Historia de las bases de datos: Ingres y el X100





Doug Inkster es un Actian Fellow con una larga trayectoria en el mercado de las bases de datos, que comenzó con IDMS en los años setenta y pasó a Ingres en los noventa. Le pedimos que recordara los momentos más emocionantes de su larga carrera. He aquí algunas de sus reflexiones:
En mis más de 40 años de trabajo y desarrollo de software de gestión de bases de datos, uno de los mejores días fue cuando conocí a Peter Boncz y Marcin Żukowski por primera vez. Yo estaba en Redwood City impartiendo formación sobre optimizadores de consultas para el equipo de ingeniería de rendimiento de Ingres Corp. (ahora Actian), y Peter y Marcin estaban en la zona de la bahía para dar una conferencia en la Universidad de Stanford.
Dan Koren, director de ingeniería de rendimiento, les invitó a hablar de la tecnología MonetDB/X100, objeto de la investigación doctoral de Marcin bajo la dirección de Peter. Dan era un gran admirador de la investigación sobre MonetDB realizada en gran parte por Peter en el CWI (el centro de investigación en matemáticas e informática financiado por el gobierno holandés) de Ámsterdam, y X100 era una continuación de MonetDB.
El día comenzó con sólo nosotros cuatro en una sala de conferencias en la sede de Ingres y Marcin dio el pistoletazo de salida con una rápida visión general de su presentación en Stanford. Peter y Marcin experimentaron comparando varios DBMS de almacenamiento por filas ejecutando la primera consulta del benchmark TPC H con un programa en C escrito a mano equivalente a la misma consulta. El programa escrito a mano era mucho más rápido que el SGBD más veloz y dio lugar al proyecto de investigación X100 (llamado así por su "modesto" objetivo de multiplicar por 100 el rendimiento actual de las bases de datos).
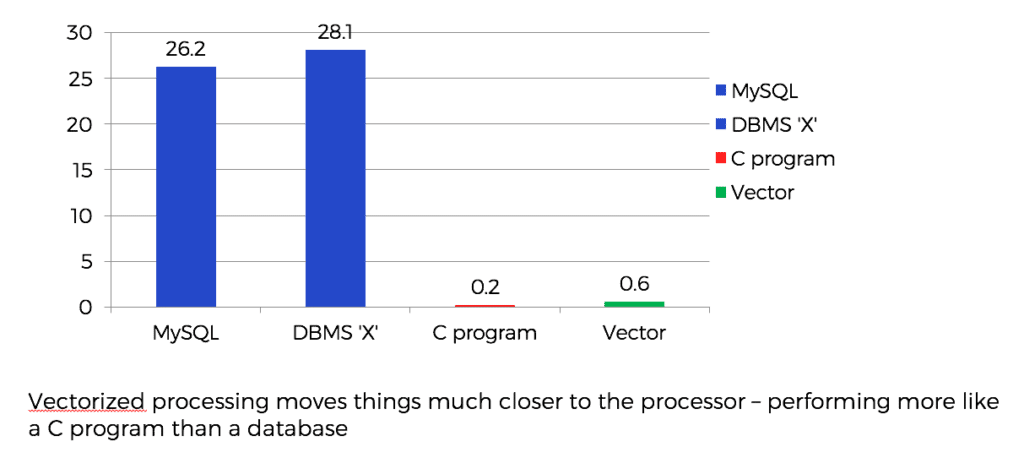
Sus investigaciones concluyeron rápidamente que la complejidad de los almacenes de filas no se limitaba únicamente a su representación en disco. El procesamiento de los datos del almacén de filas una vez en la memoria de un servidor de bases de datos sigue siendo muy complejo. La complejidad del código desafía los intentos de las cachés de aprovechar la localidad y la ejecución en orden de las instrucciones. De hecho, algunos almacenes de columnas sufren los mismos problemas de procesamiento al convertir el formato del almacén de columnas a filas una vez que los datos están en la memoria del servidor. El direccionamiento de las columnas en cuestión y la posterior ejecución de las operaciones celda por celda consumen muchos ciclos de máquina.
Ya habían abordado algunos de los problemas con MonetDB, pero seguía teniendo problemas de complejidad de consulta y escalabilidad. X100 introdujo la idea de procesar "vectores" de datos de columnas de una sola vez y transmitirlos de operador a operador. En lugar de calcular expresiones en la columna de una fila cada vez, o comparar valores de columna de filas individuales cada vez, el motor de ejecución de X100 procesa operadores en vectores de valores de columna con una única invocación de rutinas de tratamiento de expresiones. Las rutinas toman los vectores como parámetros y consisten en bucles sencillos para procesar todos los valores de los vectores suministrados. Este tipo de código compila muy bien en las arquitecturas informáticas modernas, aprovechando el pipelining de los bucles, beneficiándose de la localidad de referencia y, en algunos casos, introduciendo instrucciones SIMD (instrucción única, datos múltiples) que pueden operar sobre todos los valores del vector de entrada al mismo tiempo.
El resultado fue la reducción simultánea de las instrucciones por tupla y de los ciclos por instrucción, lo que supuso una enorme mejora del rendimiento. Me había acordado de los viejos ordenadores científicos de los años 70 (CDC, Cray, etc.), que también tenían la capacidad de ejecutar simultáneamente determinadas instrucciones sobre vectores de datos. Sin embargo, en aquella época esas técnicas estaban reservadas al procesamiento científico altamente especializado (predicción meteorológica, etc.). Incluso la reintroducción moderna de tales características de hardware estaba más dirigida a aplicaciones multimedia y juegos de ordenador. El hecho de que Peter y Marcin las aprovecharan para resolver antiguos problemas de procesamiento de bases de datos era brillante.
Por supuesto, sus investigaciones no se limitaban a eso. Uno de los principales componentes de X100 era la idea de utilizar la jerarquía de memoria -del disco a la memoria principal y a la caché- de la forma más eficaz posible. Los datos se comprimen (ligeramente) en disco y sólo se descomprimen cuando los vectores de valores están listos para ser procesados. Los tamaños de los vectores se optimizan para equilibrar el rendimiento de E/S con la capacidad de la caché. Pero para mí, la emoción (y la diversión al mismo tiempo) estaba en ver que un hardware diseñado para transmitir películas y jugar a Minecraft podía utilizarse con tanta eficacia en una aplicación empresarial tan fundamental como la gestión de bases de datos.
La posterior adopción de la tecnología X100 por parte de Ingres condujo rápidamente a un rendimiento TPC H récord (más bien aplastante) y a algunos de los años más agradables de mi carrera profesional.
Nota: Ingres sigue siendo un popular RDBMS orientado a filas que soporta aplicaciones de misión crítica, mientras que X100 ofrece un rendimiento de consulta líder en el sector tanto en la base de datos analítica Actian Vector como en la base de datos híbrida Actian X, una combinación de tecnologías Ingres y X100 capaz de manejar tablas basadas en filas y en columnas.

Manténgase conectado
Información detallada sobre los datos a su disposición.
(por ej., ventas@..., asistencia@...)