Guerra de datos: el auge de HCL Informix
Lawrence Fernandes
11 de febrero de 2025

"Nunca nadie se ha ido de verdad". - Luke Skywalker
En una galaxia no tan lejana, donde la escalabilidad y el rendimiento son primordiales, un nombre resurge silenciosamente: HCL Informix®. A menudo aclamado como un incondicional de las bases de datos relacionales tradicionales, HCL Informix ha ido evolucionando constantemente para satisfacer las demandas de los retos de datos modernos. Con el lanzamiento de HCL Informix v15, analizado brevemente en el último episodio de Data Wars [1], comienza un nuevo capítulo, que la posiciona como una potente base de datos muy grande (VLDB), que combina su rico legado RDBMS con otras características innovadoras preexistentes que hacen guiños al paradigma NewSQL. Pero, ¿puede HCL Informix reclamar realmente un puesto en la mesa NewSQL? Averigüémoslo.
Una esperanza NewSQL
Antes de sumergirnos en HCL Informix, hablemos de NewSQL. ¿Por qué es importante? ¿O debería decir "sigue importando"?
Lo primero es lo primero: el término NewSQL fue utilizado por primera vez por el analista de 451Group Matthew Aslett en un artículo de investigación de 2011 [2] en el que hablaba del auge de una nueva generación de sistemas de gestión de bases de datos diseñados para combinar la escalabilidad de NoSQL con las garantías ACID de los RDBMS tradicionales. Ya en 2020, escribí un artículo [3] sobre la aparición de las bases de datos NewSQL como solución a las limitaciones tanto de los RDBMS tradicionales como de los sistemas NoSQL, y concluí prediciendo un crecimiento significativo de este segmento de la industria.
En cuanto a mi predicción, si tomamos como referencia el rendimiento financiero de dos de los mayores proveedores de NewSQL, a saber, CockroachDB y SingleStore, diría que acerté parcialmente. Según Sacra, los ingresos de Cockroach Labs han crecido a una CAGR del 140% de 2020 a 2021 [4], mientras que el ARR de SingleStore creció un 29% de 2022 a 2023, con una valoración de $ 1,30 mil millones a partir de 2023 [5]. Mientras tanto, según Verified Market Reports, el mercado de bases de datos NewSQL se valoró en 22.810 millones de dólares en 2023, y se espera que alcance los 111.140 millones de dólares en 2030 con una CAGR del 21,78% [6]. Son buenas cifras, pero no excepcionales, y están lejos del dominio absoluto que muchos esperaban en 2020.
Ahora bien, ¿qué hay de mi primera afirmación? Bueno, aunque existe un consenso general en que los sistemas NewSQL son impresionantes, ya que pretenden proporcionar escalado horizontal y alta disponibilidad (los mayores objetivos del movimiento NoSQL) al tiempo que mantienen el soporte para transactions acid y SQL (algunos de los mejores beneficios de los RDBMS), la realidad demuestra que no es oro todo lo que reluce [7]. Los proveedores de NewSQL se enfrentaron a muchos retos, como la educación del mercado, la integración con los ecosistemas de datos existentes, la compatibilidad con las aplicaciones heredadas, los problemas para demostrar la rentabilidad en despliegues a gran escala, los fallos para garantizar la cohérence [8] y la falta de estandarización [9][10].

Comparación RDBMS (SQL) vs NoSQL vs NewSQL por el Dr. Rabi Prasad Padhy [9]
Aunque el movimiento NewSQL ya está maduro (con más de 10 años de existencia [11]), y la adopción en el mercado ha ganado tracción, incluso los principales actores han mostrado un crecimiento moderado con una cuota de mercado limitada. De hecho, la mayoría de los proveedores originales de NewSQL quebraron, fueron vendidos (y no consiguieron grandes salidas) o pivotaron [12][13]. Además, la creciente competencia de los proveedores de RDBMS y el hecho de que a los proveedores de NoSQL les haya ido mejor en comparación, hace que el futuro de NewSQL sea incierto, y muchos expertos ya declaran la muerte de NewSQL en 2021 [7][11][12][13].
La competencia contraataca
Volviendo a 2025, la vida no es nada fácil para los proveedores de NewSQL que quedan en el mercado. Vender bases de datos es un reto innegable, una realidad de la que puedo dar fe por experiencia propia. El problema radica en la "rigidez" de las bases de datos; es comprensible que las empresas se muestren reacias a migrar de sus sistemas RDBMS o NoSQL. Además, muchos de estos sistemas han evolucionado hasta convertirse en bases de datos multimodelo, una categoría que Gartner situó en la meseta de la productividad en su Hype Cycle 2023 para la gestion des données.
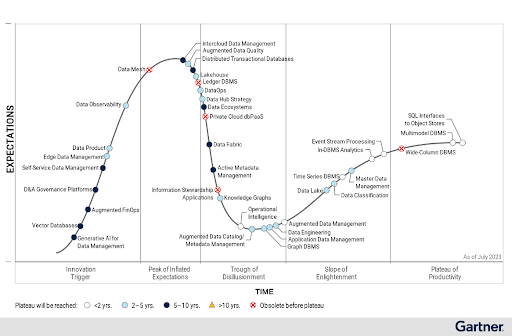
Ciclo Hype de Gartner para la gestion des données, 2023
Esto nos lleva a HCL Informix: un RDBMS consolidado con una rica historia y pedigrí que ha evolucionado hasta convertirse en una base de datos multimodelo. Fundada en 1980 y lanzada a bolsa en 1986, HCL Informix (entonces llamada simplemente "Informix") saltó a la fama en la década de 1990, convirtiéndose en la segunda base de datos más popular después de Oracle. Según Art Kagel, durante las feroces guerras de bases de datos de los 90, Informix y Oracle compitieron intensamente por el título de "Mejor" rendimiento OLTP, sin que Informix perdiera nunca una comparativa de rendimiento frente a Oracle, Sybase, SQL Server u otros competidores [14]. Hablando de benchmarks de rendimiento, un antiguo benchmark TPC-D reveló que Informix era un 70% más rápido que Oracle a la vez que funcionaba con un 25% menos de hardware [15].
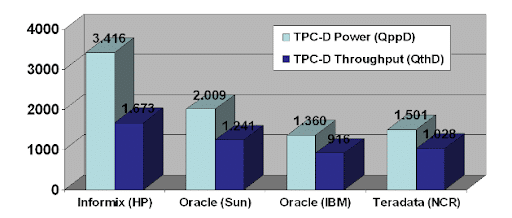
TPC-D Benchmark de los años 90
De 1996 a 2000, la leyenda del mundo de las bases de datos Michael Stonebraker se convirtió en el director técnico de Informix, tras la adquisición de Illustra [16]. A pesar de sus avances tecnológicos, el éxito de Informix se vio empañado por algunos contratiempos técnicos[17][18] y escándalos financieros[19], que provocaron la caída de la empresa. Los esfuerzos por recuperarse mediante reestructuraciones y adquisiciones acabaron fracasando, culminando con la adquisición de Informix por IBM en 2005.
Según Art Kagel, "IBM ha realizado más mejoras, ampliaciones y añadido más funciones nuevas al producto que Informix Corp. durante sus 18 años de existencia" [20]. Algunas de estas mejoras incluyen Informix Warehouse Accelerator (IWA), soporte para la API de MongoDB y protocolos de conectividad, entre otros.
entre otros. Sin embargo, debido a muchas razones (algunas de ellas exploradas en el mismo hilo de Quora [20]), la competencia contraataca, lo que se traduce en una pérdida de cuota de mercado y de notoriedad.
Auge de HCL Informix
Ya en 2017, IBM firmó un acuerdo de colaboración a largo plazo con HCLTech, una de las mayores consultoras del mundo (entre otros negocios relacionados), para desarrollar conjuntamente la familia de productos Informix[21][22], lo que nos lleva a HCL Informix: la misma base de datos Informix que los clientes aprendieron a amar, pero con licencia de Actian, una división de HCLSoftware[23].
HCL Informix tiene paridad de producto con IBM® Informix® Advanced Enterprise Edition, incluyendo soporte para IWA, y ahora sus propias ofertas HCL Informix 4GL e ISQL, así como nuevas e interesantes capacidades lanzadas en la versión 15. Con un modelo simplificado de licencias por núcleo, precios competitivos, un experimentado servicio de atención al cliente y sin dependencia de ningún proveedor de la nube, hay más motivos para enamorarse de HCL Informix [24].
Pero usted se preguntará: "Vale, ¿pero es HCL Informix un sistema NewSQL?". La respuesta corta es no. Sin embargo, HCL Informix ha evolucionado a lo largo de las décadas para incluir capacidades multimodelo (compatible con datos relacionales, documentales, de series temporales y espaciales), lo que le permite rivalizar tanto con los sistemas NewSQL como con los NoSQL. Su combinación única de características de base de datos relacional tradicional con capacidades modernas como alta disponibilidad, escalabilidad y gestión de datos híbridos la convierte en un competidor formidable en ambas categorías, posicionándola como una opción versátil para las empresas que buscan salvar la brecha entre la gestion des données estructurada y no estructurada gestion des données.
La API MongoDB de HCL Informix permite a los desarrolladores aprovechar de forma nativa las capacidades de almacenamiento y consulta de documentos similares a MongoDB, soportando también el shell de MongoDB y cualquiera de las utilidades y herramientas de comandos estándar de MongoDB, además de proporcionar una API REST, conectividad MQTT y fragmentación de datos JSON [25]. Al proporcionar una plataforma unificada para cargas de trabajo SQL y NoSQL, HCL Informix elimina la necesidad de DBMS independientes y reduce la complejidad operativa. Este enfoque híbrido es especialmente valioso para las empresas que gestionan cargas de trabajo transaccionales mixtas, que también requieren el almacenamiento de documentos JSON.
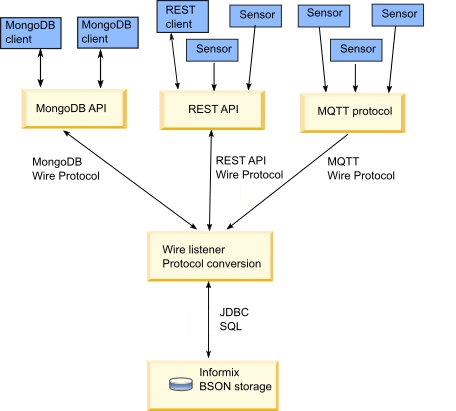
Arquitectura wire listeners de HCL Informix
Las funciones de replicación de datos de HCL Informix permiten replicar datos sin interrupciones entre nodos, lo que garantiza la cohérence los datos y la tolerancia a fallos [26]. HCL Informix ofrece un conjunto completo de funciones de replicación de datos -Replicación Empresarial (ER), Replicación de Datos de Alta Disponibilidad (HDR), Secundario Independiente Remoto (RSS) y Secundario de Disco Compartido (SDS)- que rivalizan con las capacidades de replicación de los sistemas NoSQL y NewSQL.
Enterprise Replication permite la replicación asíncrona multi-master a través de entornos geográficamente distribuidos, haciéndolo comparable a soluciones NoSQL como
MongoDB [27]. HDR, por otro lado, proporciona replicación síncrona para una configuración primaria-secundaria, asegurando una fuerte cohérence de datos, muy similar a las bases de datos NewSQL como SingleStore, que priorizan CAcohérence and Availability) en el teorema CAP [28].
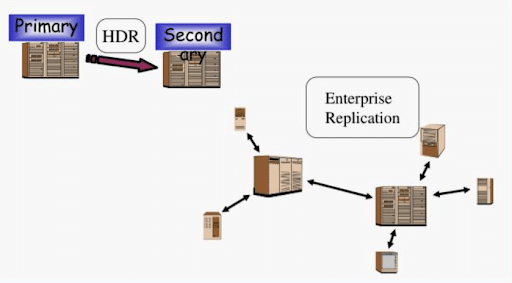
Enterprise Replication de HCL Informix frente a HDR
RSS añade flexibilidad al permitir réplicas de sólo lectura en ubicaciones remotas, optimizando la reprise après sinistre y la escalabilidad de lectura global, similar a la configuración de preferencia de lectura de MongoDB o las réplicas regionales de Spanner [29]. Por último, SDS amplía la escalabilidad y la tolerancia a fallos al permitir una arquitectura de disco compartido con latencia mínima, lo que la hace ideal para cargas de trabajo OLTP de haute performance [30].

Características HADR vs. ER de HCL Informix
Las capacidades VLDB de HCL Informix refuerzan aún más su posición frente a los sistemas NoSQL y NewSQL en el manejo de conjuntos de datos masivos. SmartBLOBs permite la gestión de grandes volúmenes de datos no estructurados al proporcionar capacidades eficientes de almacenamiento, recuperación y manipulación de contenido multimedia, documentos y otros tipos de datos BLOB/CLOB, integrados a la perfección en flujos de trabajo transaccionales, una funcionalidad mejorada con el lanzamiento de External SmartBLOBs en HCL Informix 15 [31].
Además, HCL Informix 15 tiene direcciones de filas y páginas más grandes: su tamaño de tabla ha aumentado 134 millones de veces, el tamaño de trozo 2,25 millones de veces y la capacidad de almacenamiento 4,2 millones de veces en comparación con HCL Informix 14.10. Este cambio ha hecho que la capacidad máxima de almacenamiento de una sola instancia de HCL Informix 15 sea de medio yottabyte, ¡o 4 veces el tamaño estimado de Internet! Este cambio hace que la capacidad máxima de almacenamiento de una única instancia de HCL Informix 15 sea de medio yottabyte, es decir, ¡4 veces el tamaño estimado de Internet!

HCL Informix 15 Re-Arquitectada para una Mejora Masiva de la Capacidad de Almacenamiento
Juntas, estas características proporcionan a las empresas un conjunto de herramientas de replicación versátil y la capacidad de manejar cantidades masivas de datos, tendiendo un puente entre la fiabilidad de los RDBMS tradicionales y el escalado horizontal de las modernas plataformas NoSQL y NewSQL. Para una comparación en profundidad de HCL Informix con algunos proveedores clave de NewSQL, consulte las tablas siguientes:
| Característica/Métrica | Informix | Proveedores NewSQL |
| Categoría | SGBDR tradicional con capacidad multimodelo | Bases de datos híbridas que combinan características RDBMS con escalabilidad NoSQL |
| Arquitectura | Arquitectura RDBMS tradicional con agrupación en clústeres opcional y funciones de nube mejoradas | Arquitecturas distribuidas y nativas de la nube creadas para la escalabilidad horizontal |
| Modelos de datos compatibles | Relacional, documento (JSON), series temporales, espacial | CucarachaDB: Relacional
SingleStore: Relacional, Clave/Valor, Documento (JSON), Orientado a Objetos, Multivalor, Vectorial Llave inglesa: Relacional, Clave/Valor, Vectorial YugabyteDB: Relacional, Clave/Valor |
| Transacciones por segundo (TPS) | 2 millones de TPS | CucarachaDB: 1,684,437 TPS
SingleStore: 10M TPS Google Cloud Spanner: 1B TPS YugabyteDB: 100K |
| Capacidad máxima de almacenamiento | Medio Yottabyte | CucarachaDB: ~890TB (10TiB por nodo, se recomiendan 81 nodos como máximo)
SingleStore: Ilimitado (teóricamente ilimitado en Spanner: ~850TB (10TB por nodo, 85 nodos como máximo - pero los usuarios pueden solicitar un aumento) YugabyteDB: ~1000TB (10TB por nodo, 100 nodos como máximo probados - pero puede manejar más, pero pueden producirse cuellos de botella en el rendimiento) |
| Tablas por base de datos | 477.102.080 (máximo de tablas por sistema, admite hasta 21M de bases de datos por sistema) | CucarachaDB: Prácticamente ilimitado
SingleStore: Prácticamente ilimitado Llave inglesa: 5000 YugabyteDB: Prácticamente ilimitado |
| Columnas por tabla | 32K | CucarachaDB: 1600
SingleStore: 4096 Llave inglesa: 1024 YugabyteDB: 1600 (límite en PSQL, no en el propio YugabyteDB) |
| Escalabilidad | Diseñado para el escalado vertical (scale-up) aprovechando un hardware más potente; admite el escalado horizontal (scale-out) pero requiere una configuración específica.
Las funciones de escalado horizontal incluyen fragmentación, fragmentación en fragmentos (tanto fragmentos locales o remotos como fragmentos de datos JSON), replicación y consultas distribuidas. |
CucarachaDB: Escalabilidad horizontal: los datos se reparten automáticamente entre los nodos y es posible añadir o eliminar nodos sin esfuerzo.
SingleStore: Admite escalado vertical y horizontal, optimizado para consultas rápidas y cargas de trabajo mixtas OLTP/OLAP. Spanner: Escalabilidad horizontal excepcional; se amplía a regiones y zonas manteniendo la cohérence global. YugabyteDB: altamente escalable, escala horizontalmente añadiendo nodos, diseñado para la distribución global. |
| Cumplimiento de la normativa ACID | Totalmente compatible con ACID, lo que garantiza transacciones sólidas en configuraciones de nodo único y distribuidas. | CucarachaDB: Totalmente compatible con ACID, incluso en transacciones distribuidas
SingleStore: Proporciona conformidad ACID, pero la transaccionalidad puede variar en función de los tipos de tabla específicos. Spanner: Totalmente compatible con ACID con cohérence fuerte basada en TrueTime. YugabyteDB: totalmente compatible con ACID, diseñado para cargas de trabajo transaccionales distribuidas. |
| Teorema CAP | Se adhiere principalmente a CAcohérence & Availability) adecuado para cargas de trabajo OLTP en redes estables. | CucarachaDB: Se centra en CP cohérence & Partition Tolerance), sacrificando la Disponibilidad en determinados escenarios de partición.
SingleStore: Destinado a CA, optimizado para el rendimiento sobre una estricta tolerancia a las particiones. Spanner: Equilibra CP, con transacciones globalmente consistentes usando TrueTime YugabyteDB: da prioridad al CP y ofrece una gran cohérence en configuraciones distribuidas |
| Facilidad de uso | Ecosistema maduro y preparado para la empresa con una amplia gama de herramientas e integraciones, y una sólida documentación |
CucarachaDB: Fácil de configurar con conocimientos de SQL y herramientas intuitivas; el escalado horizontal sin fisuras puede requerir cierta experienciaSingleStore: Diseñado para facilitar su uso con funciones centradas en la integración (por ejemplo, pipelines), pero la gestión de los tipos de tablas (rowstore frente a columnstore) añade complejidad. Llave inglesa: Sencillo para operaciones básicas, pero las funciones avanzadas requieren comprender TrueTime y la distribución global. YugabyteDB: sintaxis SQL conocida y buena documentación para desarrolladores; déploiement distribuido puede resultar complicado para los principiantes. |
| Casos de uso | Ideal para OLTP, datos IoT, cargas de trabajo de series temporales y aplicaciones empresariales tradicionales que requieren un rendimiento estable.
Soporte para cargas de trabajo OLAP pensadas para IWA o integración en tiempo real con Actian Data Platform para analyse des données big data Compatibilidad con arquitecturas híbridas: HCL Informix está disponible on-prem y en mercados cloud (AWS, Azure, |
CucarachaDB: Se adapta perfectamente al OLTP distribuido global cargas de trabajo, configuraciones multirregión y aplicaciones SaaS modernas, y arquitecturas híbridas (on-prem, AWS, Azure, GCP, DigitalOcean)SingleStore: Optimizado para casos de uso OLTP y OLAP mixtos, análisis en tiempo real y cargas de trabajo de ingesta rápida como IoT. Servicio gestionado (SaaS) limitado a AWS. Spanner: Aplicaciones globales a escala empresarial con necesidades estrictas de cohérence y alta disponibilidad. Servicio gestionado (SaaS) limitado a GCP. YugabyteDB: cargas de trabajo transaccionales distribuidas y nativas de la nube, y arquitecturas de nube híbrida (on-prem, AWS, Azure, GCP) |
Gracias por leer, y si estás interesado en HCL Informix, Actian, la división de Datos y Análisis de HCLSoftware, está lista para apoyarte en tu viaje de modernización de bases de datos. Hasta el próximo episodio de Data Wars, ¡que la fuerza (de los datos) te acompañe! Si le ha gustado este blog, considere la posibilidad de suscribirse a mi boletín Data Wars en LinkedIn.
Homenaje a un legado de excelencia en la comunidad Informix
Dedico este artículo a la memoria de Harry Carlton Doe III, un pilar de la comunidad Informix cuya dedicación y conocimientos inspiraron a innumerables profesionales. Aunque nunca nos conocimos, las contribuciones de Carlton Doe -que incluyen ser miembro fundador del International Informix User Group (IIUG) y sus numerosos libros sobre Informix (de algunos de los cuales poseo un ejemplar)- han dejado una huella imborrable, y su legado sigue guiando y potenciando a toda la comunidad Informix.
OBS: Informix es una marca comercial de IBM Corporation en al menos una jurisdicción y se utiliza bajo licencia.
Referencias:
[1] Lawrence Fernandes. Data Wars: 2024 Wrap-Up.
[2] Aslett, Matthew (6 de abril de 2011). "De qué hablamos cuando hablamos de NewSQL". 451 Group.
[3] Lawrence Fernandes. Guerras de datos: una esperanza NewSQL.
[4] https://sacra.com/c/cockroach-labs/
[5] https://sacra.com/c/singlestore/
[6] https://www.verifiedmarketreports.com/product/newsql-database-market/
[7] https://dev.to/arctype/too-good-to-be-true-why-newsql-failed-l7p
[8] Los sistemas de bases de datos NewSQL no garantizan la cohérence, y yo culpo a Spanner. Daniel Abadi. Diversiones sobre los SGBD. 21 de septiembre de 2018.
[9] Bases de datos NewSQL. Mandeep Kumar. Julio, 2022.
[10] Google Spanner:Un viaje NewSQL o el principio del fin de la era NoSQL. Dr. Rabi Prasad Padhy. Octubre, 2018.
[11] Diez años de NewSQL: De vuelta al futuro de las bases de datos relacionales distribuidas. Matt Aslett. Junio, 2021.
[12] Andrew Pavlo. La retrospectiva oficial de diez años de las bases de datos NewSQL: Vídeo
[13] Andrew Pavlo. La retrospectiva oficial de diez años de las bases de datos NewSQL: PDF
[14] Art Kagle. Quora. ¿Cuáles son las ventajas de utilizar una base de datos Informix en lugar de una base de datos Oracle?
[15] Informix IDS vs Oracle: A Competitive Comparison. https://slideplayer.com/slide/6229837/
[16] https://en.wikipedia.org/wiki/Michael_Stonebraker
[17] Informix admite que un código defectuoso bloqueará Universal Server. TechMonitor, redactor de CBR, octubre de 1996. https://www.techmonitor.ai/technology/informix_admits_faulty_code_will_crash_universal_server
[18] New Era no ha desaparecido, sólo ha dejado de ser relevante. TechMonitor, CBR Staff Writer, julio de 1997. https://www.techmonitor.ai/technology/informixs_new_era_is_not_gone_just_no_longer_relevant_1/
[19] Steve W. Martin. 2005. La verdadera historia de Informix Software y Phil White: Lessons in Business and Leadership for the Executive Team. Sand Hill Publishing.
[20] Art Kagle. Quora. ¿Cuáles son los pros y los contras de utilizar Informix como base de datos? https://qr.ae/pYsl2Z
[21] Art Kagle. Quora. ¿Cuál es el futuro de Informix? https://qr.ae/pYsdFQ
[22] https://virtual-dba.com/blog/explaining-the-ibm-hcl-partnership/
[23] https://www.hcl-software.com/actian/informix
[24] https://www.actian.com/databases/hcl-informix/
[25] https://help.hcl-software.com/hclinformix/15.0.0/json/json.html
[26]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication
[27]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication/ER.xml
[28Embarqué
[29]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication/ER.xml
[30]https://docs.deistercloud.com/content/Databases.30/IBM%20Informix.2/Replication/RSS.xml
[31] https://help.hcl-software.com/hclinformix/15.0.0/1infocenter/new_features_ce.html#concept_v15.0.0.0__ext_sbspace_15.0.0.0
Descargo de responsabilidad:
No estoy afiliado ni avalado por ninguno de los autores citados ni por The Walt Disney Company. Las referencias a La guerra de las galaxias son puramente un homenaje hecho por fans.

Suscríbase al blog de Actian
Suscríbase al blog de Actian para recibir información sobre datos directamente en su correo electrónico.
- Manténgase informado: reciba lo último en análisis de datos directamente en su bandeja de entrada.
- No se pierda ni una publicación: recibirá actualizaciones automáticas por correo electrónico que le avisarán cuando se publiquen nuevas publicaciones.
- Todo depende de usted: cambie sus preferencias de entrega para adaptarlas a sus necesidades.