¿Cuál es la diferencia entre un Data Analytics Hub y un Lakehouse?





En la primera entrega de esta serie de blogs - Lagos de datos, almacenes de datos y concentradores de datos: ¿Necesitamos otra opción? exploro por qué la simple migración de estas plataformas de integración, gestión y análisis de datos on-prem a la nube no satisface plenamente las necesidades modernas de análisis de datos. Al comparar estas tres plataformas, queda claro que todas ellas satisfacen ciertas necesidades críticas, pero ninguna de ellas satisface las necesidades de los usuarios finales de las empresas sin un apoyo significativo de TI. En el segundo blog de esta serie - ¿Qué es un centro de análisis de datos? - introduzco el término concentrador de análisis de datos para describir una plataforma que toma los elementos operativos y analíticos óptimos de los concentradores, lagos y almacenes de datos y los combina con las características y funcionalidades de la nube para abordar directamente las necesidades operativas y de autoservicio en tiempo real de los usuarios empresariales (y no exclusivamente de los usuarios de TI). También me tomaré un momento para examinar una cuarta tecnología relacionada, el centro de análisis. Dada la proximidad titular de centro de análisis a centro de análisis de datos, sólo tenía sentido aclarar que un centro de análisis sigue siendo una solución tan incompleta para el análisis moderno como lo es un lago de datos, un centro y un almacén.
¿Por qué? Porque, en esencia, un centro de análisis de datos toma lo mejor de todas estas plataformas de integración, gestión y análisis y las combina en una única plataforma. Un concentrador de análisis de datos reúne la agregación de datos, la gestión y el soporte analítico para cualquier fuente de datos con cualquier herramienta de BI o IA, visualización, generación de informes u otro destino. Además, un centro de análisis de datos está diseñado para ser accesible a todos los usuarios de un equipo multifuncional (incluso virtual). El siguiente diagrama muestra la relación entre los cuatro predecesores y el centro de análisis de datos (le resultará familiar si ha leído la segunda entrega de esta serie).
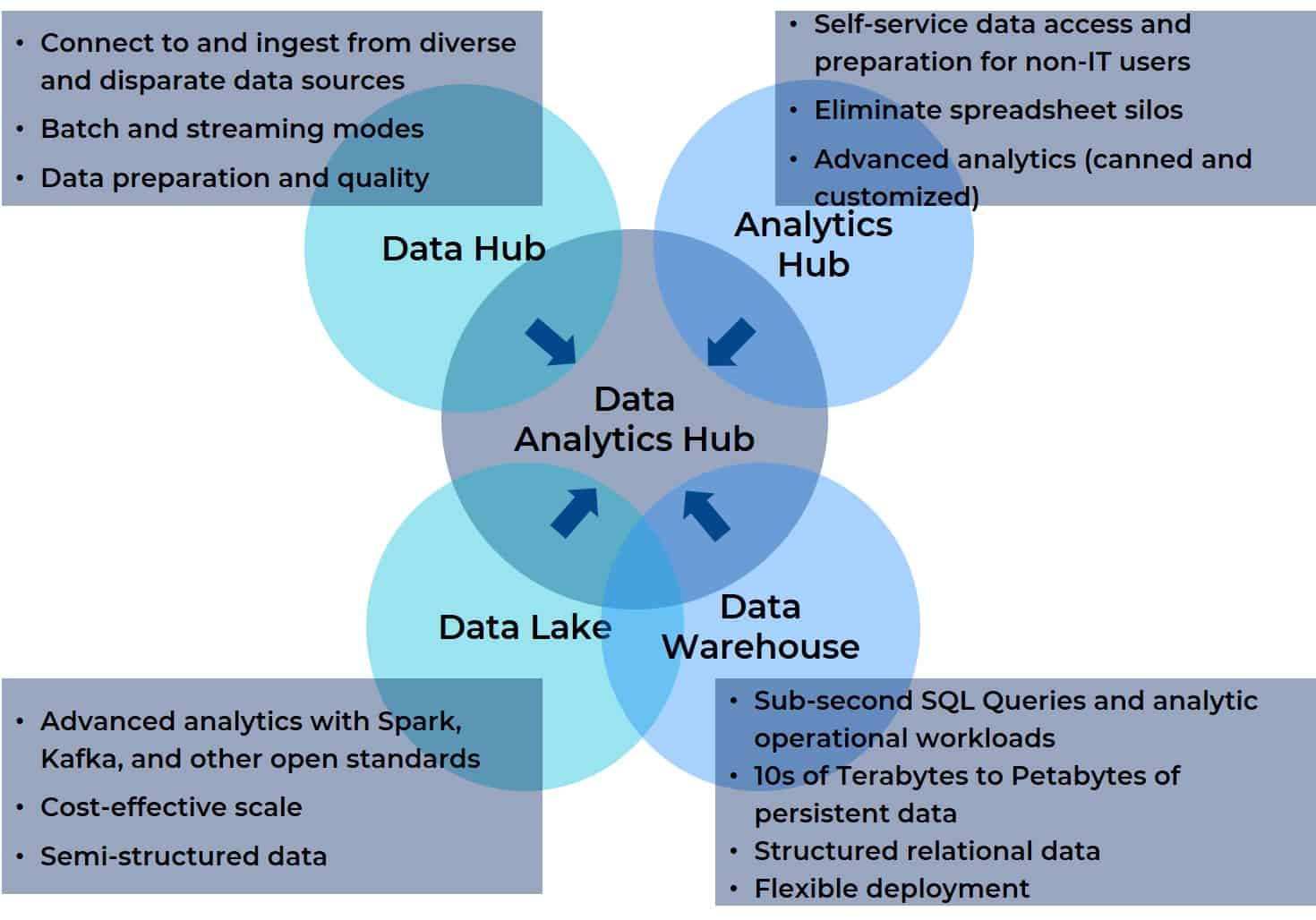
Espera... ¿Qué pasa con Data Lakehouse?
La semana pasada tuve el privilegio de recibir a Bill Inmon, considerado el padre del almacenamiento de datos, en un seminario en línea sobre la integración moderna de datos en almacenes de datos en la nube. No hace falta decir que hubo muchas preguntas para Bill, pero hubo una que pensé que merecía un debate centrado aquí: ¿Qué es un data lakehouse y en qué se diferencia de un data lake o un data warehouse?
Empecemos por lo más obvio y que el nombre no deja lugar a dudas: un data lakehouse es una combinación de hardware básico, estándares abiertos y capacidades de gestión de datos semiestructurados y no estructurados de un lago de datos y SQL Analytics, soporte de esquemas estructurados e integración de herramientas de BI de un almacén de datos. Esto es importante porque la cuestión no es tanto en qué se diferencia un data lakehouse de un data lake o un data warehouse, sino en qué se parece más a uno u otro. Y esta distinción es importante porque el punto de partida de la convergencia es importante. En términos matemáticos sencillos, si A + B = C, entonces B + A = C. Pero en el mundo real esto no es del todo cierto. El punto de partida lo es todo cuando se trata de la convergencia de dos plataformas o productos, ya que ese punto de partida informa de tu visión de adónde vas, de tu percepción del viaje y de tu sensación de si has acabado o no donde esperabas cuando por fin has llegado al final del trayecto.
Hablando de viajes, hagamos un pequeño recorrido por la memoria para comprender los retos que impulsaron la idea de un lago de datos.
Históricamente, los lagos de datos eran el reino de los científicos de datos y los usuarios avanzados. Admitían grandes cantidades de datos -estructurados y no estructurados- para la exploración de datos y complicados proyectos de ciencia de datos en hardware estándar abierto. Pero esas necesidades no requerían acceso a datos activos como los asociados al proceso operativo diario de la empresa. A menudo se convertían en laboratorios científicos y, en algunos casos, en vertederos de datos.
Esto contrasta con las necesidades históricas de los analistas de negocio y otros usuarios avanzados de la línea de negocio (LOB). Creaban y ejecutaban cargas de trabajo operativas asociadas con análisis SQL, BI, visualización e informes, y necesitaban acceder a datos activos. Para satisfacer sus necesidades, los departamentos de TI crearon almacenes de datos empresariales, que tradicionalmente aprovechaban un conjunto limitado de repositorios de datos de aplicaciones ERP íntimamente ligados a las operaciones diarias. El departamento de TI tenía que intermediar entre el almacén de datos y los analistas de negocio y los usuarios avanzados de la LOB, pero el propio almacén de datos proporcionaba de forma eficaz un bucle de retroalimentación cerrado que impulsaba la información para mejorar el apoyo a la toma de decisiones y la agilidad empresarial.
Sin embargo, a medida que ha avanzado la transformación digital, las necesidades han cambiado. Las aplicaciones se han vuelto más inteligentes e impregnan todos los aspectos de la empresa. Las expectativas para los lagos de datos y los almacenes de datos han evolucionado. La demanda de apoyo a la toma de decisiones en tiempo real ha reducido el bucle de retroalimentación del almacén de datos/repositorio ERP asintóticamente, hasta el punto de acercarse al tiempo real. Y el conjunto original de repositorios ERP ya no son los únicos repositorios de interés para los analistas de negocio y los usuarios avanzados de LOB: los flujos de clics web, IoT, archivos de registro y otras fuentes también son piezas fundamentales del rompecabezas. Pero estas otras fuentes se encuentran en los conjuntos de datos dispares y diversos que nadan en los lagos de datos y abarcan múltiples aplicaciones y departamentos. Esencialmente, cada aspecto de la interacción humana puede modelarse para revelar información que puede mejorar en gran medida la precisión operativa, por lo que consolidar los datos de un universo de datos diverso y dispar y convertirlos en una vista unificada se ha cristalizado como un requisito clave. Esta necesidad está impulsando la convergencia en los espacios de los lagos de datos y los almacenes de datos y dando lugar a la idea de una casa lago de datos.
Volvamos al presente: Dos de los principales defensores de los data lakehouses son databricks y Snowflake. El primero aborda la tarea de consolidación de plataformas desde la perspectiva de un vendedor de lagos de datos y el segundo desde la de un vendedor de almacenes de datos. Lo que comparten sus ofertas de data lakehouse es lo siguiente:
- Acceso directo a los datos de origen para herramientas de BI y análisis (desde el lado del almacén de datos ).
- Compatibilidad con datos estructurados, semiestructurados y no estructurados (desde el lado del lago de datos).
- Soporte de esquemas con conformidad ACID en lecturas y escrituras concurrentes (desde el lado del almacén de datos).
- Herramientas de estándar abierto para apoyar a los científicos de datos (desde el lado del lago de datos).
- Separación de cálculo y almacenamiento (desde el punto de vista del almacén de datos).
Entre las principales ventajas compartidas figuran:
- Eliminación de la necesidad de repositorios separados para la ciencia de datos y las cargas de trabajo de BI operativas.
- Reducción de la carga administrativa de TI.
- Consolidar los silos establecidos por las herramientas individuales de BI e IA que crean sus propios repositorios de datos.
El énfasis lo es todo
Mejorar la velocidad y la precisión del análisis de conjuntos de datos grandes y complejos no es una tarea para la que la mente humana esté bien preparada; sencillamente, no somos capaces de comprender ni detectar patrones sutiles en conjuntos de datos realmente grandes y complejos (o, dicho de otro modo, lo siento, pero no eres Neo y no puedes «ver» Matrix en un flujo de datos digitales). Sin embargo, la IA es muy buena para encontrar patrones en conjuntos de datos multivariantes complejos, siempre y cuando los científicos de datos puedan diseñar, entrenar y ajustar los algoritmos necesarios para ello (tareas para las que sus mentes están muy bien preparadas). Una vez que los algoritmos se han ajustado e implementado como parte de las cargas de trabajo operativas, pueden respaldar la toma de decisiones realizada por humanos (apoyo a la toma de decisiones basado en el conocimiento de la situación) o realizada de forma programática (apoyo a la toma de decisiones automatizado y ejecutado por máquinas como operaciones de máquina a máquina no supervisadas). Con el tiempo, cualquiera de estos algoritmos, o todos ellos, pueden necesitar ajustes basados en un patrón de resultados o en desviaciones respecto a los resultados esperados o deseados. Una vez más, y no es que sienta la necesidad de hacer publicidad, estas son tareas para las que la mente humana está bien preparada.
Pero volvamos al impulso hacia la convergencia y analicemos desde dónde parten los proveedores de data lakehouse. ¿Cuál es su punto de vista? ¿Y cómo influye eso en la visión que tienen de cómo debería ser el destino convergente? Históricamente, los data lakes han sido utilizados por científicos de datos, con la ayuda de ingenieros de datos y otro personal de TI cualificado, para recopilar y analizar los datos necesarios para gestionar la fase inicial del ciclo de vida de la IA, especialmente en lo que respecta al aprendizaje automático (ML). Ampliar ese entorno significa facilitar la implementación de su ML en las cargas de trabajo operativas. Desde esa perspectiva, el éxito sería una plataforma convergente que acortara el ciclo de vida del ML y lo hiciera más eficiente. Sin embargo, para los analistas de negocio, los ingenieros de datos y los usuarios avanzados, jugar con algoritmos o crear conjuntos de datos de referencia para entrenar y ajustar no forma parte de su trabajo diario. Para ellos, lo que importa es ejecutar además el ML como parte de sus cargas de trabajo operativas, incluyendo los conjuntos de datos adicionales, diversos y dispares.
Aunque los científicos e ingenieros de datos no pertenezcan propiamente a los departamentos de TI, no son lo mismo que los usuarios finales no informáticos. Los lagos de datos suelen ser entornos complejos en los que trabajar, con múltiples API y cantidades significativas de codificación, lo que está bien para los científicos de datos y los ingenieros, pero no lo está en absoluto para las funciones ajenas a TI, como los analistas empresariales y operativos o sus equivalentes en diversos departamentos de LOB. Lo que realmente necesitan es una convergencia que amplíe un almacén de datos para gestionar los componentes de ML operacionalizados en sus cargas de trabajo en una plataforma unificada, sin aumentar la complejidad del entorno ni añadir requisitos para pasar muchas noches y fines de semana obteniendo nuevos títulos.
¿Estamos escuchando a todos los que debemos?
He trabajado en gestión y marketing de productos y, al final, la voz que llega más lejos y más alto es la de los clientes. Ellos son los que siempre definirán mejor las características y funcionalidades incrementales de tus productos. Para los proveedores de lagos de datos, son los científicos de datos, los ingenieros y los informáticos; para los proveedores de almacenes de datos, son los informáticos. Lógicamente, los confines del dominio del problema se limitan a estos grupos.
Pero, ¿saben qué? Esta lógica pasa por alto al grupo más importante que existe
Ese grupo está formado por la empresa y sus representantes, los analistas empresariales y operativos y otros usuarios poderosos ajenos a TI y a la ingeniería. Los proveedores de lagos de datos y almacenes de datos -y, por extensión, los proveedores de data lakehouse- no hablan con estos usuarios porque TI siempre está en medio, siempre intermediando. Estos usuarios hablan con los vendedores de herramientas de BI y análisis y, en menor medida, con los vendedores que ofrecen concentradores de datos y concentradores de análisis.
El verdadero problema para todos estos grupos consiste en introducir los datos en el repositorio de datos, enriquecerlos, ejecutar análisis de referencia en la plataforma y aprovechar las herramientas existentes para realizar más análisis de BI, IA, visualización e informes sin salir del entorno. El problema es más agudo para la parte empresarial, ya que necesitan herramientas de autoservicio que actualmente no tienen fuera de las herramientas de BI y análisis (que a menudo silencian los datos dentro de la herramienta/proyecto en lugar de facilitar la construcción de una visión unificada que pueda ser vista por todas las partes).
Todo el mundo está de acuerdo en que tiene que haber una visión unificada de los datos a la que todas las partes puedan acceder, pero el acuerdo no satisfará a todas las partes por igual. Un data lakehouse basado en un lago de datos es una gran manera de mejorar el ciclo de vida de ML y acercar a los científicos de datos al resto del equipo interfuncional. Sin embargo, eso podría lograrse simplemente trasladando la infraestructura HDFS a la nube y utilizando S3, ADLS o Google Cloud Store, además de un moderno entrepôt de données cloud. Una solución de este tipo satisfaría la inmensa mayoría de los casos de uso que operacionalizan componentes ML para cargas de trabajo. Lo que realmente falta tanto en el lago de datos como en el centro de análisis de datos es la funcionalidad del centro de datos y del centro de análisis, que está integrada en el centro de análisis de datos.
Conclusión: Lakehouse sólo ofrece un subconjunto de las funciones de un centro de análisis de datos.
El diagrama con el que hemos comenzado ilustra cómo un centro de análisis de datos consolida los elementos esenciales de un lago de datos, un almacén de datos, un centro de análisis y un centro de datos. También pone de manifiesto la falta de visión a largo plazo del enfoque del «data lakehouse». No basta con fusionar solo dos de los cuatro componentes que los usuarios necesitan para el análisis moderno, sobre todo cuando el desarrollo de esta quimera se basa en los comentarios de un subconjunto de los perfiles multifuncionales que utilizan la plataforma.
En la próxima entrada del blog, analizaremos con más detalle los casos de uso impulsados por este grupo más amplio de usuarios, y quedará claro por qué y cómo un centro de análisis de datos satisfará mejor las necesidades de todas las partes, independientemente de si se centran en optimizaciones basadas en el aprendizaje automático o en las cargas de trabajo operativas diarias.
Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)