Actian Vector ingestion de données





La utilidad de una base de datos analítica está estrechamente ligada a su capacidad para ingerir, almacenar y procesar grandes cantidades de datos. Normalmente, los datos se ingieren desde múltiples fuentes, como bases de datos operativas, archivos CSV y flujos de datos continuos. En la mayoría de los casos, las cargas de datos diarias se miden en decenas o cientos de millones de filas, por lo que el mecanismo tradicional INSERT de SQL no es adecuado para estos volúmenes de datos.
En esta entrada de blog examinaremos Actian Vector, nuestra base de datos columnar ideal para aplicaciones analíticas, y evaluaremos una variedad de opciones de ingestion de données CSV que operan a las tasas de datos requeridas. En futuras entradas, examinaremos Actian VectorH ejecutándose en un entorno Hadoop y la ingestión desde fuentes de datos en streaming.
El objetivo de este ejercicio no es comparar el rendimiento de ingestion de données , sino evaluar la velocidad relativa de varios métodos en el mismo entorno de hardware. Evaluaremos SQL INSERT como línea de base, SQL COPY TABLE, la línea de comandos vwload y las herramientas ETL/workflow Pentaho Data Integration (también conocida como Kettle), Talend Open Studio for Data Integration y Apache NiFi. Talend y Pentaho son herramientas ETL tradicionales que han evolucionado para incluir una variedad de cargadores masivos y otras herramientas y tecnologías denominadas big data; ambas se basan en la interfaz de usuario de Eclipse. NiFi fue cedida a la Fundación Apache por la Agencia de Seguridad Nacional de EE.UU. (NSA) y es una herramienta de uso general para automatizar el flujo de datos entre sistemas de software; utiliza una interfaz de usuario basada en web.
Los tres implementan algún concepto de grafo dirigido con datos que fluyen de un operador al siguiente con operadores que se ejecutan en paralelo. Pentaho y Talend tienen ediciones comunitarias y de suscripción, mientras que NiFi es de código abierto de Apache.
El servidor Vector es un procesador de núcleo hexagonal AMD Opteron 6234 de clase sobremesa, 64 GB de memoria y discos giratorios SATA (coste del hardware ~ 2.500 dólares) que ejecuta la versión 5.0 de Vector en un único nodo.
Como base de comparación, insertaremos aproximadamente 24 millones de registros en la tabla lineitem de referencia TPCH. La estructura de esta tabla es:
l_orderkey bigint NOT NULL, l_partkey INT NOT NULL, l_suppkey INT NOT NULL, l_linenumber INT NOT NULL, l_quantity NUMERIC(19,2) NOT NULL, l_extendedprice NUMERIC(19,2) NOT NULL, l_descuento NUMERIC(19,2) NOT NULL, l_tax NUMERIC(19,2) NOT NULL, l_returnflag CHAR(1) NOT NULL, l_linestatus CHAR(1) NOT NULL, l_shipdate FECHA NOT NULL, l_commitdate FECHA NOT NULL, l_receiptdate FECHA NOT NULL, l_shipinstruct CHAR(25) NOT NULL, l_shipmode CHAR(10) NOT NULL, l_comentario VARCHAR(44) NOT NULL
INSERTAR SQL
Como Vector es compatible con ANSI SQL, quizás el mecanismo de ingesta más obvio sea la construcción estándar SQL INSERT. Esta es generalmente la opción de menor rendimiento, ya que da lugar a operaciones de inserción de un único registro. Las inserciones pueden optimizarse hasta cierto punto haciendo uso de la parametrización e insertando registros en lotes, pero incluso esto puede no proporcionar el nivel de rendimiento requerido.
Para la prueba SQL INSERT, construiremos un simple flujo de trabajo Pentaho con dos pasos, uno para leer el archivo de datos CSV y el otro para insertar esas filas en una base de datos Vector. También ejecutaremos el flujo de trabajo en el mismo nodo que la instancia de Vector, así como en un nodo remoto para medir el efecto de la sobrecarga de la red.

En esta situación, la carga desde un nodo remoto funciona marginalmente mejor que la carga desde el nodo local y el rendimiento mejora generalmente con un tamaño de lote creciente hasta aproximadamente 100K registros y luego se aplana. Esto no quiere decir que 100K sea siempre el tamaño óptimo de lote; lo más probable es que varíe en función del tamaño de las filas.
Vector COPY TABLE
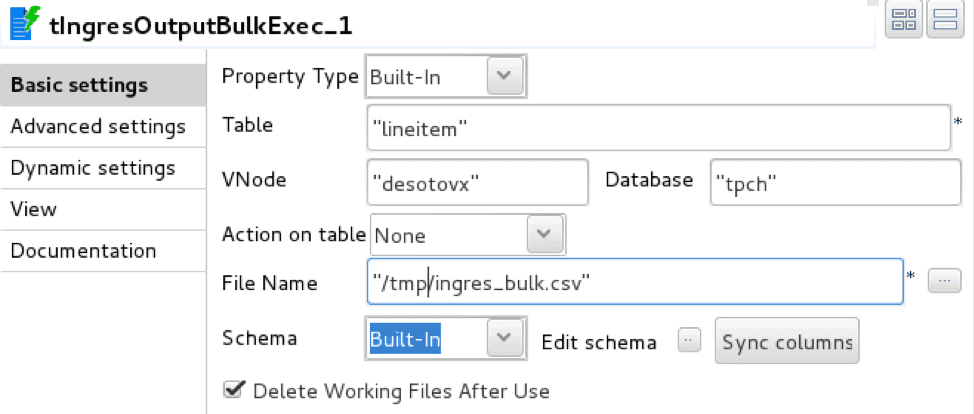
La construcción COPY TABLE de Vector se utiliza para cargar datos de forma masiva desde un archivo CSV a la base de datos. Si se ejecuta desde un nodo remoto, este enfoque requiere una instalación de Vector Client Runtime, es decir, Ingres Net y el monitor de terminal Ingres SQL. El Client Runtime está disponible gratuitamente y no tiene requisitos de licencia. Tanto Pentaho como Talend han incorporado soporte para esta construcción, aunque la implementación es ligeramente diferente. Pentaho utiliza tuberías con nombre para hacer fluir los datos hacia el operador, mientras que Talend crea un archivo de disco intermedio y luego llama al operador.
La implementación de Talend hace uso de dos operadores, tFileInputDelimited, lector de ficheros delimitados, y tIngresOutputBulkExec, cargador Ingres/Vector COPY TABLE

El cargador se configura con los detalles de conexión a la base de datos, la tabla de destino y el archivo de almacenamiento intermedio.
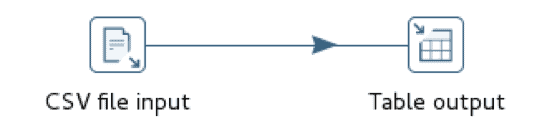
La implementación de Pentaho utiliza dos operadores equivalentes, CSV file input, lector de archivos delimitados, e Ingres VectorWise Bulk Loader, cargador de tablas de base de datos.

El cargador se configura con una conexión Vector y una tabla de destino. A diferencia de Talend, el cargador Pentaho no utiliza un archivo de puesta en escena intermedio.

El rendimiento de ambas herramientas es esencialmente el mismo, pero del orden de 6 veces más rápido que SQL INSERT. Apache NiFi no proporciona soporte nativo de Vector COPY TABLE y simular este enfoque lanzando el monitor de terminal por separado y conectando con named pipes es relativamente engorroso.
Vector vwload
La utilidad vwload suministrada por Vector es un cargador masivo de haute performance para Actian Vector y VectorH. Es una utilidad de línea de comandos diseñada para cargar uno o más archivos en una tabla Vector o VectorH desde el sistema de archivos local o desde HDFS. Exploraremos la variante HDFS en un futuro post.
Vwload puede invocarse de forma autónoma o como mecanismo de carga de datos para los flujos de flujo de trabajo generados por Pentaho, Talend o NiFi. Pentaho tiene soporte vwload incorporado, mientras que Talend y NiFi proporcionan un mecanismo para dirigir los flujos de datos de flujo de trabajo a vwload sin persistir primero en el disco.
La implementación de Talend utiliza tFileInputDelimited para leer el archivo CSV de origen y tFileOutputDelimited para escribir las filas del archivo de origen en una tubería con nombre. Para cargar el flujo de datos en Vector necesitamos ejecutar vwload con la misma tubería con nombre que el archivo fuente.
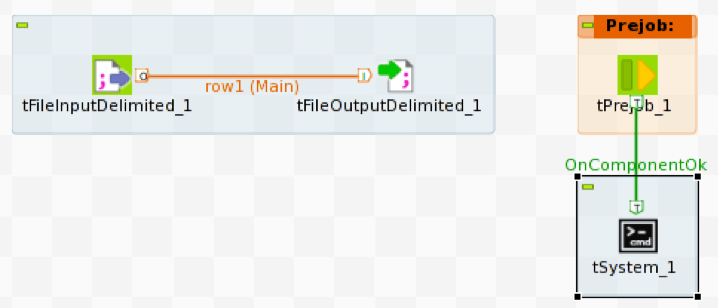
Para iniciar vwload usamos la construcción Prejob para disparar el operador tSystem, tSystem es el mecanismo para ejecutar comandos a nivel de sistema operativo o scripts de shell. El operador Prejob se activa automáticamente al inicio del trabajo antes que cualquier otro operador de flujo de trabajo y está configurado para activar el operador tSystem.
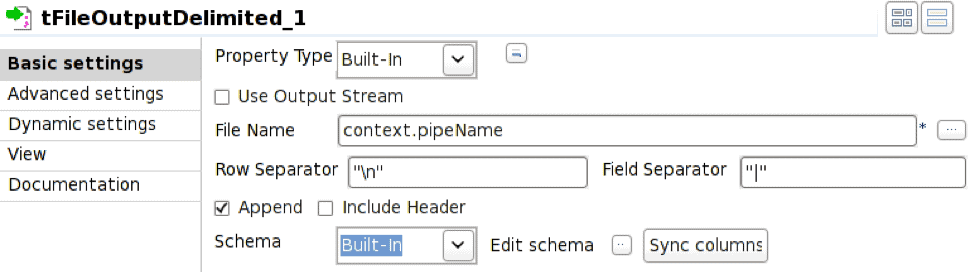
El operador tFileOutputDelimited está configurado para escribir en la tubería definida por la variable de entorno context.pipeName. La tubería nombrada debe existir en el momento de la ejecución del trabajo y es necesario comprobar Append.
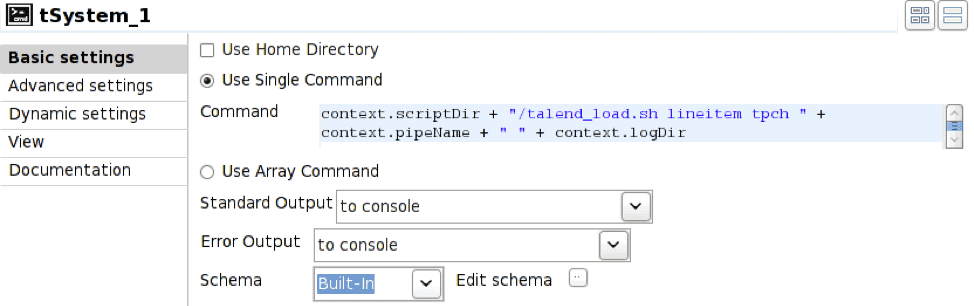
En este caso, el operador tSystem ejecuta el script de shell talend_load.sh pasando parámetros para el nombre de la tabla, el nombre de la base de datos, el nombre de la tubería y el directorio del archivo de registro resultante. La notación context. es el mecanismo para hacer referencia a variables de entorno asociadas con el trabajo; esto permite parametrizar los trabajos. El script de shell es:
/bin/bash nohup vwload -m -t $1 $2 $3 > $4/log_`date +%Y%m%d_%H%M%S`.log 2>&1 &
La secuencia de ejecución resultante es:
- Ejecutar operador Prejob
- Operador tSystem
- tEl operador del sistema ejecuta un script de shell
- Shell script lanza vwload en segundo plano y regresa; vwload está ahora leyendo de la tubería nombrada esperando a que lleguen las filas
- Inicia tFileInputDelimited para leer filas del fichero fuente
- Inicia tFileOutputDelimited para recibir las filas entrantes y escribirlas en la tubería con nombre
La implementación de Pentaho utiliza el archivo CSV de entrada y los operadores de Ingres VectorWise Loader como en el caso de COPY TABLE, pero el cargador masivo está configurado para utilizar vwload en su lugar.
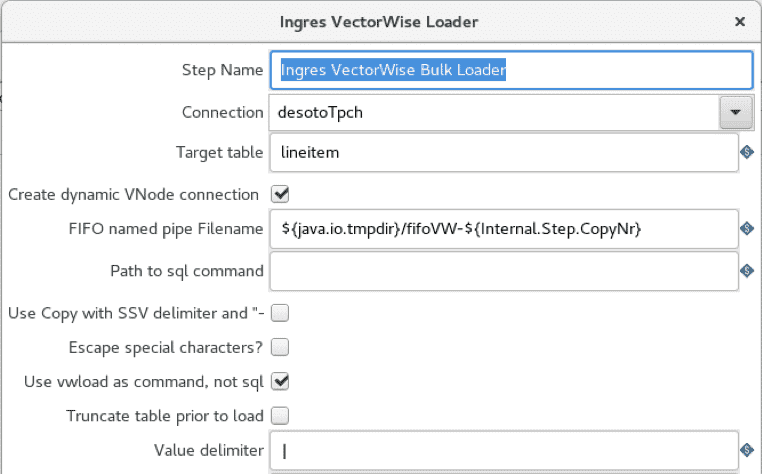
La opción "use vwload" está seleccionada, y el campo "Path to sql command" está en blanco. Esta es la forma de invocar la utilidad vwload.
La implementación de Apache NiFi hace uso de tres operadores: GetFile, que es un oyente de directorio, FetchFile, que lee el archivo real, y ExecuteStreamCommand, que pasa los datos de streaming del archivo al proceso vwload en segundo plano.
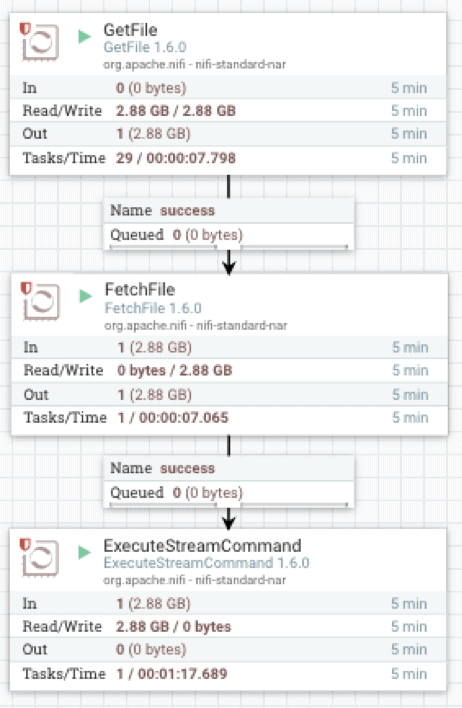
FetchFile alimenta el flujo de datos de origen a ExecuteStreamCommand, que está configurado para ejecutar un script de shell.
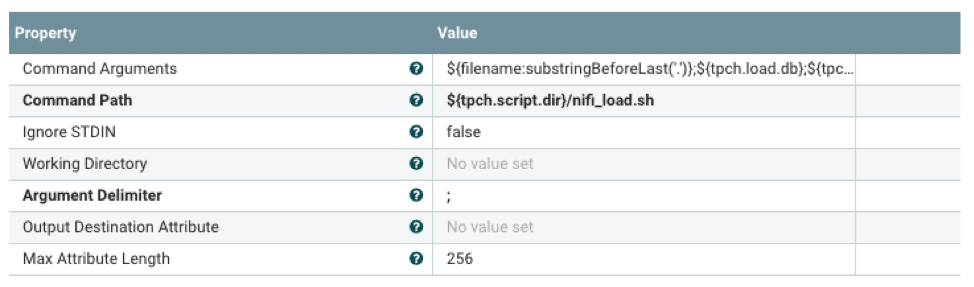
El script de shell lanzará vwload en segundo plano y dirigirá el flujo de datos a vwload a través de una tubería con nombre. La notación ${} es el mecanismo para hacer referencia a propiedades configuradas con un archivo de propiedades externo. Esto permite la configuración del procesador de flujo en tiempo de ejecución.
#!/bin/bash tableName=$1 dbName=$2 loadPipe=$3 logDir=$4 echo "`date +%Y-%m-%d\ %H:%M:%S` vwload -m -t $tableName db $dbName $loadPipe " >> $directorio_de_log/load.log vwload -uactian -m -t $tableName $dbName $loadPipe >> $logDir/load.log 2>&1 & cat /dev/stdin >>$loadPipe
La línea de comandos vwload se utiliza como mecanismo de carga en los flujos de trabajo precedentes de Pentaho, Talend y NiFi. Como punto de comparación, también cargamos el mismo jeu de données utilizando vwload independiente en la máquina Vector local, así como desde el cliente remoto utilizando Ingres Net.

Los tiempos transcurridos específicos y las tasas de ingestión variarán ampliamente en función del hardware y del tamaño de las filas.
En resumen, las opciones de ingestion de données , por orden de aumento del rendimiento, son SQL INSERT, SQL COPY TABLE y vwload. Para volúmenes de datos importantes, vwload utilizado con la herramienta ETL adecuada suele ser la elección correcta. La elección de la herramienta ETL suele depender del rendimiento y la funcionalidad. Como mínimo, debe existir un mecanismo de interfaz con el método de ingestión elegido. Los requisitos de funcionalidad vienen determinados principalmente por la cantidad y el tipo de transformación que debe realizarse en el flujo de datos entrantes. Aunque los datos entrantes deban cargarse tal cual, una herramienta ETL puede ser útil para la detección de archivos entrantes, la programación de trabajos y la notificación de errores.
Los flujos de trabajo anteriores son el caso trivial para la ingestión de archivos CSV, normalmente sólo la lectura de un archivo de datos de origen y la carga en Vector. Como tales, también representan el mejor caso de rendimiento para cada uno de los métodos de ingestión. La mayoría de los casos de uso de la vida real implicarán cierto grado de lógica de transformación en el flujo de trabajo, con tasas de flujo de datos que disminuyen en función de la complejidad de la transformación. La medición de las tasas de datos del flujo de trabajo nos permite seleccionar el método de ingestión que cumpla esos requisitos.
Más información sobre Actian Vector
Puede obtener más información sobre Actian Vector visitando los siguientes recursos:
Obtenga más información sobre nuestras ediciones de la comunidad Actian Vector en:
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)