Aufschlüsselung der Datenherkunft: Typologien und Granularität





Als Konzept scheint Data Lineage universell zu sein: Unabhängig vom Tätigkeitsbereich muss jeder Stakeholder in einer data-driven Organisation den Ursprung (Upstream Lineage) und das Ziel (Downstream Lineage) der Daten kennen, die er bearbeitet oder interpretiert. Diesem Bedürfnis liegen wichtige Motive zugrunde.
Für einen Datenkatalog-Anbieter ist die Fähigkeit, Data Lineage verwalten, entscheidend für sein Angebot. Doch wie so oft verbirgt sich hinter einer einfachen und universellen Frage eine schwer zu erfassende Komplexität. Diese Komplexität hängt zum Teil mit derHeterogenität der Antworten zusammen, die von einem Gesprächspartner zum anderen im Unternehmen variieren.
In diesem Artikel erläutern wir unseren Ansatz zur Aufschlüsselung der Datenabfolge je nach Art der gesuchten Informationen und ihrer Granularität.
Die Typologie der Datenabstammung: Suche nach dem Ursprung der Daten
Es gibt viele mögliche Antworten auf die Frage nach dem Ursprung der Daten. Einige wollen die genaue Formel oder Semantik der Daten wissen. Andere wollen wissen, aus welchen Systemen, Anwendungen, Maschinen oder Fabriken die Daten stammen. Einige werden sich für die Geschäfts- oder Betriebsprozesse interessieren, die die Daten erzeugt haben. Andere wiederum interessieren sich für die gesamte vor- und nachgelagerte technische Verarbeitungskette. Es ist schwierig, sich in diesem Gewirr von Überlegungen zurechtzufinden!
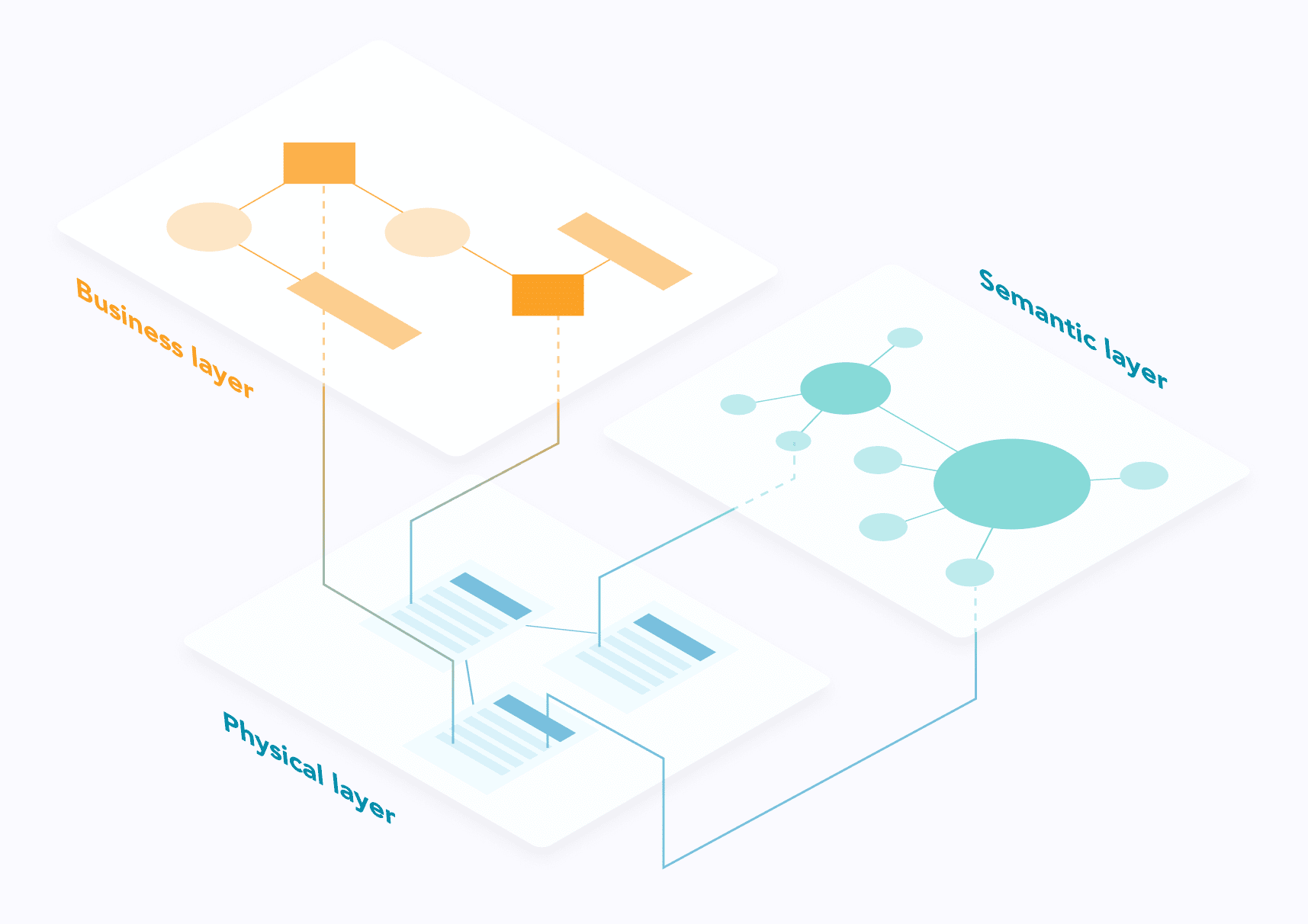
Ein Schichten-Ansatz
Für die Strukturierung von Abstammungsinformationen schlagen wir vor, die Praxis der Geokartierung praktiziert wird, indem wir mehrere übereinander liegende Ebenen unterscheiden. Wir können drei identifizieren:
- Die physische SchichtSie umfasst die Objekte des Informationssystems - Anwendungen, Systeme, Datenbanken, Datensätze, Integrations- oder Transformationsprogramme usw.
- Die GeschäftsebeneSie enthält die organisatorischen Elemente - Bereiche, Geschäftsprozesse oder Aktivitäten, Entitäten, Manager, Kontrollen, Ausschüsse usw.
- Die semantische Schichtdie sich mit der Bedeutung der Daten befasst - Berechnungsformeln, Definitionen, Ontologien usw.
Schwerpunkt auf der physikalischen Schicht
Die physische Ebene ist die Grundfläche, auf der alle anderen Ebenen verankert werden können. Auch dieser Ansatz ähnelt dem der Geokartierung: Über der physischen Karte können andere Ebenen mit spezifischen Informationen eingeblendet werden.
Die physische Schicht stellt die technische Dimension des Stammbaums dar; sie wird durch greifbare technische Artefakte materialisiert - Datenbanken, Dateisysteme, Integrations-Middleware, BI-Tools, Skripte und Programme usw. Theoretisch kann die Struktur des physischen Stammbaums aus diesen Systemen extrahiert und dann weitgehend automatisiert werden, was bei den anderen Schichten im Allgemeinen nicht der Fall ist.
Damit dieser Bottom-up-Ansatz funktionieren kann, muss die physische Abstammung vollständig sein.
Das bedeutet nicht, dass die Abstammung aller physischen Objekte verfügbar sein muss, aber für die Objekte, die eine Abstammung haben, muss diese vollständig sein. Hierfür gibt es zwei Gründe. Erstens besteht die Gefahr, dass eine unvollständige (und damit falsche) Abstammung die Person, die den Katalog konsultiert, in die Irre führt und die Annahme des Katalogs gefährdet. Zweitens dient die physische Schicht als Anker für die anderen Schichten, was bedeutet, dass alle Unzulänglichkeiten in ihrer Abstammung weitergegeben werden.
Zusätzlich zu dieser schichtweisen Darstellung wollen wir uns mit einem weiteren grundlegenden Aspekt der Abstammung befassen: ihrer Granularität.
Granularität der Datenabfolge
Bei der Granularität der Abstammung unterscheiden wir 4 verschiedene Ebenen: Werte, Felder (oder Spalten), Datensätze und Anwendungen.
Die Werte können schnell angesprochen werden. Ihr Zweck ist es, alle Schritte zu verfolgen , die zur Berechnung bestimmter Daten unternommen wurden (wir beziehen uns hier auf bestimmte Werte, nicht auf die Definition bestimmter Daten). Bei Anwendungen zur Preisermittlung nach dem Modell muss die Preisabfolge beispielsweise alle Rohdaten (Zeitstempel, Lieferant, Wert), die von diesen Rohdaten abgeleiteten Werte sowie die Versionen aller bei der Berechnung verwendeten Algorithmen enthalten.
Regulatorische Anforderungen gibt es in vielen Bereichen (Banken, Finanzen, Versicherungen, Gesundheitswesen, Pharmazie, IOT usw.), aber in der Regel in einer sehr lokalisierten Weise. Sie sind eindeutig außerhalb der Reichweite eines Datenkatalog, in dem es schwer vorstellbar ist, jeden Datenwert zu verwalten! Die Erfüllung dieser Anforderungen erfordert entweder ein spezialisiertes Softwarepaket oder eine spezifische Entwicklung.
Die anderen drei Ebenen befassen sich mit Metadaten und fallen eindeutig in den Aufgabenbereich eines Datenkatalog. Lassen Sie uns diese kurz erläutern.
Die Website Feldebene ist die detaillierteste Ebene. Sie besteht darin, alle Schritte (auf physischer, geschäftlicher oder semantischer Ebene) für eine Information in einem Datensatz (Tabelle oder Datei), einem Bericht, einem dashboard usw. nachzuvollziehen, die es ermöglichen, das betreffende Feld zu füllen.
Auf der Datensatz wird die Abstammung nicht mehr für jedes Feld definiert, sondern auf der Ebene des Feldcontainers, der eine Tabelle in einer Datenbank, eine Datei in einem Daten-Lake, eine API usw. sein kann. Auf dieser Ebene werden die Schritte dargestellt, die es uns ermöglichen, den Datensatz als Ganzes aufzufüllen, typischerweise aus anderen Datensätzen (wir finden auf dieser Ebene auch andere Artefakte wie Berichte, Dashboards, ML-Modelle oder sogar Algorithmen).
Schließlich ist die Anwendungsebene ermöglicht schließlich die Dokumentation der Abstammung auf makroskopischer Ebene, wobei der Schwerpunkt auf logischen Elementen auf hoher Ebene im Informationssystem liegt. Der Begriff "Anwendung" wird hier generisch verwendet, um eine funktionale Gruppierung mehrerer Datensätze zu bezeichnen.
Es ist natürlich möglich, sich weitere Ebenen jenseits dieser 3 vorzustellen (z. B. die Gruppierung von Anwendungen in Geschäftsbereiche), aber die Erhöhung der Komplexität ist eher eine Frage der Flussabbildung als der Abstammung.
Schließlich ist es wichtig zu bedenken, dass jede Ebene mit der darüber liegenden Ebene verwoben ist. Das bedeutet, dass die Abstammung der höheren Ebene aus der Abstammung der niedrigeren Ebene abgeleitet werden kann (wenn ich die Abstammung aller Felder eines Datensatz kenne, kann ich auf das Alter dieses Datensatz schließen).
Wir hoffen, dass diese Aufschlüsselung von Data Lineage Ihnen helfen wird, es für Ihr Unternehmen besser zu verstehen. In einem zukünftigen Artikel werden wir unseren Ansatz vorstellen, damit jedes Unternehmen dank unserer Typologie/Granularität/Geschäftsmatrix den maximalen Nutzen aus Lineage ziehen kann.
Bleiben Sie in Verbindung
Datenanalysen, die Ihnen geliefert werden.
(z. B. sales@..., support@...)