Actian zeigt große Vorteile gegenüber SQL auf Hadoop-Alternativen
Actian Germany GmbH
6. Juni 2020

Stellen Sie sich vor, dass Berichte, deren Ausführung in Hadoop derzeit viele Minuten dauert, in Sekundenschnelle Ergebnisse liefern könnten. Erhalten Sie Antworten auf detaillierte Fragen zu Verkaufszahlen und Kundentrends in Echtzeit. Erstellen Sie Umsatzprognosen auf der Grundlage aktueller Kundenmetriken aus einem breiten Spektrum von Quellen. Iterieren Sie schneller und simulieren Sie verschiedene Geschäftsentscheidungen, um bessere Ergebnisse zu erzielen. Die Actian Vector for Hadoop Analyseplattform kann diese Verbesserungen in Ihrer Hadoop Big Data Umgebung liefern.
Actian Vector für Hadoop hat im Vergleich zu anderen großen SQL in Hadoop Alternativen eine um ein bis drei Größenordnungen bessere abfragen gezeigt.
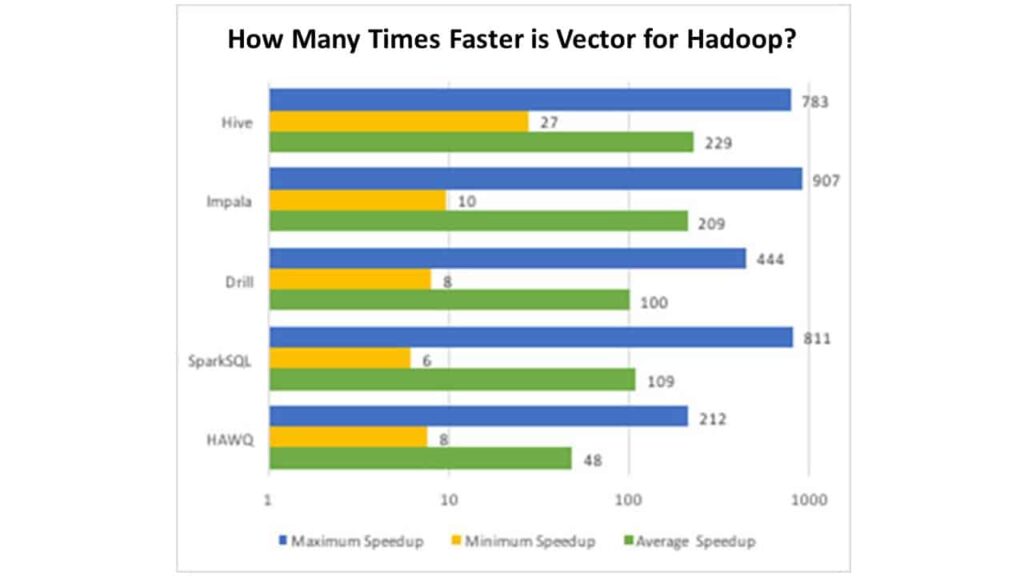
Actian Performance Engineering hat den vollständigen Satz von 22 TPC-H-Abfragen verwendet, um ungeprüfte Benchmarks mit mehreren der auf dem Markt befindlichen SQL-on-Hadoop-Lösungen durchzuführen, und die Ergebnisse könnten Sie überraschen (uns aber nicht). Hier ist eine kurze Zusammenfassung:
Diese Ergebnisse wurden in einem wissenschaftlichen Papier veröffentlicht, das bei der International Conference on Management of Data (ACM SIGMOD) eingereicht und vorgestellt wurde. Das Papier geht auf viele technische Gründe ein, wie Vector for Hadoop einen solchen Leistungsvorteil erzielen kann - hier ist die Kurzfassung:
- Effiziente, parallele und vektorisierte Multi-Core - Vector for Hadoop wurde entwickelt, um die Leistungsmerkmale der CPU zu nutzen, einschließlich des AVX2-Vektorbefehlssatzes und großer, mehrschichtiger Caches.
- Gut abgestimmter abfragen - Vector for Hadoop erweitert den ausgereiften Optimierer aus seiner ursprünglichen SMP-Version, um die verschiedenen Ebenen der Parallelität und die Vorteile der Datenlokalität in einem MPP-Hadoop-System zu nutzen. Der Vector for Hadoop-Optimierer kann die Join-Reihenfolge ändern oder Datentabellen partitionieren, um parallele Operationen zu verbessern, Schritte, die für Abfragen in den anderen Alternativen manuell durchgeführt werden müssen.
- Kontrolle über die HDFS-Blocklokalität - da Vector for Hadoop nativ innerhalb von HDFS und YARN arbeitet, kann es an der Ressourcenverwaltung teilnehmen und Zuweisungsentscheidungen im Kontext des größerenWorkload treffen. Gleichzeitig reduzieren spezifische Optimierungen der Tabellenspeicherung den Overhead, beschleunigen die Lesevorgänge, maximieren die Festplatteneffizienz und reduzieren den Datenschiefstand, um schnellere abfragen zu erzielen.
- Effektive E/A-Filterung - die Verfolgung des Wertebereichs in einer Spalte (MinMax) ermöglicht das Überspringen des Lesens von Blöcken, die außerhalb des Bereichs der abfragen liegen, wodurch E/A und Leseverzögerungen auf der Festplatte reduziert und Dekomprimierungsberechnungen vermieden werden, manchmal sogar erheblich.
- Leichtgewichtige Komprimierung - Die Komprimierung von Vector erreicht ein hohes Maß an Verdichtung bei hoher Geschwindigkeit, wodurch eine schnellere vektorisierte Ausführung durch Minimierung von Verzweigungen und Befehlsanzahl erreicht wird. Unsere Kompressionsalgorithmen sind in der Lage, vollständig im CPU zu laufen, was die Speicherbandbreite effektiv erhöht. Verschiedene Kompressionsalgorithmen sind auf die verschiedenen Datentypen zugeschnitten, und Vector kalibriert und wählt automatisch zwischen ihnen aus, um im Vergleich zu allgemeinen Kompressionsalgorithmen ein höheres Maß an Kompression und Effizienz zu erreichen.
Wie wurden die Tests durchgeführt?
- Actian Performance Engineering baute einen Cluster, jeder Knoten 2xIntel 3.0GHz E5-2690v2 CPUs, 256GB RAM, 24x600GB HDD, 10Gb Ethernet, Hadoop 2.6.0. Es gab einen Namensknoten und neun SQL-on-Hadoop-Knoten, die mit Cloudera Express 5.5 eingerichtet wurden.
- Diese Tests wurden Anfang 2016 mit der jeweils aktuellsten Version der SQL-on-Hadoop-Alternativen (Actian Vector for Hadoop 4.2.2, Apache Hive 1.2.1, Cloudera Impala 2.3, Apache Drill 1.5, Apache Spark SQL 1.5.2 und Pivotal HAWQ 1.3.1) durchgeführt. Es wurden angemessene Anstrengungen unternommen, jede Plattform feinabstimmen , um faire Vergleiche zu ermöglichen.
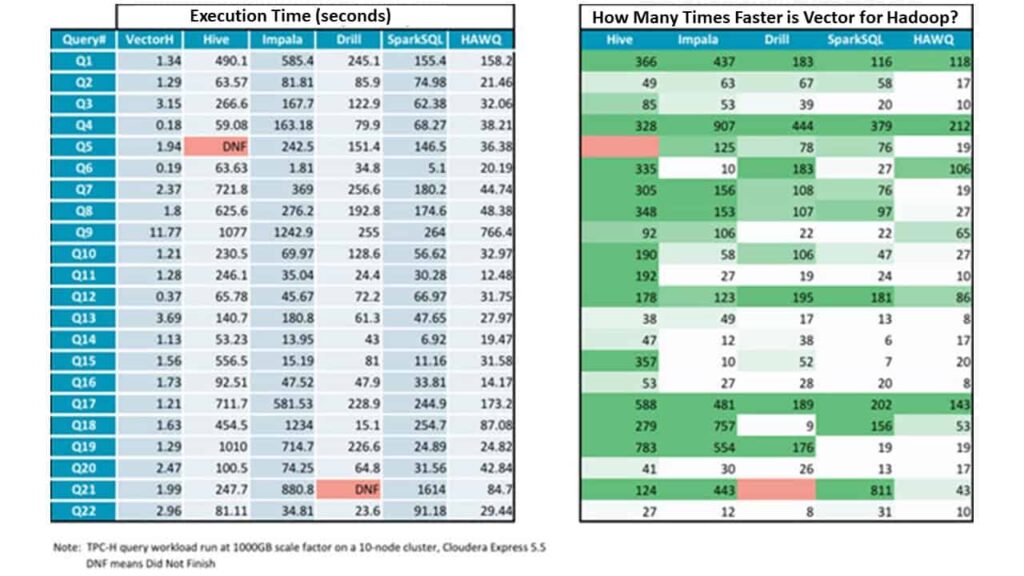
Hier sind die tatsächlichen individuellen abfragen und der Beschleunigungsfaktor für Vector für Hadoop im Vergleich zu jeder der Alternativen:
Abonnieren Sie den Actian Blog
Abonnieren Sie den Blog von Actian, um direkt Dateneinblicke zu erhalten.
- Bleiben Sie auf dem Laufenden: Holen Sie sich die neuesten Informationen zu Data Analytics direkt in Ihren Posteingang.
- Verpassen Sie keinen Beitrag: Sie erhalten automatische E-Mail-Updates, die Sie informieren, wenn neue Beiträge veröffentlicht werden.
- Ganz wie sie wollen: Ändern Sie Ihre Lieferpräferenzen nach Ihren Bedürfnissen.
Abonnieren
(d.h. sales@..., support@...)