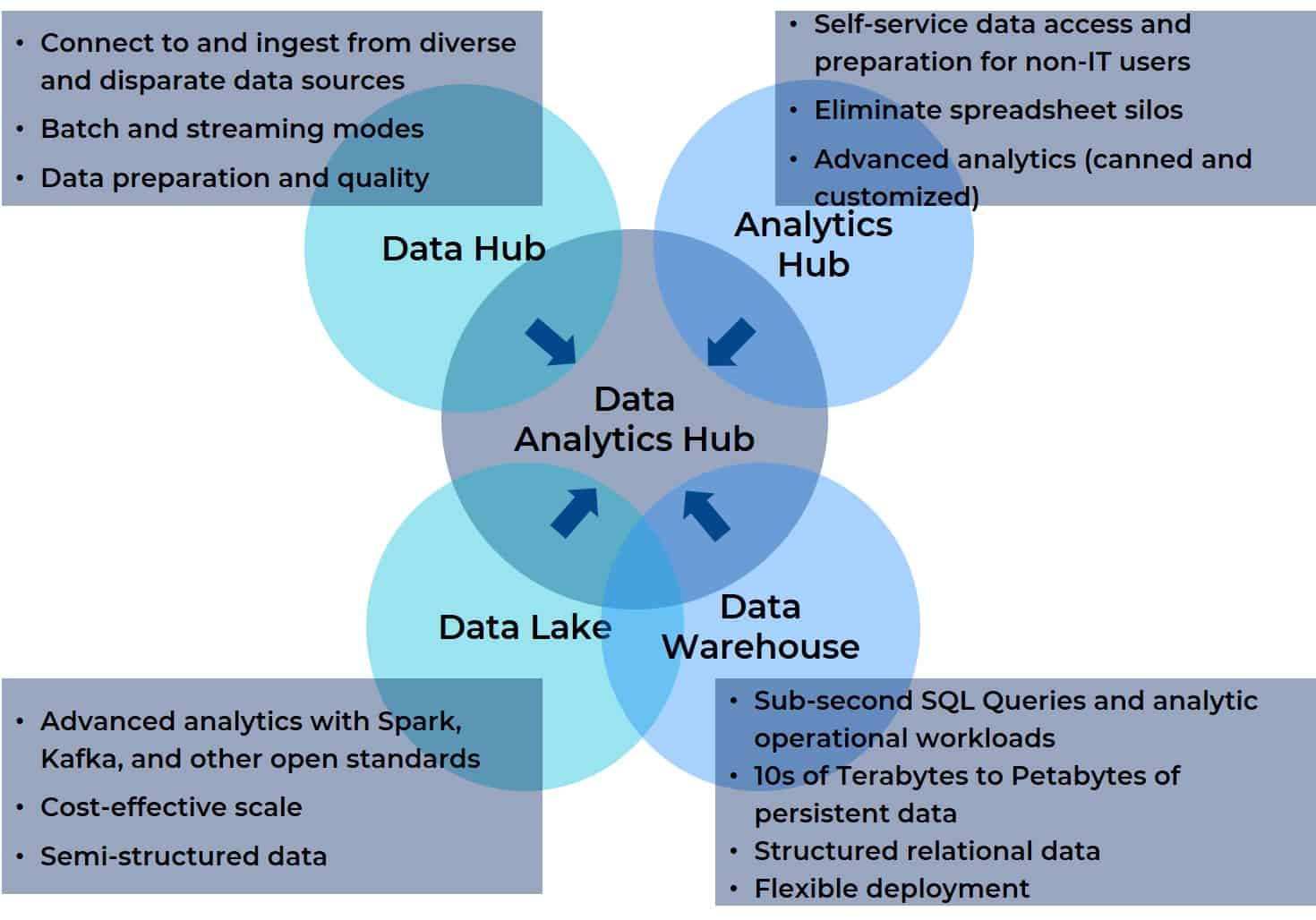
Warum? Weil ein Data Analytics Hub im Wesentlichen das Beste aus all diesen Integrations-, Verwaltungs- und Analyseplattformen in einer einzigen Plattform zusammenfasst. Ein Data Analytics Hub vereint die Datenaggregation, das Management und die Analyseunterstützung für jede Datenquelle mit jedem BI- oder KI-Tool, jeder Visualisierung, jedem Reporting oder anderen Ziel. Darüber hinaus ist ein Data Analytics Hub so aufgebaut, dass er für alle Benutzer in einem funktionsübergreifenden Team (auch in einem virtuellen) zugänglich ist. Das folgende Diagramm zeigt die Beziehung zwischen den vier Vorgängern und dem Data Analytics Hub (es wird Ihnen bekannt vorkommen, wenn Sie Teil 2 dieser Serie gelesen haben).
Moment... Was ist mit Daten-Lakehouse?
Letzte Woche hatte ich das Privileg, Bill Inmon, der als Vater des Data Warehousing gilt, für ein Webinar über moderne Datenintegration in Cloud Data Warehouses zu empfangen. Natürlich gab es viele Fragen an Bill, aber es gab eine, von der ich dachte, dass sie es verdient, dass sie hier diskutiert wird: Was ist ein Daten-Lakehouse, und wie unterscheidet es sich von einem Daten-Lake oder Data Warehouse?
Fangen wir mit dem Offensichtlichsten an, das schon der Name verrät: ein Daten-Lakehouse ist eine Kombination aus handelsüblicher Hardware, offenen Standards und halbstrukturierten und unstrukturierten Fähigkeiten aus einem Daten-Lake und den SQL-Analysen, der Unterstützung strukturierter Schemata und der Integration von BI-Tools, die in einem Data Warehouse zu finden sind. Dies ist wichtig, denn die Frage ist weniger, wiesich ein Daten-Lakehouse von einem Daten-Lake oder Data Warehouseunterscheidet , sondern vielmehr, wie es dem einen oder dem anderen ähnelt . Und diese Unterscheidung ist wichtig, weil es darauf ankommt, wo man mit der Konvergenz beginnt. In einfachen mathematischen Begriffen, wenn A + B = C, dann B + A = C. Aber in der realen Welt ist das nicht ganz richtig. Der Ausgangspunkt ist alles, wenn es um die Konvergenz von zwei Plattformen oder Produkten geht, denn dieser Ausgangspunkt bestimmt, wohin man geht, wie man die Reise wahrnimmt und ob man am Ende der Migrationdort angekommen ist, wo man es erwartet hat oder nicht.
Apropos Reisen: Machen wir einen kleinen Ausflug in die Vergangenheit, um die Herausforderungen zu verstehen, die hinter der Idee eines Daten-Lakehouse stehen.
In der Vergangenheit waren Data Lakes die Domäne von Datenwissenschaftlern und Power-Usern. Sie unterstützten große Datenmengen - strukturiert und unstrukturiert - für die Datenexploration und komplizierte data science auf offener Standardhardware. Diese Anforderungen erforderten jedoch keinen Zugriff auf aktive Daten, wie sie im täglichen Geschäftsbetrieb anfallen. Sie wurden oft zu wissenschaftlichen Labors und in einigen Fällen zu Datenabfallhalden.
Im Gegensatz dazu stehen die historischen Anforderungen von Business-Analysten und anderen Power-Usern der Geschäftsbereiche (LOB). Sie erstellten und führten operative Workloads in Verbindung mit SQL-Analysen, BI, Visualisierung und Berichterstellung aus und benötigten Zugriff auf aktive Daten. Für ihre Bedürfnisse richteten die IT-Abteilungen unternehmensweite Data Warehouses ein, die traditionell eine begrenzte Anzahl von ERP-Anwendungsdatenspeichern nutzten, die eng mit dem Tagesgeschäft verbunden waren. Die IT-Abteilung musste zwischen dem Data Warehouse und den Geschäftsanalysten und den LOB-Power-Usern vermitteln, aber das Data Warehouse selbst stellte eine geschlossene Feedback-Schleife zur Verfügung, die Erkenntnisse für eine bessere Entscheidungsunterstützung und Geschäftsflexibilität lieferte.
Mit dem Fortschreiten der digitalen Transformation haben sich jedoch auch die Anforderungen geändert. Die Anwendungen sind intelligenter geworden und durchdringen jeden Aspekt des Unternehmens. Die Erwartungen an Data Lakes und Data Warehouses haben sich weiterentwickelt. Die Nachfrage nach Echtzeit-Entscheidungsunterstützung hat die Rückkopplungsschleife zwischen Data Warehouse und Lager asymptotisch reduziert, bis zu dem Punkt, an dem sie sich der Echtzeit nähert. Und die ursprünglichen ERP-Repositories sind nicht mehr die einzigen Repositories, die für Business-Analysten und LOB-Power-User von Interesse sind - Web-Clickstreams, IoT, Protokolldateien und andere Quellen sind ebenfalls wichtige Teile des Puzzles. Diese anderen Quellen sind jedoch in den unterschiedlichen und vielfältigen Datensätzen zu finden, die in Data Lakes schwimmen und sich über mehrere Anwendungen und Abteilungen erstrecken. Im Grunde genommen kann jeder Aspekt menschlicher Interaktion modelliert werden, um Erkenntnisse zu gewinnen, die die betriebliche Genauigkeit erheblich verbessern können - daher hat sich die Konsolidierung von Daten aus einem vielfältigen und uneinheitlichen Datenuniversum und deren Zusammenfassung in einer einheitlichen Ansicht als zentrale Anforderung herauskristallisiert. Dieser Bedarf treibt die Konvergenz in den Bereichen Daten-Lake und Data Warehouse voran und führt zu der Idee eines Daten-Lakehouse.
Zurück in die Gegenwart: Zwei der Hauptbefürworter von Data Lakehouses sind Databricks und Snowflake. Ersterer nähert sich der Aufgabe der Plattformkonsolidierung aus der Perspektive eines Daten-Lake und letzterer aus der Perspektive eines Data-Warehouse-Anbieters. Was ihre Daten-Lakehouse gemeinsam haben, ist dies:
- Direkter Zugriff auf Quelldaten für BI- und Analysetools (von der Data Warehouse-Seite ).
- Unterstützung für strukturierte, halbstrukturierte und unstrukturierte Daten (von der Daten-Lake ).
- Schemaunterstützung mit ACID-Konformität bei gleichzeitigen Lese- und Schreibvorgängen (auf der Data-Warehouse-Seite).
- Offene Standardwerkzeuge zur Unterstützung von Datenwissenschaftlern (von der Daten-Lake ).
- Trennung von Datenverarbeitung und Speicherung (von der Data Warehouse-Seite).
Zu den wichtigsten gemeinsamen Vorteilen gehören:
- Keine separaten Repositories mehr für data science und operative BI-Arbeitslasten erforderlich.
- Verringerung des IT-Verwaltungsaufwands.
- Konsolidierung der Silos, die durch einzelne BI- und KI-Tools entstanden sind, die ihre eigenen Datenrepositories erstellen.
Betonung ist alles
Die Verbesserung der Geschwindigkeit und Genauigkeit bei der Analyse großer, komplexer Datensätze ist keine Aufgabe die der menschliche Verstand besonders gut geeignet ist; wir sind schlichtweg nicht in der Lage, subtile Muster in wirklich großen, komplexen Datensätzen zu erfassen und zu erkennen (oder, anders ausgedrückt: Tut mir leid, du bist nicht Neo und kannst die Matrix in einem digitalen Datenstrom nicht „sehen“). KI ist jedoch sehr gut darin, Muster in komplexen multivariaten Datensätzen zu finden – solange Datenwissenschaftler feinabstimmen dafür erforderlichen Algorithmen entwerfen, trainieren und feinabstimmen können (Aufgaben, für die ihr Verstand sehr gut geeignet ist ). Sobald die Algorithmen abgestimmt und als Teil der operativen Arbeitslasten eingesetzt wurden, können sie Entscheidungsfindung unterstützen Entscheidungsfindung durch Menschen (Entscheidungsunterstützung auf Basis von Situationsbewusstsein) oder programmgesteuert (automatisierte Entscheidungsunterstützung, die von Maschinen als unbeaufsichtigte Machine-to-Machine-Operationen ausgeführt wird). Im Laufe der Zeit müssen einige oder alle dieser Algorithmen möglicherweise auf der Grundlage von Ergebnismustern oder Abweichungen von den erwarteten oder gewünschten Ergebnissen angepasst werden. Auch hier gilt: Nicht, dass ich Werbung machen möchte, aber dies sind Aufgaben, für die der menschliche Verstand gut geeignet ist.
Kehren wir jedoch zum Bestreben nach Konvergenz zurück und betrachten wir, wo die Daten-Lakehouse ansetzen. Wie sieht die Lage aus ihrer Perspektive aus? Und wie beeinflusst dies die Vorstellung der Anbieter davon, wie das konvergierte Ziel aussehen soll? Data Lakes wurden in der Vergangenheit von Datenwissenschaftlern – unterstützt von Dateningenieuren und anderem qualifizierten IT-Personal – genutzt, um die Daten zu sammeln und zu analysieren, die für die Bewältigung des vorderen Teils des KI-Lebenszyklus erforderlich sind, insbesondere für Maschinelles Lernen ML). Eine Erweiterung dieser Umgebung bedeutet, die Deployment ML in den operativen Workloads zu erleichtern. Aus dieser Perspektive wäre der Erfolg eine konvergierte Plattform, die den ML-Lebenszyklus verkürzt und effizienter macht. Für Business-Analysten, Dateningenieure und Power-User feinabstimmen das Experimentieren mit Algorithmen oder das Erstellen von Basisdatensätzen zum trainieren feinabstimmen jedoch nicht zu ihren täglichen Aufgaben. Für sie ist es entscheidend, ML zusätzlich als Teil ihrer operativen Workloads auszuführen, einschließlich der zusätzlichen vielfältigen und unterschiedlichen Datensätze.
Datenwissenschaftler und Dateningenieure gehören zwar nicht zu den eigentlichen IT-Abteilungen, sind aber auch nicht dasselbe wie Nicht-IT-Endbenutzer. Data Lakes sind in der Regel komplexe Arbeitsumgebungen mit mehreren APIs und beträchtlichen Mengen an Kodierung, was für Datenwissenschaftler und Ingenieure in Ordnung ist, aber überhaupt nicht für Nicht-IT-Rollen wie Geschäfts- und Betriebsanalysten oder deren Äquivalente in verschiedenen LOB-Abteilungen. Sie brauchen wirklich eine Konvergenz, die ein Data Warehouse erweitert, um die operationalisierten ML-Komponenten in ihren Arbeitslasten auf einer einheitlichen Plattform zu handhaben - ohne die Komplexität der Umgebung zu erhöhen oder die Anforderungen für viele Nächte und Wochenenden zu erhöhen, um neue Abschlüsse zu erwerben.
Hören wir allen zu, die wir brauchen?
Ich war im Produktmanagement und im Produktmarketing tätig, und am Ende des Tages ist die Stimme Ihrer Kunden diejenige, die am weitesten und lautesten zu hören ist. Sie sind diejenigen, die die neuen Merkmale und Funktionen Ihrer Produkte am besten definieren können. Bei Daten-Lake sind es die Datenwissenschaftler, Ingenieure und die IT-Abteilung, bei Data-Warehouse-Anbietern die IT-Abteilung. Logischerweise sind die Grenzen des Problembereichs auf diese Gruppen beschränkt.
Aber wissen Sie was? Diese Logik geht an der wichtigsten Gruppe da draußen vorbei
Diese Gruppe besteht aus dem Unternehmen und seinen Vertretern, den Geschäfts- und Betriebsanalysten und anderen Power-Usern außerhalb von IT und Technik. Die Daten-Lake und Data-Warehouse-Anbieter - und damit auch die Daten-Lakehouse - sprechen nicht mit diesen Anwendern, weil die IT immer in der Mitte steht, immer vermittelt. Diese Anwender sprechen mit den Anbietern von BI- und Analysetools und, in geringerem Maße, mit den Anbietern von Data Hubs und Analytics Hubs.
Das eigentliche Problem für all diese Gruppen besteht darin, die Daten in das Lager einzuspeisen, sie anzureichern, grundlegende Analysen innerhalb der Plattform durchzuführen und die vorhandenen Tools für weitere BI-Analysen, KI, Visualisierung und Berichterstattung zu nutzen, ohne die Umgebung zu verlassen. Das Problem ist für die Unternehmensseite noch akuter, da sie Self-Service benötigen, die ihnen derzeit außerhalb der BI- und Analysetools nicht zur Verfügung stehen (die oft Daten innerhalb des Tools/Projekts isolieren, anstatt den Aufbau einer einheitlichen Ansicht zu erleichtern, die von allen Parteien gesehen werden kann).
Alle sind sich einig, dass es eine einheitliche Sicht auf die Daten geben muss, auf die alle Parteien zugreifen können, aber die Vereinbarung wird nicht alle Parteien gleichermaßen zufriedenstellen. Ein Daten-Lakehouse , das auf einem Daten-Lake basiert, ist eine großartige Möglichkeit, den ML-Lebenszyklus zu verbessern und die Datenwissenschaftler näher an den Rest des funktionsübergreifenden Teams heranzuführen. Dies ließe sich jedoch auch einfach durch die Verlagerung der HDFS-Infrastruktur in die Cloud und die Verwendung von S3, ADLS oder Google Cloud Store sowie eines modernen Cloud Data Warehouse erreichen. Eine solche Lösung würde die große Mehrheit der Anwendungsfälle abdecken, in denen ML-Komponenten für Workloads eingesetzt werden. Was sowohl bei den Daten-Lake als auch bei den Data-Warehouse-basierten Lakehouses wirklich fehlt, ist die Funktionalität des Data Hub und des Analytics Hub, der in den Data Analytics Hub integriert ist .
Schlussfolgerung: Ein Lakehouse bietet nur einen Teil der Funktionalität eines Data Analytics Hub
Das Diagramm, mit dem wir begonnen haben, veranschaulicht, wie ein Data Analytics die wesentlichen Elemente eines Daten-Lake, eines Data Warehouse, eines Analytics-Hubs und eines Data-Hubs zusammenführt. Es verdeutlicht zudem die Kurzsichtigkeit des Daten-Lakehouse . Es reicht nicht aus, nur zwei der vier Komponenten zusammenzuführen, die Anwender für moderne Analysen benötigen – insbesondere, wenn die Entwicklung dieser Chimäre auf dem Feedback einer Untergruppe der funktionsübergreifenden Rollen basiert, die die Plattform nutzen.
Im nächsten Blogbeitrag werden wir uns eingehender mit den Anwendungsfällen dieser breiteren Nutzergruppe befassen, und es wird deutlich werden, warum und wie ein Data Analytics den Anforderungen aller Beteiligten besser gerecht wird – unabhängig davon, ob ihr Schwerpunkt auf ML-basierten Optimierungen oder auf alltäglichen operativen Arbeitsabläufen liegt.


Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)