Amundsen: Cómo Lyft puede descubrir fácilmente sus datos





En nuestro último artículo, hablamos de Databook de Uber, una plataforma interna diseñada por sus propios ingenieros con el objetivo de convertir los datos en activos contextualizados. En este artículo, nos centraremos en la plataforma de metadatos y descubrimiento de datos de Lyft: Amundsen.
En respuesta al éxito de Uber, el mercado de los viajes compartidos vio llegar una importante oleada de competidores, y entre ellos está Lyft.
Cifras clave y estadísticas de Lyft
Fundada en 2012 en San Francisco, Lyft opera en más de 300 ciudades de Estados Unidos y Canadá. Con más del 29% del mercado estadounidense de viajes compartidos*, Lyft se ha asegurado sin duda la segunda posición, codo con codo con Uber. Algunas estadísticas clave sobre Lyft son:
- 23 millones de usuarios de Lyft en enero de 2018.
- Más de mil millones de viajes con Lyft.
- 1,4 millones de conductores (dic. 2017).
Y, por supuesto, esas cifras se han transformado en cantidades colosales de datos que gestionar. En una empresa moderna basada en datos como Lyft, es evidente que la plataforma se alimenta de datos. Con el rápido aumento del panorama de los datos, cada vez es más difícil saber qué datos existen, cómo acceder a ellos y qué información está disponible.
Este problema llevó a la creación de Amundsen, la solución de descubrimiento de datos y plataforma de metadatos de código abierto de Lyft.
Conozcamos a Amundsen
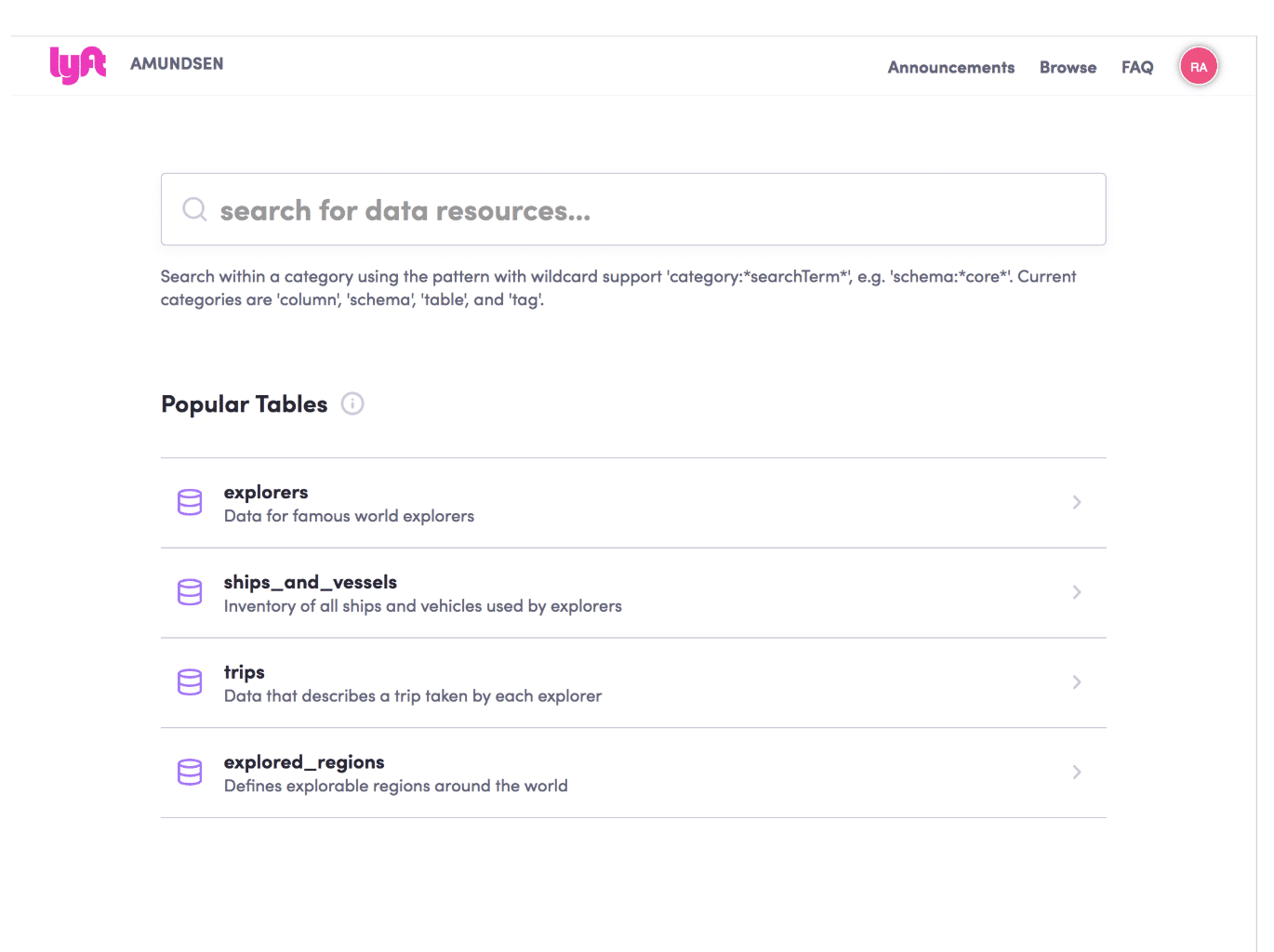
Lyft, que toma su nombre del explorador noruego Roald Amundsen, mejora la productividad de sus usuarios de datos ofreciéndoles una interfaz de búsqueda intuitiva de datos, que tiene este aspecto:
Aunque los científicos de datos de Lyft querían dedicar la mayor parte del tiempo al desarrollo y la producción de modelos, se dieron cuenta de que dedicaban la mayor parte de su tiempo al descubrimiento de datos. Se hacían preguntas como las siguientes:
- ¿Existen estos datos? En caso afirmativo, ¿dónde puedo encontrarlos? ¿Puedo acceder a ellos?
- ¿Quién / qué equipo es el propietario? ¿Quiénes son los usuarios comunes?
- ¿Puedo fiarme de estos datos?
Para responder a estas preguntas, Lyft se inspiró en motores de búsqueda como Google.
Como se muestra más arriba, su punto de entrada es un sencillo cuadro de búsqueda en el que los usuarios pueden escribir cualquier palabra clave, como "clientes" "empleados" o "precio". Sin embargo, si el usuario de datos no sabe lo que busca, la plataforma le presenta una lista de las tablas más populares, para que pueda navegar libremente por ellas.
Algunas características clave:
Los resultados de la búsqueda se muestran en "forma de lista", donde aparece la descripción sobre la tabla y la fecha de su última actualización. La clasificación utilizada es similar al Page Rank de Google, donde las tablas más populares y relevantes aparecen en los primeros resultados.
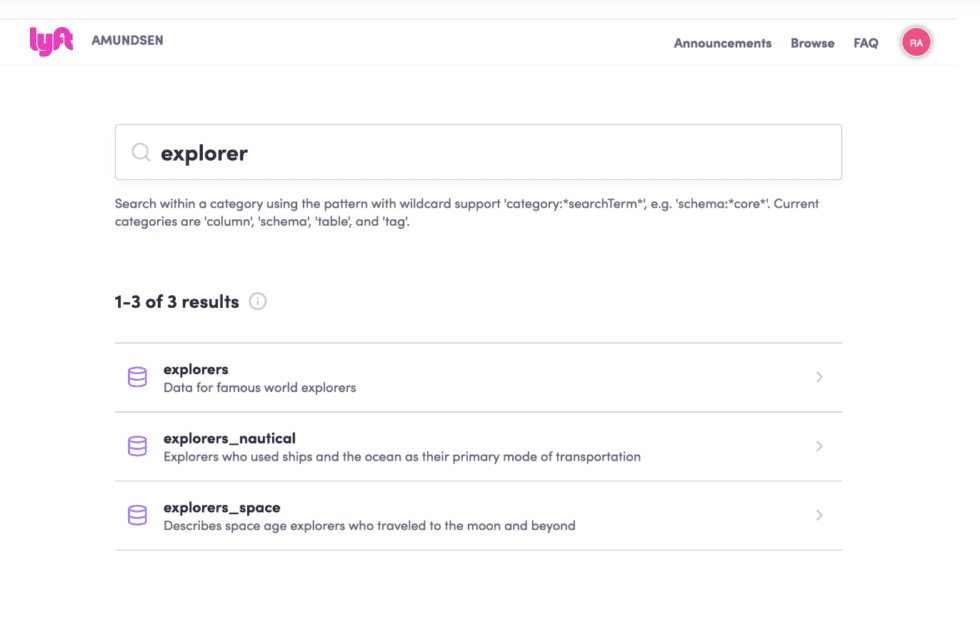
Cuando un usuario de datos en Lyft encuentra lo que busca y selecciona su opción, se le dirige a una página de detalles que muestra el nombre del cuadro, así como su descripción curada manualmente. Los usuarios también pueden insertar manualmente etiquetas, los propietarios y otras descripciones. Sin embargo, muchos de sus metadatos se seleccionan automáticamente, como la popularidad de la mesa o incluso sus usuarios frecuentes.
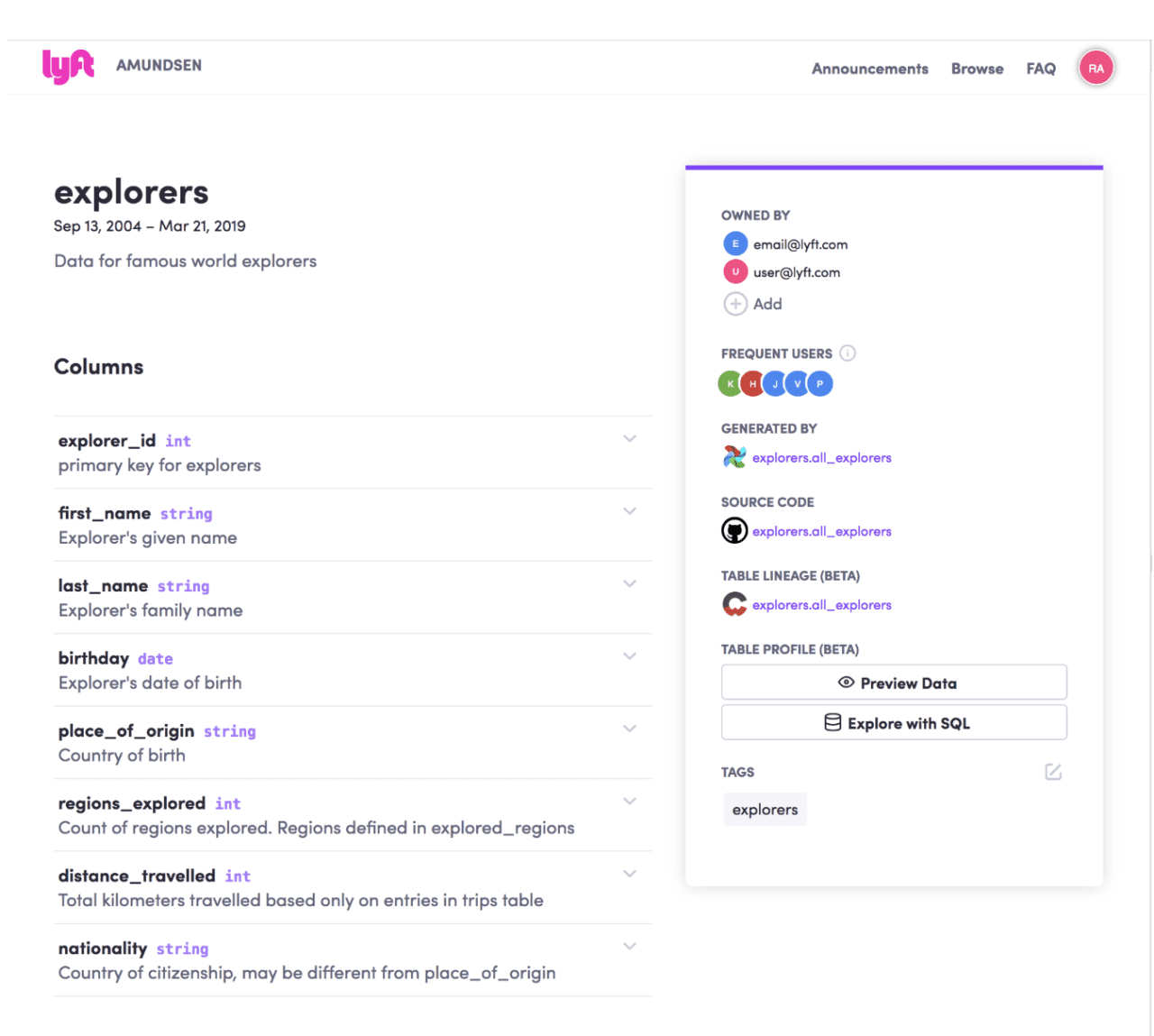
Cuando están en una tabla, los usuarios pueden explorar las columnas asociadas para descubrir más a fondo los metadatos de la tabla.
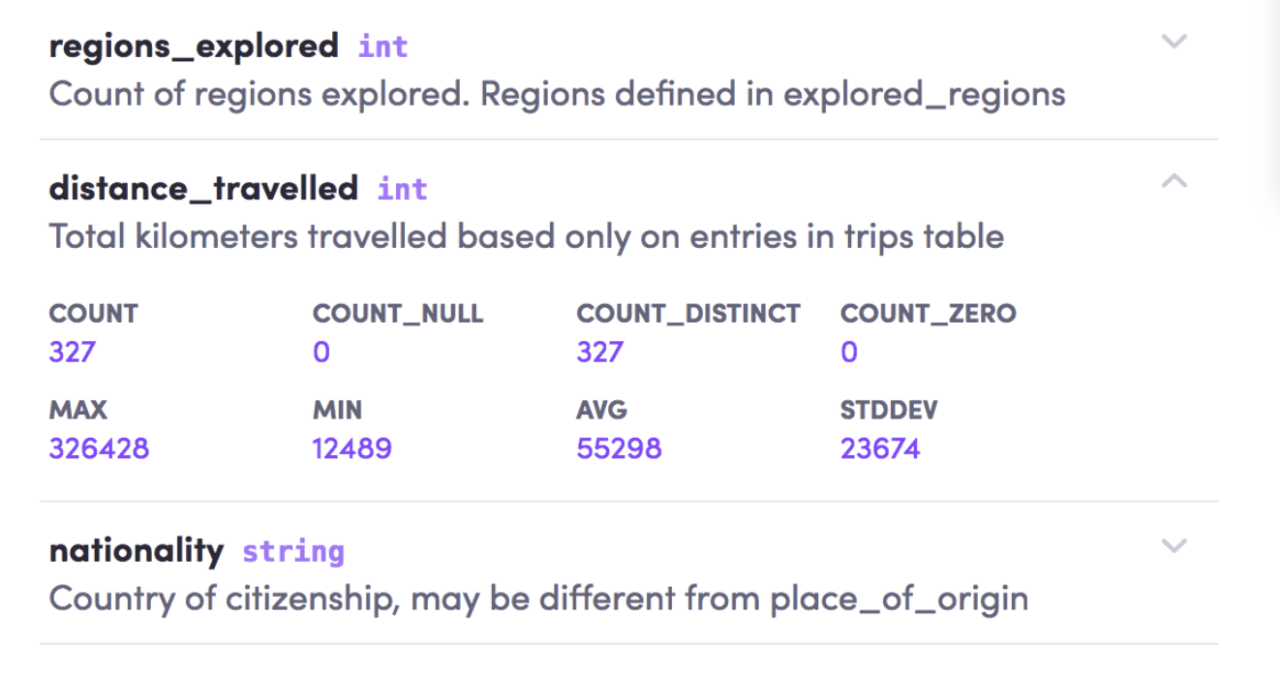
Por ejemplo, si selecciona la columna "distancia_viajada" como se muestra a continuación, encontrará una pequeña definición del campo y sus estadísticas relacionadas, como el registro de recuento, el recuento máximo, el recuento mínimo, el recuento medio, etc., para que los científicos de datos comprendan mejor la forma de sus datos.
Por último, los usuarios pueden acceder a ver los datos del conjunto de datos pulsando el botón de vista previa de la página. Por supuesto, esto sólo es posible si el usuario tiene acceso a los datos subyacentes en primer lugar.
Amundsen democratiza la búsqueda de datos
Mostrar los datos pertinentes
Amundsen permite ahora a todos los empleados de Lyft, desde los nuevos hasta los más experimentados, ser autónomos en el descubrimiento de datos para sus tareas diarias.
Ahora hablemos de técnica. El almacén de datos de Lyft está en Hive y todas las particiones físicas se almacenan en S3. Sus usuarios de datos confían en Presto, un motor de consulta en vivo, para el descubrimiento de sus tablas. Para que su motor de búsqueda muestre las tablas más importantes o relevantes para sus usuarios, Lyft utiliza el framework DataBuilder para construir un extractor de uso de consultas que analiza los registros de consultas para obtener datos de uso de tablas. A continuación, persisten en este uso de la tabla como un documento de tabla Elasticsearch. Y así es como, en muy poco tiempo, son capaces de recuperar los conjuntos de datos más relevantes para sus usuarios de datos.
Conectar los datos con las personas
Por mucho que nos guste afirmar lo técnicos y digitales que somos todos, los procesos de búsqueda de datos consisten principalmente en interacciones con personas. Y la noción de propiedad de los datos es bastante confusa; lleva mucho tiempo a menos que se sepa exactamente a quién preguntar.
Amundsen aborda este problema creando relaciones entre sus usuarios y sus datos, de modo que el conocimiento tribal se comparte a través de la exposición de estas relaciones.
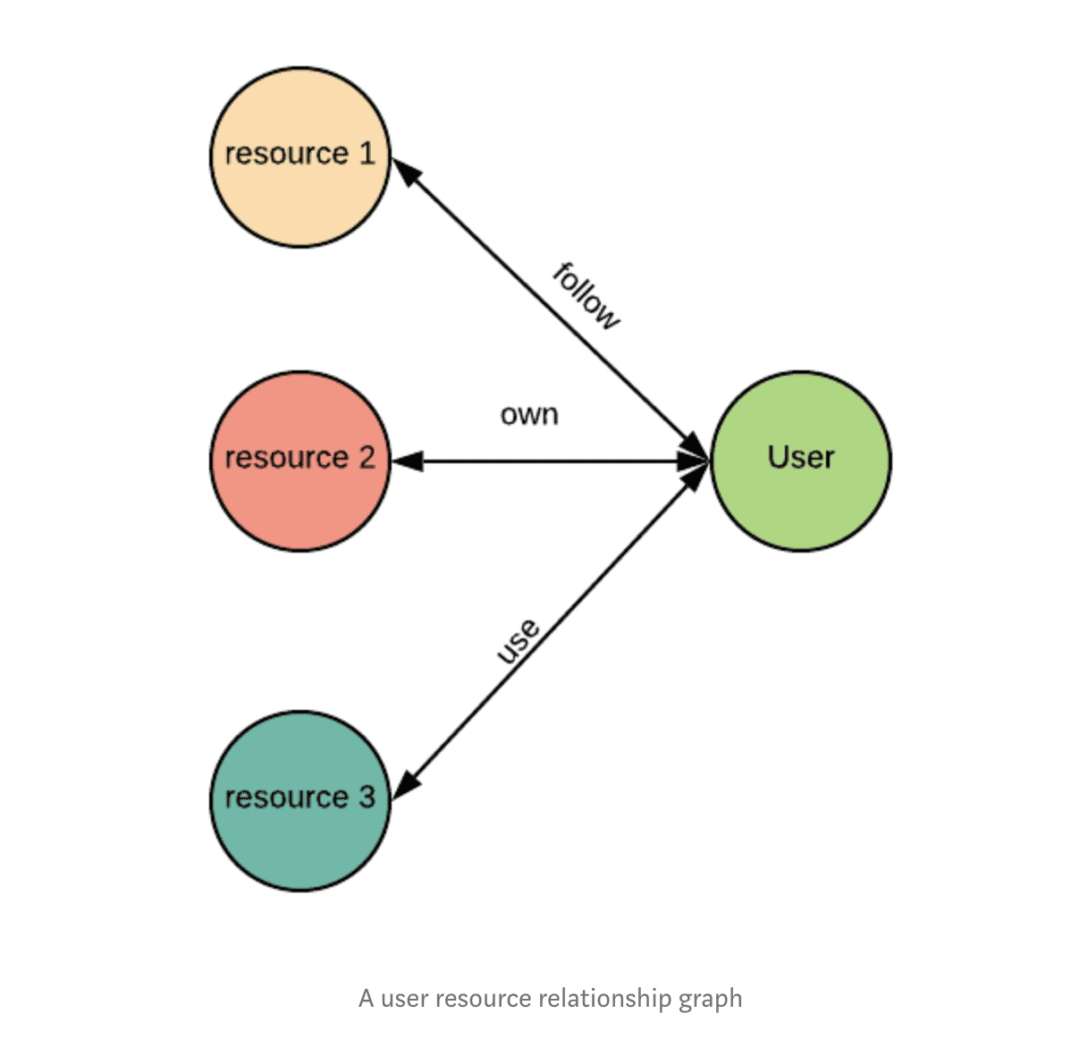
Lyft tiene actualmente tres tipos de relaciones entre usuarios y datos: seguidos, propios y usados. Esta información ayuda a los empleados experimentados a convertirse en recursos útiles para otros empleados con una función laboral similar. Amundsen también hace que el conocimiento tribal sea más fácil de encontrar gracias a un enlace a cada perfil de usuario en el directorio interno de empleados.
También han estado trabajando en la implementación de una función de notificaciones que permita a los usuarios solicitar más información a los propietarios de los datos como, por ejemplo, la falta de una descripción en una tabla.
Si desea más información sobre Amundsen, visite su sitio web aquí.
El futuro de Lyft
Lyft espera seguir trabajando con una comunidad cada vez mayor para mejorar su experiencia de descubrimiento de datos y aumentar la productividad de los usuarios. Su hoja de ruta incluye actualmente un sistema de notificaciones por correo electrónico, linaje de datos, rediseño de la interfaz de usuario y la interfaz de usuario, ¡y mucho más!
La empresa de viajes compartidos aún no ha dicho su última palabra.
Fuentes:
Lyft: estadísticas y datos:https://www.statista.com/topics/4919/lyft/
Lyft y su camino hacia el éxito:https://www.startupstories.in/stories/lyft-and-its-drive-through-to-success
Estadísticas de ingresos y uso de Lyft (2019):https://www.businessofapps.com/data/lyft-statistics/
Infraestructura Presto en Lyft:https://eng.lyft.com/presto-infrastructure-at-lyft-b10adb9db01?gi=f100fa852946
Amundsen de código abierto: una plataforma de descubrimiento de datos y metadatos:https://eng.lyft.com/open-sourcing-amundsen-a-data-discovery-and-metadata-platform-2282bb436234
Amundsen: motor de descubrimiento de datos y metadatos de Lyft:https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)