Desglosando el linaje de los datos: Tipologías y granularidad





Como concepto, el linaje de datos parece universal: sea cual sea el sector de actividad, cualquier parte interesada de una organización basada en datos necesita conocer el origen (linaje ascendente) y el destino (linaje descendente) de los datos que maneja o interpreta. Esta necesidad tiene importantes motivos subyacentes.
Para un proveedor de catálogos de datos, la capacidad de gestionar el linaje de datos es crucial para su oferta. Sin embargo, como ocurre a menudo, detrás de una pregunta simple y universal se esconde un mundo de complejidad difícil de comprender. Esta complejidad está en parte ligada a laheterogeneidad de las respuestas que varían de un interlocutor a otro en la empresa.
En este artículo, explicaremos nuestro enfoque para desglosar el linaje de datos según la naturaleza de la información buscada y su granularidad.
La tipología del linaje de los datos: en busca de su origen
Hay muchas respuestas posibles sobre el origen de cualquier dato. Algunos querrán saber la fórmula exacta o la semántica de los datos. Otros querrán saber de qué sistema(s), aplicación(es), máquina(s) o fábrica proceden. Algunos se interesarán por los procesos empresariales u operativos que produjeron los datos. Otros se interesarán por toda la cadena de procesamiento técnico ascendente y descendente. Es difícil encontrar una solución en este laberinto de consideraciones.
Un enfoque por capas
Para estructurar la información sobre linajes, sugerimos emular lo que se practica en el geomapas distinguiendo varias capas superponibles. Podemos identificar tres:
- La capa física que incluye los objetos del sistema de información: aplicaciones, sistemas, bases de datos, conjuntos de datos, programas de integración o transformación, etc.
- La capa empresarialque contiene los elementos organizativos: dominios, procesos o actividades empresariales, entidades, gestores, controles, comités, etc.
- La capa semánticaque se ocupa del significado de los datos: fórmulas de cálculo, definiciones, ontologías, etc.
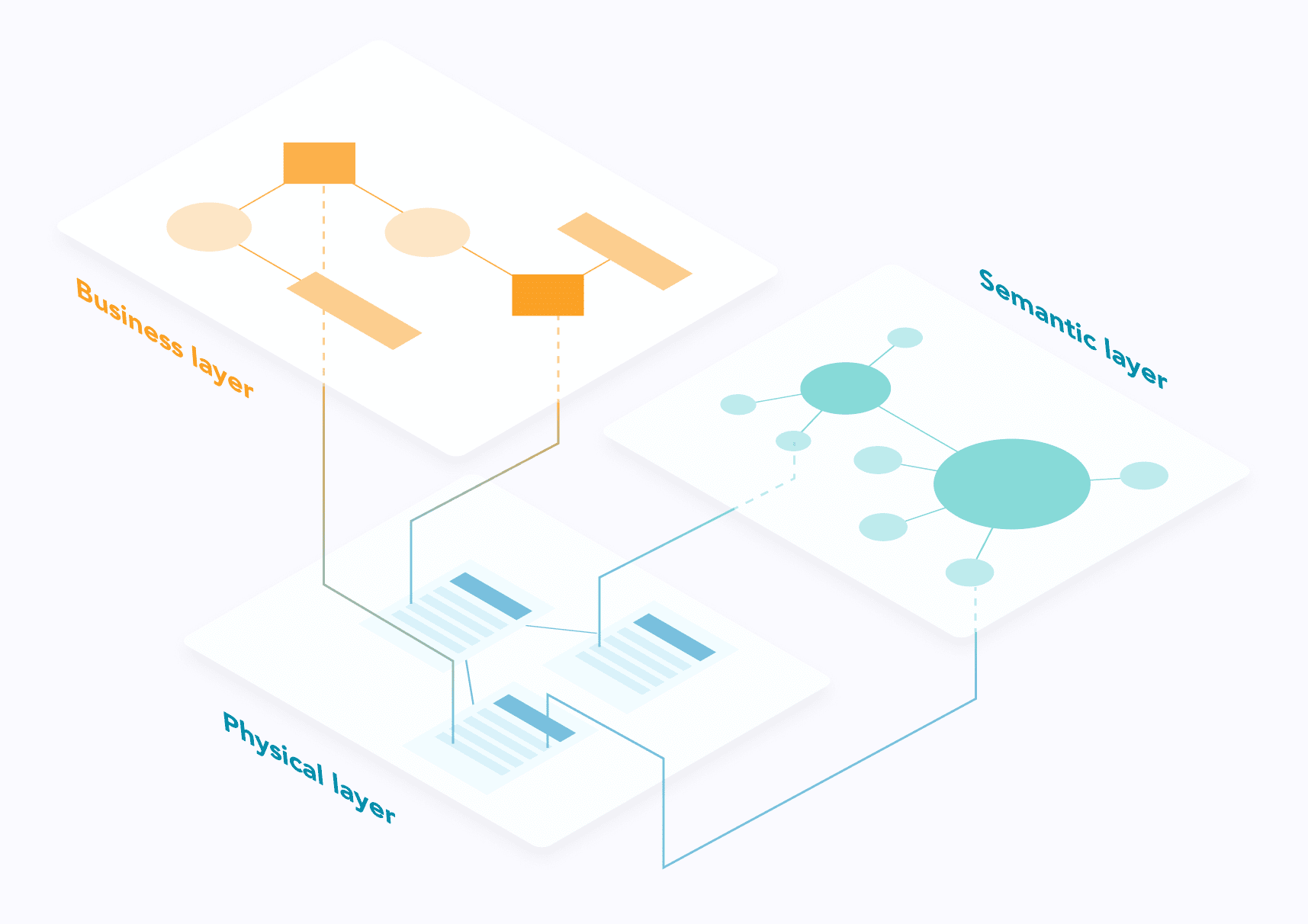
La capa física en el punto de mira
La capa física es el lienzo básico en el que pueden anclarse todas las demás capas. Este planteamiento es, de nuevo, similar a lo que se practica en la cartografía geográfica: sobre el mapa físico es posible superponer otras capas portadoras de información específica.
La capa física representa la dimensión técnica del linaje; se materializa mediante artefactos técnicos tangibles: bases de datos, sistemas de archivos, middleware de integración, herramientas de BI, scripts y programas, etc. En teoría, la estructura del linaje físico puede extraerse de estos sistemas y automatizarse en gran medida, lo que no suele ocurrir con las demás capas.
Lo siguiente parece fundamental: para que este enfoque ascendente funcione, es necesario que el linaje físico esté completo.
Esto no significa que deba existir el linaje de todos los objetos físicos, pero para los objetos que sí tienen linaje, éste debe ser completo. Hay dos razones para ello. La primera razón es que un linaje parcial (y por tanto falso) corre el riesgo de inducir a error a la persona que lo consulta, poniendo en peligro la adopción del catálogo. En segundo lugar, la capa física sirve de ancla para las demás capas, lo que significa que cualquier deficiencia en su linaje se propagará.
Además de esta representación por capas, abordemos otro aspecto fundamental del linaje: su granularidad.
Granularidad en el linaje de datos
En cuanto a la granularidad del linaje, identificamos 4 niveles distintos: valores, campos (o columnas), conjuntos de datos y aplicaciones.
Los valores pueden abordarse rápidamente. Su propósito es rastrear todos los pasos dados para calcular cualquier dato en particular (nos referimos a valores específicos, no a la definición de cualquier dato específico). Para las aplicaciones de fijación de precios según modelo, por ejemplo, el linaje de precios debe incluir todos los datos brutos (marca de tiempo, proveedor, valor), los valores derivados de estos datos brutos, así como las versiones de todos los algoritmos utilizados en el cálculo.
Los requisitos normativos existen en muchos campos (banca, finanzas, seguros, sanidad, farmacia, IoT, etc.), pero normalmente de forma muy localizada. Están claramente fuera del alcance de un catálogo de datos, ¡en el que es difícil imaginar la gestión de cada valor de datos! Para responder a estas necesidades se necesita un paquete de software especializado o un desarrollo específico.
Los otros tres niveles se refieren a los metadatos, y son claramente competencia de un catálogo de datos. Vamos a detallarlos rápidamente.
La dirección nivel de campo es el nivel más detallado. Consiste en trazar todas las etapas (a nivel físico, de negocio o semántico) de una información en un conjunto de datos (tabla o archivo), un informe, un cuadro de mandos, etc., que permiten rellenar el campo en cuestión.
A nivel conjunto de datosel linaje ya no se define para cada campo, sino a nivel del contenedor de campos, que puede ser una tabla en una base de datos, un archivo en un lago de datos, una API, etc. En este nivel se representan los pasos que permiten poblar el conjunto de datos en su conjunto, normalmente a partir de otros conjuntos de datos (también encontramos en este nivel otros artefactos como informes, cuadros de mando, modelos ML o incluso algoritmos).
Por último, el nivel de aplicación permite documentar el linaje macroscópicamente, centrándose en los elementos lógicos de alto nivel del sistema de información. El término "aplicación" se utiliza aquí de forma genérica para designar una agrupación funcional de varios conjuntos de datos.
Por supuesto, es posible imaginar otros niveles más allá de esos 3 (agrupando las aplicaciones en dominios de negocio, por ejemplo), pero aumentar la complejidad es más una cuestión de mapeo de flujos que de linaje.
Por último, es importante tener en cuenta que cada nivel está interrelacionado con el nivel superior. Esto significa que el linaje del nivel superior puede calcularse a partir del linaje del nivel inferior (si conozco el linaje de todos los campos de un conjunto de datos, puedo deducir la edad del linaje de este conjunto de datos).
Esperamos que este desglose del linaje de datos le ayude a entenderlo mejor para su organización. En un próximo artículo, compartiremos nuestro enfoque para que cada negocio pueda obtener el máximo valor de Lineage gracias a nuestra tipología/granularidad/matriz de negocio.
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ejemplo, ventas@..., asistencia@...)